# Volvo Kubernetes WAR *checklist*
## Well Architected Review for Kubernetes
### June 9, 2020
###### tags: `Kubernetes` `EKS` `WAR`
---
Increase awareness of architectural best practices.
Addresses foundational areas that are often neglected. Consistent approach to evaluating architectures. Influence future architectures
* Application checklist for Kubernetes
* Cluster ready checklist for Kubernetes
* Operational consideration for Kubernetes
Standard WAR pillars:
* Security
* Reliability
* Performance
* Cost Optimizationm
* Operational Excellence
---
## Application Checklist for Kubernetes
- [x] Pod readiness checks
- [x] Liveness checks
- [x] metric instrumentations (i.e. Prometheus, New Relic, Datadog, etc...)
- [ ] Dashboards
- [ ] standard K8 dashboard
- [ ] Grafana
- [ ] [kontena](https://www.kontena.io/). Kontena is now retired.
- [ ] [Kui](https://github.com/IBM/kui)
- [ ] [Lens](https://github.com/lensapp/lens)
- [ ] [Kubebox](https://github.com/astefanutti/kubebox)
- [ ] [Octant](https://github.com/vmware-tanzu/octant)
- [ ] [kubelieve](https://github.com/ameerthehacker/kubelive)
- [ ] [kubevious](https://github.com/kubevious/kubevious)
- [ ] [k9s](https://github.com/derailed/k9s)
- [ ] [sloop](https://github.com/salesforce/sloop). Kubernetes history visualization
- [ ] [WeaveScope](https://www.weave.works/oss/scope/)
- [ ] or [alternatives](https://kube-web-view.readthedocs.io/en/latest/alternatives.html)
- [ ] Playbooks and Runbooks
- [x] Limits and Requests (memory and CPU, or # of pods / namespace)
- [x] Labels and annotations
* Pod placement
- [ ] How many pods per application?
- [ ] Taints and Tolerations
- [x] Pod affinity / anti-afinity
- [ ] Node selectors
- [ ] Alerting
- [ ] Structured logging output (ELK stack or commercial options)
- [ ] Tracing (X-Ray, Zipkin, Lightstep, Appdash, Jaeger)
- [ ] Graceful shutdowns (i.e. how does app respond to SIGTERM)
- [ ] Graceful dependencies (Apps should not assume dependencies are available)
- [ ] Environmental variables
- [ ] Configmaps (Apps should use them for dependency injection)
- [ ] Labeled images using commit SHA (do not use "latest" image)
- [ ] Locked down runtime context (i.e. no root user)
- [x] Consider using Pod Security Policy (PSP)
- [ ] Consider using AppArmor or SELinux security context
- [ ] Open Policy Agent. [OPA](https://aws.amazon.com/blogs/opensource/using-open-policy-agent-on-amazon-eks/)
- [ ] [Security tool for policy enforcement](https://github.com/cruise-automation/k-rail)
## Cluster Ready Checklist for Kubernetes
- [ ] Build Pipeline - CI portion (Jenkins, Travis, CircleCI, CodeBuild)
- [ ] Deployment Pipeline - CD portion (GitOps using Weave Cloud and Flux or Argo)
- [ ] Image Registry (DockerHub, JFrog or ECR)
- [ ] Private Repos require credential storage
- [ ] Monitoring infrastructure by collecting and storing metrics (Prometheus or CloudWatch)
- [ ] Databases or Stateful Apps
* Storage
- [ ] CSI drivers for block storage
- [ ] CSI drivers for shared file storage (EFS)
- [ ] OpenEBS
- [ ] Portworx
- [ ] Rook / Ceph
* Secrets Management (Bitnami Sealed Secrets, Hashicorp Vault, etc...)
- [ ] EKS [secrets using envelope encryption](https://aws.amazon.com/about-aws/whats-new/2020/03/amazon-eks-adds-envelope-encryption-for-secrets-with-aws-kms/)
- [ ] Bitnami [Sealed Secrets](https://github.com/bitnami-labs/sealed-secrets). Seems best.
- [ ] GoDaddy [External Secrets](https://www.godaddy.com/engineering/2019/04/16/kubernetes-external-secrets/)
- [ ] [SOPS](https://medium.com/better-programming/secrets-management-stinks-use-some-sops-43a92b7b8d54)
- [ ] [Helm Secrets](https://github.com/futuresimple/helm-secrets)
- [ ] [kubesec](https://blog.stack-labs.com/code/keep-your-kubernetes-secrets-in-git-with-kubesec/)
- [ ] Jeremy's [prototype](https://github.com/jicowan/secret-sidecar)
- [ ] HashiCorp Vault
- [ ] aws [secret operator](https://github.com/mumoshu/aws-secret-operator)
- [ ] [aws poc](https://github.com/mhausenblas/nase)
- [ ] [poc](https://github.com/Mahendrasiddappa/eks-secret-injector)
* Ingress Controller
- [ ] ALB
- [ ] nginx
- [ ] Kong
- [ ] Solo gloo
- [ ] Traefik
- [ ] HAProxy
- [ ] Ambassador
- [ ] [Skipper](https://opensource.zalando.com/skipper/tutorials/basics/)
* Service Mesh
- [ ] AppMesh
- [ ] Istio
- [ ] Linkerd
- [ ] Service Catalog functionality
- [ ] [service catalog](https://aws.amazon.com/blogs/opensource/kubernetes-service-catalog-aws-service-broker-on-eks/)
- [ ] AWS Service [Operator](https://github.com/aws/aws-service-operator-k8s)
- [ ] User and Pod Authorization
- [ ] IAM users or roles
- [ ] SAML Federation
- [ ] OIDC [Federation](https://aws.amazon.com/blogs/opensource/consistent-oidc-authentication-across-multiple-eks-clusters-using-kube-oidc-proxy/)
- [ ] IRSA for Pods, KIAM or Kube2IAM
- [ ] Network Policies (Tigera Calico)
- [ ] Static or Dynamic Image/Runtime Scanning
- [ ] ECR (static only)
- [ ] Twistlock
- [ ] Aqua Security
- [ ] Stack Rox
- [ ] Sysdig
- [ ] [Falco](https://falco.org/)
- [ ] Log Aggregation
- [ ] CloudWatch / Container Insights (i.e. FluentD forwarder)
- [ ] Splunk
- [ ] [FluentBit](https://aws.amazon.com/blogs/opensource/centralized-container-logging-fluent-bit/) (targeted for ECS)
- [ ] Others
## Operational Considerations for Kubernetes
* Horizontal Pod Autoscaling
- [ ] Metrics Server
- [ ] Use AWS CloudWatch or external metrics
* Vertical Pod Autoscaling
- Only recommended for Fargate at this time.
* Cluster autoscaling or AWS native ASG
- [ ] cluster autoscaler is not AZ aware
- [ ] cluster autoscaler will dynamically move pods around and terminate instances
- [ ] Gracefully scale-in. See [node-drainer](https://github.com/aws-samples/amazon-k8s-node-drainer)
- [ ] cluster autoscaler is reactive
- [ ] cluster autoscaler assumes nodegroups are homogenous
* How do you bootstrap a new cluster
- [ ] [helm files](https://github.com/roboll/helmfile)
- [ ] GitOps
- [ ] scripts
- [x] Utilizing Namespaces for team/developer isolation. RBAC.
* How to create clusters using IaC
- [ ] eksctl
- [ ] CloudFormation / CDK
- CDK for [Kubernetes](https://aws.amazon.com/blogs/containers/introducing-cdk-for-kubernetes/) and [GitHub](https://cdk8s.io). See [library](https://github.com/toricls/cdk8s-debore)
- [x] Terraform
- [ ] [Pulumi](https://www.pulumi.com/)
- [ ] [Fugue](https://www.fugue.co)
- [ ] Scripts / Other
* How do you upgrade your node groups?
- [ ] eksctl
- [ ] AWS managed node groups (eksctl or aws cli can be used)
- [ ] [open source tooling](https://github.com/keikoproj/upgrade-manager)
- [ ] [hello fresh - open source](https://engineering.hellofresh.com/open-sourcing-eks-rolling-update-a-tool-for-updating-amazon-eks-clusters-5cef5b497a95)
- [ ] [EC2 node instance shutdown](https://github.com/aws/aws-node-termination-handler). Can be used for Spot or regular maintenance.
- [ ] manually
* Do you have SSH access into your worker nodes
- [ ] SSH keys
- [ ] SSM [agent](https://github.com/mumoshu/kube-ssm-agent)
- [ ] It is possible to use `kubectl node-shell`. See [Github](https://github.com/kvaps/kubectl-node-shell)
- [ ] SSM [daemon-set](https://github.com/mumoshu/kube-ssm-agent)
* AMI choice
- [ ] AWS Linux 2 / EKS Optimized Linux
- [ ] [Ubuntu](https://aws.amazon.com/blogs/opensource/optimized-support-amazon-eks-ubuntu-1804/)
- [ ] Custom AMI
* VPC design
- [ ] AWS CNI requires large number of IP addresses
- [ ] Overlay CIDR block possible
- [ ] 6x /20 subnets recommended (3 public and 3 private) over 3x Availability Zones
- [ ] Public or Private DNS settings
- [ ] Private endpoints require additional work
- [ ] Hybrid design
* Worker Nodes
- [ ] Instance sizing impacts number of pods/IPs
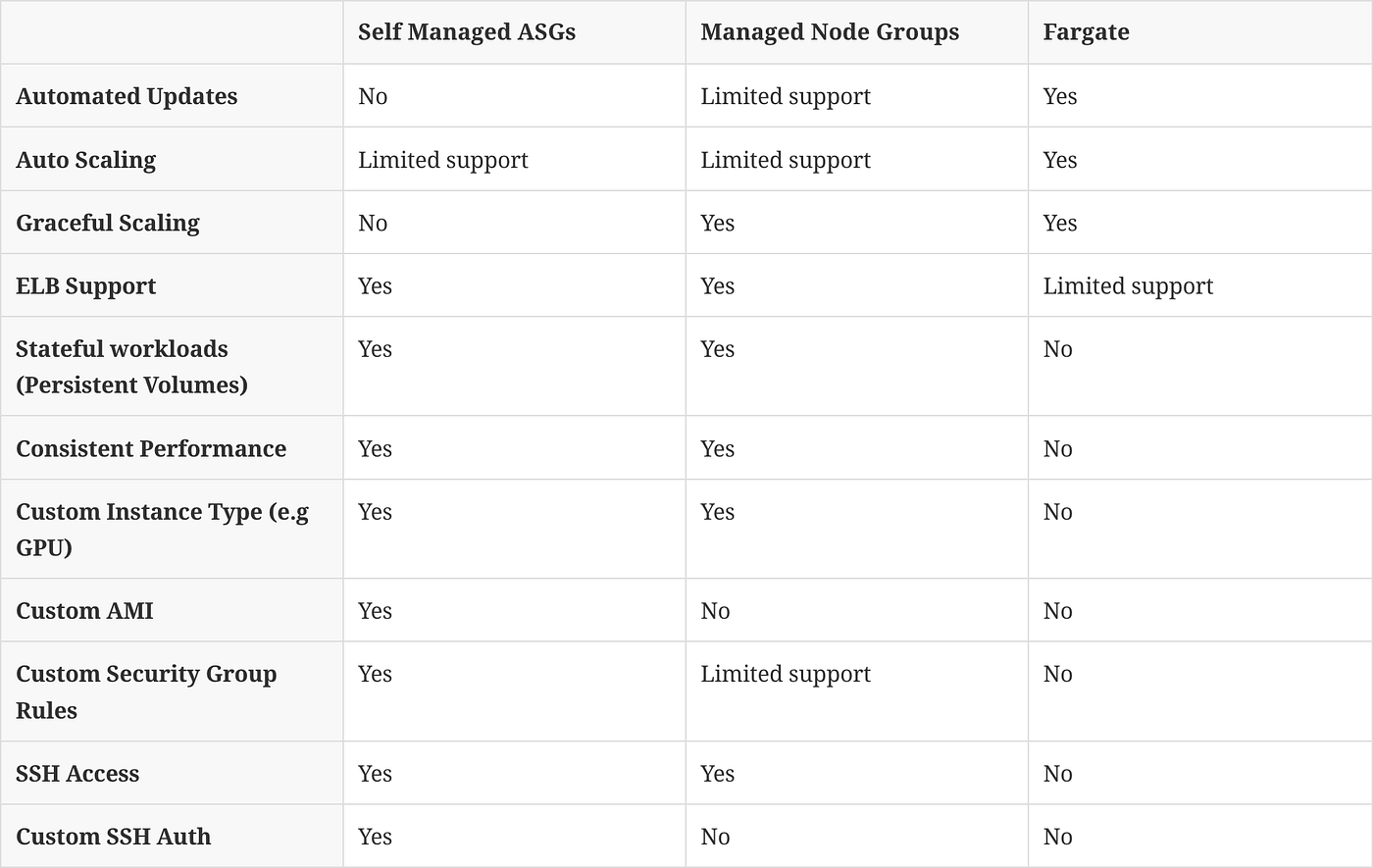
- [ ] Fargate for EKS
- Fargate does not support daemon sets (which makes logging a challenge). See [documentation](https://docs.aws.amazon.com/eks/latest/userguide/fargate.html)
* DNS (CoreDNS)
- [x] EKS only uses 2 DNS pods by default. See [blog](https://aws.amazon.com/blogs/containers/eks-dns-at-scale-and-spikeiness/)
- [ ] Daemon set may be better
- [ ] Daemon set with local access only
- [ ] [External DNS](https://github.com/kubernetes-sigs/external-dns)
* Control Plane logging - CloudTrail (off by default)
* Disaster Recovery
- [ ] [Federation v2](http://www.nickaws.net/aws/kubernetes/2019/09/02/Federation-and-EKS.html)
- [ ] [Velero](https://github.com/vmware-tanzu/velero)
- [ ] [GitOps](https://www.weave.works/technologies/gitops/)
---
## Security
Includes the ability to protect information, systems, and assets while delivering business value through risk assessments and mitigation strategies
### [Security Best Practices for EKS](https://aws.github.io/aws-eks-best-practices/)
1. Apply security at all layers
2. Enable traceability
3. Implement a principle of least privilege
4. Focus on securing your system
5. AWS Shared Responsibility Model
6. Automate security best practices
* Detective Controls
* Infrastructure Protection
* Data Protection
* Incident Response
* IAM
* Root account
- [ ] MFA
- [ ] Not used
- [ ] Key rotation
- [ ] IAM role
- [ ] Federation
- [ ] Encryption
- [ ] At rest
- [ ] In transit
* Key storage
- [ ] KMS
- [ ] CloudHSM
- [ ] Other
* Network / VPC
- [ ] Security Groups
- [ ] NACLS
* [ ] Pen tests
* [ ] Host based firewalls
* [ ] WAF
* Monitoring and Logging
- [ ] Cloudtrail
- [ ] CloudWatch logs
- [ ] VPC flow logs
- [ ] Third Party Systems (Splunk, AppMonitoring)
## Reliability
The ability of a system to recover from infrastructure or service failures,
dynamically acquire computing resources to meet demand, and mitigate disruptions such as misconfigurations or transient network issues
1. Test recovery procedures
2. Automatically recover from failure
3. Scale horizontally to increase aggregate system availability
4. Stop guessing capacity
5. Manage change using automation
* [ ] Limits monitoring
* [ ] HA/Failover
* [ ] Autoscaling
* [ ] Monitoring
* [ ] Change management
* [ ] GitOps or Infrastructure as Code
* [ ] Chaos Testing
* [ ] Backup and recovery
* [ ] Planning for DR
* [ ] Did you have Enterprise support?
## Performance
The ability to use computing resources efficiently to meet system requirements,
and to maintain that efficiency as demand changes and technologies evolve
1. Democratize advanced technologies
2. Go global in minutes
3. Use serverless architectures
4. Experiment more often
5. Mechanical sympathy
* [ ] Instance selection
* [ ] Instance monitoring
* [ ] Autoscaling
* [ ] Database selection
* [ ] Load testing
## Cost Optimization
The ability to avoid or eliminate unneeded cost or suboptimal resources while meeting your functional requirements
1. Cost-effective resources
2. Matching supply with demand
3. Expenditure awareness
4. Optimizing over time
* [ ] Governance
* [ ] Spend monitoring
* [ ] Usage to spend monitoring
* [ ] Storage usage
* [ ] CDN
* [ ] RI's or "Savings Plan"
* [x] Spot
* [ ] Use higher level services
* [ ] SQS
* [ ] DDB
* [ ] SNS
* [ ] etc
* [ ] Cleanup/decommissioning
## Operational Excellence
The ability to run and monitor systems to deliver business value and to continually improve supporting processes and procedures
1. Preparation
2. Operation
3. Response
* What best practices for cloud operations are you using?
* How are you doing configuration management for your workload?
* How are you evolving your workload while minimizing the impact of change?
* How do you monitor your workload to ensure it is operating as expected?
* How do you respond to unplanned operational events?
* How is escalation managed when responding to unplanned operational events?
****
## Useful AWS Helm charts:
1. https://hub.helm.sh/charts/incubator/aws-alb-ingress-controller
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet