# Res2Net
###### tags: `paper` `已公開`
[toc]
## 摘要
在多個尺度上表示特徵對於許多視覺任務非常重要。 骨幹卷積神經網絡的最新進展不斷展示出更強的多尺度表示能力,從而在廣泛的應用中獲得一致的性能提升。 然而,大多數現有方法以分層方式表示多尺度特徵。 在本文中,我們通過在單個殘差塊內構建分層殘差連接,為 CNN 提出了一種新的構建塊,即 Res2Net。 Res2Net 表示粒度級別的多尺度特徵,並增加了每個網絡層的感受野範圍。 提出的 Res2Net 塊可以插入最先進的骨幹 CNN 模型,例如 ResNet、ResNeXt 和 DLA。我們在所有這些模型上評估 Res2Net 塊,並在廣泛使用的數據集(例如 CIFAR-100 和 ImageNet)上展示了與基線模型相比的一致性能提升。對代表性計算機視覺任務(即對象檢測、類激活映射和顯著對象檢測)的進一步消融研究和實驗結果,進一步驗證了 Res2Net 相對於最先進的基線方法的優越性
## Introdution

視覺 patterns 在自然場景中以多尺度出現,如圖 1 所示。
1. 首先,單個圖像中可能出現**不同尺寸**的物體,例如沙發和杯子的尺寸不同。
1. 其次,對象的基本**上下文信息**可能佔據比對象本身大得多的區域。 例如,我們需要依靠大桌子作為上下文來更好地判斷放在它上面的小黑色斑點是杯子還是筆架。
1. 第三,**感知來自不同尺度的信息對於理解部分和對象至關重要**,對於細粒度分類和語義分割等任務。
因此,為視覺認知任務的多尺度設計良好的特徵至關重要(Thus, it is of critical importance to design good features formulti-scale stimuli for visual cognition tasks),包括圖像分類、物件檢測、注意力預測、目標跟踪、動作識別、語義分割、顯著目標檢測、目標提議、骨架提取、立體匹配和邊緣檢測。
不出所料,多尺度特徵已廣泛應用於傳統特徵設計和深度學習。在視覺任務中**獲得多尺度表示需要特徵提取器使用大範圍的感受野來描述不同尺度的對象/部分/上下文**。 卷積神經網絡通過一堆卷積運算子自然地學習從粗到細的多尺度特徵。CNN 的這種固有的多尺度特徵提取能力為解決眾多視覺任務提供了有效的表示。如何設計更多有效的網路架構,是提升CNN效能的關鍵。
在過去幾年,很多backbone網路,在許多視覺任務中取得了重大進展,並具有最先進的性能。 早期的架構如 AlexNet 和 VGGNet 堆疊卷積算子,使得多尺度特徵的數據驅動學習成為可能。 隨後通過使用具有不同內核大小(InceptionNets)、殘差模塊(ResNet)、快捷連接(DenseNet)和hierarchical layer aggregatrion([DLA](https://openaccess.thecvf.com/content_cvpr_2018/papers/Yu_Deep_Layer_Aggregation_CVPR_2018_paper.pdf))來提高多尺度能力的效率。


在這項工作中,我們提出了一種簡單而有效的多尺度處理方法。與大多數增強 CNN 逐層多尺度表示強度的現有方法不同,**我們在更細粒度的級別上提高了多尺度表示能力**。不同於一些同時期的研究,通過利用不同分辨率(解析度)的特徵來提高多尺度能力,**我們提出的方法的多尺度是指在更細粒度的水平上多個可用的感受野**。為了實現這個目標,我們用一組較小的過濾器組代替了 n 個通道 的3×3 個過濾器 ,每個過濾器組都有 w 個通道(不失一般性,我們使用$n=s×w$)。如圖 2 所示。這些較小的過濾器組以hierarchical residual-like 的方式連接,以增加輸出特徵可以表示的尺度數量。具體來說,我們將輸入特徵圖分為幾組。一組過濾器首先從一組輸入特徵圖中提取特徵。然後將前一組的輸出特徵與另一組輸入特徵圖一起發送到下一組過濾器。 這個過程會重複幾次,直到處理完所有輸入特徵圖。最後,將所有組的特徵圖連接起來並發送到另一組 1×1 過濾器以融合信息。 隨著輸入特徵轉換為輸出特徵的任何可能路徑,每當通過3×3濾波器時等效感受野增加,由於組合效應導致許多等效特徵尺度
除了現有的 depth、width 和 cardinality 維度之外,Res2Net 策略還公開了一個新維度,即$scale$(the number of feature groups in the Res2Net block),作為一個必不可少的因素。而且增加scale比增加其他維度更有效。
請注意,所提出的方法在更細粒度的級別上利用了多尺度潛力,這與利用layer-wise operations的現有方法正交。 因此,建議的構建塊,即 Res2Net 模塊,可以輕鬆插入到許多現有的 CNN 架構中。大量實驗結果表明,Res2Net 模塊可以進一步提高最先進的 CNN 的性能,例如 ResNet、ResNeXt 和 DLA
## Related Wrok
### Backbone Networks
近年來見證了很多backbone具有更強多尺度表示,在各種視覺任務中實現最先進的性能。按照設計,CNN 具備基本的多尺度特徵表示能力,因為輸入信息遵循從細到粗的方式。AlexNet 依序堆疊過濾器,與傳統的視覺識別方法相比,性能顯著提高。然而,由於過濾器的網絡深度和內核大小有限,AlexNet只有相對較小的感受野。VGGNet 增加了網絡深度並使用了具有較小內核大小的過濾器。更深的結構可以**擴展感受野,這對於從更大的尺度提取特徵很有用**。**通過堆疊更多層來擴大感受野比使用大內核更有效**。 因此,VGGNet 提供了比 AlexNet 更強的多尺度表示模型,參數更少。 然而,AlexNet 和 VGGNet 都是直接堆棧過濾,這意味著每個特徵層都有一個相對固定的感受野。
> receptive field
>
Network in Network將多層感知器作為微網絡插入到大型網絡中,以增強模型對感受野內局部補丁的判別能力。**NIN 中引入的 1×1 卷積已經成為融合(通道)特徵的流行模塊。GoogLeNet 利用具有不同內核大小的並行濾波器來增強多尺度表示能力**。然而,由於其有限的參數效率,這種能力經常受到計算約束的限制。Inception Nets ,在 GoogLeNet 中並行路徑的每條路徑中堆疊更多過濾器以進一步擴展感受野。另一方面,ResNet 向神經網絡引入了短連接,從而緩解了梯度消失問題,同時獲得了更深的網絡結構。在特徵提取過程中,短連接允許卷積算子的不同組合,從而產生大量等效的特徵尺度。類似地,DenseNet 中的密集連接層使網絡能夠在非常廣泛的範圍內處理對象。[DPN](https://arxiv.org/abs/1707.01629) 將 ResNet 和 DenseNet 結合起來,實現 ResNet 的特徵重用能力和 DenseNet 的特徵探索能力。最近提出的 DLA 方法將層組合成樹狀結構。 層次樹結構使網絡能夠獲得更強的分層多尺度表示能力

### Multi-scale Representations for Vision Tasks
CNN 的多尺度特徵表示對於許多視覺任務非常重要,包括對象檢測、人臉分析、邊緣檢測、語義分割、顯著對象檢測和骨架檢測,提高了模型的性能那些領域
+ object detection
有效的 CNN 模型需要定位場景中不同尺度的對象。早期的工作如 R-CNN 主要依靠骨幹網絡,即 VGGNet 來提取多尺度的特徵。He et al. 提出了一種 SPP-Net 方法,該方法在骨幹網絡之後利用空間金字塔池化來增強多尺度能力。Faster R-CNN 方法進一步提出了 region proposal networks 來生成各種尺度的bounding boxes。 FPN 方法基於 Faster R-CNN,引入特徵金字塔,從單個圖像中提取不同尺度的特徵。SSD方法利用不同階段的特徵圖來處理不同尺度的視覺信息。
+ semantic segmanetation
提取對象的基本上下文信息需要 CNN 模型處理各種尺度的特徵以進行有效的語義分割。Long et al. 提出了一種最早的方法,可以為語義分割任務實現全卷積網絡(FCN)的多尺度表示。在 DeepLab 中,Chen et al. 引入了 並聯(cascaded)空洞卷積 模塊以進一步擴展感受野,同時保留空間分辨率。 最近,通過 PSPNet 中的金字塔池化方案,從基於區域的特徵聚合全局上下文信息

+ Salient object detection
精確定位圖像中的顯著對象區域需要了解用於確定對象顯著性的大尺度上下文信息和準確定位對象邊界的小尺度特徵。早期方法利用手工製作的全局對比度或多尺度區域特徵表示。Li et al.提出了最早的方法之一,可以為顯著對象檢測實現多尺度深度特徵。後來,提出了多上下文深度學習和multi-level卷積特徵來改進顯著目標檢測。最近,Hou et al.在階段之間引入密集的短連接,以在每一層提供豐富的多尺度特徵圖,用於顯著目標檢測
### Concurrent Works

最近有一些作品,旨在通過利用多尺度特徵來提高性能,Big-Little Net 是由不同計算複雜度的分支組成的多分支網絡。[Octave Conv](https://openaccess.thecvf.com/content_ICCV_2019/papers/Chen_Drop_an_Octave_Reducing_Spatial_Redundancy_in_Convolutional_Neural_Networks_ICCV_2019_paper.pdf) 將標準卷積分解為兩種分辨率來處理不同頻率的特徵。[MSNet](https://arxiv.org/pdf/1905.02649.pdf) 利用高分辨率網絡通過使用低分辨率網絡學習的上採樣低分辨率特徵。(utilizes a high-resolution network to learn high-frequency residuals by using the up-sampled low-resolution fea-tures learned by a low-resolution network.)。除了當前工作中的低分辨率表示之外,HRNet 在網絡中引入了高分辨率表示並反复執行多尺度融合以加強高分辨率表示。一個常見操作是它們都使用池化或上採樣將特徵圖的大小重新調整為原始比例的 2n 倍,以節省計算預算,同時保持甚至提高性能。而在 Res2Net 塊中,單個殘差塊模塊中的分層殘差類連接能夠在更細粒度的級別上改變感受野,以捕獲細節和全局特徵。實驗結果表明,Res2Net 模塊可以與那些新穎的網絡設計集成,以進一步提高性能。

## Res2Net
### Res2Net Module
瓶頸結構如圖2所示,是許多現代主幹 CNN 架構中的基本構建塊,例如 ResNet、ResNeXt 和 DLA。我們不是在瓶頸塊中使用一組 3×3 濾波器提取特徵,而是尋求具有更強多尺度特徵提取能力的替代架構,同時保持類似的計算負載。具體來說,我們用較小的過濾器組替換了一組 3×3 過濾器,同時以類似分層殘差的方式連接不同的過濾器組。由於我們提出的神經網絡模塊涉及單個殘差塊內的residual-like連接,我們將其命名為 Res2Net。
如圖2,顯示了瓶頸塊和 Res2Net 模塊之間的差異。經過 1×1卷積後,我們將特徵圖平均分成特徵圖子集,記為 $x_{i}$,其中 $i \in {1,2,3,...,s}$ 。 與輸入特徵圖相比,每個特徵子集 $x_{i}$ 具有相同的空間大小,但通道數為 $1/s$。 除了$x_{1}$ ,每個$x_{i}$ 都有一個對應的3×3卷積,記為$K_{i}()$。我們用$y_{i}$表示$K_{i}()$ 的輸出來表示。特徵子集$x_{i}$ 與$K_{i-1}()$的輸出相加,然後饋入$K_{i}()$。為了在增加的同時減少參數,對於$x_{1}$我們省略了3×3卷積。因此,$y_{i}$ 可以寫成
$$
f(x)=\left\{
\begin{aligned}
\ x_{i} \qquad &x=1;& \\
\ K_{i}(x_{i}) \qquad &i=2;&\\
\ K_{i}(x_{i} + y_{i-1})\qquad &2<i\leq s;&
\end{aligned}
\right.
$$
每個 3×3 卷積算子$K_{i}()$ 可能會從所有特徵分割中${x_{j}, j/leq i}$接收特徵信息。每次一個特徵分割 $x_{j}$ 通過一個 3×3 的捲積算子,輸出結果可以有一個比 $x_{j}$ 更大的感受野。 由於組合爆炸效應,Res2Net 模塊的輸出包含不同數量和不同感受野大小/尺度的組合。
在 Res2Net 模塊中,分割以多尺度方式處理,有利於全局和局部的提取信息。為了更好地融合不同尺度的信息,我們將所有分割連接起來,並通過一個 1×1 卷積傳遞它們。 split(拆分)和concatenate(串聯)策略可以強制卷積更有效地處理特徵。為了減少參數的數量,我們省略了第一次分割的捲積,這也可以看作是特徵重用的一種形式。
在這項工作中,我們使用作為scale維度的控制參數。 越大的s(scale) 濳在地允許學習具有更豐富的感受野大小的特徵,連接引入的計算/記憶體開銷可以忽略不計。
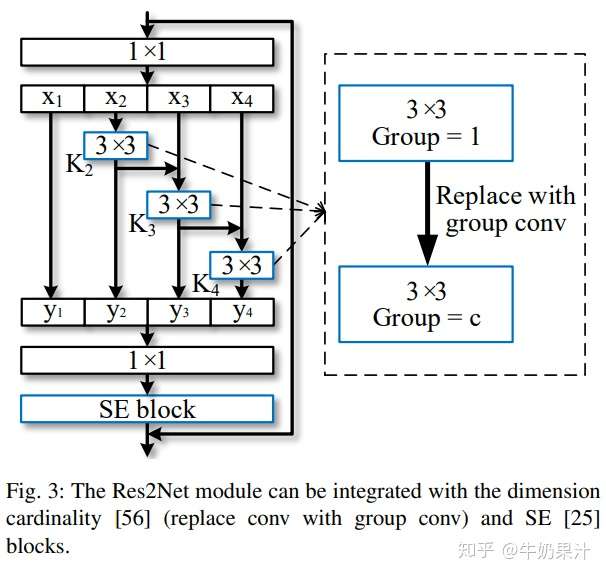
### Integration with Modern Modules
近年來提出了許多神經網絡模塊,包括ResNeXt引入的cardinality維度,以及SENet引入的squeeze和extraction block。
Res2Net 模塊引入了與這些改進正交的scale維度。 圖3,我們可以輕鬆地將cardinality維度和 SE block 與提出的Res2Net 模塊整合。
- Dimension cardinality
維度cardinality 表示過濾器內的組數。該維度將過濾器從單分支變為多分支,提高了 CNN 模型的表示能力。在我們的設計中,我們可以用3×3 group conv.代替3×3 conv.,其中$c$表示組數。 scale維度和cardinality 會在實驗進行比較。
- SE block
SE 模塊通過對通道之間的相互依賴性進行建模來自適應地重新校准通道方面的特徵響應。我們在 Res2Net 模塊的殘差連接之前添加 SE 塊。 Res2Net 模塊可以從 SEblock 的整合中受益,我們已經通過實驗證明了這一點。
### Integrated Models
由於提出的 Res2Net 模塊對整體網絡結構沒有特定要求,並且 Res2Net 模塊的多尺度表示能力與 CNN 的layer-wise feature aggregation 模型正交,因此我們可以輕鬆地將提出的 Res2Net 模塊整合到 最先進的模型,例如 ResNet 、 ResNeXt 、 DLA 和 Big-Little Net 。對應的模型分別稱為 Res2Net、Res2NeXt、Res2Net-DLA 和 bLRes2Net-50。
提出的scale維度與先前工作的基數維度和寬度維度正交。因此,在設置尺度之後,我們調整基數和寬度的值以保持整體模型複雜度與其對應物相似。 我們在這項工作中不專注於減小模型大小,因為它需要更細緻的設計,例如深度可分離卷積、模型剪枝和模型壓縮。
- 對於 ImageNet 數據集的實驗,我們主要使用 ResNet-50、ResNeXt-50、DLA-60 和 bLResNet-50 作為我們的基線模型。 所提出模型的複雜度近似等於基線模型的複雜度,其參數數量約為25M,50層網絡的224×224像素圖像的FLOP數量約為4.2G。
- 對於 CIFAR 數據集的實驗,我們使用 ResNeXt-29, 8c×64w 作為我們的基線模型。
## Experiments
### Implementation details
我們使用 Pytorch 框架實現了提出的模型。 為了公平比較,我們使用了 ResNet、ResNeXt、DLA 和 bLResNet-50 的 Pytorch 實現,並且僅用提議的 Res2Net 模塊替換了原始瓶頸塊。與之前的工作類似,在 ImageNet 數據集上,每個圖像都是從重新調整大小的圖像中隨機裁剪的 224×224 像素。我們使用相同的data augumentation策略。我們在 4 張 Titan Xp GPU 上使用SGD權重衰減為 0.0001、momentum 0.9 和 256 的 mini-batch 訓練網絡。學習率最初設置為 0.1,每 30 個 epoch 除以 10。
ImageNet 的所有模型,包括基線和提出模型,都使用相同的訓練和data augumentation策略訓練 100 個 epoch。 為了測試,我們使用與相同的圖像裁剪方法。在 CIFAR 數據集上,我們使用 ResNeXt-29 的實現。 對於所有任務,我們使用基線的原始實現,僅用提出的 Res2Net 替換主幹模型。
### ImageNet

我們在 ImageNet 數據集上進行了實驗,該數據集包含來自 1000 個類別的 128 萬張訓練圖像和 5 萬張驗證圖像。我們構建了大約 50 層的模型,用於針對最先進的方法進行性能評估。
#### Performance gain
表 1 顯示了 ImageNet 數據集上的 top-1 和 top-5 測試錯誤。 為簡單起見,表 1 中的所有 Res2Net 模型的scale s=4。
1. Res2Net-50 比 ResNet 提高了 1.84% on top-1 error。
1. Res2NeXt-50 在 top-1 error方面比 ResNeXt-50 實現了 0.85% 的改進。
1. Res2Net-DLA-60 在 top-1 error方面比 DLA-60 高 1.27%。
1. Res2NeXt-DLA-60 在 top-1 error方面比 DLA-X-60 高 0.64%。
1. SE-Res2Net-50 比 SENet-50 提高了 1.68%。
1. bLRes2Net-50 在 top-1 error方面比 bLResNet-50 提高了 0.73%
Res2Net 模塊在粒度級別上進一步增強了 bLResNet 的多尺度能力,即使 bLResNet 被設計為利用不同尺度的特徵。注意,ResNet、ResNeXt、SE-Net、bLResNet 和 DLA 是最先進的 CNN 模型。與這些強基線相比,與 Res2Net 模塊集成的模型仍然具有一致的性能提升。
我們還將我們的方法與 InceptionV3 模型進行了比較,後者使用具有不同內核組合的並行過濾器。為了公平比較,我們使用 ResNet-50 作為基線模型,並使用 InceptionV3 模型中使用的 299×299 像素的輸入圖像大小來訓練我們的模型。 提出的 Res2Net-50-299 在 top-1 error 上比 InceptionV3 高 1.14%。 我們得出的結論是,在處理多尺度信息時,Res2Net 模塊的分層殘差連接比 InceptionV3 的並行過濾器更有效。 Incep-tionV3 中過濾器的combination pattern 是專門設計的,而 Res2Net 模塊則呈現了簡單但有效的combination pattern 。

#### Going deeper with Res2Net

對於視覺任務,更深的網絡已被證明具有更強的表示能力。為了以更大的深度驗證我們的模型,我們比較了 Res2Net 和 ResNet 的分類性能,兩者都有 101 層。 如表 2 所示,Res2Net-101 在 top-1 error 方面比 ResNet-101 實現了 1.82% 的顯著性能提升。Res2Net-50 在 top-1 error方面比ResNet-50有1.84%的增益。這些結果表明,所提出的具有額外維度(scale) 尺度的模塊可以與更深的模型集成以獲得更好的性能。我們還將我們的方法與 DenseNet 進行了比較。與官方提供的 DenseNet 系列中性能最佳的模型 DenseNet-161 相比,Res2Net-101 在 top-1 錯誤方面提高了 1.54%。
#### Effectiveness of scale dimension

為了驗證我們提出的維度scale,我們通過實驗分析了不同尺度的影響。如表3所示,性能隨著規模的增加而增加。
隨著規模的增加,14w×8s 的 Res2Net-50 在 top-1 error 方面比 ResNet-50 實現了 1.99% 的性能提升。
注意,在保留複雜度的情況下,$K_{i}()$ 的寬度隨著scale的增加而減少。我們進一步評估了隨著模型複雜性增加而增加scale的性能增益。
26w×8s 的 Res2Net-50 在 top-1 錯誤方面比 ResNet-50 取得了顯著的性能提升,3.05%。
18w×4s 的 Res2Net-50-L 在 top-1 錯誤方面也比 ResNet-50 高 0.93%,只有 69% 的 FLOPs。
表3顯示了不同尺度下的Runtime,即推斷224×224 大小的ImageNet驗證集的平均時間。儘管由於hierarchical connections,特徵split需要按順序計算,但 Res2Net 模塊引入的額外運行時間通常可以忽略。由於 GPU 中可用張量的數量有限,對於 Res2Net 的典型設置,即 s=4,在單個 GPU 時鐘週期內通常有足夠的並行計算。
#### Stronger representation with ResNet
為了進一步探索 Res2Net 的多尺度表示能力,我們遵循 "Bag of tricks for image classification with convolutional neural networks" 修改 Res2Net,並使用數據增強技術(即 CutMix )訓練模型。Res2Net 的修改版本,即 Res2Net v1b,大大提高了 ImageNet 上的分類性能,如表1所示。 Res2Net v1b 進一步提高了模型在downstream tasks 上的性能。 我們分別在表 5、表 8 和表 10 中展示了 Res2Net v1b 在對象檢測、實例分割、關鍵點估計方面的性能。

Res2Net 更強的多尺度表示已在許多downstream tasks上得到驗證,即vectorized road extraction 、物體檢測、弱監督語義分割、顯著物體檢測、交互式圖像分割、視訊識別、隱蔽物體檢測、醫學分割。半監督知識蒸餾解決方案也可以應用於Res2Net,在ImageNet上達到85.13%top。
### CIFAR

我們還在 CIFAR-100 數據集上進行了一些實驗,其中包含來自 100 個類別的 50k 個訓練圖像和 10k 個測試圖像。 The ResNeXt-29, 8c×64 用作基線模型。 我們只用我們提出的 Res2Net 模塊替換原始基本塊,同時保持其他配置不變。
表 4 顯示了 CIFAR-100 數據集上的 top-1 測試誤差和模型大小。 實驗結果表明,我們的方法超越了基線和其他參數較少的方法。
1. * 我們提出的Res2NeXt-29,6c×24w×6s 優於基線1.11%。Res2NeXt-29, 6c×24w×4s 甚至優於ResNeXt-29, 16c×64w,只有35%的參數。
1. * 與 DenseNet-BC 相比,我們還以更少的參數實現了更好的性能。
1. 與Res2NeXt-29相比,6c×24w×4s,Res2NeXt-29,8c×25w×4獲得了更好的結果,具有更多的寬度和基數,表明維度尺度與維度寬度和基數是正交的。
我們還將最近提出的 SE 塊集成到我們的結構中。 在參數較少的情況下,我們的方法仍然優於 ResNeXt-29, 8c×64w-SE baseline
### Scale Variation
我們通過增加不同的 CNN 維度scale、cardinality和depth 來評估基線模型的測試性能。在使用一個維度增加模型容量的同時,我們固定所有其他維度。 在這些變化下訓練和評估了一系列網絡。 由於已經表明增加基數比增加寬度更有效,我們只將
scale與cardinality和depth進行比較

圖五,顯示了 CIFAR-100 數據集上關於模型大小的測試精度。 基線模型的深度、基數和尺度分別為 29、6 和 1。 實驗結果表明,scale是提高模型性能的有效維度。此外,增加規模比其他維度更有效,導致更快的性能提升。 如方程1和圖 2 中所述。對於scales=2的情況,我們只增加了1×1個filters的更多參數來增加模型容量。
* 因此,s=2的模型性能比增加cardinality的性能略差。
* 對於s = 3,4,我們的分層殘差結構的組合效應產生了豐富的等效scale set,從而顯著提高了性能。
* scale = 5, 6 的模型的性能提升有限,我們假設 CIFAR 數據集中的圖像太小而不能有很多scale。
### Class Activation Mapping(CAM)

為了理解 Res2Net 的多尺度能力,我們使用 Grad-CAM 可視化類激活映射,它通常用於定位圖像分類的判別區域。在圖4所示的可視化示例中。較強的CAM區域被較淺的顏色覆蓋。
* 與ResNet相比,基於Res2Net的CAM結果在“棒球”和“企鵝”等小物體上具有更集中的激活圖。
* 兩種方法在中等大小的對像上都有類似的激活圖,例如“冰淇淋”。
* 由於具有更強的多尺度能力,Res2Net 的激活圖傾向於覆蓋大物體上的整個物體,如“bulbul”、“山狗”、“圓珠筆”和“清真寺”,而 ResNet 的激活圖僅覆蓋對象的部分。
這種精確定位 CAM 區域的能力使 Res2Net 對弱監督語義分割任務中的對象區域挖掘具有潛在價值
### Object Detection

對於目標檢測任務,我們在 PAS-CAL VOC07 和 MS COCO 數據集上驗證 Res2Net,使用 Faster R-CNN 作為基線方法。 我們使用 ResNet-50 與 ResNet-50 的主幹網絡。 Res2Net-50,並遵循所有其他實現細節以進行公平比較。 表 5 顯示了目標檢測結果。 在 PASCAL VOC07 數據集上,基於 Res2Net-50 的模型在平均精度上優於其對應模型 2.3%。 在 COCO 數據集上,基於 Res2Net-50 的模型在 AP 上的性能優於其對應模型 2.6%,在 AP@IoU=0.5 上的性能為 2.2%。
我們進一步測試了不同大小對象的 AP 和平均召回分數(AR),如表6所示 根據大小將對象分為三類。基於 Res2Net 的模型在小、中、大物體的AP 上比同類模型有很大的改進幅度分別為 0.5%、2.9% 和 4.9%。
AR對小、中、大物體的提升分別為1.4%、2.5%和3.7%。 由於具有強大的多尺度能力,基於 Res2Net 的模型可以覆蓋大範圍的感受野,提高對不同尺寸對象的性能。
### Semantic Segmentation

語義分割需要 CNN 強大的多尺度能力來提取對象的基本上下文信息。 因此,我們使用 PASCAL VOC12 數據集評估 Res2Net 在語義分割任務上的多尺度能力。 我們按照之前的工作使用增強的 PASCAL VOC12 數據集,其中包含 10582 個訓練圖像和 1449 個圖像。 我們使用 Deeplab v3+ 作為我們的segmentation method。 除了主幹網絡被 ResNet 和我們提出的 Res2Net 替換外,所有實現都與 Deeplabv3+ 相同。 用於訓練和評估的輸出步幅都是 16. 如表 7 所示,基於 Res2Net-50 的方法在平均 IoU 上優於其對應方法 1.5%。並且基於 Res2Net-101 的方法在平均 IoU 上比同類方法高 1.2%。具有挑戰性的示例的語義分割結果的視覺比較如圖 6 所示。 **基於 Res2Net 的方法傾向於對對象的所有部分進行分割,而不管對像大小**

### Instance Segmentation

實例分割是物件檢測和語義分割的結合。它不僅需要正確檢測圖像中各種尺寸的物體,還需要對每個物體進行精確分割。物體檢測和語義分割都需要CNNs強大的多尺度能力。 因此,多尺度表示非常有利於實例分割。我們使用Mask R-CNN作為實例分割方法,並用我們提出的Res2Net替換ResNet-50的骨幹網絡。實例分割在 MS COCO 數據集上的性能見表 8。基於Res2Net-26w×4s的方法分別在$AP$ 1.7% 和$AP_{50}$ 2.4% 的提升。還展示了不同尺寸物體的性能提升。小、中、大物體的AP提升分別為0.9%、1.9%和2.8%。 表 8 還展示了 Res2Net 在相同複雜度下不同尺度下的性能比較。隨著scale的增加,總體效能呈上升趨勢。與 Res2Net-50-48w×2s 相比,Res2Net-50-26w×4s 的 $AP_{L}$ 提高了 2.8%,而 Res2Net-50-48w×2s 與 ResNet-50 相比具有相同的 $AP_{L}$。
我們假設大型物體的性能提升得益於額外的scales。當scale相對較大時,性能提升並不明顯。 Res2Net 模塊能夠學習合適的感受野範圍。 當圖像中物體的規模已經被 Res2Net 模塊中的可用感受野覆蓋時,性能提升是有限的。**在固定複雜度的情況下,增加的scale導致每個感受野的通道更少,這可能會降低處理特定尺度特徵的能力**
### Salient Object Detection

顯著物體檢測這樣的像素級任務也需要 CNN 強大的多尺度能力來定位整體物體及其區域細節。這裡我們使用[Deeply supervised salient object detection with short connections
](https://arxiv.org/abs/1611.04849)作為我們的基線。 為了公平比較,我們只用 ResNet-50 和我們提出的 Res2Net-50 替換主幹,同時保持其他配置不變。 接下來,我們使用 MSRA-B dataset 訓練這兩個模型,並在 ECSSD、PASCAL-S、HKU-IS 和 DUT-OMRON 數據集上評估結果。F-measure 和Mean Absolute Error(MSE)差用於評估。如表 9 所示,與所有數據集的對應模型相比,基於 Res2Net 的模型具有一致的改進。在 DUT-OMRON 數據集上,與基於 ResNet 的模型相比,基於 Res2Net 的模型在 F-measure 上有 5.2% 的改進,在 MAE 上有 2.1% 的改進。 基於 Res2Net 的方法在 DUT-OMRON 數據集上實現了最大的性能提升,因為與其他三個數據集相比,該數據集包含最顯著的對像大小變化。 在具有挑戰性的示例上的顯著目標檢測結果的一些視覺比較如圖 7 所示。

### Key-points Estimation

人體部位大小不一,這就需要關鍵點估計方法來定位不同尺度的人體關鍵點。為了驗證 Res2Net 的多尺度表示能力是否有利於關鍵點估計任務,我們使用 ["Simple Baselines for Human Pose Estimation and Tracking"](https://arxiv.org/abs/1804.06208) as SimpleBaseline 作為關鍵點估計方法,並且只用提出的 Res2Net 替換了主幹。包括訓練和測試策略在內的所有實現都與 SimpleBaseline 相同。 我們使用 COCO 關鍵點檢測數據集訓練模型,並使用 COCO validation set 評估模型。 按照常見設置,我們在 SimpleBaseline 中使用相同的個人檢測器進行評估。 表 10 顯示了使用 Res2Net 在 COCO validation set 上進行關鍵點估計的性能。 基於 Res2Net-50 和 Res2Net-101 的模型在 AP 上的性能分別比基線高 3.3% 和 3.0%。 此外,與基線相比,基於 Res2Net 的模型在不同尺度的人類上具有可觀的性能提升。
## Conclusion and future work
我們提出了一個簡單而有效的block,即 Res2Net,以在更細粒度的級別上進一步探索 CNN 的多尺度能力。 Res2Net 公開了一個新維度,即“尺度”,這是除了現有深度、寬度和基數維度之外的一個重要且更有效的因素。我們的 Res2Net 模塊可以與現有的最先進方法集成,with no effort。 CIFAR-100 和 ImageNet 基准上的圖像分類結果表明,我們的新骨幹網絡始終優於其最先進的競爭對手,包括 ResNet、ResNeXt、DLA 等。
幾個有代表性的計算機視覺任務,包括類激活映射、對象檢測和顯著對象檢測,我們相信多尺度表示對於更廣泛的應用領域是必不可少的。 為了鼓勵未來的工作利用 Res2Net 強大的多尺度能力,源程式碼可在 https://mmcheng.net/res2net/ 上獲得。
## 參考資料
- [Res2Net: A New Multi-scale Backbone Architecture](https://arxiv.org/abs/1904.01169)