
---
# Performance
## through parallelism
### (Daniel - Thanh - Carlos)
---
<br/>
<br/>
<br/>
Parallelism happens when **components work together** to increase total performance by **combining their resources**.
^both letting you focus on the entire system without worrying about the details, and increasing total performance by combining the resources of the individual components.
[.slide-transition: push(horizontal, 0.3)]
---
^(Before Flashlight) It can be found in many non-computer science related systems. For Example,
**Flashlights** often have **multiple bulbs working together** to produce more light
^ (After flashlight) also, we have two eyes working at the same time, giving us a wider field of vision and depth perception.

---
<!-- BREAK 1 -->
>
Stores with **multiple checkout counters** are also **examples of parallelism**, because the line can be **divided into multiple smaller lines** which are processed in parallel.

^NOTE: one disadvantage of parallelism in this case is that the company has to pay for several employees working at different counters instead of paying for just one person
[.slide-transition: push(horizontal, 0.3)]
----
<br/>
<br/>
<br/>
The way **this factory works** to **build a motherboard** is a good example of parallelism:
[.slide-transition: fadeThroughColor(#000000)]
---

^ (Beginning of video) After the distribution of the first plate, (PRESS PLAY) another plate starts coming out of the plate making machine.(PRESS PAUSE)
^(AT the end of video) The first plate goes through different processes, while the 2nd plate is processed only one step behind.Each process is done at once, in parallel. (PRESS PLAY) In the end, multiple motherboards will be produced following this process.
----
<br/>
<br/>
<br/>
We will be **focusing on** the **performance advantages**, including:
[.slide-transition: move(horizontal)]
---
## 1. SPEED ADVANTAGE
---
<!-- SPACING 1-->
>
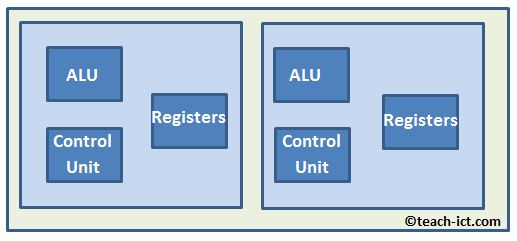
Every computer has a processor, which now have multiple cores to increase performance by **allowing multiple threads (core units)** so that we can **run through multiple instructions per clock cycle.**
----
## 2. EFFICIENCY
----
<br/>
<br/>
Instead of advancing technologies to **raise the clock speed**, which increases **power consumption** and produces **more heat**, having **more core units** in the processor is a more power-efficient and cost effective technique.
---
[.column: ]

[.column: ]

^ (first graph)(THANH) With the increase of the clock speed, the more power we have to provide for CPU
(DANIEL) As you can see here, the difference between a clock speed of 1.5 to 2.5 does not increase the power consumption very much, but the difference between a clock speed of 3.5 to 4.5 makes a big difference, so at some point, it's not worth it to increase the clock speed any more.
^- The size of the CPUs are the same, but the number of transistors is increasing to increase the clock speed, so that those transistors have to be smaller in size to fit into CPUs. At some point, it gets very difficult to make them smaller than their size now, which are already only 14 nanometers, or only 70 silicon atoms wide.
^ - Meanwhile, **increasing the clock speed** is less cost-effective because more transistors produce more heat, and the **heat is expensive to alleviate**.
So, **multiple cores** is a **cheaper** way to increase performance.
---
# HISTORY
^(before slide) When looking at reasons for parallelism, the major events in the history of Parallelism might open up some answers
[.slide-transition: push(horizontal, 0.3)]
---
<!-- Here is a brief history of Parallelism -->

[.text: #FFFF00 , alignment(center), line-height(10), text-scale(1.0), Avenir Next BOLD]
^- In 1946, the developement of the first Parallel Machine Model called the Von Newmann machine.
- (In 1980) A computer cluster is a set of computers connected together which all perform the same task, controlled by the software.
- (1990) Companies started setting standard to mindfully adopt parellism in designing machines.
- (2013 until now) witnesses the development of Various projects dedicated to increasing speeds and reducing cost via paralelis
---
<!-- SPACING1-->
>
<!-- SPACING2-->
>
<!-- SPACING3-->
>
# STAGES
Parallelism can be split into 4 stages:
^When looking at reasons for parallelism, looking at how it is done generally can also be helpful
[.text: #FFFF00 , alignment(center), line-height(10), text-scale(1.0), Avenir Next BOLD]
[.slide-transition: reveal(horizontal)]
---
1. Partitioning - Identifying the problem and determining smaller tasks to handle it.
---
1. Partitioning - Identifying the problem and determining smaller tasks to handle it.
2. Communication - Determining which information is relevant to solve the problem
^communication among the processors so that they may operate in parallel.
---
1. Partitioning - Identifying the problem and determining smaller tasks to handle it.
2. Communication - Determining which information is relevant to solve the problem
3. Agglomeration - determines resource cost and when possible, tasks are combined to save costs
----
1. Partitioning - Identifying the problem and determining smaller tasks to handle it.
2. Communication - Determining which information is relevant to solve the problem
3. Agglomeration - determines resource cost and when possible, tasks are combined to save costs
4. Mapping - Sending instructions to components to process
---
<!-- SPACING1-->
>
<!-- SPACING2-->
>
<!-- SPACING3-->
>
<!-- SPACING4-->
>
<!-- SPACING5-->
>
Computation is beginning!
[.text: #FFFF00 , alignment(center), line-height(10), text-scale(1.0), Avenir Next BOLD]
---

---
### Examples In
## COMPUTER SCIENCE
^I will be talking about two types of parallelism in Computer Science, Instructional P and Bit-Level P
[.slide-transition: push(horizontal, 0.3)]
---
<br/>
## BIT LEVEL PARALLELISM
**Bit-Level parallelism** focuses on **increasing the length** of each piece of data managed by the processor, including the length of **registers and instructions**.
^Which in MIPS, are 32 bits long.
---

^ The 64-Bit is not popular.
---
## INSTRUCTION-LEVEL PARALLELISM
1. Pipelining
2. Multiple issue processors
^- (Pipelines) improve performance by sequencing the stages of the data-path.
^- (Multiple issue processors) can simultaneously execute different instructions.
---
<!-- SPACINGl itanum
>
<!-- SPACING3-->
>
# Pipelining:
^Pipelining is an important implementation of instruction-level parallelism.
An Instruction-Level Parallelism technique
[.text: #FFFF00 , alignment(center), line-height(10), text-scale(1.0), Avenir Next BOLD]
[.slide-transition: reveal(right)]
---
<!-- SPACING1-->
>
<!-- SPACING2-->
>
<!-- SPACING3-->
>
<!-- SPACING4-->
>
<!-- SPACING5-->
>
Pipelining is a technique enabling **multiple instructions** to be processed **at once** in a pipeline, or queue, within a **single processor**.
---
<!-- SPACING1-->
>
<!-- SPACING2-->
>
<!-- SPACING3-->
>
<!-- SPACING4-->
>
<!-- SPACING5-->
>
Pipelining **exploits the potential** for parallelism in instructions, by dividing the parts of the processor into five stages, or functional units,
as shown here:
---

Instruction Fetch - Instruction Decode - Execute - Memory Access - Write Back
[.text: #FFFF00 , alignment(center), line-height(1), text-scale(0.5), Avenir Next Bold]
^Each functional unit can execute part of an instruction at once, as opposed to a non-pipelined implementation, where the processor can only handle one instruction in total.
Using pipelining can increase the speed at which instructions are executed drastically in programs with a lot of instructions.
---
Pipelined and Non-Pipelined Processors

^This diagram shows the performance difference between pipelined and non-pipelined processors.
[.text: #FFFF00 , alignment(center), line-height(10), text-scale(1.0), Avenir Next BOLD]
---
<!-- SPACING1-->
>
<!-- SPACING2-->
>
# Multi-Issue Processors
Multiple issue processors can **simultaneously execute multiple operations**, by issuing **operations that can run in parallel** in a **single cycle**.
^an operation is the abstract form of an individual instruction.
^(After Slide) I will be focusing on two types of Multiple Issue processors:
VLIW processors and Superscalar processors.
[.slide-transition: fade(0.3)]
---
<!-- Space -->
>
### Very-Long-Instruction-Word Processors
- **VLIW processors** use **instructions called VLIWs** which are basically a number of MIPS Instructions **combined** together.
- **VLIWs** have multiple **operation slots** for different **types of operations** that can be run in parallel.
- The slots depend on the functional units in the processor.
^ (AFTER SLIDE) For example, if the processor has two ALUs then two operations that use the ALU can execute at once.
[.slide-transition: reveal(horizontal)]
---
<!-- SPACING1-->
>
<!-- SPACING2-->
>
- The **compiler checks** for **independent operations** of different types that can **run in parallel**, and **combines them** into a VLIW.
^(Thanh)The compiler checks which operations in the source code are independent and use different functional units in the processor, and them combines them into a VLIW.
- Operations which are dependent on each other **cannot run in parallel**.
^(cannot run in parallel)Operations cannot be run in parallel if they are dependent on each other because they would try to access nonexistant data.
- Combine as many operations as possible for **maximum** performance.
^(for **maximum** performance.)Ideally, all the operation slots in the VLIW would be full, meaning all the types of operations the processor can handle at once are in a single VLIW.
---
VLIW VS MIPS INSTRUCTION
^This example shows a VLIW with slots for branch, ALU, and load/store operations, versus a short ALU MIPS instruction.

[.text: #FFFF00 , alignment(center), line-height(10), text-scale(1.0), Avenir Next BOLD]
^In this example, the VLIW is 4 bytes per operation times 3 operations in each VLIW, or 12 bytes long, versus the 4 byte long MIPS instruction.
---
When operations **cannot run in parallel**, *no-ops*, **operations that do nothing,** must be **added to the slots** instead of operations.
^As shown here, which slows down the execution of the operations.
In this example, there was no load or store operation available in the source code, so a no-op must be added to the slot.

---
<!-- SPACING1-->
>
<!-- SPACING2-->
>
<!-- SPACING3-->
>
## Superscalar:
- Dependence checking and instruction scheduling are **done in the hardware**.
^ ( done in the hardware) Instruction scheduling means they send multiple instructions to the right function unit, unlike very long instruction word processors which use the compilerb.
- The processors use standard **four-byte instructions**.
^ (Four-byte instructions)Superscalar processors use standard 4 byte instructions which hold only one operation, unlike the very-long-instruction-word instructions.
[.slide-transition: move(horizontal)]
---
<br/>
<br/>
<br/>
Here is a diagram showing **the differences between VLIW and Superscalar execution** on the **same source code**.
---

^(Compiler with scheduling) Which combines independent operations into a VLIW.
^(Scheduling hardware) Superscalar checks for independece between instructions and schedules instructions to run in parallel at run-time.
^Checking for dependencies at run-time can give the superscalar implementation an advantage in some scenarios, when the VLIW compiler cannot know if there are dependencies between the operations and will have to assume that there are dependencies.
---
Here is an example of a **VLIW compiler** being **unable to detect dependencies**.

^ The address t1 is stored to, and the address s1 is loaded in from, are the same, which means if they execute at once, the load word instruction will try to access the non-existant output of the store word instruction. But the compiler cannot know the values of the registers, so it has to assume that all store word operations have to be executed before load word operations, limiting the possible slots in the VLIW.
^Superscalar processors don’t have this problem, because hardware in the processor checks which and how many instructions can be executed in a given clock cycle when the code is run, when the values of t2 and t1 are known.
---
^Both Superscalar and VLIW processors often add more ports to the registers and memory and have duplicate functional units to increase the number of operations that can be executed in parallel, but only Superscalar processors need to be expanded to be able to detect dependencies and schedule instructions, because the compiler does all the dependence checking in VLIW.

---
^Multiple issue and pipelining often go hand in hand, which can improve the performance even more.
**Pipelined Multiple Issue Processors**
^ This diagram shows a superscalar pipeline, which is capable of executing two instructions in each clock cycle, giving a CPI (clocks per instruction) of 0.5.

[.text: #FFFF00 , alignment(center), line-height(10), text-scale(1.0), Avenir Next Regular]
---
###VLIW VS SUPERSCALAR
**VLIW Advantages:**
+ Simpler hardware
^(Simpler hardware) The hardware is simpler because the dependency checking and instruction scheduling is done in the compiler, which also means it is cheaper to build.
+ Easier to design and maintain
^(Easier to design and maintain) Because Improvements can be made after the chips have been fabricated, since the compiler is what has the VLIW functionality.
[.slide-transition: fadeThroughColor(#000000)]
---
###VLIW VS SUPERSCALAR
**VLIW Disadvantages:**
+ Some slots might have to be filled with no-ops, slowing down the execution of instructions.
^ If you can’t have one operation of each type in the VLIW, some slots will be wasted and filled with no-ops, which slows the execution of instructions.
+ The compiler cannot always tell if there are dependencies between instructions.
^ In some situations like I showed earlier, the compiler cannot tell if there are dependencies between instructions, and it will have to assume there are, limiting the performance gain.
[.autoscale: true]
---
###VLIW VS SUPERSCALAR
**Superscalar Advantages:**
+ The processor has more code compatibility.
^ Existing code will run on a superscalar implementation, the code does not need to support the upgraded compiler of a VLIW.
+ The data values are known when dependencies are checked.
^Since the hardware in the processor checks for dependencies,
which can be done when you run the code, when the values are known.
---
###VLIW VS SUPERSCALAR
**Superscalar Disadvantages:**
+ More expensive to produce.
^ (expensive to produce) The hardware being more complex means the cpu has to be bigger and is more expensive to fabricate.
+ More power consumption.
^Which also makes it consume more power.
---
^(Before slide) Here is an example of processors that have multi-issue functionality:
## Parallel Processor Example
Intel Core 2 processors are superscalar and can issue up to four instructions per clock cycle. They also use pipelining, meaning that they have four pipelines going at once.

---
## SOURCES
http://twins.ee.nctu.edu.tw/courses/ca_08/literature/11_vliw.pdf
https://en.wikipedia.org/wiki/Very_long_instruction_word
https://en.wikipedia.org/wiki/Superscalar_processor
https://www.youtube.com/watch?v=yme66Oo8SzI
https://home.deib.polimi.it/silvano/FilePDF/ARC-MULTIMEDIA/VLIW1.pdf
https://www.youtube.com/playlist?list=PL1C2GgOjAF-JQv5snuxjBkurjk6AAK0Cj
https://www.mcs.anl.gov/~itf/dbpp/text/node15.html
https://cseweb.ucsd.edu/~j2lau/cs141/week9.html
https://www.computerworld.com/article/2535019/timeline--a-brief-history-of-the-x86-microprocessor.html
https://www.youtube.com/watch?v=3re04MxFtnU
[.autoscale: true]
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet