# Twitter Analytics on the Cloud
START-PANEL:"success"
[table]
[thead]
[tr]
[th]Value[/th]
[th]Target RPS[/th]
[th]Weight[/th]
[th]Due date **(at 11:59PM EST)**[/th]
[/tr]
[/thead]
[tr]
[td]Checkpoint Report[/td]
[td]-[/td]
[td]5%[/td]
[td]Sunday, October 18[/td]
[/tr]
[tr]
[td]Query 1 Checkpoint[/td]
[td]-[/td]
[td]5%[/td]
[td]Sunday, October 18[/td]
[/tr]
[tr]
[td]Query 1 Final[/td]
[td]32,000[/td]
[td]10%[/td]
[td]Sunday, October 25[/td]
[/tr]
[tr]
[td]Query 2 Checkpoint[/td]
[td]-[/td]
[td]10%[/td]
[td]Sunday, October 25[/td]
[/tr]
[tr]
[td]Query 2 Final[/td]
[td]10,000[/td]
[td]50%[/td]
[td]Sunday, November 1[/td]
[/tr]
[tr]
[td]Final Report + Code[/td]
[td]-[/td]
[td]20%[/td]
[td]Tuesday, November 3[/td]
[/tr]
[/table]
END-PANEL
START-PANEL:"warning"
#### For all due dates, the due time is 11:59:59 PM Eastern Standard Time.
END-PANEL
START-PANEL:"info"
#### Learning Objectives
This project will encompass the following learning objectives:
1. Build a performant and reliable web service on the cloud using self-managed VMs within a specified budget by combining the skills developed in this course.
2. Design, develop, deploy, test and optimize functional web-servers that can handle a high load (~ tens of thousands of requests per second).
3. Implement Extract, Transform and Load (ETL) on a large data set (~ 1 TB) with budget constraints and load the data into MySQL and HBase databases.
4. Design a suitable schema for a specific problem as well as optimize MySQL and HBase databases to increase throughput when responding to a large scale of requests.
5. Explore methods to identify the potential bottlenecks in a cloud-based web service to improve system performance.
END-PANEL
### Introduction
After making a huge profit for the Massive Surveillance Bureau, you realize that your Cloud Computing skills are being undervalued. To maximize your own profit, you launch a cloud-based startup company with one or two colleagues from 15619.
A client has approached your company and several other companies to compete on a project to build a web service for analyzing Twitter data. The client has over one terabyte of raw tweets for your consumption. Your responsibility is to design, develop and deploy a web service that meets the throughput, budget and query requirements of the client. You manage to convince your team to join this competition to demonstrate your superior cloud skills to your potential client by winning the competition.
In this competition, your team needs to build (and optimize) a web service with two tier, a web-tier serving http requests and a storage-tier serving different data queries as shown in Figure 1.0.
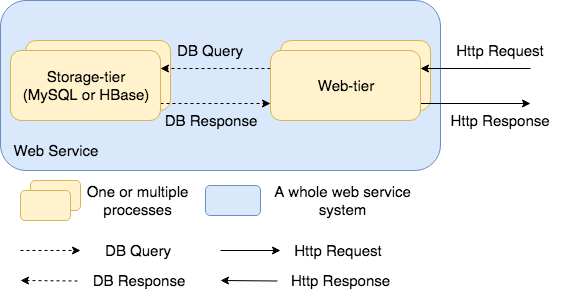
**Figure 1.0:** The runtime view of a multi-tier web service system
Your web service design should follow these guidelines:
1. A Web Tier: This should be a web service able to receive and respond to queries. Specifically, the service should handle incoming HTTP GET requests and provide suitable responses (as defined in the Query Types section below).
1. Users access your service using an HTTP GET request through an endpoint URL. Different URLs are needed for each query type, which are shown in the Query Types section. Query parameters are included within the URL string of the HTTP request.
2. An appropriate response should be formulated for each type of query. The response format should be followed exactly otherwise your web service will not provide acceptable responses when tested with our load generator and testing system.
3. The web service should run smoothly for the entire test period, which lasts for several hours.
4. The web service must not refuse queries and should tolerate a heavy load.
2. A Storage Tier: This is used to store the data to be queried.
1. You will evaluate both SQL (MySQL) **and** NoSQL (HBase) databases in the first two phases of this project.
2. You should compare their performance for different query types for different dataset sizes. You can then decide on an appropriate storage-tier for your final system to compete against other systems in Phase 3.
3. Your web service should meet the requirements for throughput and cost/hour for queries at a provided workload.
4. The overall service (development and deployment test period) should cost under a specified budget. Less is generally better, otherwise your competitor will win the contract.
5. Your client has a limited budget. So, you can **ONLY** use instances in the **M family** which are smaller than or equal to **large** for your web service (both your web-tier and storage-tier) in all your submissions. You can use t3.micro instance for your initial testing but submissions should adhere to the restrictions of M family smaller than or equal to large. You should use spot instances for batch jobs and development. For instance storage, you are **ONLY** allowed to use **General Purpose SSD Volumes (gp2)**. Using other types of volumes (io1, st1, etc.) is not allowed. You are also limited to having 1 volume that holds the database on a single instance, i.e., we don't want you to use soft RAID for this project! Mind that since m5d instances do not use the gp2 storage, they are **not** allowed for the project. However, m5a instances are allowed.
### Dataset
The dataset is available at multiple places:
- **s3://cmucc-datasets/twitter/f20/** (AWS)
- **wasb://twitter@cmuccpublicdatasets.blob.core.windows.net/f20/** (Azure)
- **gs://cmuccpublicdatasets/twitter/f20/** (GCP)
You can do your ETL process on any of these platforms, but we encourage you to not use AWS, since we have a budget limit for AWS and ETL is costly. If you choose to use Azure or GCP, you can use any of your team members' accounts. We do not have a strict budget limit for Azure and GCP, but you should be careful about your balance in these platforms. If you are using Azure, please also double check the expiration date of the Lab your subscription belongs to.
The dataset will be larger than 1 TB after decompressing. There may be **duplicate** or **malformed** records that you need to account for.
The dataset is in [JSON](http://en.wikipedia.org/wiki/JSON) format. Each line is a JSON object representing a tweet. Twitter's documentation has a good description of the data format for tweets and related entities in this format. Here is a link to the [Twitter API](https://developer.twitter.com/en/docs/tweets/data-dictionary/overview/tweet-object).
Please note that since the tweet texts in the JSON objects are encoded with unicode, different libraries might parse the text slightly differently. To ensure your correctness, we recommend that you use the following libraries to parse your data.
* If you are using Java, please use **org.json**. [(mvn)](https://mvnrepository.com/artifact/org.json/json)
* If you are using Python, use the **json** module in the standard library
### Deliverables
This project has 3 phases. In each phase you are required to implement your web service to provide responses to some particular types of queries. The query types will be described in the writeup of each phase.
At the end of each project phase, you need to submit some deliverables including:
1. Performance data of your web service.
2. Cost analysis of the phase.
3. All the code related to the phase, including your auto-deployment script for web service and your database loading scripts. In your scripts, web-tier of all queries should be provisioned automatically. For storage-tier, you need to provision the VMs for HBase and MySQL but you are not required to import data to the databases in your auto-deployment script.
4. Answers to questions associated with the phase.
5. A **Checkpoint 1 report** at the end of Phase 1 Checkpoint 1. This report is designed to help you start thinking about the project. We have provided some useful hints in the report questions so please read the report template before you start coding. Please remember to submit your report in `pdf` format.
6. A **final report** at the end of each phase. This report must include detailed evidence-supported reasoning for your design decisions and deliverables for each phase. A report template is provided. **We encourage you to read the report template prior to commencing your work since you have to collect data and experimental results for the report.** Please remember to submit your report in `pdf` format.
### Load Generation and Web Service Testing
#### Scoreboard
We provide a real-time scoreboard for you to compare your performance with other teams. Your best submission for each query will be displayed on the scoreboard.
**Note:** For Phase 1, you will only see your Q2 performance on the scoreboard if you have achieved at least 30% of the target RPS for both MySQL and HBase.
START-PANEL:"info"
If your team achieves higher than the target on each query, the score will be calculated using the largest throughput from each query. For grading purposes, the maximum score will be capped according to the weight of each query, although the throughput may show higher.
END-PANEL
#### How to submit your request?
You can submit the public DNS of your web service to start the test. The DNS you submit is the one we will send requests to, in order to do performance testing on your service. You can submit the DNS of an EC2 instance or of an Elastic Load Balancer. We provide tests of varying durations. Please think carefully about what you need to verify for each request and choose an appropriate duration. For example, if you want to just verify whether your service is reachable and is giving correct results, you probably don't need to run a long test. On the other hand, if you want to test your service to see how it performs under a heavy load for a long duration, you probably don't want to run a short (1 or 2-minute) test. Please be aware that a short term test may have a different throughput as long test. Long test will give you a stable result about the throughput performance. We will only run 10-minute test during Live Test.
#### How is my web service tested?
When you submit a request, a testing instance (similar to load generators that you launched in previous projects) will be launched by us. This instance will run a performance test for the specified query against the web service address that you provided. We will be testing both performance and correctness. At the end of the test, the results will be displayed in your submission history table on TheProject.Zone.
#### Wait List
Since we have a limited amount of resources and budget, if there are many teams submitting requests at the same time, your request may be waitlisted. Our system will try to add or deduct resources automatically based on the current average waiting time, so don’t worry if you see a long waiting time.
#### FAQs (we will update these to reflect common administrative questions, keep an eye on Piazza as well)
* Can I use my individual project account to submit a request?
* No, you can only use the team account that you entered on TheProject.Zone.
* Why can't I submit a request?
* To save cost and prevent repeat submissions, every team can only have one request running or waiting. In other words, if anyone in your team submits a request, no one in your team can submit another request until the running job finishes.
* Can I schedule submissions in the future or make multiple submissions?
* No.
* Why does my 10-minute submission abort quickly and I get a 0 score?
* Our auto grader will automatically drop your submission at the 90th second if your submission has one of these:
* < 10% of the target RPS
* < 80% correctness
* > 20% error rate
#### Submission History
When your submission is running, you can check the submission history page to see the progress of the current submission and how many seconds are remaining. After your request finishes, your results will be displayed. You can also view all your previous submissions. If you have doubts for a specific query, you can take down the submission ID and contact us for more details.
#### Interpreting your results
There are several parameters shown for each query submission:
1. Throughput: average responses per seconds during the testing period.
2. Latency: Average latency for each query issued during the testing period.
3. Error: The error rate. Your message type in the HTTP header of your response must be 2xx. Otherwise it will be recognized as an erroneous response and counted in the error rate.
4. Correctness: This column indicates whether your service responds with the correct result. Your response should exactly match our standard response format, so please read the requirements of each query carefully.
#### Query Score Calculation
The raw score for a query is based on the effective throughput for that query
Error Rate = Error / 100
Correctness Rate = Correctness / 100
Effective Throughput = Throughput * (1 - Error Rate) * Correctness Rate
Raw Score = (Effective Throughput)/(Target Throughput)
The Target Throughput will be provided by us for each query. As you can see, error and correctness can severely impact your effective throughput.
#### Phase 1 Query Score
In Phase 1, only the score of a 10-minute submission will be counted as the score for this query. We will choose your highest score as your final score by the deadline of each query, so keep trying! Remember, the Query 1 deadline is sooner than the Phase 1 deadline. So you need to have a 10-minute Query 1 submission before the deadline.
#### Live Tests
Phases 2 and 3 culminate in a Live Test, where services developed by all competitors (teams) are tested at the same time. Your grade for these two phases is based on your performance in these tests and the report.
#### Bug Report
If you encounter any bugs in this system or have any suggestions for improvement, feel free to post privately on Piazza.