# README
- [README](#readme)
* [프로젝트 & 웹](#--------)
* [DKT Competition](#dkt-competition)
* [참고 자료](#-----)
* [Installation](#installation)
* [디렉토리](#----)
* [DKT Data EDA(Exploratory Data Analysis)](#dkt-data-eda-exploratory-data-analysis-)
* [Team Collaboration Tools](#team-collaboration-tools)
* [License](#license)
<!-- <center><img src="https://i.imgur.com/SmILzOp.png"></center> -->
<center>
<div style="transform: translateX(-250%); height: 10%; max-height: 10%; max-width: 10%; width: 10%; display: flex;">
<img src="https://s3-ap-northeast-2.amazonaws.com/prod-aistages-public/app/Users/00000180/user_image.png" style="object-fit: cover; border-radius: 50%;">
<img src="https://s3-ap-northeast-2.amazonaws.com/prod-aistages-public/app/Users/00000025/user_image.png" style="object-fit: cover; border-radius: 50%;">
<img src="https://s3-ap-northeast-2.amazonaws.com/prod-aistages-public/app/Users/00000167/user_image.png" style="object-fit: cover; border-radius: 50%;">
<img src="https://s3-ap-northeast-2.amazonaws.com/prod-aistages-public/app/Users/00000128/user_image.png" style="object-fit: cover; border-radius: 50%;">
<img src="https://s3-ap-northeast-2.amazonaws.com/prod-aistages-public/app/Users/00000019/user_image.png" style="object-fit: cover; border-radius: 50%;">
<img src="https://s3-ap-northeast-2.amazonaws.com/prod-aistages-public/app/Users/00000218/user_image.png" style="object-fit: cover; border-radius: 50%;">
</div>
</center>
# Competition 1st

## 프로젝트 & 웹 (우리 프로젝트의 이름으로 적을것)
### 시연
- 상식 주제를 골라 문제를 푼다.
- 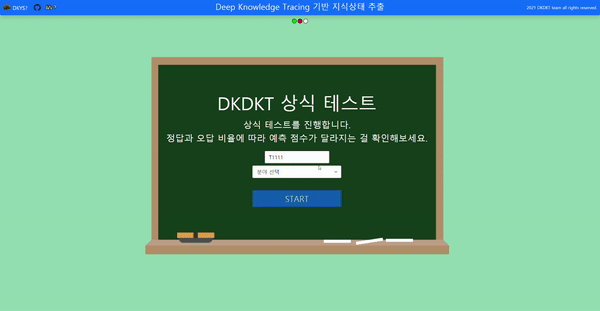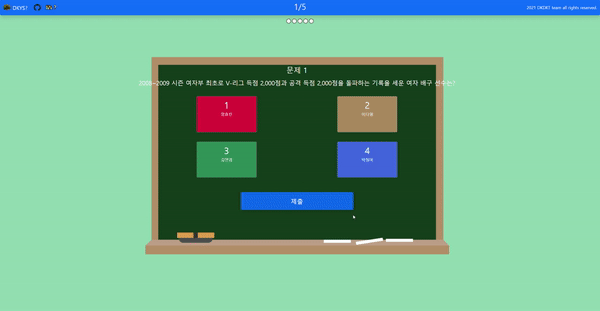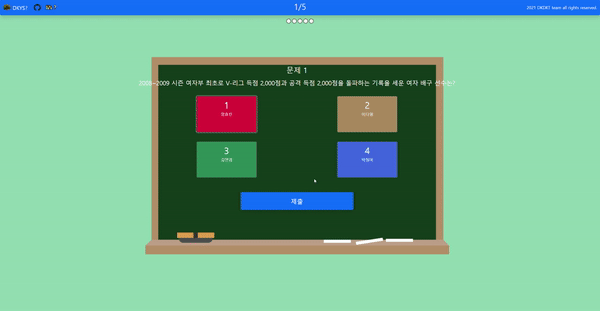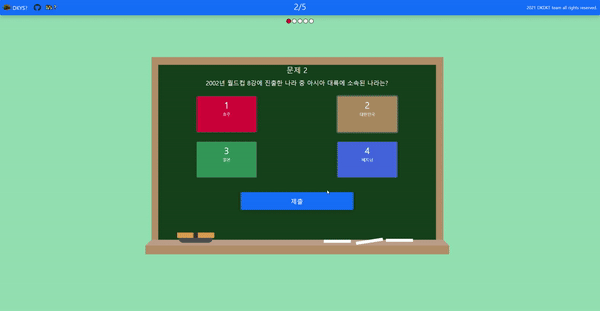
- 문제를 다 풀면 사용자가 쉬워 할 문제와 어려워 할 문제를 모델이 추론하여 보여준다.
- 
### 개요
- 사용자는 상,중,하 3가지의 난이도로 이루어진 사칙연산 5문제를 푼다.
- 사용자의 시계열 데이터는 feature engineering을 통해 모델에 넣을 수 있게 가공된다.
- 가공된 데이터를 모델에 넣고 다음에 어떤 문제를 풀어야 효율적인지 알려준다.
- 데이터가 일정량 쌓이면 모델은 이를 추가하여 새롭게 학습한다.
### 효과
- COVID 19로 교육격차가 커진 상황에서 누구나 개인 지도 선생님을 갖게 됨으로써 교육의 빈부격차 해소할 수 있다.
## DKT Competition
### 결과
- 1등 LB score: 0.8486
### 개요

- DKT는 Deep Knowledge Tracing의 약자로 우리의 "지식 상태"를 추적하는 딥러닝 방법론
- 대회에서는 지식 상태를 추적하는 것 보다는 주어진 문제를 맞출지 틀릴지 예상한다.
- 각 학생이 푼 문제 리스트와 정답 여부가 담긴 데이터를 받아 최종 문제를 맞출지 틀릴지 예측한다.
### 평가방법
- AUROC(Area Under the ROC curve)
- 다양한 threshold에서 모델의 분류 성능을 측정할 수 있다.
### Solution
- CV strategy
```ptyhon
for _, row in TESTID.iterrows():
# 1) 마지막 문제 유형이 같은가?
candidate = TRAINID[TRAINID['last_grade']==row['last_grade']].copy()
# 2) 이미 선택되지 않은 것 중
candidate['c'] = candidate['userID'].apply(lambda x : x in tdict.values())
candidate = candidate[candidate['c'] == False]
# 3) 마지막 문제에 대한 학습이력 길이가 비슷한 상위 30개 중
candidate['last_count'] = candidate['last_count'].apply(lambda x : abs(x-row['last_count']))
candidate = candidate.sort_values(by='last_count').reset_index(drop=True)
candidate = candidate[:min(candidate.shape[0],30)].copy()
# 4) 시험지가 같거나 다르다면 해당 grade에 대한 정확도가 비슷한 것
candidate['r_acc'] = (candidate['grade_acc'] - row['grade_acc']).apply(lambda x : x if x >=0 else -x)
candidate['r_mid'] = (candidate['last_mid'] == row['last_mid']).astype(int)
candidate = candidate.sort_values(by=['r_mid','r_acc']).reset_index(drop=True)
tdict[row['userID']] = list(candidate['userID'])[0]
```
- LGBM + Tabnet
- LGBM : 망각 관련 feature포함 54개 사용, 이후 test 데이터에 대해서만 fine-tuning
- Tabnet : 수치형 변수만으로 학습 후 pseudo labeling을 적용해 5epoch 더 학습
- Blending Ensemble
- 각 모델의 inference 결과를 tree 모델 기반으로 ensemble!
## 참고 자료
### Last Query Transformer
- !!! 인사이트 위주 !!!
- !!!! 장점 / 한계 내주기 !!!
- 링크
- https://arxiv.org/pdf/2102.05038v1.pdf
- 요약
- Self-attention에서 마지막 sequence만 사용하여 inner product
- Time Complexity O(n^2)에서 O(n)으로 감소
- 낮은 시간 복잡도로 긴 sequence의 데이터도 학습이 가능하지만 반대로 긴 sequence가 필요 없을때는 사용 할 필요성을 못느낌
### SAKT
- 링크
- https://arxiv.org/pdf/1907.06837v1.pdf
- 요약
- self-attention layer를 사용
- query: exercise(문제에 관한 정보)
- key,value: interaction(사용자의 응답 정보)
- exercise, interaction뿐만 아니라 다른 feature들을 concat해서 사용하면 성능이 올라감
### DSAKT
- 링크
- https://arxiv.org/pdf/2105.07909v2.pdf
- 요약
-
### SAINT
- 링크
- https://arxiv.org/pdf/2002.07033v5.pdf
- 요약
- SAKT 한계 개선
- shallow attention layer
- Multi-Attention Layer로 변경
- same inputs
- Ecoder inputs : Exercise info
- Decoder inputs : Response info
### SAINT Plus
- 링크
- https://arxiv.org/pdf/2102.05038v1.pdf
- 요약
- SAINT 모델 Decoder의 input feature 추가
- Elapsed : 정답을 도출하는데 걸린 시간
- Lag Time : 다음 시험지로 넘어가는데 걸린 시간
## Installation
> How to clone our repository
```bash=
git clone https://github.com/bcaitech1/p4-dkt-dkdkt
```
> Or Downloads .zip file
### Dependencies
os에 대한 설명
- easydict==1.9
- lightgbm==3.2.1
- numpy==1.19.5
- pandas==1.2.4
- sklearn==0.0
- torch==1.6.0
- torchvision==0.7.0
- tqdm==4.46.0
- transformers==4.6.1
- wandb==0.10.31
```bash=
pip install -r requirements.txt
```
- cuda에 대한 설명과 설치법?
## 디렉토리
### Code
```
-- pseudo
|-- args.py
|-- dkt
| |-- criterion.py
| |-- dataloader.py
| |-- metric.py
| |-- model.py
| |-- new_model.py
| |-- optimizer.py
| |-- scheduler.py
| |-- trainer.py
| `-- utils.py
|-- inference.py
|-- pseudolabel.py
|-- train.py
|-- train_debug.py
`-- train_kfold.py
```
### Dataset
```
-- asset
|-- KnowledgeTag_classes.npy
|-- assessmentItemID_classes.npy
|-- cv_train_data_FE_modify_FE_relative.csv
|-- cv_valid_data_FE_modify_FE_relative.csv
|-- elapsed_classes.npy
|-- grade_classes.npy
|-- other_classes.npy
|-- problem_number_classes.npy
|-- testId_classes.npy
|-- test_data_FE.pkl
|-- test_data_FE_modify_FE_relative.csv
`-- train_data_FE.pkl
```
## Usage/Examples
> Default 값을 사용하는 간단한 실행 예제
```bash=
python train.py
```
부스트캠프 AI Tech에서 Deep Knowledge Tracing Competition 기간 동안 제공한 예제 코드를 토대로 개발한 DKT 모델 Baseline입니다.
### Train
```python=
argument에 대한 설명
너무 많음, 필요한것만 설명 + 쓸모없는 거 통합해야할 듯
```
Train argument에 대한 설명, 사용례
지원하는 모델, metric 등,
모델
lgbm, saint, tfixup saint, lstm, lstm attention, tabnet???
loss
bce, roc star, spherical 어쩌구
metric
auc, acc
optimizer
adam, admaW
### Inference
```bash=
inference 예시 코드
```
Inference 방법 및 csv 제출 형식, csv 저장 장소
제출 횟수 제한이나, 제출 팀원에게 알리는 방법?(<= 코드에 대해만 써야 하는가?)
### Sweeping(hyperopt), 앙상블, k-fold validation => 실험 관리 탭으로
Wandb를 이용한 실험 관리 및 sweeping 방법 예시
tmux 등을 이용한 session 생성법
간단하게,
## DKT Data EDA(Exploratory Data Analysis)
### i-Scream 데이터 분석
> i-Scream 데이터의 예시
| userID | assessmentItemID | testId | answerCode | Timestamp | KnowledgeTag |
|:------:|:----------------:|:----------:|:----------:|:-------------------:|:------------:|
| 0 | A060001001 | A060000001 | 1 | 2020-03-24 00:17:11 | 7224 |
| 0 | A060001002 | A060000001 | 1 | 2020-03-24 00:17:14 | 7225 |
| 0 | A060001003 | A060000001 | 0 | 2020-03-24 00:17:22 | 7225 |
| ... | ... | ... | ... | ... | ... |
- 각 컬럼에 대한 설명 블라블라
데이터에 대한 설명 (column, 갯수, test dataset의 특징, 출처 등)
데이터에 대한 특징 ()
### EDA
EDA에서 얻어낸 결과(시각화(그래프), ex) grade 올라갈수록 정답률이 떨어진다.)
- 다른 링크
EDA 코드 또는 링크
### Feature Engineering
Feature 종류와 설명, (표? 아니면 따로 말머리 할당?)
링크?
## Team Collaboration Tools
!!! 링크나 그림으로 대체 !!! 굳이 글보다는 보여주는 식으로
### Notion
- Features 및 작업 공유
### Github
- 목적 :
- 작업 내용 및 코드 공유
- 내용 :
- 개인 작업 공간
- Issue 관리
- Projects 관리
- ...
### Google Drive
- 목적 :
- 데이터 저장
- 내용 :
- Trainset
- Testset
- ...
### Slack
- 목적 :
- 멘토링 및 간단한 정보 공유
- 내용 :
- Competition Feedback
- Project Feedback
- ...
## License
> [MIT](https://choosealicense.com/licenses/mit/) 라이센스
```
MIT License
Copyright (c) 2021 DKDKT
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
```
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet