---
tags: TTF, GNU/Linux
---
# Il Sistema Operativo GNU/Linux 2021
## Linux
### Linux & GNU: Introduzione e storia
In questa parte introduttiva scopriremo com'è nato linux e come si è evoluto fino a oggi. Introdurremo anche i concetti di *kernel* e *sistema operativo*.
Partiamo da definire cos'è un sistema operativo e quali sono i suoi compiti. Ogni volta che si accende il computer, viene visualizzata una schermata in cui è possibile eseguire diverse attività come scrivere una lettera, navigare in Internet o guardare un video. Cos'è che fa funzionare l'hardware del computer in quel modo? Come fa il tuo computer a sapere che gli stai chiedendo di eseguire un file mp3?
Bene, è il sistema operativo o il kernel che fa questo lavoro. Un **kernel** è un programma al centro di qualsiasi sistema operativo che si occupa di cose fondamentali, come consentire all'hardware di comunicare con il software. Un **Sistema Operativo** però non è composto solo dal kernel. Al suo interno vi sono altri programmi o librerie che ti permettono di sfruttare il kernel e l'hardware in modo semplice e fare attività di grande valore!
Cos'è Linux?
> Linux è un kernel, non è un sistema operativo. È distribuito con una licenza open source. Il suo elenco di funzionalità è molto simile a UNIX e anche la sua interfaccia di sistema.
Nell'immagine sotto, trovate una rappresentazione schematica di come il kernel comunica con il resto del software, chiamato *User Space* nell'immagine.

Sostanzialmente il kernel è formato da svariati componenti specializzati che lavorano i stretta simbiosi con l'hardware sottostante; mentre, la comunicazione verso gli altri software (User Space) viene mediato da un livello intermedio che astrae e disaccoppia il kernel dagli applicativi che lo devono utilizzare. Questo livello intermedio si chiama *System Call Interface*. La System Call Interface del kernel Linux è molto simile a quella del Sistema Operativo UNIX e per questo motivo è compatibile con tantissimo software scritto per UNIX.
Da UNIX sono nati svariati progetti di kernel proprietari o "free", ma questa è un'altra storia che meriterebbe ore per essere raccontata! Qui sotto vi lascio la timeline dei kernel derivati da UNIX.

*Image: Unixtimeline.en.svg: Guillem, Wereon, Hotmocha (copied from old version's history) Christoph S. (redrew the image with w:Inkscape). - From Image:Unix timeline.en.svg and that is from Image:Unix.png.*
Chi ha creato Linux?
> Linux germinò da un'idea nella mente del giovane e brillante Linus Torvalds quando era uno studente di informatica. Torvalds lavorava sul sistema operativo UNIX (software proprietario) e pensava che necessitasse di miglioramenti. Tuttavia, quando i suoi suggerimenti sono stati respinti dai progettisti di UNIX, Torvalds ha pensato di lanciare un sistema operativo che fosse ricettivo alle modifiche, modifiche suggerite dai suoi stessi utenti.
Così Torvalds ha ideato un kernel chiamato Linux nel 1991. Il nuovo kernel era qualcosa come un cono gelato, ma senza gelato in cima. Mancavano totalmente i programmi che normalmente vengono eseguiti da un Sistema Operativo e.g. File Manager, Document Editor, Audio-Video. Fino al 1994 le versioni di Linux non erano così facili da usare in quanto erano utilizzate dai programmatori di computer e **Linus Torvalds non aveva mai pensato di commercializzare il suo prodotto**.
Col passare del tempo, Torvalds ha collaborato con altri programmatori, principalmente appartanenti ad università o istituti di ricerca, **le applicazioni per il kernel Linux hanno iniziato ad apparire grazie alla sua "compatibilità" con UNIX**. Quindi, intorno al 1994, fu lanciato ufficialmente un sistema operativo basato su kernel Linux funzionante con alcune applicazioni e questo fu l'inizio di uno dei sistemi operativi più amato e open source disponibile oggi.
Perché proprio nel 1994?
> Nel 1994 viene rilasciata la prima versione stabile del kernel Linux.
Il principale vantaggio di Linux è che i programmatori sono in grado di utilizzare il kernel per disegnare e progettare il proprio "sistema operativo" personalizzato. Personalizzato in base ai propi gusti e alle proprie esigenze! Oggi i Sistemi Operativi basati su kernel Linux sono presenti in tantissimi computer o dispositivi e neanche ce ne accorgiamo! Per esempio:
- smartphone Android
- dispositivi multimediali domestici e automotive
- modem e router
- super-computer
- apparati di rete
Tra il 1993 e il 1994 nascono le prime distribuzioni GNU/Linux. Esse sono la combinazione del kernel Linux con i programmi (librerie, applicazioni, utilità, etc.) del GNU Project.
Cos'è il GNU Project?
> GNU è un sistema operativo UNIX-like. Lo sviluppo di GNU, iniziato nel gennaio 1984, è noto come GNU Project.
Il GNU Project è composto da svariati software: applicazioni, librerie, strumenti di sviluppo, kernel, etc. In un sistema UNIX-like, il programma che alloca le risorse della macchina e parla all'hardware si chiama kernel. GNU è in genere usato con un kernel chiamato Linux, anche se possiede un kernel sviluppato internamente al progetto e chiamato Hurd. Questa combinazione è il sistema operativo GNU/Linux. Non tutti i Sistemi Operativi che utilizzano il kernel Linux sono basati su GNU, per esempio Android non è un OS GNU/Linux!
Le prime 3 distribuzioni GNU/Linux sono considerate i "padri fondatori" e oggi la maggior parte delle distribuzioni sono derivate da 2 di quelle prime 3!
I "padri fondatori" sono:
- Slackware 1993
- Debian 1994
- RedHat 1994
A questo link trovate la timeline (incompleta) delle distribuzioni basate su kernel Linux: [https://upload.wikimedia.org/wikipedia/commons/8/8c/Linux_Distribution_Timeline_Dec._2020.svg](https://upload.wikimedia.org/wikipedia/commons/8/8c/Linux_Distribution_Timeline_Dec._2020.svg)
Riassumendo:
- Linux è un Kernel UNIX-like, cioé il componente alla base di un sistema operativo e che ha il compito di interfacciare il software con l'hardware.
- Il GNU Project ha lo scopo di creare un sistema operativo UNIX-like. Esso mette a disposizione una vasta raccolta di software per comporre il proprio sistema operativo.
- Le distribuzioni GNU/Linux sono dei sistemi operativi (OS) basati sulle applicazioni del GNU Project e che utilizzano un Kernel Linux.
### The Linux Foundation
È l'organizzazione "ombrello" per molti progetti open source cirtici e fondamentali per molte aziende in differenti settori!
> The Linux Foundation makes it its mission to provide experience and expertise to any initiative working to solve complex problems through open source collaboration, providing the tools to scale open source projects: security best practices, governance, operations and ecosystem development, training and certification, licensing, and promotion.
La fondazione orginizza direttamente, o appoggia, svariati eventi con lo scopo di creare dei gruppi di lavoro, connettere le industrie, gli utenti e gli sviluppatori tra loro e, in generale, incoraggiare la collaborazione attraverso la cumminity.
Una parte importante del lavoro della fondazione è quello di erogare corsi di formazione e certificazione relativi a tutto l'ecosistema legato a Linux.
### Caratteristiche
Le principali caratteristiche di un sistema operativo GNU/Linux sono:
- hierarchical filesystem
- processes, devices e network sockets sono rappresentati da oggetti "file-like"
- fully multitasking
- multiuser (più utenti possono loggarsi simultaneamente)
- daemons (UNIX-like)
- configurazioni tramite file di testo
Sotto è rappresentata la gerarchia del filesystem e per ogni directory è illustrato il suo scopo e utilizzo.

*Image: The Linux Foundation*
### Documentazione
Abbiamo differenti sorgenti per la documentazione:
- `man <command_or_topic>` (Linux Programmer's Manual), sono la documentazione ufficiale di linux! Essa è suddivisa in differenti capitoli (1-8), per esempio il capitolo 3 descrive la *X Window API*
- `man –f` oppure `whatis` mostra l'elenco delle pagine il cui nome contiene l'argomento cercato
- `man –k` oppure `apropos` mostra l'elenco delle pagine il cui nome o descrizione contengono l'argomento cercato
- `man socket` mostra la prima pagina che corrisponde all'argomento cercato
- `man -a socket` mostra tutte le pagine che corrispondono all'argomento cercato
- `man 2 socket` mostra la pagina presente al capitolo 2 e che corrisponde all'argomento cercato
- `man 7 socket` mostra la pagina presente al capitolo 7 e che corrisponde all'argomento cercato
- man pages online: https://man7.org/linux/man-pages/
- `info <topic>` GNU info
- `--help` opzione presente in quasi tutti i comandi e le applicazioni e.g. `man --help`
- `help` ci mostra l'help della bash
- `/usr/share/doc` contiene la documentazione dei pacchetti installati
- gli help dei Desktop Environment:
- gnome-help (GNOME)
- yelp (GNOME)
- khelpcenter (KDE)
- risorse online:
- [The Linux Command Line](http://linuxcommand.org/tlcl.php)
- [Ubuntu Documentation](https://help.ubuntu.com/)
- [openSUSE Documentation](https://doc.opensuse.org/)
- [Fedora Documentation](https://docs.fedoraproject.org/)
- [Arch Linux Documentation](https://wiki.archlinux.org/)
- [Gentoo Documentation](https://www.gentoo.org/support/documentation/)
- [Linux Advanced Routing & Traffic Control](https://lartc.org/)
### User Environment
Comandi utili:
- `whoami` identifica l'utente corrente
- `who -a` mostra tutti gli utenti loggati
- `set` *Set or unset values of shell options and positional parameters*
- `unset` *Unset values and attributes of shell variables and functions.*
- `export`
- `env` *Set each NAME to VALUE in the environment and run COMMAND.*
Variabili d'interesse:
- `HOME`
- `PWD`
- `PATH`
- `SHELL`
- `PS1`
## Console & Command Line Interface
### Console "startup files"
In `/etc` ci sono le configurazioni globali di sistema, mentre nella *home* ci sono quelle specifiche e personalizzabili per ogni utente.

:::success
Graphical user interfaces make easy tasks easier, while command line interfaces make difficult tasks possible
:::
- file `~/.bash_history`
- `history` mostra la history
- `!<line_number>` esegue il comando presente nella riga desiderata della history
- `!!` esegue il comando precedente
- `CTRL-R` cerca nella history
La history è configurabile e possiamo vedere la sua configurazione tramite il comando *set*: `set |grep HIST`.
Scorciatoie da tastiera:
- **CTRL-L**: pulisce lo schermo, equivalente al comando `clear`
- **CTRL-Z**: sospende il processo corrente, mettendolo in backgroud
- **CTRL-C**: *kill* del processo corrente
- **CTRL-H**: funziona come il tasto backspace
- **CTRL-A**: torna all'inizio della linea
- **CTRL-W**: cancella la parola prima del cursore
- **CTRL-U**: cacella dall'inizio della linea al cursore
- **CTRL-E**: va alla fine della linea
- **CTRL-R**: cerca nella history
- **Tab**: autocomplemento
### Reboot and Shutting Down
Il metodo prefereito per spegnere o riavviare il sistema è usare il comando `shutdown`. Questo comando invia un "avvertimento" e impegisce agli altri utenti di accedere al sistema. Il processo `init` controllerà lo spegnimento o il riavvio del sistema. È importante spegnere sempre il sistema in modo corretto; in caso contrario, si possono verificare danni al sistema e/o perdita di dati.
I comandi `halt` e `poewroff` lanciano il comando `shutdown -h` per arrestare il sistema; mentre `reboot` lancia `shutdown -r` e provoca il riavvio anziché il sempolice spegnimento della macchina. Sia il riavvio che lo spegnimento da riga di comando richiedono l'accesso come superutente (root).
Quando si amministra un sistema multiutente, si ha la possibilità di avvisae gli utenti prima dello spegnimento, come nell'esempio sotto:
```bash=
$ sudo shutdown -h 10:00 "Shutting down for scheduled maintenance."
```
Nota: nelle distribuzioni GNU/Linux recenti basate su **Wayland**, i messaggi di broadcast non appaiono nell sessioni di "emulazione di terminale" in esecuzione nell'ambiente desktop; essi appaiono solo sui display delle console VT.
### Caricare manualmente i file di configurazione
È possibile creare nuovi file di configurazione della console, in questo modo possiamo creare degli ambiente virtuali personalizzati. Una volta creati i file di configurazione possiamo caricarli nella console tramite uno dei seguenti comandi (sono equivalenti):
```bash=
$ source <env_file>
```
```bash=
$ . <env_file>
```
### Alias
Gli *alias* sono essenzialmente delle corciatoie che ci permetto di ricordare comandi lunghi, riducendo il tempo per la loro digitazione e la probabilità di introdurre errori durante la loro digitazione.
Spesso gli *alias* sono utilizzati per lanciare un comando con delle opzioni predefinite da noi decise e impostate.
Definire un *alias* è molto semplice, basta usare il segeunte comando:
```bash=
$ alias <nome_alias>=<comando da eseguire comprensivo di parametri>
```
## File Ownership & Permission
In linux e più in generale in tutti i sistemi operativi basati su UNIX, i file sono associati a un utente e a un gruppo (un sotto insieme di utenti)! Per ogni file sono definiti i permessi di lettura, scrittura ed esecuzione per il proprio utente, il proprio gruppo e gli altri utenti.
La proprietà e i permessi possono essere manipolati tramite i seguenti comandi:
- `chown` cambia l'utente proprietario e il gruppo (originariamente solo l'utente)
- `chgrp` cambia il gruppo
- `chmod` imposta i permessi
I permessi possono essere rappresentati in 2 differenti modi:
- **numerici** e.g. `640`
- **letterali** e.g. `rw-r-----`
I permessi degli esempi sopra sono del tutto identici!
Quando i permessi sono rappresentati in modo numerico, il primo numero indica i permessi per l'utente proprietario, il secondo per gli utenti appartenti al gruppo proprietario e il terzo si applica a tutti gli altri. Nell'esempio sopra il valore `640` significa che l'utente ha il permesso `6`, il gruppo `4` e gli altri `0`, ma cosa significano quei numeri?
:::info
Il valore 4 significa *read*, il valore 2 `write` il valore 1 `execute` (per le directory significa potervi accedere) e la loro somma è la singola cifra che compone il valore numerico.
:::
| cifra | read | write | execute |
|-------|------|-------|---------|
| 7 | 4 | 2 | 1 |
| 6 | 4 | 2 | - |
| 5 | 4 | - | 1 |
| 4 | 4 | - | - |
| 3 | - | 2 | 1 |
| 2 | - | 2 | - |
| 1 | - | - | 1 |
| 0 | - | - | - |
Quando i permessi sono rappresentati in modo letterale è necessario:
:::info
separarli in 3 gruppi di 3 valori e rimane valida la logica in cui il primo terzetto si applica all'utente proprietario, il secondo terzetto agli utenti appartenti al gruppo proprietario e il terzo terzetto a tutti gli altri.
:::
Nel nostro esempio abbiamo: utente *read* e *write*, gruppo *read* tutti gli altri non hanno alcun permesso di accesso.
La tabella sopra riportata è utile per convertire velocemente i permessi rappresentati in modo numerico con il corrispondente permesso di *read*, *write* ed *execute*.
Il comando `chmod` può essere utilizzato con entrambe le rappresentazioni dei permessi, ma normalmente si adottano 2 modalità di funzionamento differente:
- **numerico**: impostazione dei permessi passati al comando e.g. `chmod 640 file.txt` i permessi sono impostati al valore 640 a prescindere dal loro valore precedente
- **testuale**: modifica differenziale dei permessi e.g. `chmod g+w file.txt` aggiunge il permesso di *write* al gruppo
L'uso del comando *chmod* in maniera differenziale ci permette di modificare un singolo permesso senza alterare gli altri valori. Possiamo aggiungere il permesso usando il carattere **+** oppure rimuovere un permesso usando il carattere **-**. I prefissi **u**, **g** e **o** indicano rispettivamente *utente proprietario*, *gruppo proprietario* e *altri utenti*.
### Users & Groups
File di configurazione:
- `/etc/passwd` contiene gli utenti
- `/etc/shadow` contiene le password crittate
- `/etc/group` contiene i gruppi
Gli **UID** (User ID) inferiori al 1000 sono riservati per il sistema, quindi il primo utente creato avrà ID 1000.
Esempio di utenti:
```
lp:x:4:7:lp:/var/spool/lpd:/bin/false
gianni:x:1000:1000:Gianni Bombelli:/home/gianni:/bin/bash
```
Esempio di gruppi:
```
lp:x:7:lp,gianni
lpadmin:x:106:gianni
gianni:x:1000:
```
Comandi per gestire utenti e gruppi:
- `id`
- `useradd` e.g. `useradd -m -c "Gianni Bombelli" -s /bin/bash bombo82` (-m crea la home directory)
- `userdel` e.g. `userdel -r bombo82` (-r rimuove la home directory)
- `passwd` cambia la password o imposta la password iniziale per un utente
- `groups` mostra i gruppi a cui appartiene l'utente
- `groupadd`
- `groupdel`
- `usermod` modifica i gruppi associati a un utente
Nel file `/etc/defaults/useradd` si trovano le impostazioni predefinite per gli utenti creati tramite il comando `useradd`.
La directory home dell'utente viene creata basandosi sullo *skeleton* predefinito che si trova nella directory `/etc/skel`.
I gruppi sono utilizzati per definire i permessi sui file presenti nel sistema e di conseguenza definire quali operazioni possono fare gli utenti. In GNU/Linux e UNIX praticamente ogni cosa può essere assimilata a un file. Per abilitare gli utenti a svolgere operazioni comuni o particolari essi devono appartenere al relativo gruppo. Per esempio per stampare devono appartenere al gruppo *lp*, per gestire le stampanti al gruppo *lpadmin*, per usare una scheda audio al gruppo *audio*, etc.
:::info
In GNU/Linux e UNIX i gruppi non servono solo per gestire i file, ma anche per definire quali operazioni possono eseguire. Il motivo è semplice: in GNU/Linux e UNIX praticamente qualsiasi cosa è un file!!!
:::
### Ereditarietà e valori di default
I permessi e i gruppi non vengono ereditati! Non vi è alcun meccanismo che implementa l'ereditarietà dei permessi per i file e le directory!
Possiamo solo definire i permessi e i gruppi di default. In generale, l'uso dei valori di default è sufficiente per gestire i permessi di file e directory in modo efficace. Il comando `umask` permette di definire i permessi di default dei file e delle directory contenuti all'interno della directory in cui viene eseguito. Al comando `umask` passiamo un terzetto di numeri che rappresentano i permessi di default per *user*, *group* e *others*. La singola cifra è un numero conpreso tra 0 e 6 e non rappresenta il valore che avrà il permesso bensì la maschera da applicare al valore massimo. I valori massimi per i file è 6, mentre per le directory è 7. Essendo una maschera per trovare i permessi che verranno dati ai file e alle directory è necessario fare un semplice calcolo:
:::success
default permission = max value - umask
:::
Di seguito alcune machere normalmente utilizzate:
| umask | file | directory |
| ----- | ---- | --------- |
| 0 | 6 rw- | 7 rwx |
| 2 | 4 r-- | 5 r-x |
| 6 | 0 --- | 1 --x |
| 7 | 0 --- | 0 --- |
:::warning
Prestate attenzione al fatto che le directory hanno valore massimo `7`, mentre i file `6`. Questo fatto comporta che i permessi di default per i file e le directory saranno differenti e per la precisione le directory saranno anche accessibili perché possiedono in più il permesso `x`.
:::
Abbiamo appena imparato come impostare i permessi di default, ma una cosa importante è poter configurare anche il gruppo predefinito per i file e le directory. La logica predefinita utilizza il gruppo principale dell'utente, ma questo comportamento può essere modificato e utilizzare come gruppo di default quella della directory stessa. Per modificare il comporatamente dobbiamo utilizzare il comando `chmod g+s some_directory`.
### Definire uno schema di permessi
In un Sistema Operativo basato su Ms Windows è consuetudine creare uno schema di permessi che rappresenta i ruoli e la gerarchia all'interno dell'organizzazione. Questo approccio è molto semplice, efficace e facile da comprendere e manutenere. Purtroppo in GNU/Linux non è possibile applicare questo approccio, ma è necessario usare un approccio incentrato sul singolo servizio.
Spesso **un esempio vale più di mille parole** e questa massima si addice perfettamente a questo caso! Supponiamo di avere una macchina GNU/Linux che esegue un web server e vogliamo definire i seguenti permessi per la directory contenente i dati. I permessi sono definiti per alcune *tipologie* di utenti e per la precisione:
- sviluppatori: read, write
- grafici: read, write
- altri: nessun accesso
Creando uno schema di permessi basato sui gruppi `sviluppatori` e `grafici` non è possibile configurare i permessi in modo corretto; mentre, è fattibile sfruttando un gruppo apposito per il servizio (o scopo), come il gruppo `www-data` in cui verranno inseriti sia gli sviluppatori che i grafici.
## Boot Process
A livello puramente concettuale, possiamo vedere il processo di boot come una sequenza di operazioni eseguite dalla macchina:

Nella realtà, tutti i sistemi operativi moderni eseguono in parallelo alcuni di questi step, oppure sfruttano il multi-tasking per eseguire in parallelo alcune operazioni presenti nello stesso step.

## Daemons
Nei sistemi operativi multi-task, un **daemon** è un processo in background non associato ad alcun terminale. Tradizionalmente i nomi dei daemon terminano con la lettera **d**, ma questa regola non è sempre applicata e.g. httpd, ftpd, ntpd, sshd, cronie, gpm, syslog-ng, nullmailer, docker
Dal punto di vista prettamente tecnico, nei sistemi UNIX-like un processo è un daemon quando il suo processo padre (quello che lo ha lanciato) termina e gli viene assegano come padre il processo **init** (PID 1) e non ha un terminale di riferimento. Tuttavia potrebbe essere considerato un daemon qualsiasi processo eseguito in background che non è associato ad alcun terminale, a prescindere da essere figlio o meno del processo **init**.
Storicamente in GNU/Linux, la gestione dei daemons è basata sul modello di **UNIX System V** (pronunciato "system five"), ma nell'ultimo decennio è nata e ha preso piede un nuova suite di applicazioni chiamata **systemd**. A differenza di System V che si occupa solo della gestione del processo di boot e dei daemon, il nuovo **systemd** controlla anche altre operazioni di basso livello del sistema operativo e ha creato un ecosistema abbastanza articolato di moduli per gestire le più svariate attività e funzionalità dei sistemi operativi GNU/Linux.
Nell'illustrazione trovate l'evulozione delle famiglie dei Sistemi Operativi UNIX e UNIX-like.

*Image: Eraserhead1, Infinity0, Sav_vas - Levenez Unix History Diagram, Information on the history of IBM's AIX on ibm.com*
### System V init
È il modello di gestione dei daemon e del processo di boot creato per il sistema operativo UNIX System V del 1983. Esso è stato utilizzato in tutte (o quasi), le distribuzioni GNU/Linux fino al 2011. Sono disponibili svariate implementazioni del processo di "init", alcune sono più vecchie e scarne; mentre, altre si sono evolute aggiungendo nuove funzionalità, pur mantenendo la retrocompatibilità con le specifiche originali.
Riporto una lista non esaustiva delle implementazioni del System V init:
- initV
- initng
- runit
- launchd (Apple)
- upstart
- OpenRC
Oggi credo che l'unica implementazione valida e al passo con i tempi sia **OpenRC**, mentre le altre implementazioni sono antiquate e alcune non sono più supportate.
### OpenRC
OpenRC separa il codice di gestione del daemon dalla sua configurazione e per la precisione nella directory `/etc/init.d` si trova il codice, mentre le configurazioni sono nella directory `/etc/conf.d`.
Non esiste una GUI di gestione e va fatto tutto tramite CLI e file di configurazione. I comandi per utilizzare e gestire *OpenRC* sono:
- `openrc`: modifica il *runlevel* corrente
- `rc-update`: gestisce l'associazione dei daemon ai *runlevel*
- `rc-status`: mostra lo stato dei *daemon* presenti nel sistema
- `rc-service`: gestisce il singolo *daemon* (start, stop, etc.)
### systemd
Questa suite di applicazioni include e integra svariate funzionalità, tra cui:
- processo di init
- gestore dei login
- gestione dei log
- gestione della rete
- gestione delle sessioni utente
- bus di comunicazione di sistema
Noi ci occuperemo solo della parte relativa al processo di init e di visulizzazione dei log.
Vediamo brevemente come utilizzare systemd tramite la sua CLI:
- `systemctl list-units`: mostra i daemon e le altre risorse gestite da systemd
- `systemctl enable` e `systemctl disable`
- `systemctl start` e `systemctl stop`
- `systemctl status`
- `systemctl cat`: mostra la configurazione
- `systemctl list-dependencies`
- `systemctl daemon-reload`: ricarica le personalizzazione delle configurazioni per i daemon
- `journalctl`: mostra i log (`-u` specifica il daemon; `-k` mostra i log del kernel)
## Partition e filesystem
> Disk partitioning or disk slicing[1] is the creation of one or more regions on secondary storage, so that each region can be managed separately.[2] These regions are called partitions. It is typically the first step of preparing a newly installed disk, before any file system is created. The disk stores the information about the partitions' locations and sizes in an area known as the partition table that the operating system reads before any other part of the disk. Each partition then appears to the operating system as a distinct "logical" disk that uses part of the actual disk.
> --- [wikipedia](https://en.wikipedia.org/wiki/Disk_partitioning)
### Partition
In GNU/Linux sono supportati svariati tipologie di partizioni o meglio di *Partition Table*. In pratica quando abbiamo un disco vergine in cui vogliamo creare delle partizioni, prima dobbiamo creare una struttura dati che memorizza le informazioni relative alle partizioni. Questa struttura dati è chiamata *Partition Table* e il formato normalmente utilizzato è **GPT**, mentre in passato si utilizzava il formato **MBR**.
In GNU/Linux ci sono principalmente 2 applicazioni a riga di comando che gestiscono le partizioni:
- `fdisk` applicazioni storica, ma ancora utilizzata
- `parted` applicazione moderna, spesso utilizzata dalle interfacce grafiche e.g. gparted e KDE Partition Manager
### Filesystem
Una volta creato il nostro schema di partizioni è necessario formattarle per renderle utilizzabili dal Sistema Operativo. Sono supportate svariati formati e per alcuni esistono differenti versioni.
Lista dei principali (ne esistono molti altri) filesystem supportati:
- fat16 (legacy)
- fat32 (legacy)
- HPFS (legacy)
- NTFS
- Ext2 (legacy)
- Ext3 (legacy)
- Ext4
- BTRFS
- F2FS
- JFS
- XFS
Ogni tipo di filesystem ha le proprie applicazioni per la gestione e la formattazione. In generale queste applicazioni hanno uno schema di nomi simili, per rendere facile identificarle. L'applicazione che formatta un filesystem normalmente si chiama `mkfs.<type>` e quella che esegue il check della consistenza `fsck.<type>`, ma potrebbe non essere rispettata questa consuetudine sui nomi.
https://www.tecmint.com/find-linux-filesystem-type/
Sotto riporto una tabella comparativa dei filesystem supportati nativamente e in modo stabile da GNU/Linux.
| Caratteristiche | Ext2 | Ext3 | Ext4 | BTRFS | F2FS | JFS | XFS |
| --------------- | ---- | ---- | ---- | ----- | ---- | --- | --- |
| Anno di rilascio | 1993 | 2001 | 2008 | 2008 | 2013 | 1990 | 1994 |
| Dimensioni massime file | 16GB-2TB | 16GB-2TB | 16GB-16TB | 8EB-16EB | 3.94TB | 4PB | 8EB |
| Numero massimo di directory | 31998 | 31998 | illimitato | illimitato | illimitato | illimitato | illimitato |
| Dimensione massime filesystem | 2TB-32TB | 2TB-32TB | 1EB | 16EB | 16TB | 32PB | 8EB |
| Journaling | NO | SI | SI (eliminabile) | SI (con ridondanza) | SI (via checkpoint) | SI (solo metadati) | SI (solo metadati) |
| Consigliato per | | | pc general purpose | storage server | dispositivi NAND | macchine con scarse prestazioni | server performanti e gaming |
Il tipo di partizione più diffuso in GNU/Linux è Ext4, seguito da BTRFS per i NAS e gli "storage server".
#### Usare differenti partizioni e filesystem
Nei sistemi GNU/Linux è comune utilizzare differenti filesystem, principalmente per 2 motivi:
1. utilizzare il tipo di filesystem più indicato o performante per la tipologia di dati e utilizzo. Per esempio, uno "storage server" potrebbe avere un filesystem formattato in **Ext4** usato per il sistema operativo e un'altra partizione formattata in **BTRFS** per i dati e montata nella directory `/srv`.
2. evitare blocchi dei sistemi quando un filesystem si riempie. Pensate a un sistema che ha parecchi utenti e che ognuno di essi potrebbe salvare grandi quantitativi di dati nella propria *home folder*, se essa si trova sullo stesso filesystem del sistema operativo potremmo incorrere nel problem ache gli utenti esauriscono lo spazio e il sistema non sarebbe più in grado di funzionare correttamente. Al contrario, se avessimo un filesyste e una partizione dedicata per la *home direcotry* il problema avrebbe un impatto inferiore perché il sistema operativo avrebbe ancora lo spazio necessario per funzionare.
La combinazione delle partizioni e dei tipi di filesystem viene chiamata **partition scheme**. Ci sono infinite possibilità e variabili da tenere in considerazione, qui sotto riporto un esempio preso dalle raccomandazioni di RedHat per sistemi server.
| Directory | Type | Minimum Size |
|-----------|------|--------------|
| / | Ext4 | 250MB |
| /boot | Ext, FAT32 or vFAT | 250MB |
| /home | Ext4 or BTRFS | 100MB |
| /srv | Ext4 or BTRFS | depends by services hosted, usually GB or TB |
| /tmp | Ext4 | 50MB |
| /usr | Ext4 | 250MB |
| /var | Ext4 | 384MB |
| swap | swap | 2 time the amount of RAM, at least 4GB |
#### pseudo-Filesystem
In GNU/Linux esistono alcuni filesystem particolari, che non corrispondono a nessuna partizione del disco e si chiamano ***pseudo-filesystem***. Essi sono gestiti dalle *API* di alcuni software e servono per mostrare delle informazioni sotto forma di filesystem, ma i loro dati non sono presenti in alcuna partizione ed è il software che li crea e gestisce a risponderci.
Gli esempi principali sono il filesystem presente alle directory `/dev` e `/proc`:
- `/dev`: il kernel, e altri software di basso livello, creano questo pseudo-filesystem contenente tutti i dispositivi hardware presenti sul nostro computer. I file, otlre a rappresentare il dispositivo, possono essere utilizzati come riferimento al dispositivo stesso e.g.`/dev/sda1` rappresenta la prkma partizione del primo HDD.
- `/proc` è praticamente un'interfaccia testuale verso il kernel Linux! In questo filesystem troviamo le configurazioni del kernel attualmente in esecuzione e altri tipi di documentazione gestita direttamente dal kernel. Alcuni file sono in sola lettura, mentre altri possono essere modificati per cambiare il comportamento del kernel stesso. Inoltre, alcuni di questi file ci mostrano lo stato attuale dell'hardware del sistema rilevato dal kernel tramite appositi sensori e.g. `/proc/acpi/button/lid/LID0/state` contiene l'informazione se il monitor di un pc portatile è aperto o chiuso.
### Mount
Come visto nei capitoli iniziali, la struttura del filesystem è gerarchica... in GNU/Linux non esiste il concetto di **lettere di unità**! Tutti i filesystem sono dei volumi contenenti dati che vengono collegati a una directory presente nella gerarchia. Questo significa che una qualsiasi directory potrebbe essere fisicamente salvata su un filesystem e partizione differente, indipendentemente dalla posizione in cui la troviamo nella gerrchia. Questa cosa è molto potente, ma come la possiamo gestire?
Il comando `mount` permette di "montare" cioè collegare un filesystem a una directory. L'effetto del comando `mount` è temporaneo e dura fino al successivo riavvio della macchina. È anche possibile pre-configurare i filesystem da montare e le directory in cui montarle, questo viene fatto tramite le configurazioni presenti nel file `/et/fstab`. Oltre montare manualmente un filesystem è possibile smontarlo tramite il comando `umount`. La lista dei filesystem attualmente montati è presente nel file `/etc/mtab`.
Per gesitire gestire il mount dei filesystem abbiamo a disposizione i seguenti comandi:
- `mount`: monta un filesystem
- `umount`: smonta un filesystem precedentemente montato
Le configurazioni e lo stato attuale sono presenti nei seguenti file:
- `/etc/fstab`: configurazione dei filesystem
- `/etc/mtab`: stato attuale, questo file è in sola lettura NON andrebbe mai modificato!
## Networking
### Comandi base
### Server DNS
Lo scopo di un DNS è convertire gli FQDN in indirizzi IP e vice-versa. La prima operazione è quella principale e più importante dei DNS.
Cos'è un FQDN? Esso è un nome mnemonico che rappresenta in modo univoco una risorsa e sta per Fully Qualified Domain Name. Un FQDN è composto da più parti separate tra loro dal carattere "." e identifica un servizio o una macchina all'interno di una rete (computer, router, etc.).
#### Gerarchia e Delegazione
Gli FQDN seguono una gerarchia data dalle parti che ne compongono i nomi, per esempio *www.google.com* è composto da ".com" che ne è il TLD (Top Level Domain), da "google" che rappresenta il dominio di secondo livello (sono quelli normalmente acquistabili) e da un dominio di terzo livello o sub-domain che indica il servizio di cui vogliamo usufruire. Se li consideriamo come una gerarchia otteniamo un diagramma simile al seguente:
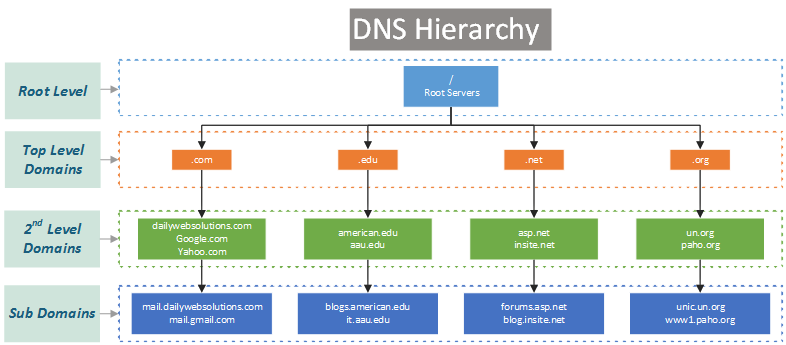
Quattro TLD sono stati riservati e non esiste alcun server pubblico che li gestisce, essi sono:
- `example`: riservato agli esempi
- `invalid`: riservato per l'uso in nomi palesemente invalid
- `localhost`: riservato per evitare il conflitto con l'uso tradizionale di localhost come hostname
- `test`: riservato ai test
Questa organizzazione gerarchica permette di sfruttare il concetto di **delegazione**, Non esiste alcun server in grado di risolvere direttamente tutti gli FQDN in indirizzi IP, ma ogni server conosce solo una piccola parte della rete e chiede ad altri server di risolvere gli FQDN che non conosce. Per la precisione, i server DNS di livello superiore conoscono i *nomi di dominio* di livello inferiore e l'indirizzo IP del server DNS in grado di risolve la seguente parte del FQDN.
In pratica quando chiediamo a un DNS Server di risolvere "www.google.com", vengono contattati più server e per la precisione:
1. root server: conosce ".com" e restituisce l'indirizzo IP del server che gestisce il TLD ".com";
2. ".com" server: conosce "google" e restituisce l'indirizzo IP del server che gestisce il dominio "google.com";
3. "google.com": conosce "www.google.com" e resituisce l'indirizzo IP del servizio indicato dal FQDN, in pratica risolvendo effettivamente l'indirizzo IP per il FQDN cercato.
Potenzialmente i "sub-domain" sono infiniti, quindi questo processo di risoluzione viene reiterato fino a quando non si risolve effettivamente l'indirizzo IP corrispondente al FQDN.
#### Reverse DNS
Abbiamo detto che lo scopo principale è quello di risolvere i DNS in indirizzi IP, ma i server DNS possono fare anche l'operazione opposta che prende il nome di **reverse DNS**. La risoluzione degli IP a partire dagli FQDN non è sempre disponibile e andrebbe utilizzata solo per resituire gli FQDNdella macchine e mai per restituire gli FQDN dei servizi. Il reverse DNS è molto importante nelle reti locali e a volte non viene configurato per le reti pubbliche, dato che vengono esposti dei servizi e non delle singole macchine. I concetti di gerarchia e di delegazione sono validi anche per i reverse DNS e tecnicamente sono applicabili.
Sotto trovate un diagramma in cui sono rappresentate graficamente le configurazioni DNS. In arancio sono rappresentati gli FQDN, mentre in blue gli indirizzi IP. Gli ovali rappresentano i DNS server, mentre i rettangolo gli host o i servizi.
Nell'esempio abbiamo un cluster di server (srv1 e srv2) che offrono il servizio web. Come potete notare sono registrati gli FQDN sia per il servizio "web" che per i nomi dei 2 server che lo offrono; mentre lato reverse non è presente il servizio "web", ma solo i nomi dei 2 server.

### BIND9 e NAMED
Per i sistemi GNU/Linux esistono differenti implementazioni di DNS server, ma la più utilizzata è **NAMED**, che implementa le specifiche **BIND9**.
Le configurazioni del server DNS avvengono tramite file di confgiurazione testuali ed esistono alcune primitive GUI, ma vengono poco utilizzate. Durante il corso vedremo solo la configurazione delle zone di tipo **master**, ma in realtà esistono altre funzionalità che non vedremo e le principali sono:
- replica zone su altri server che si comportano da **slave**;
- configurazione di zone come **slave** provenienti da altri server;
- gestione dinamica dei DNS integrata con il servizio DHCP;
- inter-operabilità con DNS Server di Microsoft (standalone e Domain Controller).
#### Tipologie di record
##### SOA
```
@ IN SOA test. root.test. (
2 ; Serial
604800 ; Refresh
86400 ; Retry
2419200 ; Expire
604800 ) ; Negative Cache TTL
```
Il primo record effettivo nel nostro file di zona di esempio, o in qualsiasi altro file di zona normale, è il record SOA, che ci indica lo Start Of Authority del dominio. È anche il tipo di record più confuso dell'intero sistema DNS. Per qualsiasi record, compreso questo record SOA, il primo argomento è il nome dell'host a cui si applica il record, in questo caso "@" che indica *l'origine* corrente e che per noi è vuota perché stiamo configurando una zona TLD.
L'argomento successivo è IN, abbreviazione di "Internet". Questa è la classe di record. Esistono altre classi di record DNS, ma si può facilmente passare l'intera carriera senza vederne una (come CH, per Chaos) in produzione. La classe del record è facoltativa; se viene omessa, BIND assume che il record specificato sia di classe IN. Si consiglia di non ometterlo, tuttavia, per evitare che qualcosa cambi e che tutti i file di zona si rompano improvvisamente dopo un aggiornamento di BIND!
I due argomenti successivi sono FQDN, o almeno così sembrano. Il primo FQDN è davvero un FQDN e dovrebbe essere l'FQDN del server dei nomi primario per il dominio stesso, in questo caso semplicemente **`test.`**. Si noti che si possono usare nomi di host non terminati dal caratter "**.**", ma è meglio essere espliciti.
Il secondo FQDN, `root.test.` non è in realtà un FQDN. È invece un modo perverso di riscrivere un indirizzo e-mail. "**@**" è un carattere riservato nei file di zona e il BIND originale utilizza la prima sezione di questo "FQDN" come la parte utente di un indirizzo e-mail, quindi si tradurrebbe nell'indirizzo `root@test`. È incredibilmente comune vedere questo errore nei file di zona reali, ma fortunatamente non ha molta importanza. Non siamo a conoscenza di nessuno che utilizzi questa caratteristica di una zona DNS per contattare qualcuno.
Proseguendo, abbiamo seriale, refresh, retry, expire e TTL negativo per la zona all'interno di parentesi. Si noti che i commenti che si vedono qui, che li etichettano, non sono obbligatori e nella vita reale si vedranno raramente. Preferiamo fortemente inserire questi commenti nei file di zona di produzione per facilitarne la lettura, ma a BIND non importa!
- **serial**: è un semplice numero di serie per il file di zona, che deve essere incrementato ogni volta che il contenuto della zona viene modificato. Se non si aggiorna il seriale del file di zona, le modifiche apportate alla zona non verranno rilevate dai resolver DNS che hanno precedentemente memorizzato nella cache i record della zona! In passato il formato era YYMMDDnn, ma ora non è più richiesto e in alcuni casi nemmeno supportato. Iniziate le vostre zone con il numero 1, aumentate a 2 la volta successiva che apportate una modifica alla zona e così via.
- **refresh**: dopo questo periodo di tempo, i server dei nomi secondari devono interrogare il server dei nomi primario per questo record SOA, per rilevare i cambiamenti nel numero di serie. Se il numero di serie è aumentato, tutti i record memorizzati nella cache devono essere invalidati e recuperati nuovamente dal server dei nomi primario.
- **retry**: se il nameserver primario non risponde a una richiesta SOA, un nameserver secondario deve attendere questo tempo prima di tentare di interrogare nuovamente il nameserver primario.
- **expire**: se il nameserver primario non ha risposto alla richiesta SOA di un nameserver secondario per questo periodo di tempo, il nameserver secondario deve smettere di offrire la risoluzione DNS per il dominio.
- **negative caching TTL**: controlla per quanto tempo deve essere memorizzata nella cache una risposta "negativa", ad esempio "non ho il record che stai chiedendo".
##### NS
```
@ IN NS localhost.
```
In questo record vengono definiti gli hostname, che sono i nameserver autoritativi per la nostra zona. Solitamente vengono utilizzati almeno 2 record NS differenti e appartententi a reti distinte, questo per garantire alta affidabilità e disponibilitàdel servizio DNS. Ancora una volta, abbiamo usato FQDN con terminazione a punti per questo record. Ancora una volta, avremmo potuto usare nomi di host non terminati - `ns1` - e affidarci al nostro $ORIGIN per espanderli. In questo modo, però, la zona sarebbe stata più confusa e difficile da leggere.
Si noti che il record NS specifica i nomi di host, non gli indirizzi IP. Questa è una fonte comune di confusione per i neofiti del DNS ed è importante che sia corretta. Non è possibile specificare un indirizzo IP come nameserver di un dominio; è assolutamente necessario specificare un nome host.
Infine, notate che non abbiamo specificato il nome del dominio in nessuna delle due righe, perché lo abbiamo ereditato dal record SOA precedente. Abbiamo iniziato la riga con "**@**", che si espande in `test.` Poiché non abbiamo specificato un altro nome host, questi nuovi record NS si applicano anche a quel nome host per impostazione predefinita.
##### A
```
web IN A 10.0.10.1
web IN A 10.0.10.2
web1 IN A 10.0.10.1
web2 IN A 10.0.10.2
```
I record A sono la parte di un file di zona che fa effettivamente ciò che la maggior parte delle persone pensa che il DNS faccia: traduce un nome host in un indirizzo IPv4 nudo.
In questo caso, si tratta solo di un file di esempio, e il nostro record A per `web1.test` risolve semplicemente a `10.0.10.1`, secondo lo stesso principio per cui i numeri di telefono nei film iniziano sempre con il numero 555. Nella vita reale, ovviamente, si inserisce l'indirizzo IP del server che si prevede risponda quando si effettua un ping su `web1.test`, si punta un browser Web su `https://web1.test/` e così via.
In questo semplice file di zona, abbiamo 2 record record A per `web.test`. Nella vita reale, è comune avere diversi record **A** per lo stesso FQDN: potrebbero esserci più server gateway in grado di rispondere alle richieste Web per `https://web.test/`; in tal caso, ognuno di essi avrebbe il proprio record A sulla propria riga.
##### PTR (reverse lookup PoinTeR)
```
1 IN PTR web1.test.
```
I record **PTR** semplicemente traducono gli indirizzi **IP** nei corrispettivi **FQDN**. In questo caso, si tratto solo di un esempio, il nostro record **PTR** per l'indirizzo **IP** `1` risolve a `web1.test`. Questo esempio apparentemente non ha alcun senso, perché il valore "1" non è un indirizzo **IP** valido! In realtà **BIND9** completa l'indirizzo con quello definito nel file delle zone, che nel nostro caso dovrebbe essere `10.0.10`, quindi l'indirizzo completo sarà `10.0.10.1` che viene risolto come `web1.test`.
##### MX
Nel nostro esempio non abbiamo configurato record di questo tipo.
```
IN MX 10 mail.test.
```
In questo semplice dominio, abbiamo un solo mailserver, che è `mail.test`. Il record MX indica semplicemente a chiunque voglia inviare e-mail a qualsiasi indirizzo di `test` di effettuare la connessione SMTP al nome host specificato in questo record.
L'argomento precedente, 10 in questo caso, è la priorità numerica del server di posta in questo specifico record. Numeri più bassi significano priorità più alta. Quando per un dominio sono disponibili più server SMTP, si vedranno anche più record MX, ciascuno con una priorità diversa. In teoria, i server di posta elettronica a priorità più alta dovrebbero essere sempre provati per primi e quelli a priorità più bassa solo se il server a priorità più alta fallisce.
I server SMTP ben educati seguono questo protocollo, ma gli spammer tendono a colpire deliberatamente i server di posta a priorità più bassa, partendo dal presupposto che i server ad alta priorità potrebbero essere gateway anti-spam e quelli a priorità più bassa potrebbero essere i server finali nudi e non filtrati. Gli spammer sono brutte persone!
##### TXT
Nel nostro esempio non abbiamo configurato record di questo tipo.
```
IN TXT "v=spf1 a mx a:mail.test a:web.test ?all"
```
In un record TXT (o record di testo), si può inserire praticamente qualsiasi cosa; questo specifico record è un record SPF, formattato per fornire ai mailserver informazioni su quali macchine sono autorizzate a emettere posta per conto di `test`.
In questo caso, stiamo dicendo che stiamo usando la versione SPF1 della formattazione. Informiamo quindi chiunque interroghi questo record che qualsiasi record A valido per `test` è autorizzato a inviare posta a suo nome, così come qualsiasi MX valido per il dominio, e infine che gli indirizzi IP associati ai record **A** per `mail.test` e `web.test` sono autorizzati a inviare posta. Infine, tutto ciò dice che se un'altra macchina dice di voler inviare posta da un indirizzo di `test`, dovrebbe essere autorizzata... ma dovrebbe essere esaminata più attentamente di quanto non lo siano gli host specificamente autorizzati.
#### CNAME (Canonical NAME)
Nel nostro esempio non abbiamo configurato record di questo tipo.
```
www IN CNAME web.test.
```
L'ultimo tipo di record che vediamo è CNAME, abbreviazione di Canonical Name. Si tratta di un alias che consente di dire a BIND di risolvere sempre le richieste per l'host **CNAME** utilizzando il record **A** o **AAAA** specificato nell'argomento target. In questo caso significa che l'indirizzo IP di `web.test` deve essere fornito se qualcuno chiede `www.test`.
I record CNAME sono comodi, ma sono un po' strani. Vale la pena ricordare che ogni livello di **CNAME** richiede un'altra ricerca DNS: in questo caso, a una macchina remota che chiedesse di risolvere `www.test` verrebbe detto "per favore cerca `web.test.` per trovare la risposta", e quindi dovrebbe fare una richiesta DNS separata per il record **A** associato a `web.test`. Se avete **CNAME** che puntano a **CNAME** che puntano a **CNAME**, introdurrete una latenza non necessaria nelle richieste delle vostre risorse e il vostro dominio apparirà "lento" e "laggoso" agli utenti!
I record **CNAME** presentano ulteriori limitazioni. Ricordate che vi abbiamo detto che i record **MX** e **NS** devono puntare a nomi di host, non a indirizzi **IP** grezzi? Più precisamente, devono puntare direttamente ai record **A**, non ai record **CNAME**.
#### Configurazione di base
I file di configurazione principali di bind9 sono nella directory `/etc/bind` e per la precisione sono:
- `named.conf`: normalmente non contiene alcuna configurazione e si limita a includere gli altri file di configurazione;
- `named.conf.options`: contiene le configurazioni generali e generiche del server e.g. forwarders o abilitazione di IPv6;
- `named.conf.default-zones`: contiene la configurazione delle zone dei default gestite da un DNS server, che solitamente non richiedono di essere modificate. Le zone di default riguardano il dominio *localhost* e i reverse *127*, *0* (all addresses) e *255* (subnet mask);
- `named.conf.local` che contiene la definizione delle zone e il riferimento al relativo file di configurazione;
- `db.*`: sono 1 o più file che contengono i record DNS di ogni zona e i dati di configurazione della stessa.
Credo che la cosa migliore per spiegare la configurazione sia partire da un esempio! Considerate la seguente gerarchia di domini in cui abbiamo come TLD il dominio *test* e sotto il quale è direttamente presente alcuni record di secondo livello chiamati *web*, *web1* e *web2*, oltre a un sotto-dominio chiamato *ttf*.

:::warning
In una qualsiasi zona è possibile avere record per host (o servizi) e altri sotto-domini.
:::
1. partiamo dalla definizione della zona a livello più alto della gerarchia, nel nostro caso **test**:
- aggiungiamo la definizione della zona nel file `named.conf.local`
```
zone "test" {
type master;
file "/etc/bind/db.test";
}
```
per convenzione chiamiamo il nome del file contenente i record con il nome `db.test`, potremmo chiamarlo liberamente, ma per convenzione si usa *db* seguito dal nome della zona stessa
- a questo punto dobbiamo creare il file `/etc/bind/db.test` contenente le configurazioni e i record della zona
```
$TTL 604800
@ IN SOA test. root.test. (
2 ; Serial
604800 ; Refresh
86400 ; Retry
2419200 ; Expire
604800 ) ; Negative Cache TTL
;
@ IN NS localhost.
```
di base stiamo definendo un record di tipo **SOA (Start Of Authority)** con cui definiamo la zona corrente e le sue impostazioni! Di seguito specifichiamo a quale DNS Server è delegata la gestione di quella zona e nel nostro caso sarà *localhost* perché vogliamo gestirla localmente
- infine aggiungiamo al file i record di tipo **A (Address Mapping)** presenti nella zona *test* presenti in figura
```
web IN A 10.0.10.1
web IN A 10.0.10.2
web1 IN A 10.0.10.1
web2 IN A 10.0.10.2
```
2. procediamo definendo la zona di reverse per gli indirizzi `10.0.10.x`
- aggiungiamo la definizione della zona nel file `named.conf.local` prestanto particolare attenzione all'ordine degli ottetti dell'indirizzo... ***essi devono comparire in ordine inverso!!!*** In questo caso si scrive uguale anche invertendo l'ordine. Le reverse-zone terminano sempre con il suffisso `in-addr.arpa`, non dimenticatelo!
```
zone "10.0.10.in-addr.arpa" {
type master;
file "/etc/bind/db.10.0.10";
};
```
- adesso possiamo creare il file `/etc/bind/db.10.0.10` con la configurazione base della zona
```
$TTL 604800
@ IN SOA test. root.test. (
1 ; Serial
604800 ; Refresh
86400 ; Retry
2419200 ; Expire
604800 ) ; Negative Cache TTL
;
@ IN NS localhost.
```
- infine definiamo i record di tipo **PTR (reverse lookup PoinTeR)**
```
1 IN PTR web1.test.
2 IN PTR web2.test.
```
mi raccomando fate attenzione agli ottetti degli indirizzi IP che devono essere invertiti, dato che siamo in un reverse-zone.
:::info
Prestate attenzione al carattere ". (punto)"!!! Essi non sono messi in modo casuale alla fine dei nomi di dominio, ma hanno un senso ben preciso: la presenza del "." indica un FQDN, mentre la sua assenza un nome di sotto-dominio che viene automaticamente completato con il nome della zona stessa. Se nell'esempio predente di reverse avessimo omesso il "." avremmo come FQDN il valore *web1.test.10.0.10.in-addr.arpa* che è palesemente sbagliato!
:::
#### Esempio completo
Completando l'esercizio rappresentato nella figura sopra dovremmo ottenere le seguenti configurazioni o qualcosa di molto simile. Per comodità sotto riporto i file completi:
- **named.conf.local**
```
zone "test" {
type master;
file "/etc/bind/db.test";
};
zone "ttf.test" {
type master;
file "/etc/bind/db.test.ttf";
};
zone "10.0.10.in-addr.arpa" {
type master;
file "/etc/bind/db.10.0.10";
};
zone "20.0.10.in-addr.arpa" {
type master;
file "/etc/bind/db.20.0.10";
};
```
- **db.test**
```
$TTL 604800
@ IN SOA test. root.test. (
2 ; Serial
604800 ; Refresh
86400 ; Retry
2419200 ; Expire
604800 ) ; Negative Cache TTL
;
@ IN NS localhost.
web IN A 10.0.10.1
web IN A 10.0.10.2
web1 IN A 10.0.10.1
web2 IN A 10.0.10.2
```
- **db.test.ttf**
```
$TTL 604800
@ IN SOA test. root.test. (
2 ; Serial
604800 ; Refresh
86400 ; Retry
2419200 ; Expire
604800 ) ; Negative Cache TTL
;
@ IN NS localhost.
web IN A 10.0.10.1
web IN A 10.0.10.2
web1 IN A 10.0.10.1
web2 IN A 10.0.10.2
```
- **/etc/bind/db.10.0.10**
```
$TTL 604800
@ IN SOA test. root.test. (
1 ; Serial
604800 ; Refresh
86400 ; Retry
2419200 ; Expire
604800 ) ; Negative Cache TTL
;
@ IN NS localhost.
1 IN PTR web1.test.
2 IN PTR web2.test.
```
- **/etc/bind/db.20.0.10**
```
$TTL 604800
@ IN SOA ttf.test. root.ttf.test. (
1 ; Serial
604800 ; Refresh
86400 ; Retry
2419200 ; Expire
604800 ) ; Negative Cache TTL
;
@ IN NS localhost.
1 IN PTR srv1.ttf.test.
2 IN PTR srv2.ttf.test.
```
### Firewall
I firewall sono una parte estremamente importante nella sicurezza informatica e un argomento abbastanza ostico. In un sistema GNU/Linux le "funzionalità" normalmente presenti in un generico firewall sono incorporate direttamente nel kernel, ma per sfruttarle è necessario utilizzare degli strumenti estermi che ne permettono la configurazione e l'organizzazione delle regole e logiche di un firewall. Nel kernel linux esistono un gran numero di funzionalità relative ai firewall e i questi moduli sono raccolti dal progetto "**netfilter**". Lato utente esistono svariati tool che consentono l'impostazione e la configurazione dei moduli *netfilter* del kernel e i principali sono:
- **ipchains**: strumento legacy e oggi poco utilizzato;
- **iptables**: oggi è lo strumento più utilizzato direttamente o indirettamente. Esistono alcuni strumenti che si appaggiano su iptables;
- **ufw (Uncomplicate FireWall**: è uno strumento molto utilizzato e sostanzialmente è un gestore di regole di **iptables**, nato con lo scopo di semplificarne l'uso. Oltre all'interfaccia a riga di comando esistono delle GUI;
- **nftables**: il più nuovo tra gli strumenti presenti e che potrebbe sotituire **iptables** in futuro.
In questo corso noi ci concentreremo su **iptables**, dato che è lo standard de-facto e la base per altri strumenti come *ufw*.
#### iptables: rules, chains e tables
Per chi si approccia a **iptables** esiste uno scoglio iniziale per comprendere come sono strutturati alcuni concetti base, ma questa confusione può essere superata con alcuni esempi pratici.
I concetti base sono 3:
- **rules**: un construtto che dice cosa accade se un pacchetto rispetta un determinato pattern;
- **chains**: catene contenenti le regole. Le regole all'interno di una catena vengono eseguite in modo sequenziale e quando una pacchetto trova corrispondenza in una regola, essa viene applicata e nessun altra regola verrà valutata. Esistono differenti catene in base alla loro applicazione e.g. traffico in ingresso locale, traffico in transito verso altra rete, etc.
- **tables**: anche le tabelle sono una raccolta di regole e qui nasce un sacco di confusione! pensate alle tabelle come una raccolta di regole dello stesso tipo e.g. regole di NAT, regole di filtraggio, etc.
Sostanzialmente le **chains** indicano quando una regola viene applicata, mentre le **tables** indicano la tipologia della regola. Per ogni tipologia di regola possiamo definire comportamente differenti e sfruttare i moduli che kernel corrispondenti. Per esempio, una regola di *filter* non potrà reindirizzare un indirizzo IP o una porta TCP, perché questa è una regola tipica di *nat (Network Address/port Translator*. In *iptables* esiste una tabella apposita per le regole di *nat* e ovviamente in quella tabella potremmo solo inserire regole specifiche per quel tipo di operazione.
La configurazione delle regole viene fatta a livello di tabella, in pratica noi aggiungiamo all'interno di una tabella, una regola che compone la *chain* desiderata. Il comando `iptables` se lanciato senza specificare una tabella utilizza quella di default che è la tabella *filter*. Sotto eseguo il comando `iptables` con l'opzione `-L` che restituisce l'elenco delle regole presenti nella tabella, raccolte per *chains* e alcuni dati aggiuntivi in accordo con le impostazioni di visualizzazione inserite `-v -n`.
```
fw:~# iptables -L -v -n
Chain INPUT (policy DROP 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
0 0 ACCEPT tcp -- * * 0.0.0.0/0 0.0.0.0/0 tcp dpt:22
0 0 ACCEPT tcp -- eth1 * 0.0.0.0/0 0.0.0.0/0 tcp dpt:443
0 0 ACCEPT all -- * * 0.0.0.0/0 0.0.0.0/0 state RELATED,ESTABLISHED
Chain FORWARD (policy DROP 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
0 0 ACCEPT tcp -- * * 0.0.0.0/0 10.0.0.100 tcp dpt:443
0 0 ACCEPT all -- * * 0.0.0.0/0 0.0.0.0/0 state RELATED,ESTABLISHED
Chain OUTPUT (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
```
Se volessimo visualizzare (o manipolare), una tabella differente da *filter* dobbiamo specificarla con l'opzione `-t`, come in esempio `iptables -t nat`.
```
fw:~# iptables -t nat -L -v -n
Chain PREROUTING (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
0 0 DNAT tcp -- eth0 * 0.0.0.0/0 0.0.0.0/0 tcp dpt:443 to:10.0.0.100
Chain INPUT (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain OUTPUT (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain POSTROUTING (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
0 0 MASQUERADE all -- * eth0 0.0.0.0/0 0.0.0.0/0
```
Come si può notare, ogni tabella al suo interno contiene delle *chains* e all'interno di queste sono presenti le *rules*. Alcune *chain* sono presenti in più tabelle e questa è una cosa normale! Pensata alle *chain* come un raggruppamento logico delle regole che ne definisce l'ordine globale di esecuzione. La differenza più evidente che notiamo sono i *"target"* che nella tabella di *filter* sono **DROP**, mentre nella tabella di *nat* troviamo **DNAT** e **MASQUERADE**. Questi sono solo degli esempi, ma in generale, i *target* disponibili cambiano da tabella a tabella. I *target* di una regola definiscono l'operazione che deve essere applicata a un pacchetto che corrisponde alla condizione che la fa scattare.
Esistono svariate rappresentazioni dell'ordine di esecuzione delle regole presenti nelle *chains* e nelle *tables*, ma alla fine tutti raccontano in la stessa storia. Storiacamente il diagramma più utilizzato è quello riportato immediatamente sotto ed è nato per essere stampato sui libri in B/N.

Qui sotto trovate una versione con le *tables* colorate in modo coerente e raccolte nelle *chains* presenti nel sistema. Questa versione è quella che normalmente uso a lezione e spero sia leggermente più chiara della precedete.

**Riassumendo:** a livello logico le *rules* sono raccolte in *chains* ed eseguite nell'ordine in cui sono scritte e sono raggruppate in *tables* in base alla tipologia di regola. A livello pratico quando usiamo il comando `iptables` agiamo sulle *rules* presenti in una determinata *tables* e vediamo le *chains* come un raggruppamento di regole.
:::warning
Quando un pacchetto trova corrispondenza in una *rules*, viene applicato il **target** definito e non vengono valutate le successive regole per la *table* nella *chain* in esame. Vengono valutate normalmente le *rules* presenti nella successiva *table* della *chain* corrente e anche tutte le *rules* presenti in *chains* successive.
:::
Definiamo brevemente le *tables* e la tipologia di *rules* presenti in ognuna di esse:
- **filter:** in questa tabella vengono definite le regole di filtraggio dei pacchetti, sostanzialmente si definisce quali pacchetti sono leciti e quali no! I *target* per le regole presenti sono `ACCEPT`, `DROP` e `REJECT`.
- **nat:** questa tabella serve per modificare gli indirizzi IP o le porte TCP/UDP dei pacchetti e si applica sia sulle destinazioni che le sorgenti. I *target* per le regole sono `SNAT (Source-NAT)`, `DNAT (Destination-NAT)`, `MASQUERADE` e `REDIRECT`.
- **mangle:** serve per manipolare i gli header dei paccheti, per esempio cambiare il loro "Type of Service", il "TTL", etc. Non viene usata spesso, quindi non entreremo nei dettagli di questa tabella.
- **raw:** serve per manipolare l'intero contenuto dei pacchetti che transitano. Tramite questa tabella possiamo fare realmente quasi qualsiasi cosa! Viene usata molto raramente, quindi non entreremo nei dettagli di questa tabella.
Per quanto riguarda le *chains* credo non sia necessario elencarle, dato che il loro nome è intuitivo e dal disegno sopra è facile identificare quando intervengono. Notate che in una *chain* possono essere presenti due o più *tables*, ma che nessuan *table* è presente in tutte le `chains`.
Il firewall *netfilter* è nativo nel kernel linux e si integra con altri servizi e funzionalità del kernel come il *routing*. Quando scriviamo le regole del firewall dobbiamo sempre tenere a bene a mente lo schema sopra che rappresenta, a livello logico, i flussi dei pacchetti e le *chains* e le *tables* da essi attraversati. Innanzitutto potremmo distinguire in 2 macro-casistiche:
1. pacchetti diretti/provenienti da servizi locali;
2. pacchetti che devono essere instadati da una interfaccia di rete a un'altra.
Il servizio di *routing* si integra con *netfilter* e in base alle scelte effettuate in fase di **routing** i pacchetti possono attraversare differenti *chains* e tramite l'applicazione di alcune *rules* di **netfilter** potremmo influenzare le scelte del componente di *routing*.
Grazie a *iptables* e *netfilter* possiamo creare anche delle *custom chain* a nostro piacimento e alcuni strumenti come **ufw** ne fanno ampio uso. In questo corso non trattiamo le *custom-chain* e ci limitiamo a sfruttare le *default-chain* offerte dal sistema.
#### Policy di default e flush
Una cosa molto importante è la possibilità di impostare una *default policy* per ogni *chain* presente in una *table*. Come *default policy* esistono solo 2 impostazioni di base: `ACCEPT` e `REJECT`.
:::info
Se non modificata la *default policy* è sempre `ACCEPT`
:::
Come detto sopra possiamo modificare la *default policy* per ogni *chain* presente in ogni *table*, ma questo ha poco senso, anche se tecnicamente possibile! Configurare una *default policy* a **DROP** significa scartare tutti i pacchetti che entrano in quella *chain* a meno che non siano espressamente accettati dalle regole di filtraggio definite dalla *chain*/*table* in questione. Il **DROP** ha senso solo per la *filter table*, perché solo in essa abbiamo la possibilità di definire le regole di filtraggio per i pacchetti con il *target* **ACCEPT**; mentre, nelle altre tabelle ci è impossibile utilizzare il *target* **ACCEPT**.
:::warning
La *default policy può essere **DROP** solo nella *filter table*, se messa a **DROP** in altre *tables* blocchiamo tutto il traffico che passa in quella *chain*.
:::
Possiamo modificare la *default policy* con il seguente comando: `iptables [-t <table>] -P <default value> <chain>`. Per esempio, se volessimo scartare tutto il traffico in forward `iptables -P DROP FORWARD`.
Un'altra azione utile da eseguire è quella di cancellare tutte le regole presenti in una *table* o in una singola *chain* di una *table*. In gergo informatico tale operazione si chiama *flush* e la possiamo eseguire con il seguente comando: `iptables [-t <table>] -F [<chain>]`. Per esempio se volessimo cancellare tutta la *nat table* `iptables -t nat -F`.
Una funzionalità che a volte può risultare utile sono i **counter** che ci offre in automatico *iptables* e che possiamo resettare in ogni momento. Questi counter ci dicono quanti pacchetti e quanti byte sono affetti da una particolare regola. Possiamo eseguire il reset dei counter seguente comando: `iptables [-t <table>] -Z [<chain>]`. Per esempio se volessimo farlo sulla *postrouting chain* della *nat table* `iptables -t nat -Z POSTROUTING`.
#### Permettere il traffico in uscita generato da locale
Prendiamo in considerazione un semplice caso d'uso: dalla macchina che fa da firewall vogliamo poter accedere alla rete Internet in modo libero, senza alcuna limitazione, ma il traffico in entrata è bloccato dalla *default policy* che è **DROP**.
In questo caso sembra che non ci sia nulla da fare, ma in realtà non è così! Per quanto riguarda la `filter table` della `output chain` lasciamo la *default policy* in **ACCEPT**, ma come impostiamo a **DROP** del *default policy* della `input chain` smettiamo di comunicare con Internet.
Qui la configurazione:
```
iptables -P INPUT DROP
iptables -P OUTPUT ACCEPT # non necessario, lo riporto solo per completezza
```
Andando a vedere lo schema sopra riportato e cercando di percorrere il percorso dei pacchetti ci rendiamo conto che:
- i pacchetti escono verso Internet perché non vi è alcuna regola che li blocca e la *default policy* è **ACCEPT**;
- i pacchetti di risposta da Internet verso il firewall stesso vengono bloccati dalla *default policy* della `input chain` che è **DROP**.
Bisogna sempre prestare attenzione sia al percorso di *"andata"* che a quello di *"ritorno"* dei pacchetti! Errore comune è considerare sola il percorso di andanta, dando per scontato che i pacchetti possano anche *"ritornare"* magicamente. Purtroppo in un firewall non esistono cose magiche, ma solo `rules` che permettono o meno il passaggio dei pacchetti. In questa cosa non possiamo scrivere una regola specifica per aprire il traffico da una particolare porta o indirizzo IP, ma dobbiamo sfruttare lo stato delle connessioni. Quello che possiamo fare è permettere il traffico in entrata per le connessioni che sono in qualche modo correlate a delle connessione già instaurate in modo lecito. Ci vengono in aiuto 2 differenti moduli di *netfilter* che valutano lo stato delle connessioni e che possiamo utilizzare come condizione per accettare alcuni flussi di pacchetti. I moduli in questione sono:
- **state:** si limita a verificare lo stato della connessione dichiarato all'interno dei pacchetti del protocollo IP. Questo modulo è abbastanza datato e soggetto ad alcuni attacchi mirati proprio a ingannarlo e per questo motivo sarebbe meglio non utilizzarlo. Nelle versioni recenti del kernel il problema non si pone perché il modulo *state* è stato rimosso e se proviamo a utilizzarlo in automatico viene utilizzato il modulo *conntrack*;
- **conntrack:** il suo comportamento è simile a quello del modulo *state*, ma in aggiunta tiene traccia di tutte le connessioni in uscita, ingresso e forward sul firewall. In questo modo non può essere ingannato, perché di accerge se i pacchetti fanno realmente parte di una connessione precedentemente instaurata e non si basa solo sullo stato dichiarato dal pacchetto che viene preso in esame.
```
iptables -P INPUT DROP
iptables -P OUTPUT ACCEPT # non necessario, lo riporto solo per completezza
iptables -A INPUT -m conntrack --ctstate ESTABLISHED,RELATED -j ACCEPT
```
#### Permettere il traffico in ingresso con destinazione locale
Prendiamo in considerazione un semplice caso d'uso: sulla macchina è presente un server **ssh** e vogliamo accettare il traffico a esso diretto quando la *default policy* è **DROP**.
In questo caso dobbiamo effettivamente aprire la porta 22 (ssh) in ingresso sul firewall stesso. Se manteniamo la *default policy* della *output chain* in **ACCEPT** non è necessario creare alcuna regola per abilitare il traffico di ritorno verso il client ssh.
```
iptables -P INPUT DROP
iptables -P OUTPUT ACCEPT # non necessario, lo riporto solo per completezza
iptables -A INPUT -p tcp --dport 22 -j ACCEPT
```
:::warning
Il concetto di *port* appartiene ai protocolli di livello 4 dello stack ISO/OSI, quindi dobbiamo specificare a quale protocollo vogliamo applicare la regola. Normalmente i protocolli di livello 4 che usano le porte sono **TCP** e **UDP**, in questo modo possiamo filtrare non solo la *port*, ma anche il *protocol* della connessione.
:::
Potremmo rendere la regola più restrittiva accettando solo le nuove connessioni, quelle con *ctstate NEW*. Se lo facessimo però dovremmo considerare i pacchetti successivi al primo che avranno uno stato differente da *NEW*. In tal caso potremmo raffinare le regole in questo modo sfruttando il modulo *conntrack*:
```
iptables -P INPUT DROP
iptables -P OUTPUT ACCEPT # non necessario, lo riporto solo per completezza
iptables -A INPUT -m conntrack --ctstate ESTABLISHED,RELATED -j ACCEPT
iptables -A INPUT -p tcp --dport 22 -m conntrack --ctstate NEW -j ACCEPT
```
Spesso si specifica lo stato delle connessioni, perché in modo semplice possiamo rendere la configurazione più robusta e meno soggetta ad attacchi specifici che sfruttano gli stati delle connessioni per violare il sistema.
#### Inoltro del traffico in uscita da un'interfaccia a un'altra
Prendiamo in considerazione un caso d'uso molto diffuso, in cui abbiamo un firewall a protezione di una rete locale composta da computer client. In questa tipologia di rete rientrano le reti domestiche, quella della scuola stessa e molte reti aziendali in cui non sono presenti server accessibili da Internet.
In questo caso abbiamo la rete Internet sulla scheda di rete `eth0` del firewall e la rete locale sulla `eth1`. Tutti i computer della rete locale devono poter accedere liberamente a Internet, mentre in ingresso da Internet è consentito solo il traffico relativo alla connessioni originate dalla rete locale.
Proviamo a pensare ai flussi di traffico basandoci sui diagrammi sopra presentati:
1. il traffico generato da *eth1* deve essere accettato, in questo modo può uscire verso Internet tramite *eth0*;
2. l'indirizzo sorgente di tali pacchetti è un indirizzo privato della rete locale ed esso non può essere raggiungibile tramite Internet, di conseguenza è necessario modificare l'indirizzo IP sorgente con quello dell'interfaccia *eth0* che ha un indirizzo raggiungibile da Internet;
3. dobbiamo abilitare il traffico in risposta che deve entrare nel nostro firewall ed essere consegnato al cilent che ha originato le richiesta.
```
# eth0 -> Internet
# eth1 -> LAN
iptables -P FORWARD DROP
iptables -A FORWARD -i eth1 -j ACCEPT # punto 1
iptables -A FORWARD -o eth1 -m conntrack --ctstate ESTABLISHED,RELATED -j ACCEPT # punto 3
iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE # punto 2
```
:::warning
In questo caso è molto comodo ragionare sulle interfacce di rete e in `iptables` possiamo usare le opzioni **-i** per indicare quella di ingresso e **-o** per quella di uscita.
:::
La prima regola permette in forward tutto il traffico entrante dalle scheda *eth1*, la seconda permette tutto il traffico in forward che esce sulla scheda *eth1* a patto che sia correlato a connessioni già esistenti. L'ultima regola è una sintassi adottata nei casi in cui dobbiamo fare **nat** di tutto il traffico senza modificare le porte e usando l'indirizzo IP principale della scheda di uscita, esattamente come nel nostro caso!
Potremmo scrivere lo stesso set di regole in un modo più stringente specificando gli stati e le schede sia di ingresso sia di uscita. In questo caso è necessaria una regola aggiuntiva per soddisfare il punto 1.
```
# eth0 -> Internet
# eth1 -> LAN
iptables -P FORWARD DROP
iptables -A FORWARD -i eth1 -o eth0 -m conntrack --ctstate NEW -j ACCEPT # punto 1
iptables -A FORWARD -i eth1 -o eth0 -m conntrack --ctstate ESTABLISHED,RELATED -j ACCEPT # punto 1
iptables -A FORWARD -i eth0 -o eth1 -m conntrack --ctstate ESTABLISHED,RELATED -j ACCEPT # punto 3
iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE # punto 2
```
:::danger
Quando abbiamo più di 2 schede di rete è necessario specificare entrabe le schede - ingresso e uscita - per evitare delle ambiguità nelle regole di forward! Valutate bene i casi e considerate di fare un disegno ordinato della vostra rete e dei flussi di pacchetti consentiti e vietati!
:::
#### Inoltro del traffico in ingresso da un'interfaccia a un'altra
In questo caso d'uso abbiamo un server nella rete locale che deve essere raggiungibile da Internet, per esempio sulla porta 443. Siamo di fronte a un tipico web server che "hosta" un sito aziendale.
Proviamo a pensare ai flussi di traffico basandoci sui diagrammi sopra presentati:
1. il traffico generato da *eth0* deve essere accettato solo se la porta di destinazione è la 443 e l'indirizzo di destinazione quello del nostro web server;
2. la destinazione del traffico in ingresso da Internet sulla porta 443 deve essere inoltrato verso l'indirizzo IP privato del server in LAN, quindi tramite *iptables* dobbiamo modificare il comportamento del routing dei pacchetti;
3. per le risposte provenienti del web server sulla rete locale deve essere possibile il loro inoltro verso Internet;
4. l'indirizzo sorgente dei pacchetti di risposta è un indirizzo privato della rete locale ed esso non può essere raggiungibile tramite Internet, di conseguenza è necessario modificare l'indirizzo IP sorgente con quello dell'interfaccia *eth0* che ha un indirizzo raggiungibile da Internet;
L'esempio è abbastanza simile al caso precedente:
```
# eth0 -> Internet
# eth1 -> LAN
# IP web server -> 10.0.0.1
iptables -P FORWARD DROP
iptables -A FORWARD -d 10.0.0.1 -p tcp --dport 443 -j ACCEPT # punto 1
iptables -A FORWARD -s 10.0.0.1 -m conntrack --ctstate ESTABLISHED,RELATED -j ACCEPT # punto 3
iptables -t nat -A PREROUTING -i eth0 -p tcp --dport 443 -j DNAT --to-destination 10.0.0.1 # punto 2
iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE # punto 4
```
Come nello scenario precedente possiamo specificare lo stato **NEW** delle connessioni al fine di rendere più robusta la configurazione del firewall. Per quanto riguarda l'uso del nome delle schede di rete solitamente non è necessario neanche quando siamo in presenza di più di 2 schede, perché stiamo filtrando su uno specifico indirizzo IP, ma non prendetela come regola generale e valutate caso per caso!
#### Mettiamo insieme tutti i pezzi
Proviamo a mettere insieme tutti gli scenari e togliere le regole duplicate ridondanti. Il risultato dovrebbe essere qualcosa di simile al seguente:
```
# eth0 -> Internet
# eth1 -> LAN
# IP web server -> 10.0.0.1
iptables -P INPUT DROP
iptables -P FORWARD DROP
iptables -P OUTPUT ACCEPT # non necessario, lo riporto solo per completezza
iptables -A INPUT -m conntrack --ctstate ESTABLISHED,RELATED -j ACCEPT
iptables -A INPUT -p tcp --dport 22 -m conntrack --ctstate NEW -j ACCEPT
iptables -A FORWARD -m conntrack --ctstate ESTABLISHED,RELATED -j ACCEPT
iptables -A FORWARD -i eth1 -o eth0 -m conntrack --ctstate NEW -j ACCEPT
iptables -A FORWARD -d 10.0.0.1 -p tcp --dport 443 -m conntrack --ctstate NEW -j ACCEPT
iptables -t nat -A PREROUTING -i eth0 -p tcp --dport 443 -j DNAT --to-destination 10.0.0.1
iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE
```
#### Considerazioni finali di sicurezza
Negli esempi abbiamo permesso tutto il traffico in uscita localmente al firewall e anche in inoltro dalla rete locale verso Internet. Ci siamo concentrati i limitare le connessioni in ingresso da Internet, rete che consideriamo altamente insicura; mentre, siamo stati molto permissivi lato LAN che consideriamo come una rete sicura.
:::info
Le motivazioni della scelta sono semplici: siamo di fronte a un compromesso tra semplicità e usabilità del sistema contrapposto alla sicurezza! Più è sicuro un sistema più esso è complicato e meno è usabile, il problema è che aumentando la complessità aumentano anche la probalità di introdurre errori di configurazione che comprometto l'intera sicurezza del sistema.
:::
Una soluzione così blanda, che permette il traffico in uscita dal firewall e dalla rete locale che protegge, è una soluzione semplice e di fatto è la situazione in cui ci troviamo quasi sempre nelle reti domestiche e aziendali composte da soli pc client. Tale soluzione normalmente è accettata e considerata sufficientemente sicura! Filtrare e limitare il traffico in uscita potrebbe diventare un'impresa abbastanza ardua, perché i nostri pc utilizzano un sacco di servizi Internet per funzionare correttamente e gli utenti usano svariati servizi nella loro quotidianità lavorativa. Per esempio: DNS, NTP, servizi di aggiornamento software, mail server, siti web, video conferenza, solo per citarne alcuni.
Al contrario, se lo scenario cambia e ci troviamo a disegnare e configurare un firewall per un datacenter che contiene applicazioni *mission-critical* e dati sensibili, allora è necessario alzare l'asticella e incrementare al sicurezza. Filtrare il traffico in uscita e assicurarsi che non siano contattabili DNS server e NTP server esterni alla rete locale diventa il obbligatorio, come garantire che i server che forniscono gli aggiornamenti siano affidabili.
Le considerazioni da fare sono tante e solo l'esperienza ci può aiutare nel trovare il compromesso migliore.
___
Copyright (C) 2021-2022 Gianni Bombelli <gianni@giannibombelli.it>
[](https://creativecommons.org/licenses/by-sa/4.0/)
Except where otherwise noted, this content is licensed under a [Creative Commons Attribution-ShareAlike 4.0 International License](https://creativecommons.org/licenses/by-sa/4.0/).
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet