---
tags: COTAI LHP
---
# Lecture Notes ML4AI 2021
---
tags: COTAI AI4HighSchool
slideOptions:
transition: slide
width: 1920
height: 1080
margin: 0.1
minScale: 0.2
maxScale: 1.5
---
## ML4AI Midterm Questions (written exam, open book, 1 hour)
Students **copy Markdown code** of these questions to their Lecture notes and write down solutions in there.
1. [**5** Point] Given a set of inputs $(X^1,\dots,X^N)$, we use PCA to represent them as $X^t = X_0 + z_1U_1+\dots+z_nU_n$ with $X_0$ the mean input and $U_i$ the orthonormal principal components.
- [**2** Points] Write down equation for $X_0$, and equations for properties of $U_i,U_j$: unit length & mutual orthogonal. **Solution**: Mean: $\frac{1}{N}\sum_{i=1}^N X_i$. Unit length: $d(A,B) = \sqrt{(x_1 - x_2)^2 + (y_1 - y_2)^2 + \cdots + (z_1 - z_2)^2}$. Mutual Orthogonal: $\mathbf{A \times B }=0$
- [**1** Point] We need to reduce the dimensions of $X^t$ to visualize them on 2D. What is the embedding vector ${\bf z}^t$ of $X^t$ if we use only 2 first principal components to represent it? What is the last feature of ${\bf z}^t$ in this case? **Solution**:
- [**1** Point] What are the main differences between representations by PCA and by sparse coding? **Solution**: PCA không có sparse
- [**1** Point] If we cluster the dataset into 3 groups with centroids $({\bf m}_1, {\bf m}_2, {\bf m}_3),$ what is the label embedding coordinates of $X^t$ if it belongs to cluster 2? **Solution**: (0,1,0)
2. [**1** Point] If we use each song as a feature to represent the users, what is the embedding coordinates ${\bf z}_A$ of user A in the dataset below? **Solution**:$z_A=\begin{bmatrix} \text{Mưa nửa đêm}
\\ \text{Cỏ úa}
\\ \text{Vùng lá me bay}
\\ \text{Con cò bé bé}
\\ \text{Em yêu trường em}
\end{bmatrix}$

3. [**3** Point] From the general form of linear predictors: $\hat{y}=\mathsf{s}(Wz+b)$ with $\mathsf{s}(\cdot)$ a transfer function for desired output interpretation.
- [**1** Point] What is $W$ for
- 1 dimentional linear regression? **Solution**: là các giá trị input
- sofmax regression with 3 classes? **Solution**: là các input gồm 3 classes khác nhau
- [**1** Point] What is function $\mathsf{s}(\cdot)$ for
- 1 dimentional linear regression? **Solution**: là không có
- SVM binary classification? **Solution**: là sigmoid
- [**1** Point] Why logistic regression (for binary classification) has only 1 probability output while there are 2 classes? **Solution**: Vì LR đó có xài sigmoid funnction
4. [**2** Points] Evaluation procedure
- [**1** Point] Explain the main use of the train--dev (validation)--test sets. **Solution**: Tập train là tập dùng để huấn luyện trong machine learning. Tập test dùng để kiểm tra độ chính xác sau khi huấn luyện xong tập train rồi mang vào thực tế. Tập dev dùng để lấy ra mô hình nào chính xác nhất trong tất cả mô hình trong tập train để đưa cho tập test
- [**1** Point] What are the main similarity and differences between linear SVM and logistic regression? **Solution**: Giống nhau là SVM là tối đa hóa các véc tơ bên lề gần nhất, còn LR là tối đa hóa các khả năng . Khác nhau ở chỗ SVM muốn tìm line sao cho có margin lớn nhất còn LR thì không, LR chỉ có thể tìm ra được các decision boundary với các weight khác nhau
5. [**2** Points] There are **1100 items** and **one million users**. We need to build a content-based RecSys by extracting **120 features** ${\bf z}_i$ describing each item $i$ then learn a classifier ${\bf \theta}_j$ for each user $j$ to predict **ratings from 1 to 5 stars** of each user for each item.

- [**1** Point] How many classes do we need? **Solution**:120
- [**1** Point] What is the size of $W$ if we use softmax regression $\hat{y}=s(Wz+b)$ for to classify ratings? **Solution**:
6. [**2** Points] Nonlinear predictors have general form $\hat{y}=s(W'\phi(z)+b')$. For Multilayer Perceptrons (MLP) in particular: $\phi(z) = \gamma(Wz+b)$ recursively, each called a "hidden layer".
- [**1** Point] Give explicit equation of an MLP with 2 hidden layers. **Solution**:$\mathbf{s}(\mathbf{W_2}(\gamma(\mathbf{W_1}z+b_1)+b_2)))$
- [**1** Point] What are the parameters of the fully-connected layer in your equation? **Solution**: Các nodes ở input layer nhân các nodes ở hidden layer đầu tiên + các nodes ở hidden layer đầu tiên nhân cho layer thứ 2 + các nodes ở layer thứ 2 nhân cho nodes ở output layer + 2 (là 2 bias)
7. [**2** Points] Kernel machines use "kernel trick" $\phi(z_i)\cdot\phi(z_j) = \kappa(z_i,z_j)$.
- [**1** Point] Explain why kernel trick is useful. **Solution**: Kernel trick có thể chuyển từ linear model sang non-linear model nên có thể giải được các bài toán phức tạp.
- [**1** Point] Explain how we can use kernel trick in feature-space prediction $\hat{y}=s(W^\phi\phi(z)+b)$ to turn a linear predictor into a nonlinear one. **Solution**:
---
## Midterm Coding (1 hour)
[Đề thi](https://colab.research.google.com/drive/1WuytAqhN_6EBZQK-0S7YYDiiu_MHy41V?usp=sharing).
## Section 1: Linear Predictors
Data = {đầu vào -x,đầu vào- y} ví dụ căn nhà có giá 3 tỉ 2
Prediction = dự đoán xem cái nhà đó giá bao nhiêu
=> Machine learning(Performance Measure)
1. Để dự đoán tốt ta cần chiết xuất đặc trưng ($x\xrightarrow{}$ )
X ----> Z qua một cái mẫu gọi là B - Basic
2. Từ Z ---> Y qua hàm tuyến tính(linear predictors)
Giá trị Z cho biết mức độ của đặc trưng
Z được gọi là Embedding space(không gian nhúng)
Z tốt thì ra sẽ tốt
3. Giá trị input và output
Dữ liệu rời lạc(Discrete)
Dữ liệu liên tục (Continous)
Dữ liệu ẩn(Nominal)
Dx liệu theo thứ tự(Ordinal)
* Gồm 2 loại bài toán dự báo là regression (liên tục) và classfication(rời rạc)
4 Khi phân nhóm theo ý của ta gọi là classfication (có trì bảo) ví dụ phân động vật thì phân con A là con dê con B là con chó ...
khi phân nhóm theo ý của máy tính gọi là clustering (không có trì bảo) ví dụ con A và con B là động vật có 2 chân con C và D là động vật 4 chân...
5 Bài toán tuyến tính
Giá trị dự đoán = Mô hình Z * mô hình W + b
Sử dụng tích chấm để tính tích của mô hình Z và mô hình W
Sai số = Giá trị gốc - Giá trị dự đoán
Lấy tổng bình phương của sai số chúng ta sẽ suy ra được mô hình W là tốt hay xấu
6 So khớp: đo sự giống nhau
Sử dụng tích chấm để so khớp: linear combination
Sử dụng bằng khoảng cách để so khớp
* có thể sử dụng góc. ví dụ:cos(A)= (tích chấm)/(khoảng cách)
Phân loại bằng kNN:
p/s: [gradient descent](https://machinelearningcoban.com/2017/01/12/gradientdescent/)
**Sự khác biệt giữa MAE, MSE và RMSE**
Mean Absolute Error (MAE): This measures the absolute average distance between the real data and the predicted data, but it fails to punish large errors in prediction.
Mean Square Error (MSE): This measures the squared average distance between the real data and the predicted data. Here, larger errors are well noted (better than MAE). But the disadvantage is that it also squares up the units of data as well. So, evaluation with different units is not at all justified.
Root Mean Squared Error (RMSE): This is actually the square root of MSE. Also, this metrics solves the problem of squaring the units.
## Section 3: Power-up: Transformations & Nonlinear Predictors
#### Ôn lại bại 1
Từ $x\overset{}{\to}y$ chia làm 2 bài toán regression và classfication
prediction score đẹp thì phải đưa qua các hàm chuẩn hóa như hàm softmax
công thức của linear predictor chung là $\hat{\bf y} = \mathsf{s} (Wz+{\bf b})$
* đối với bài toán regression thì s là ko có j cả
* đối với bài toán classfication thì s có thể là softmax sigmoid,... đầu ra sẽ là niềm tin
* Z là đặc trưng ($\text{Input}X\xrightarrow{B_1,B_2,B_3,\cdots}{\begin{bmatrix} Z_1
\\ Z_2
\\ Z_3
\\ \cdots
\end{bmatrix}}$ và B có vai trò là filters, kennels, patterns)
**=> Mở rộng mô hình công thức trên sẽ là nonlinear predictor**
#### Nonlinear Predictor
##### _Vì sao lại có nonlinear?_
* Khi các điểm rời rạc nhau thì linear sẽ không đúng không có độ chính xác cao bởi vậy cần có các đường non linear để dự đoán tốt hơn
* Trong trường hợp có các điểm đầu vào x nằm rải rác nhau(noisy) thì khó mà có thể tách nhau ra bằng linear được và sẽ xảy ra một số lỗi nên không thể hoàn hảo được
##### _Decision Boundary là gì?_
* Là vùng mà ta không biết được ở đú thuộc classfication nào(hay còn nói cách là prediction score và niềm tin bằng nhau)
* Vùng đó có thể là đường thẳng hoặc đường cong tùy trường hợp
* Ví dụ 
##### _Transformation là gì?_
* Transformation là biến đổi dữ liệu vào một vùng không gian mới và có thể chia cắt được (Khi để trong không gian Z mà chỉ có thể chia cắt bằng nonlinearly separable thì cần phải transform sang một không gian Z' để có thể chia cắt bằng linearly separable)
##### _Linear transform và Nonlinear transform_
* Linear transform là khi đầu vào là phẳng và đẩu ra cũng là phẳng
1) Sử dụng ma trận A thì đầu ra Z' = AZ
* Nonlinear transform là khi đầu vào là phẳng mà đầu ra là cong
1) Đầu tiên là xoay rồi co giãn rồi xoay (chưa bị méo mó)(linear transform)(đây là cốt lõi của đại số tuyến tính)
- [SVD](https://en.wikipedia.org/wiki/Singular_value_decomposition): $\forall A_{m\times n} = U_{m\times m}\sum_{m\times n}V_{n\times n}^T$
2) Sử dụng ma trận A nhân vào rồi sử dụng công thức $\phi(z) = \gamma (AZ+b)$ để bóp méo đầu ra
Trong $\gamma$ sẽ là các [Activation function](https://vi.wikipedia.org/wiki/H%C3%A0m_k%C3%ADch_ho%E1%BA%A1t) mà thường sử dụng hàm ReLU
Có 4 cách:
* Feature engineering: thiết kế hàm (hand-crafted)
* MLP(Multi layer perception)(Ngoài ra còn được gọi là Feed Forward Neuron Network): chồng mô hình lên($Z\overset{}{\to}Z'\overset{}{\to}Z''\overset{}{\to}\cdots$ và sẽ ra được không gian linear separable)
-Ngoài ra còn công thức $\hat{\bf y}={\bf s}(W_L\cdots\gamma(W_2(\gamma(W_1z+b_1)+b_2)+b_L)$
-Mô hình cơ bản trong MLP là:

-Chú thích: Layer đầu tiên là input layer, các layer ở giữa được gọi là hidden layer và layer cuối gọi là out =put layer và cá chấm tròn là các node hay còn được gọi là unit
-Mỗi node trong hidden layer và output layer : liên kết với tất cả các node ở layer trước đó với các hệ số w(weight) riêng và mỗi node có 1 hệ số bias b riêng.
-Có thể tìm hiểu thêm tại [đây](https://nttuan8.com/bai-3-neural-network/)
* Kernel machines: có công thức $\phi(z_i)\cdot\phi(z_j) = \kappa(z_i,z_j)$ [kernel trick](https://machinelearningcoban.com/2017/04/22/kernelsmv/)
* Locally linear: (chia nhỏ không gian đầu vào và mỗi không gian nhỏ sử dụng linear model khác nhau)
#### P/s
##### _Cách nhân ma trận?_
$C_{m\times p}=A_{m\times n}B_{n\times p}$ : $c_{ij}=a_{i1}b_{1j}+a_{i2}b_{2j}+\cdots +a_{in}b_{nj}=\sum_{k=1}^n a_{ik}b_{ki}$

##### _Công thức transformation để từ một không gian non linear separable thàn một không gian có thể linear separable?_
* $z = (x,y)\in\mathbb{R}^2\xrightarrow{features \:\phi(z)}z'=(x,y,h=x^2+y^2)\in\mathbb{R}^3$
## Section 4 RecSys: Recommender Systems
### Những ứng dụng của Recsys:
- Trong marketing có sử dụng các thuật ngữ như:
*Cross-sell: Người mua muốn khách mua sản phẩm dịch vụ khách với cái ban đầu họ mua.*
*Upsell: Người bán muốn khách mua một sản phẩm đắt hơn hoặc cố bán thêm sản phẩm để tăng lợi nhuận biên.*
- Trong Youtube khi mính nghe 1 bài nhạc thì hệ thống tự động gợi ý cho mình nghe thêm 1 bài khác
$\rightarrow$ RecSys là hệ thống làm cho các công ty đứng đầu như amazon, tiktok, google
### Làm sao để Recsys hoạt động tốt:
1. Có khả năng khái quát hóa: khái quát nhiều sản phẩm hay khái quát hóa những người dùng, quan sát họ rồi dự đoán những sản phẩm
2. Có sự cá nhân hóa(Personalization)
### Về bài toán Recsys:
Có 2 nhóm:nhóm người dùng và nhóm sản phẩm
Có những loại rating khác nhau như: thích-không thích; 1-5 sao; nghe 1 lần hay nghe nhiều lần
-->Output: là dự báo khuyến khích cho người dùng xài thử (thích hay không)
Có 2 cách:
User-based filtering: Dựa vào người dùng
Item-based filtering: Dựa vào sản phẩm
*Trong recsys: Ngòai input là những người dùng mua cái gì, rating bao nhiêu thì còn input khác như sử dụng website nào khối lượng như thế nào,...
### Giới thiệu vài giải thuật:
1. Collaborative filtering(CF)
- Phương pháp thứ 1: Item-based CF
- Bước 1: Hình thành ma trận: người dùng, sản phẩm rating
- Bước 2: Chuyển ma trận sang tọa độ nhúng Z(coi người dùng như là một đặc trưng)
- Bước 3: tính cosine similarity để đo độ giống nhau
- Bước 4: Tính cái rating dựa vào similarity

- Phương pháp thứ 2: User based CF

- Phương pháp thứ 3: Phân tách ma trận
- CF có một lợi thế rất lớn là có thể hoạt động với bất kỳ item nào nhưng cũng có nhiều khó khăn:
- Cold Start: cần phải có nhiều users
- Sparsity: Những ma trận users hay rating đều rải rác
- Khó mà recommend được những item không tốt
2. Personalized recommender

## Session 5: Evaluation: Metrics and losses
### Mục tiêu cần phải biết
- Hiểu được tầm quan trọng của việc đánh giá của mô hình
- Hiểu được cách thức hoạt động của nó
### Làm sao để đánh giá 1 mô hình?
- Công thức: $\text{Input }X\xrightarrow[B_\beta]{Features} \text{Embedding Coordinates Z}\xrightarrow[P_\theta]{Predictor}\text{Prediction } \hat{Y}$
- Cho tập hợp N các ví dụ $\mathcal{D}=\{ (x^t,y^t) \}_{t=1}^N$ , đưa ra đầu ra $\{ \hat{y}^t \}_{t=1}^N$ tương ứng với $\hat{y}^t=f(x^t)$
- Để biết f có tốt không thì cần chuẩn đánh giá(evaluation metric, loss) gọi chung là $\mathcal{P}$
- Cho $\mathcal{P}$ là một con số để thể hiện độ tốt của $f$ trong $\mathcal{D}: \mathcal{P}(\mathcal{D},f)\in\mathbb{R}$
- Trong regression thì có MSE: $\mathcal{P}(\mathcal{D},f)=\frac{1}{N}\sum_{t=1}^N(\hat{y}^t-y^t)^2$
- Sử dụng đạo hàm [gradient descent](https://machinelearningcoban.com/2017/01/12/gradientdescent/) có thể cho ra f0 tốt (bài sau sẽ giải thích kĩ hơn)
$\rightarrow{}$ Từ các dữ liệu đầu vào và chuẩn đánh giá $\mathcal{P}$ biến thành các hàm để tìm tối ưu hàm số
### Evaluation pipeline
- Chia bộ dữ liệu thành 3 phần:
-Training set: để dùng những hàm số khớp vào
-Validation set: để lấy ra mô hình tốt nhất
-Test set: Triển khai thực tế

### Các chuẩn đánh giá khác nhau trong regression
* *Xem lại bài 1*
MSE(Mean Squared Error) = $\frac{1}{N}\sum_{t=1}^Ne_t^2$
RMSE(Root Mean Squared Eror) = $\sqrt{\frac{1}{N}\sum_{t=1}^Ne_t^2}$
MAE (Mean Absolute Error) = $\frac{1}{N}\sum_{t=1}^N\lvert e_t \rvert$
MAPE(Mean Absolute Percentage Error) = $\frac{100\%}{N}\sum_{t=1}^N\Bigl\lvert \frac{e_t}{y_t}\Bigr\rvert$
### Chuẩn đánh giá của classfication
- Accuracy: chỉ dùng tốt cho class-balanced dataset
-Nếu mô hình đó khác với thực tế thì mô hình không tốt
-Cần có cofusion matrix để đánh giá
- Precision & recall: dùng tốt cho những dataset không cân bằng
- Trả ra true positive, false positive, true negative, false negative (positive là những thứ đưuọc lấy ra, còn negative là bị bỏ qua)
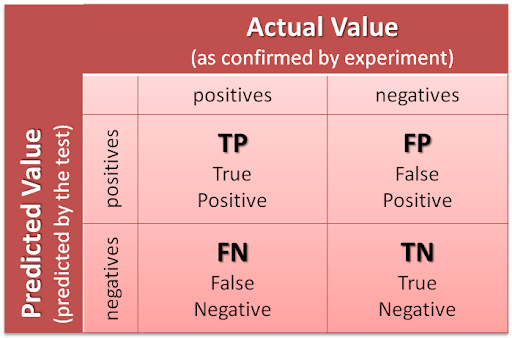
- Precision là tỉ lệ những thứ predicted (Độ hữu dụng) ($\frac{TP}{TP+FP}$)
- Recall là tỉ lệ những thứ recover (Độ nhạy)($\frac{TP}{TP+FN}$)
- Khi đó accuracy = $\frac{TP+TN}{TP+TN+FP+FN}$
- Score $F_1$ = 2$\frac{Precision \cdot Recall}{Precision + Recall}$
### Hinge Loss & Support Vector Machines(SVM)
- Đối với bài toán classfication sẽ có nhiều trường hợp có nhiều cách để tách những loại hơn, trong những cách đó cách tốt nhất chính là chọn đường mà có margin lớn nhất
- Cần Hinge Loss để tìm line có large margin lớn nhất
- Để tiện vào mặt toán học: $y^t\in\{\pm1\}, \hat{y}^t=\text{sign}(w\cdot x^t-b),
ℓ_t = max(0,1-y^t(w\cdot x^t-b))$
- loss = $[\frac{1}{N}\sum_{t=1}^Nmax(0,1-y^t(w^\top \cdot x-b))]+\lambda\left \| w \right \|^2$
- Để cho margin càng lớn thì w càng nhỏ vì chiều rộng của margin là $\frac{2}{\left \| w \right \|}$
- Còn đối với nonlinear SVM ta sẽ sử dụng các công thức sau đây:
| Tên | Công thức | $\color{red}{kernel}$ | Thiết lập hệ số |
|:----------:|:---------------------------------------:|:-----------------------:|:-------------------------------------------------------------------------------:|
| linear | $\mathbf{x}^\top\mathbf{z}$ | $\color{red}{'linear'}$ | không có hệ số |
| polynomial | $(r+\gamma\mathbf{x}^\top\mathbf{z})^d$ | $\color{red}{'poly'}$ | $d: \color{red}{degree},\gamma:\color{red}{gamma}, r: \color{red}{\text{coef}}$ |
| sigmoid | $\tanh(\gamma \mathbf{x}^\top \mathbf{z+r})$ |$\color{red}{'sigmoid'}$|$\gamma:\color{red}{gamma},r:\color{red}{\text{coef}}$|
|rbf|$\exp(-\gamma\left \| \mathbf{x}-\mathbf{z} \right \|_2^2 )$|$\color{red}{'rbf'}$|$\gamma > 0: \color{red}{gamma}$
### Một vài thuật ngữ
Interpolation:
Extrapolation:
Combinatoric:
Thresholds:
### Các công thức trong classificaiton
True Positive Rate = Recall = $\frac{TP}{TP+FN}=\frac{TP}{Positive}$
Precision = $\frac{TP}{TP+FP}$
Prevalance = $\frac{Positive}{Positive+Negative}$
Accuracy = $\frac{True}{Positive+Negative}$
Misclassification = $\frac{False}{Positive+Negative}$
## Section 7: Search: Optimization & training
(Trong giải thuật machinee learning thì work horse là giải thuật quan trọng nhất)
### Mục tiêu cần phải biết sau bài này
- Hiểu được đạo hàm quan trọng như thế nào trong machine learning
- Giải thuật tìm $f_1', f_2',\cdots$ làm sao để mô hình tốt hơn
- Biết được TEFPA rõ hơn và bài hôm nay sẽ tập trung vô phần $\mathcal{A}$ (Algorithm)
### Mô hình TEFPA
- Đây là một framework mà chúng ta cần sử dụng để mô hình huấn luyện tốt và có sự khái quát hóa tốt
$\text{Task }\mathcal{T}\rightarrow\text{Experience }\mathcal{E}\rightarrow\text{Function space }\mathcal{F}\rightarrow\text{Performace }\mathcal{P}\rightarrow\text{Algorithm }\mathcal{A}$
- Trong đó:
$\text{Task }\mathcal{T}$: TÍnh dự đoán $\{ \hat{y}^t \}_{t=1}^N$ với $\hat{y}^t=f(x^t)$ với $f \in \mathcal{F}$
$\text{Experience }\mathcal{E}$: Cho tập hợp N các ví dụ $\mathcal{D}=\{ (x^t,y^t) \}_{t=1}^N$
$\text{Performace }\mathcal{P}$: Đã đưuọc nói trên section 5
$\text{Algorithm }\mathcal{A}$: được sử dụng để tìm vị trí nào sao cho loss tại đó là thấp nhất
### Minimizing Loss
- Để tìm hàm tốt thì cần phải có lost nhỏ nhất (tính luôn cả trong tập test)
- Mô phỏng ý tưởng

- Chúng ta sẽ di chuyển $\theta$ sang $\theta'$
- Để có thể làm được điều đó, chúng ta có thể vẽ ra lost surface (như bài toán regression vì đầu vào là tham số và đầu ra là tham số)

- Vì các data không thay đổi nên chỉ có thể thay đổi được $\theta_1 và \theta_2$ sao cho loss tại đó thấp nhất
Công thức: $\boxed{\theta^* = \arg\min_\theta J(\theta; X,\bf y)}$
- Chúng ta có thể thấy để tìm được điểm thấp nhất ta có thể đi ngược hướng với độ dốc của nó, nói cách khác là chúng ta đi ngược theo hướng đạo hàm của nó
### Velocity & gradient
- Để tìm được vector vận tốc mà tại đó vị trí thay đổi nhanh nhất:
${\bf p}=(p_1,\dots,p_n) \to {\bf v}=(v_1,\dots,v_n)\text{ với } v_i = \lim_{\Delta t\to 0} \frac{\Delta p_i}{\Delta t}$
- Vector Gradient là hướng mà giá trị trong hàm số thay đổi nhanh nhất:
$\nabla_\theta J(\theta;X,{\bf y}) = \Big(\frac{\partial}{\partial\theta_1}J_\theta, \dots, \frac{\partial}{\partial\theta_k}J_\theta, \dots, \frac{\partial}{\partial\theta_n}J_\theta\Big)
\\ with \frac{\partial}{\partial\theta_k}J_\theta = \lim_{\Delta \theta_k\to 0}\frac{J(\theta_1,\dots,\theta_k,\dots,\theta_n) - J(\theta_1,\dots,\theta_k + \Delta \theta_k,\dots,\theta_n)}{\Delta \theta_k}$
- Từ đó chúng ta có giải thuật đi ngược hướng gradient để tìm ra vị trí mà tại đó loss nhỏ nhất
Công thức: $\boxed{\theta \leftarrow \theta -\eta \nabla_\theta J}$ với $0<\eta\ll 1$ được gọi là learning rate
- Tuy nhiên khi đi ngược hướng đạo hàm sẽ có một số vấn đề nảy sinh là bài toán này mình sẽ tìm vị trí của loss sao cho đạo hàm bằng 0 nhưng sẽ có rất nhiều vị trí đạo hàm bằng 0 nên có khả năng chúng ta không thể tìm được vị trí mà mình mong muốn。
back propagation là giải thuật quan trọng để tìm con số thích hợp hơn
### Những vấn để trong gradient descent
Trong giải thuật này là để tìm làm sao gradient = 0 nhưng chắc chắn không có 1 chỗ trong hàm bằng 0 mà có rất nhiều chỗ người ta gọi là local minima.
Thung lũng hẹp: thì bước đi của đạo hàm sẽ l=lớn va nó sẽ nhảy liên tục khó mà tìm điểm có độ gradient =0
Eta (learning rate) phải chọn sao cho hợp lý nếu không xài giải thuật này ít hiểu quả hơn
SGD: chỉ tính cho từng thành phần data chứ không tính hết vì RAM có hạn
Ngày này chúng ta sử dụng Optimizer: adam để giải quyết tốt hơn vấn đề này
### Heuristics
Sử dụng lost trong tập train validation và phân tích
Trong error của tập validation nếu xuất hiện early stopping point thì hàm đó khá tốt
Sử dụng dropout trong neural network để huấn luyện tốt hơn
## Section 9: Recurrent neural networks
### Mục tiêu bài học
- Hiểu được mô hình dự báo theo thời gian, tính chất của các chuỗi dự báo(ví dụ như khi xem phim hành động, chúng ta thường dự báo xem hành động tiếp theo của nhân vật này là gì)
- Hiểu được tính chất của các chuỗi dự báo(ví dụ như khi xem phim hành động, chúng ta thường dự báo xem hành động tiếp theo của nhân vật này là gì)
### Nói sơ sơ về RNN
- Chuyên xử lý về những thứ mà có dạng chuỗi như phim, giọng nói,...
- CNN cũng xử lý chuỗi nhưng CNN gộp lại thành 1 cục còn RNN thì không
- Việc di chuyển trong không gian khái niệm có tầm quan trọng rất lớn
### Di chuyển trong không gian: cộng cho một delta z
(ghi 4 công thức bạn nhé)
-> Đây chính là reccurent, lấy biểu diễn cũ để biểu diễn một biễu diễn mới, được lặp đi lặp lại nhiều lần
### Vanilla RNN
(in hình trang 15 bạn nhé)
Từ input sang biểu diễn h, luôn cùng 1 ham số giống nhau với mọi thơi gian t
Sử dụng backpropagation rất quan trọng, sẽ làm mô hình trở nên tốt hơn bằng cách đi ngược lại để sửa lỗi sai
- Có thể từ 1 input ra được các chuỗi out put, hoặc từ nhiều input chỉ đưa ra 1 output
### Vanishing (or Exploding) Gradient
- Vì là một chuỗi nên có vấn đề là các gradient sẽ được nhân lại với nhau nên cái memmrory sẽ rất nặng
- LSTM, BPTT,...
- Để giải quyết được điều đó se nâng cao LSTM và GRU(sẽ được học ở các bài sau)
## Section 10: K-means Clustering: Unsupervised Learning
* Ta cần chiết xuất đặc trưng để có thẻ đưa ra dự đoán, hiểu được những đầu vào
### Những điều cần phải biết
- Hiểu được unsupervised là gì? Hiểu được clustering là gì?
- Cách để tìm được số nhóm k sao cho hiệu quả
### Unsupervised
- Chúng ta đưa input x mà không cần y, máy vẫn có thể tự gom nhóm được
- Một số ví dụ: Tự gom những nhóm những khách hàng như nhóm người lơn tuổi hay nhóm những người trẻ tuổi thì mội nhóm sẽ có chế độ chăm sóc khách hàng khác nhau
### Clustering
- Chúng ta cần phải biểu diễn của từng một nhóm và sau đó cần phải cho máy biết được input x thuộc cụm nào
- Các weight được cho là một đại diện của một nhóm
- Ví dụ: Mỗi cụm chúng ta sẽ kiếm điểm trung bình và input nào mà gần với cái điểm trung bình nhất thì input x sẽ thuộc về nhóm đó
### K-means clustering
- K-means clustering = Phân thành K cụm
- Mỗi cụm được đại diện bởi 1 trung tâm (centroid)
- Mỗi centroid là trung bình của các “thành viên”
- Mỗi input là “thành viên” của cụm có centroid gần nhất
- Một K-means clustering tốt thì phải có intercluster và intracluster phù hợp
### Công thức intracluster: (ghi vào)
* Dùng để tối ưu xem tổng khoảng cách của từng điểm đến centroid là ngắn nhất
* Giải thuật này luôn luôn ngừng lại khi tổng khoảng cách đến centroid là ngắn nhất
### Các phương pháp
- Elbow method: Chúng ta vè ra tính tổng khoảng cách của từng k và điểm k tốt nhất là điểm mà tạo được khuỷu
- Silhouette method: Chúng ta tính tổng khoảng cách từ centroid đến các điểm của các cluster khác sao cho lớn nhất cho từng k thì tổng khoảng cách lớn nhất có số k tốt nhất
## Section 11: MDP Planning
### Mục tiêu bài giảng
- Hiểu được thế nào là planning
- Planning được áp dụng như thế nào trong cuộc sống
- Hiểu được mô hình toán giải bài planning(MDP) và giải như thế nào
* Tọa độ nhứng Z được sinh ra không phải từ environment mà từ chính con AI *
* Z chỉ là một phần của observation O, vì phải qua chiết xuất đặc trưng nhưng cũng có thể bằng O khi mình lấy màu sắc, âm thanh,... *
### Planning
- Rất quan trọng, hầu hết mọi loài vật đều phải planning để sinh tồn
- Ví dụ:
Giải câu đố
Chơi cờ vua, đưa ra nước đi tốt nhất
Hanoi Tower
Robot quét nhà
- Là hình thức thông mình cao nhất trong các chuỗi xử lí
- Plan là chuỗi các hành động dể đạt được mong muốn một cách nhanh nhất, tốt nhất và hiệu quả nhất (hay còn gọi là sequential decision making)
- Trong planning cần phải biết được mục đích, xác định môi trường ở trạng thái gì, từu đó đưa ra hành động (Cũng gọi là policy)
- Việc chuyển trạng thái hay còn gọi là transition model
### MDP
- Từ trạng thái S_t qua một hành động A_t sao cho tổng R_t là lớn nhất (Markoc decision process $\mathcal{M} = (S,A,T,R,\gamma))$ trong đó $\gamma$ là discount vector cho chúng ta biết được cái R_t nào tốt hơn
- Sử dụng chính sách $\pi$ : một plan là $=\Big\{\text{policy } \pi(s), \text{ value } q^\pi(s,a)\Big\}$
+$a_t\leftarrow\text{policy }\pi(s_t)$
+action value $q^\pi(s,a)$
- Tổng reward trong tương lai: $q^\pi(s,a) = \frac1{K} \sum_{k=1}^K \Big(r_1 + \gamma G^\pi_k(s') \Big)$
- Bellman quations: $q^*(s,a) = R(s,a) + \gamma \sum_{s'} P(s'|s,a)\max_{a'} q^*(s',a')$
P/s: Những công thức trên được sử dụng để tính được $\pi$ mà thông qua Q.
## ML4AI Session 12 Final Exam (for Students)
<br>

<br>
CoTAI AI Training Program for Highschool Students
© [CoTAI](https://gem.cot.ai) 2021
---
Open book. Choose to answer as many questions as possible, as concisely as possible. Ask instructors if you have difficulty in understanding the questions.
**Questions**
1. [**8** Points] The unified TEFPA framework to build a ML model: task $\mathcal{T}$, experience $\mathcal{E}$, function space $\mathcal{F}$, performance $\mathcal{P}$, and algorithm $\mathcal{A}$ to search. What are the elements in TEFPA framework...
- 1.1 [**2** Point, 3.1] to build a face recognition model using a DCNN? **Solution:** $\mathcal{T}$ là tìm được tên của người đó dựa vào hình cái mặt. $\mathcal{E}$ là tập hợp các hình ảnh có mặt của người và tên của người đó. $\mathcal{F}$ là đưa input vào mô hình DCNN để huấn luyện mô hình. $\mathcal{P}$ là đánh giá xem dự đoán có đúng hay không. $\mathcal{A}$ là sử dụng gradient descent để dự đoán tốt hơn
- 1.2 [**2** Point, 3.1] to build a RecSys? (using one of the models you have learned: item-based, user-based, content-based, MF)**Solution:** $\mathcal{T}$ là những item của 1 chủ đề nào đó rồi máy sẽ tự động recommend cho mình mấy thứ khác. $\mathcal{E}$ là một bảng số liệu có đánh giá của những người vè một cái gì đó. $\mathcal{F}$ là cosine similarity $\mathcal{P}$ là cho biết được cái item mà máy recommend có hợp lý hay không. $\mathcal{A}$ là sử dụng thuật toán để cố thể cho mô hình dự đoán tốt hơn
- 1.3 [**2** Point, 3.1] to build a customer segmentation model using k-means?**Solution:** $\mathcal{T}$ là cho một dữ liệu về người đó rồi gom nhóm xem người đó thuộc nhóm nào. $\mathcal{E}$ là các bảng số liệu chứa thông tin về một người nào đó. $\mathcal{F}$ là đưa các inputs vào k-means $\mathcal{P}$ là dự đoán xem người khách hàng đó thuộc nhóm đó có hợp lý không.$\mathcal{A}$ để giúp cho mô hình dự đoán tốt hơn
- 1.4 [**2** Point, 3.1] to build a sentiment analysis model (good, bad, neutral comments) using RNN+Softmax Classifier?**Solution:** $\mathcal{T}$ là đưa hình người vào rồi mô hình sẽ dự đoán cảm xúc của khuôn mặt trong hình đó là gì. $\mathcal{E}$ là đưa ra các khuông mặt và cảm xúc trên khuôn mặt đó. $\mathcal{F}$ là đưa các input vào RNN+Softmax Classifier. $\mathcal{P}$ là dự đoán xem có đúng cảm xúc không. $\mathcal{A}$ là sử dụng hàm hỗ trợ để dự đoán tốt hơn.
2. [**6** Points] Convolutional filters (or kernels)
- 2.1 [**1** Point, 1.1, 3.2] How do we extend them from dot product? **Solution:**
- 2.2 [**1** Point, 1.1, 3.2, 3.4] Why do we call their outputs "feature maps"? **Solution:** Vì mỗi con số trên feature map sẽ biểu hiện 1 đặc trưng nào đó.
- 2.3 [**1** Point, 3.2] Explain padding: how to do & main purpose **Solution:** Để khi lấy kernel channel trượt thì có trượt luôn phần bên ngoài rìa hay không bằng cách sẽ tự thêm số 0 ở bên ngoài rìa. Padding dùng để quét chi tiết hơn. Ngoài ra còn dùng để giữ nguyên hoặc tăng kích thước đầu vào.
- 2.4 [**1** Point, 3.2] Explain pooling: how to do & main purpose **Solution:** Trong pooling mình sẽ dùng một kernel channel để trượt qua rồi tính toán lấy đi thông số, và 1 thông số đó có thể biểu thị được một ma trận vuông với các kích thước khác nhau. Pooling được sử dụng để giảm kích thước dữ liệu nhưng vẫn giữ được phần quan trọng, để tính toán nhanh hơn.
- 2.5 [**1** Point, 3.2] Explain stride: how to do & main purpose **Solution:** Khi trượt thì kernel channel sẽ nhày theo số stride. Sử dụng tùy vào trường hợp của đề bài
- 2.6 [**1** Point, 3.2, 3.4] Explain their **effective** receptive field: why do they produce highly absstract features? **Solution:**
3. [**6** Points] Recurrent neural networks (RNNs) can be used for sequential modeling.
- 3.1 [**1** Point, 3.2] What does sequential data mean? **Solution:** Là trích xuất data
- 3.2 [**1** Point, 1.1, 3.2, 3.4] Explain each element in this basic equation of RNNs $h_t = \mathsf{\gamma}(Ah_{t-1}+Wz_t)$ **Solution:**
- 3.3 [**2** Point, 1.3, 2.1, 3.2] WWhat does back-propagation-through-time mean, why do we need it instead of using plain back-prop, and how does it work for training RNNs? **Solution:**
- 3.4 [**1** Point, 1.3, 3.2] Explain vanishing gradient problem for simple RNNs. **Solution:**
- 3.5 [**1** Point, 3.1, 3.3] If we want to classify the sentiment of each user comment (good, bad, neutral) at the end of each sequence using RNN+Softmax classifier: explain briefly the model architecture. **Solution:**
4. [**6** Points] Planning in Markov Decision Process (MDP) $(S,A,T,R,\gamma)$.
- 4.1 [**1** Point, 3.1, 3.2] Explain 5 elements in MDP model (equation of each element if available). **Solution:** S là một tập hợp các state. A là tập hợp các hành động. P là xác suất để action tại state đó trong thời gian t có thể hướng tới state mowistrong thời gian t+1. R là một phần thưởng được nhận khi chuyển từ state này sang state khác qua action A. $\gamma$ là discount vector cho chúng ta biết được cái R nào tốt hơn
- 4.2 [**1** Point, 3.2] Following a policy $\pi(s)$ to generate a trajectory of 10 time steps $(s_t,a_t,s_{t+1},r_{t+1})$. Compute the return. Equation of $a_t$? **Solution:**
- 4.3 [**1** Point, 1.2, 3.2] Repeat for 10 days: from $s_0 = \text{HOME}$ take action $a_0 = \text{GET_BUS}$ with cost $r_1 = 6000 \text{VNĐ}$ then following policy $\pi(s)$ to generate $K=10$ trajectories, each with total cost $G_k$. Compute the average cost of taking bus then following $\pi$: $Q^\pi(\text{HOME, GET_BUS})$.
- 4.4 [**1** Point, 1.1, 1.3, 2.1, 3.2] How do we compute an optimal plan (i.e., optimal policy $\pi^*$) of a known MDP $(S,A,T,R,\gamma)$? **Solution:** tính policy và value $\Big\{\text{policy } \pi(s), \text{ value } q^\pi(s,a)\Big\}$
- 4.5 [**1** Point, 3.2] Why do we say that the action value function $Q^\pi(s,a)$ gives predictions into very far future? **Solution:** Vì theo công thức $q^\pi(s,a) = \frac1{K} \sum_{k=1}^K \Big(r_1 + \gamma G^\pi_k(s') \Big)$ mình có thể tính được rất xa nhờ vào K
- 4.6 [**1** Point, 1.2, 3.2] What is the meaning of action value function when we set $\gamma = 1$? $\gamma = 0$? **Solution:** Khi để $\gamma = 0$ tức là Q sẽ bằng reward và lúc này chỉ cần vào state và action đầu tiên mà không cần phải làm action tiếp theo hay nói cách khác là chỉ làm đúng 1 action duy nhất. Còn $\gamma = 1$ thì ngược lại là làm được nhiều action khác nhau tùy vào trạng thái.
5. [**7** Points] Unified ML models
$\text{Input } X \xrightarrow[B_{\beta}]{\text{Features}}\text{ Embedding Coordinates }Z \xrightarrow[P_{\theta}]{\text{Predictor}}\text{ Predictions }\hat{Y} \xrightarrow[{\pi^*}]{\text{Policy}}\text{ Action }A$
- 5.1 [**2** Points] List all *taught* algorithms for feature extraction and their main ideas. **Solution:** PCA, CNN
- 5.2 [**2** Points] List all *taught* algorithms for making predictions and their main ideas. **Solution:** Linear Regression, Logistic Regression, KMean, KNN, SVM,
- 5.3 [**2** Points] What are the main *general* differences between linear predictors? And in your opinion why do we need different algorithms? **Solution:** Các khác biệt chính là các parameter khác nhau. Chúng ta cần các algorithm khác nhau vì mỗi mô hình đó cách hoạt động khác nhau tùy vào mỗi bài, có một số bài linear nhưng mà phân loại thành nhiều nhãn thì mình không xài được SVC, nhưng 2 nhãn thì xài rất tốt, nếu bài toán cần đưa ra con số thì mình xài linear regression, ...
- 5.4 [**1** Points] For MDPs, what are the predictions $\hat{Y}$ used to make decisions $A$? **Solution:** Được sử dụng như là một trạng thái S
6. [**2** Points] RecSys

We build item embeddings ${\bf z}_i \in \mathbb{R}^2$ as in table, and use **softmax regression** to predict ratings 1 to 5. Choose a specific user $X\in \{A,\dots,F\}$, what is the training set for learning $\theta_X$? What are the parameters $\theta_X$ to be learned (with their shapes)?
7. [**6** Points] MDP Planning for playing Chess. Let rewards = 1 for winning, -1 for losing, and 0 for a draw or unfinished game, and no discount.
- 7.1 [**2** Points] What is the range of value of the optimal action-value function $Q^*(s,a)$, and how to derive probability of win/loss from it?
- 7.2 [**2** Points] If we use all the games already played in history to compute $Q^*(s,a)$, explain the method?
- 7.3 [**2** Points] Because there are so many state and action pairs $(s,a)$, we need to use *learning* to approximate and generalize for all $(s,a)$ pairs. If we use MLP to learn $Q^*(s,a)$, what is the dataset and possible network structure?
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet