# Data as a Service
In a world that requires faster delivery of products with optimized maintenance of existing development, the DevOps model has been a model that is able to solve all the solutions but what if I tell you there is still a way to increase productivity and make decisions that make the release process of the application less painful.
Before we discover the solution to increasing productivity, I think it's better to get an idea about this “DevOps Model” we are talking about.
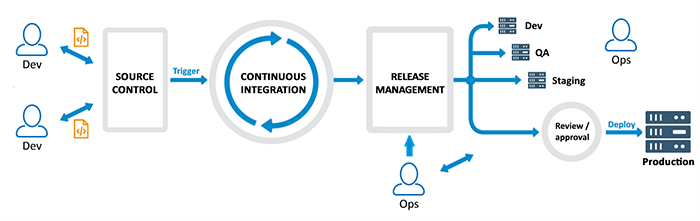
DevOps by definition is the cultural philosophy for software development and includes a set of practices, and tools that increase an organization’s ability to deliver applications and services at high velocity: evolving and improving products at a faster pace than organizations using traditional software development and infrastructure management processes.
It is not productive for an organization to have developers for building and deploying code all day long. Automating these repetitive tasks frees up developers to develop the product and this automation is achieved with DevOps. There are many tools that can be used some of them are:
*Jenkins, Ansible, Sentry, and Bitbucket.*
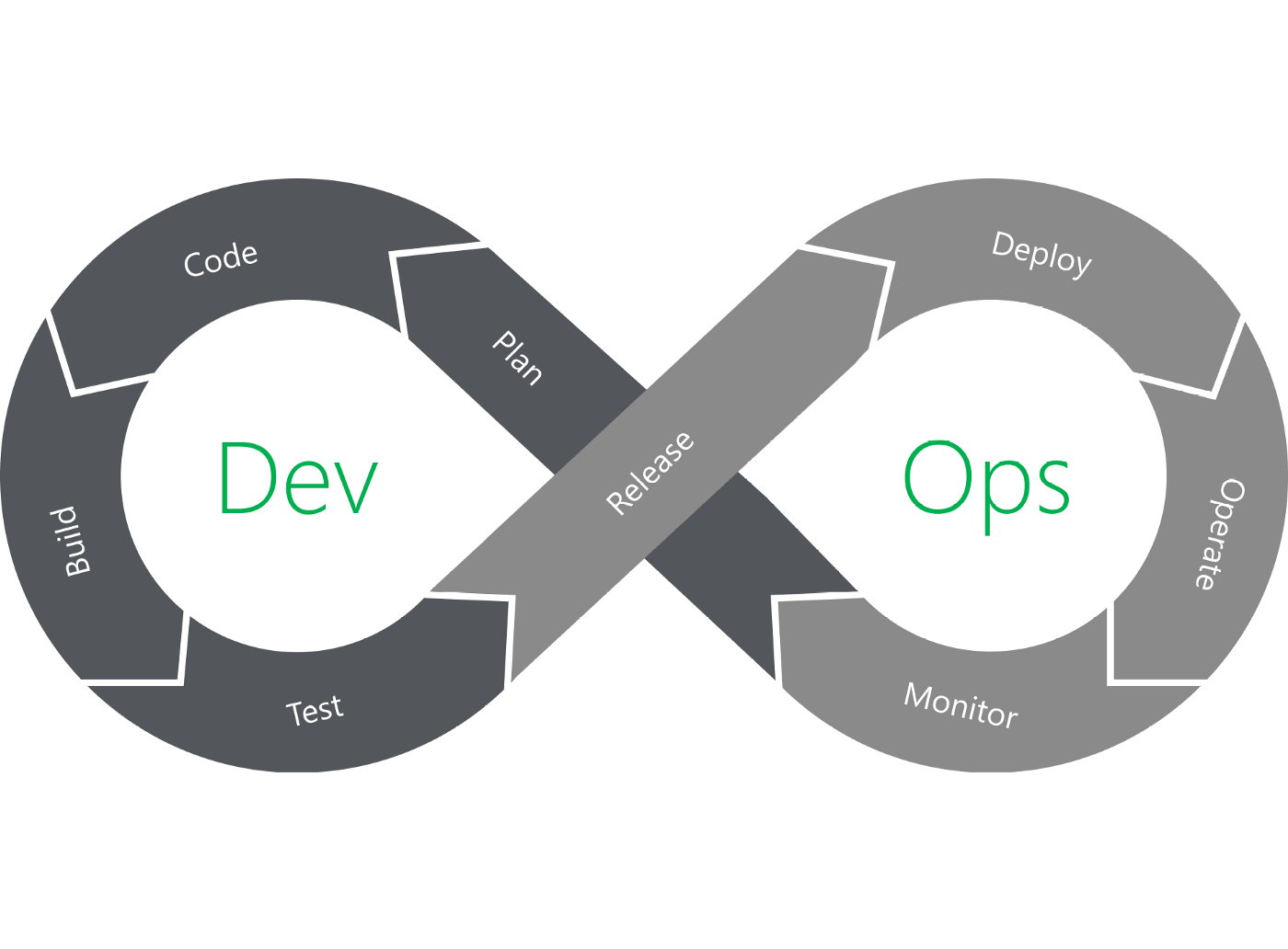
Now that we know what the DevOps model is there is one thing that is very important before making any decision and that is Data. Data provides visibility into how an organization is collaborating and solving problems. Organizations can treat data as a product and use objective metrics around the processes that engineers are beholden to, It is possible to build a roadmap to improve on their current state. But if you don’t have the data to stand on, you could be leading blind and can expect a variety of issues.
Now to get these metrics you can get them manually or you can simply use **Apache-devlake** It has the ability to bring several data sources together to get insights in one dashboard built using grafana(open-source, nightly built dashboarding, analytics, and monitoring platform that is tinkered for connection with a variety of sources like Elasticsearch, Influxdb, Graphite, Prometheus, AWS Cloud Watch, and many others.) in just under 5 minutes.
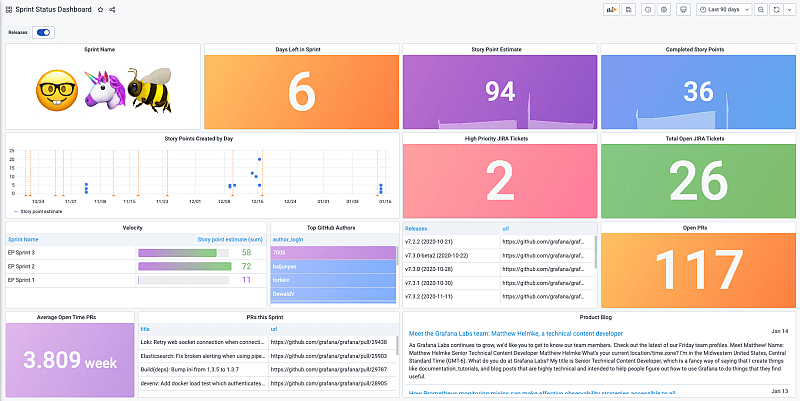
## Apache-DevLake - Moving Towards data-as-a-service
**Apache-DevLake** is an open-source dev data platform that ingests, analyzes, and visualizes the fragmented data from DevOps tools to distill insights for engineering productivity.
It is designed for developer teams looking to make better sense of their development process and to bring a more data-driven approach to their own practices. You can ask Apache-DevLake many questions regarding your development process. Just connect and query.

With its open-source background and focus on simplicity, It is designed to be broadly accessible and is able to serve as a solution as a service for both small and large enterprises. In just two to three years Apache DevLake will be able to become a true data as a service solution.
The community has been continuously active making contributions to develop and provide improvements, Now the product is able to:
- Collect DevOps data across the entire Software Development Life Cycle (SDLC) and connect the siloed data with a standard data model.
- Visualize out-of-the-box engineering metrics in a series of use-case-driven dashboards.
- Easily extend DevLake to support your data sources, metrics, and dashboards with a flexible framework for data collection and ETL (Extract, Transform, Load).
Apache DevLake is unique and one of a kind in the market. The technology is fresh and uniquely suited for data-as-a-service and already delivers the solutions using plugins for many DevOps tools.
## What is next for data-as-a-service?
Led by open source efforts like Apache-DevLake, data-as-a-service will bring solutions and another approach to increase the efficiency and productivity of engineers.
### Contribute to Apache DevLake!
- Github:https://github.com/apache/incubator-devlake
- Official Website:https://devlake.apache.org/
- Slack: https://join.slack.com/t/devlake-io/shared_invite/zt-18uayb6ut-cHOjiYcBwERQ8VVPZ9cQQw
- WeChat:<br>

 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet