# <center><i class="fa fa-edit"></i> LSTM</center>
###### tags: `notes`
:::info
**Goal:**
Understanding LSTM Network
**Resources:**
[Colah's Blog](https://colah.github.io/posts/2015-08-Understanding-LSTMs/)
:::
## What is LSTM ?

LSTM stands for <b>long short term memory</b>. It is a model or architecture that extends the memory of recurrent neural networks. Typically, recurrent neural networks have short term memory in that they use persistent previous information to be used in the current neural network. Essentially, the previous information is used in the present task. That means we do not have a list of all of the previous information available for the neural node.
LSTM belongs to the complex areas of Deep Learning. It is not an easy task get your head around lSTM. It deals with algorithms that try to mimic the human brain the way it operates and to uncover the underlying relationships in the given sequential data.
## The Logic Behind LSTM
The central role of an LSTM model is held by a memory cell known as a cell state that maintains its state over time. The cell state is the horizontal line that runs through the top of the below diagram. It can be visualized as a conveyor belt through which information just flows, unchanged.
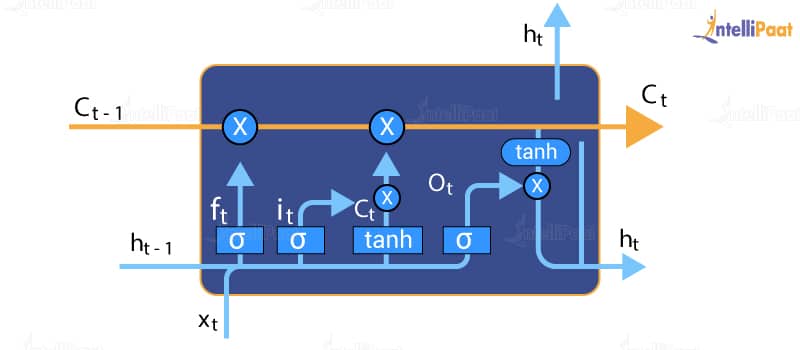
Information can be added to or removed from the cell state in LSTM and is regulated by gates. These gates optionally let the information flow in and out of the cell. It contains a pointwise multiplication operation and a sigmoid neural net layer that assist the mechanism.
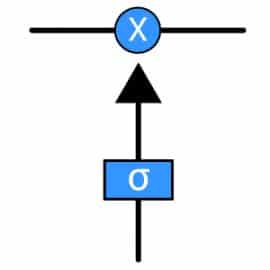
The sigmoid layer gives out number between zero and one, where zero means nothing should be let through and one means everything should be let through.
## How Does LSTM Work?
LSTM introduces long-term memory into recurrent neural networks. It mitigates the vanishing gradient problem, which is where the neural network stops learning because the updates to the various weight within a given neural network become smaller and smaller. It does this by using a series of gates. These are contained in memory blocks which are connected through layers, like this :

There are three types of gates within a unit :
- Input Gate: Scales input to cell (write)
- Output Gate: Scales output to cell (read)
- Forget Gate: Scales old cell value (reset)
Each gate is like a switch that controls the read/write, thus incorporating the long-term memory function into the model.
## Recurrent Neural Network (RNN)
Humans don’t start their thinking from scratch every second. As you read this essay, you understand each word based on your understanding of previous words. You don’t throw everything away and start thinking from scratch again. Your thoughts have persistence.
Recurrent neural networks address this issue. They are networks with loops in them, allowing information to persist.

In the above diagram, a chunk of neural network, A, looks at some input xt and outputs a value ht. A loop allows information to be passed from one step of the network to the next.
These loops will make RNN seem more mysterious. However, if you think a bit more, it turns out that they aren’t all that different than a normal neural network. A recurrent neural network can be thought of as multiple copies of the same network, each passing a message to a successor. Consider what happens if we unroll the loop:

This chain-like nature reveals that recurrent neural networks are intimately related to sequences and lists. They’re the natural architecture of neural network to use for such data.
## Disadvantage of Long-Term Dependencies
One of the attractiveness of RNNS is the idea that they could be able to link the prior information to the now a days task, such as using previous video frames might inform the understanding of the present frame.
Sometimes, we only need to look at the present information to perform the present task. For example, consider a language model trying to predict the next word based on the previous ones. If we are trying to predict the last word in “the clouds are in the sky,” we don’t need any further context – it’s pretty obvious the next word is going to be sky. In such cases, where the gap between the relevant information and the place that it’s need is small, RNNS can learn to use the past information.

Unfortunately, as that gap grows, RNNs become unable to learn to connect the information.

In theory, RNNs are absolutely capable of handling such “long-term dependencies.” A human could carefully pick parameters for them to solve toy problems of this form. Sadly, in practice, RNNs don’t seem to be able to learn them. Thankfully, LSTM’s don’t have this problem.
## LSTM vs RNN
If we want to modify certain information in a calender. We use RNN to change all of the existing data by applying a function. Whereas, LSTM makes small modifications on the data by simple addition or multiplication that flow through cell states. This is how LSTM forgets and remembers things selectively, which makes it an improvement over RNN.
## Application of LSTM
There are a huge range of wys that LSTM can be used, including:
- Handwriting recognition
- Time series anomaly detection
- Speech recognition
- Learning grammar
- Composing music
- Language modelling
- Machine Translation
- Image captioning
- Question Answering
- Video-to-text conversion
- Polymorphic music modelling
## Conclusion
LSTM networks are an improvement over RNN as they can achieve whatever RNNs might achiveve with much better finesse. As intimidating as it can be, LSTMs do provide better results and are truly a big step in Deep Learning. With more such technologies coming up, you can expect to get more accurate predictions and have a better understanding of what chocices to make.