# q learning
```python3=
import numpy as np
import random
import os
import time
# 定義迷宮地圖
maze = np.array([
[0, 0, 0, 0, 0, 0, 0, 0],
[0, 1, 0, 1, 1, 1, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0],
[0, 1, 1, 1, 0, 1, 1, 0],
[0, 0, 0, 0, 0, 0, 1, 0],
[0, 1, 1, 1, 1, 0, 1, 0],
[0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 2]
])
# 定義動作:上、下、左、右
actions = [(0, -1), (0, 1), (-1, 0), (1, 0)]
# 初始化Q值表
num_states = maze.size
num_actions = len(actions)
Q = np.zeros((num_states, num_actions))
# 定義參數
learning_rate = 0.1
discount_factor = 0.9
exploration_prob = 0.1 # 降低探索機率
num_episodes = 5000 # 增加訓練次數
# 將2D座標轉換為1D狀態
def state_to_index(state):
return state[0] * maze.shape[1] + state[1]
# 清除終端螢幕
def clear_screen():
os.system('clear' if os.name == 'posix' else 'cls')
# 檢查下一個狀態是否在合法範圍內
def is_valid_move(state, action):
next_state = (state[0] + action[0], state[1] + action[1])
return 0 <= next_state[0] < maze.shape[0] and 0 <= next_state[1] < maze.shape[1] and maze[next_state[0]][next_state[1]] != 1
# Q學習演算法
for episode in range(num_episodes):
state = (0, 0)
state_index = state_to_index(state)
while maze[state[0]][state[1]] != 2: # 直到達到目標
if random.random() < exploration_prob: # 增加隨機探索
action_index = random.randint(0, num_actions - 1)
else:
action_index = np.argmax(Q[state_index])
action = actions[action_index]
if is_valid_move(state, action): # 檢查移動是否合法
next_state = (state[0] + action[0], state[1] + action[1])
next_state_index = state_to_index(next_state)
reward = 0
if maze[next_state[0]][next_state[1]] == 2: # 到達目標
reward = 100 # 增加正向奖励
else:
reward = -1 # 走一步的負向獎勵
Q[state_index][action_index] = (1 - learning_rate) * Q[state_index][action_index] + \
learning_rate * (reward + discount_factor * np.max(Q[next_state_index]))
state = next_state
state_index = next_state_index
clear_screen()
print('Episode:', episode + 1, '/', num_episodes)
# time.sleep(0.01) # 暫停一段時間以可見變化
# 找到路徑從起始位置到目標位置
state = (0, 0)
path = [state]
while state != (7, 7):
state_index = state_to_index(state)
action_index = np.argmax(Q[state_index])
action = actions[action_index]
if is_valid_move(state, action):
state = (state[0] + action[0], state[1] + action[1])
path.append(state)
# 顯示路徑
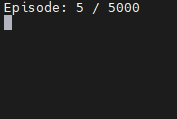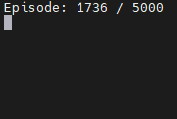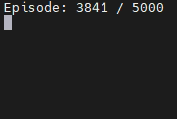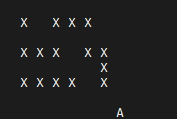
for state in path:
clear_screen()
for i in range(maze.shape[0]):
for j in range(maze.shape[1]):
if state == (i, j):
print('A', end=' ') # 代表智能體的位置
elif (i, j) == (7, 7):
print('G', end=' ') # 目標位置
elif maze[i][j] == 1:
print('X', end=' ') # 牆
else:
print(' ', end=' ')
print()
time.sleep(0.2) # 暫停一段時間以可見變化
```