### [AI / ML領域相關學習筆記入口頁面](https://hackmd.io/@YungHuiHsu/BySsb5dfp)
#### Reinforcement learning
- [[RL] Fine-Tuning Language Models from Human Preferences (RLHF)論文筆記](https://hackmd.io/@YungHuiHsu/Sy5Ug7iV6)
- [[RL] Proximal Policy Optimization(PPO)](https://hackmd.io/@YungHuiHsu/SkUb3aBX6)
- [[RL] Q learning 與 Deep Q Network(DQN)](https://hackmd.io/@YungHuiHsu/BJgnMHbUH6)
---
# [RL演算法] Proximal Policy Optimization(PPO)
PPO,或稱為Proximal Policy Optimization,是一種在強化學習領域廣泛使用的演算法,主要用於訓練代理(agent)在給定的環境中進行最佳決策
### 直觀理解:
玩一個遊戲時需要學習怎麼獲得最高分。PPO就像一個超級遊戲教練,它會告訴你根據你當前的狀態,應該採取什麼動作才能獲得最好的結果。當你按照教練的建議去做時,你會得到一些分數(獎勵),並且教練會根據你獲得的分數來調整它的建議,讓你下次能做得更好。
PPO會設法平衡學習新技巧與堅持已經學到的好技巧之間的關係。它不希望你的策略變化太快,這樣可以避免學到一些壞策略,這點像是教練想要確保你不會因為嘗試新動作而忘記了基本技巧。
### 演算法說明
PPO是一種在策略空間進行優化的演算法,用於強化學習。它的核心思想是在**保證新策略與舊策略不會差異太大的前提下,尋找一個性能更好的策略**。這個特性通過一個被稱為「信賴區域(Trust region)」的概念來實現,這使得每一步更新都不會讓策略偏離太遠,從而避免了訓練過程中的不穩定現象。
PPO的目標函數$L(\theta)$結合了策略的性能以及新舊策略之間的差異表示:
$$
L(\theta) = \hat{\mathbb{E}} \left[ \min\left( r(\theta) \hat{A}_t, \text{clip}(r(\theta), 1-\epsilon, 1+\epsilon) \hat{A}_t \right) \right]
$$
其中,
- $\hat{\mathbb{E}}$表示對樣本的期望值
- $r(\theta)$ 是機率比率 $\frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{old}}(a_t|s_t)}$,表明了在新策略下選擇動作與舊策略下選擇動作機率的比例;
- $\hat{A}_t$ 是優勢函數(advantage function),用來估計在狀態 $s_t$下採取動作 $a_t$比平均更好多少;
- $\text{clip}$ 函數將 $r(\theta)$的值限制在 $[1-\epsilon, 1+\epsilon]$的範圍內,這樣就避免了過大的策略更新
#### pseudo code 示意
- loss
```python=
import numpy as np
def ppo_loss(old_probs, new_probs, advantage, epsilon=0.2):
"""
Compute the PPO loss.
old_probs: Probability of taking actions in each state as per the old policy.
new_probs: Probability of taking actions in each state as per the new policy.
advantage: Estimated advantage for each action at each state.
epsilon: Hyperparameter that dictates how much the policy can change (usually small, like 0.1 or 0.2).
Returns the PPO loss.
"""
r_theta = new_probs / old_probs
clipped_r_theta = np.clip(r_theta, 1 - epsilon, 1 + epsilon)
loss = -np.mean(np.minimum(r_theta * advantage, clipped_r_theta * advantage))
return loss
```
## Reference
#### OPENAI官方BLOG[2017.07。openai。Proximal Policy Optimization](https://openai.com/research/openai-baselines-ppo)
> PPO has become the default reinforcement learning algorithm at OpenAI because of its ease of use and good performance
> Policy gradient methods are fundamental to recent breakthroughs in using deep neural networks for control
#### [2024.01。。Preference Tuning LLMs with Direct Preference Optimization Methods](https://huggingface.co/blog/pref-tuning)
* **直接偏好優化Direct Preference Optimizatio(DPO)**
* 概念:DPO 透過在偏好資料集上優化簡單的損失函數,來使大型語言模型(LLMs)與人類偏好對齊
* 過程:它使用由提示($x$)和配對回應組成的偏好資料,其中一個被偏好($y_w$),另一個則不被偏好($y_l$)
* 應用:實務上簡單直接,已成功應用於如Zephyr和Intel的NeuralChat等模型
* 優點:實際應用中的簡便性
* **身份偏好優化Identity Preference Optimisation(IPO)**
* 概念:IPO 在 DPO 損失中加入一個規範項,讓模型可以進行到收斂,無需像早停(early stopping)這樣的技巧
* 目標:旨在解決 DPO 可能在偏好資料集上過度擬合的問題,提供穩健性
* **Kahneman-Tversky 優化(KTO)**
* 概念:KTO 通過定義單個範例的損失函數來省略配對偏好資料的需要,這些範例被標記為“好”或“壞”
* 資料:這些標籤更容易獲得,可用於實際環境中不斷更新聊天模型
:::success
- **DPO is the most robust and best performing** LLM alignment algorithm. KTO remains an interesting development
- Both DPO and IPO require pairs preference data, whereas KTO can be applied to any dataset where responses are rated positively or negatively.
- We have empirically demonstrated that **DPO** and **IPO** can achieve comparable results, outperforming **KTO** in a paired preference setting.
:::


> - **$β$**
> - 在損失函數中reward model的偏好被賦予多少重要性
> - 越高表示reward model的偏好將對最終的損失函數有較大的影響
> - **MT Bench Scores**
> - 用來評估和比較大型語言模型在多種對話任務上的性能的一種測試工具。
> - 這些任務包括但不限於寫作、角色扮演、邏輯推理、數學問題解答、編碼、信息提取、科學技術工程數學(STEM)領域的問題和人文科學問題等。數值越高越好
#### [2023.10。紫气东来。NLP(十五):反思RLHF,如何更加高效训练有偏好的LLM](https://zhuanlan.zhihu.com/p/634707485)
:muscle: [DPO(Direct Preference Optimization)](https://arxiv.org/pdf/2305.18290.pdf)最近有效的模型訓練改進方案
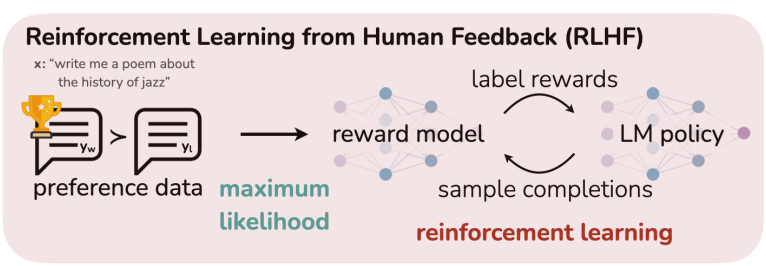

> [DPO(Direct Preference Optimization)](https://arxiv.org/pdf/2305.18290.pdf) 提出了一种使用二进制交叉熵目标来精确优化LLM的方法,以替代基于 RL HF 的优化目标,从而大大简化偏好学习 pipeline。也就是说,完全可以直接优化语言模型以实现人类的偏好,而不需要明确的奖励模型或强化学习。
>
> 与现有的算法一样,DPO 也依赖于理论上的偏好模型(如 Bradley-Terry 模型),以此衡量给定的奖励函数与经验偏好数据的吻合程度。然而,现有的方法使用偏好模型定义偏好损失来训练奖励模型,然后训练优化所学奖励模型的策略,而** DPO 使用变量的变化来直接定义偏好损失**作为策略的一个函数。鉴于人类对模型响应的偏好数据集,DPO 因此可以使用一个简单的二进制交叉熵目标来优化策略,而不需要明确地学习奖励函数或在训练期间从策略中采样。
>
#### [2023.03。PPPerry1。Proximal Policy Optimization (PPO) 算法理解:从策略梯度开始](https://zhuanlan.zhihu.com/p/614115887)

Direct Preference Optimization:
Your Language Model is Secretly a Reward Model
#### [2019.05。魏思齐。【李弘毅深度强化学习】2,Proximal Policy Optimization (PPO)](https://zhuanlan.zhihu.com/p/66302483)

- PPO演算法(TRPO)
PPO(Proximal Policy Optimization)的目標是最大化一個目標函數,這個函數考慮了策略性能的改進與新舊策略之間的KL散度(Kullback-Leibler divergence)。KL散度是一種測量兩個機率分布差異的方法。在這裡,它用來確保新策略不會與舊策略差異太大,以此來維持學習的穩定性。PPO算法的目標函數可以表示為:
$$
J^{\theta^K}_{PPO} (\theta) = J^{\theta^K} (\theta) - \beta \text{KL}(\theta, \theta^{K})
$$
其中,$J^{\theta^K} (\theta)$ 是舊策略的性能,$\text{KL}(\theta, \theta^{K})$ 是新舊策略之間的KL散度,$\beta$ 是一個權重系數。
- PPO2演算法(即主文目前介紹的主流PPO演算法)
PPO2是對PPO的一種改進,它用一個較為簡單的方法來近似KL散度限制。公式中的min函數和clip函數的使用是為了確保策略更新保持在一定的範圍內,這個範圍是由超參數$\epsilon$定義的。
PPO2算法的目標函數可以表示為:
$$
J^{\theta^K}_{PPO2} (\theta) \approx \sum_{(s_t,a_t)} \min \left( \frac{p_\theta(a_t|s_t)}{p_{\theta^{K}}(a_t|s_t)} A^{\theta^K}(s_t, a_t), \text{clip} \left( \frac{p_\theta(a_t|s_t)}{p_{\theta^{K}}(a_t|s_t)}, 1 - \epsilon, 1 + \epsilon \right) A^{\theta^K}(s_t, a_t) \right)
$$
這裡:
- $p_{\theta}(a_t|s_t)$ 是在策略$\theta$下,選擇動作$a_t$給定狀態$s_t$的機率。
- $A^{\theta^K}(s_t, a_t)$ 是在舊策略下,狀態$s_t$採取動作$a_t$的優勢函數。

圖中的線條表示了當優勢函數$A$大於0時(表示這個動作比平均策略要好)和小於0時(表示這個動作比平均策略要差)的策略更新限制。
- 綠色的方塊表示原始的機率比率,而紅色和藍色的線表示clip函數施加的上下界限制。這確保了策略更新不會過大,從而使學習過程更加穩定。
這種方法的好處是它相比於原始的PPO算法,減少了對KL散度精確計算的需要,從而簡化了演算法的實現和提高了計算效率。