# Boomboxheads v2
###### tags: `virtual production`
https://gm3.github.io/bbdapp/ Project Home Page
https://twitter.com/boomboxheads/status/1638370184040976385

First post? https://twitter.com/boomboxheads/status/1591555554836885506
Early boomboxhead https://twitter.com/boomboxheads/status/1592201020641538049
3D mint page https://twitter.com/boomboxheads/status/1613043942483980288




---
## Sprites


```bash=
#!/bin/bash
for file in *.glb; do
for i in {0..5}; do
yaw=$(expr $i \* 45 % 315) # Calculate yaw angle, wrapping around to 0 after 7 increments of 45 degrees
filename=$(basename "$file" .glb)"-$i.png" # Construct filename
screenshot-glb -i "$file" -w 512 -h 512 -m "orientation=0 0 $yaw" -o "$filename" # Take screenshot
done
# Combine screenshots into a grid with transparent background
montage $(basename "$file" .glb)-*.png -tile 6x1 -geometry +0+0 -background none -resize 3072x512 montage-$(basename "$file" .glb).png
# Combine all images into a final GIF
convert -dispose background -delay 50 -loop 0 $(basename "$file" .glb)*.png $(basename "$file" .glb).gif
#rm "$(basename "$file" .glb)"-*.png
done
```
---
## LOD
> what platforms support MSFT_lod ?
i think not many cuz its not artist friendly to produce
but it can be implemented on backend for the platform
285 KB glb is 9x smaller than the original 2.6 MB
but all LODs together add +15% on the original glb
Generating LODs using this script: https://github.com/madjin/glTF-Transform-lod-script
From 20k -> 6.8k -> 6.6k tris
2.6 MB -> -> 485 KB -> 285 KB
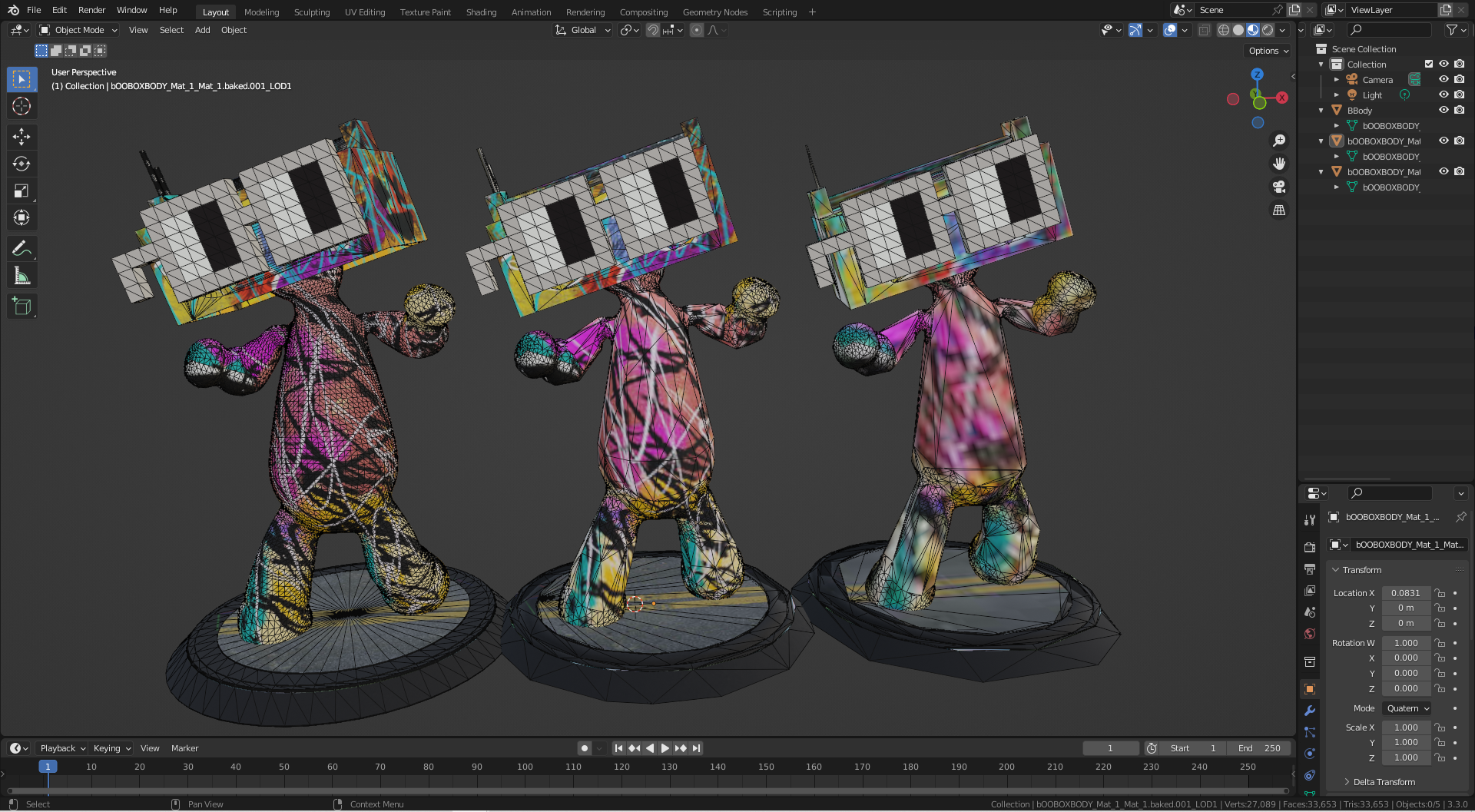
Platforms will need to add support for MSFT_lod to use, and it bloats the file size of the glb (2.6 MB -> 3.1 MB aka +15%)

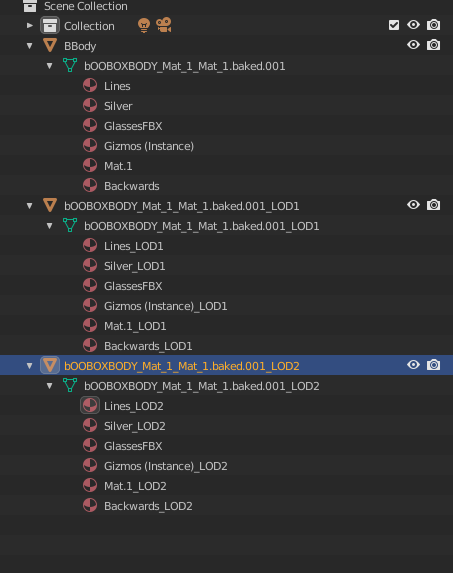
## NFT metadata instead?
This is how the blender hierarchy looks in my output of gltf transform lod script, what if we separated these LODs and included them in the exported metadata for the file instead of bundling them into the glb?
Or could this be a use case for glxf? https://github.com/KhronosGroup/glXF

420 original glbs = 1.47 GB
420 optimized glbs = 863 MB
420 draco + MSFT_LOD glbs = 883 MB
Estimate for 420 LOD_1 = ~98 MB
## ETM
https://etm-standard.github.io/ETM_MULTIASSET_v1.0.0#motivation
> For NFTs which adhere to our proposed metadata standard, the path to ingesting assets into a game world looks like:
>
> Proposed Ingestion Path Example
>
> 1. User purchases an NFT
> 2, Game verifies that the user owns the NFT
> 3. Game parses NFT's metadata to ingest appropriate assets into the game world
>
> The clear benefit of this approach is that with no custom project-level support from the game developer and no manual action from the NFT owner, the user is able to use their assets in-game.
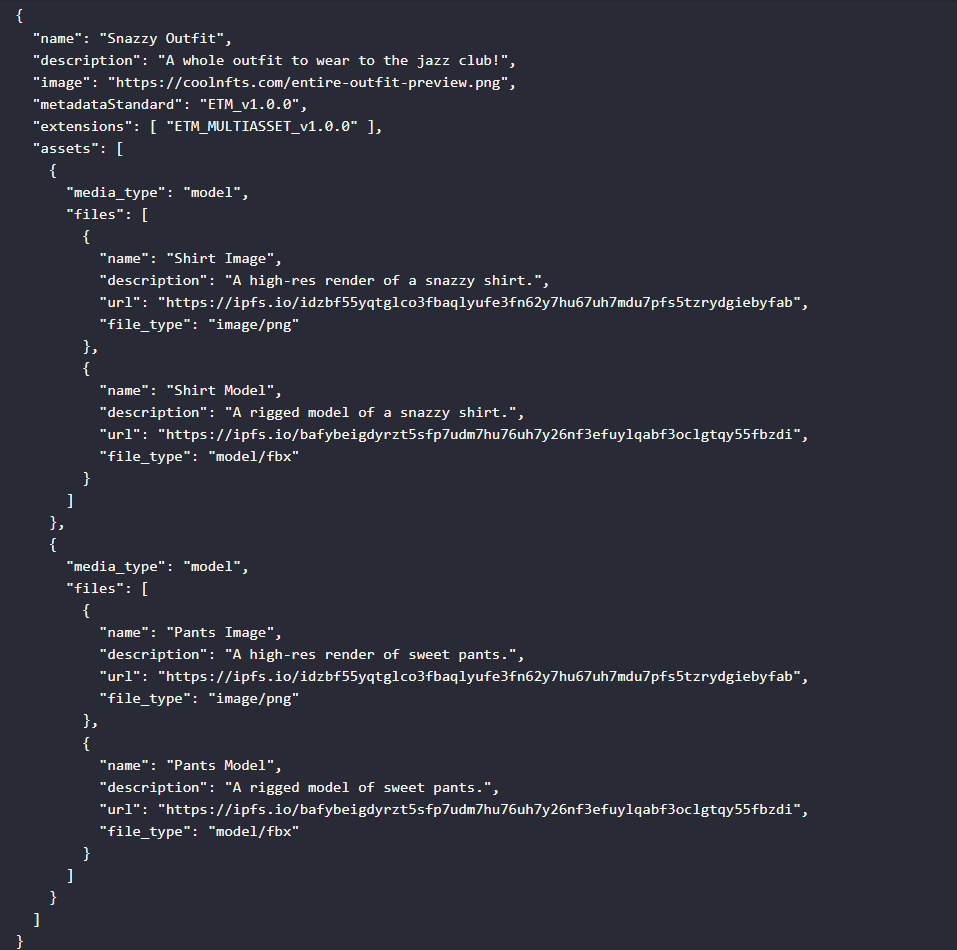
https://etm-standard.github.io/ETM_MULTIASSET_v1.0.0#motivation
https://github.com/ETM-Standard/etm-python-module
Python module -> Blender script?
### Avatar LOD

https://docs.cryptoavatars.io/cryptoavatars/api/avatars/multiverse-token-metadata-mtm-manifest
---
## Image Previews
Idea: WebP preview image in the metadata?
The 4K images by default are quite big (383 MB), so what many platforms seem to do is use the images from opensea API which provides optimized versions through their CDN in the API stream event payloads: https://docs.opensea.io/reference/stream-api-event-example-payloads
```
"metadata":{
"animation_url":null,
"image_url":"https://i.seadn.io/gae/7k408lJucpd0xYOlfvucW50zsXfa53YvdhsRZ_Y_mkmR1mUcNxPKoUphLbgHjLE7-qd5fvnYKBkyGxPsIyV2zQhLy2jjH4KVr8gqeg?w=500&auto=format",
"metadata_url":"https://api.sneakerheads.xyz/sneaker/3884",
"name":"SNEAKERHEADS #3884"
```
This is great for performance, but also seems not great for decentralization because then aren't we relying on Opensea API? If something happens, like access gets revoked, will everything look broken?
**Idea**: add preview image uri into the metadata
512x512 resolution webp of all 420 images is ~33.7 MB, 10x smaller
but then what would the field be called? image is usually reserved for the high res piece
Downsides: Adds extra steps, most people do not mint this way
- superrare metadata is just the original image:
- https://superrare.com/artwork-v2/after-hour-40976
- https://opensea.io/assets/ethereum/0xb932a70a57673d89f4acffbe830e8ed7f75fb9e0/40976
- https://ipfs.pixura.io/ipfs/QmVAwUHzf1MxMNT4sh2jVGWfmocNL1tXh6GHT73qVYicxq/metadata.json
Just brainstorming here
### Self hosted Node Optimization
When people backup their NFTs, perhaps that is where they can also generate the LODs for images. Many popular self-hosted image gallery software such as [PhotoPrism](https://www.photoprism.app/) and [thumbsup](https://thumbsup.github.io/) and file explorers have programs to automatically generate thumbnails of media inside of it. So too should the world computer!
This reduces the upfront responsibility for artists when minting onto the collectors and platforms that are more incentivized to run nodes powering this decentralized content network.
https://github.com/awesome-selfhosted/awesome-selfhosted#photo-and-video-galleries
https://www.clubnft.com/
---
## Metadata scripts steps
1. Split combined metadata
`jq -c '.[]' combined_metadata_fixed_final.json | split -l 1 -a 3 -d --additional-suffix='.json' - output`
Then thunar to rename numerically
2. Convert to XMP standard schema
`for i in {1..420}; do ./convert_json_xmp.sh "$i".json xmp/"$i".json;done`
3. Move {1..420}_xmp.json to gltf-metadata-cli directory
4. Run for loop
`for i in {1..420}; do cargo run -- -i glbs/"$i"_sanitized.glb -o out/"$i".glb -j xmp/"$i".json;done`
If you want the warnings disappear on console just comment out some lines
## Convert to ETM
Make text file with filenames next to IPFS hashses
`IPFS add *.glb > out.txt`
Will look like this:
```
1_LOD0.glb QmRoCb3HD4q7tJqwBg943BC6QVcZ4VJiq2mj13DRBcZM65
1_LOD1.glb QmeXr3P4sLcPkCFmExC2RKuj8U2kohktoetx1xhV5PHRre
2_LOD0.glb QmTAqR9DtpZQJ5WG34ZLCMAAr7n1JCQNz1CBMsYpyLQffS
2_LOD1.glb Qmc61qDKVpXaxBtR4Msxk6ieSjBeZP1YtH1qX8Fm6zCUf3
3_LOD0.glb QmcZBt17B1EfPiNe6sMLx39oZkCHckoYBdbMCLNS9GrZZV
3_LOD1.glb QmdEDCe131LgBWWT4sYv1kwAaWrMzuMRgY7E8UVa6DAfk7
4_LOD0.glb QmaTDADTn7CA9BG1dyqVwvVsHHkobp1mQ1pBggvXN4YmRG
4_LOD1.glb QmfB6ddusp969FP25r7rRK7abpvpwcretBe5f2AAhFesbe
5_LOD0.glb QmPUYFVgxezmhVN8GToyTopQSfKW6w9JJ8uWGUTCr5qiMr
5_LOD1.glb QmYa6Yvnn91xmN15AKAvSVDmuuLhYDJCyzVvbM8rcoHQW5
6_LOD0.glb QmYp9pN42hgrkw9dA5oWb1bnHCrBn5J64w6BquNJkMEZx9
6_LOD1.glb QmbXFJUQFTsYEYCnVxQc5z7F47YWVi3F82MczipnRCVkUQ
7_LOD0.glb QmTcHbBAKq2C46htsGRra9GmxvmgaZdgrAkCi8eKDUgKLC
7_LOD1.glb QmZ7XDgvwJJWF43wkEBDKHnR6Cz7h3du5qWkzpXrnmpewg
8_LOD0.glb QmTqdTcmoxWuRUauaobNjGC2UnDxNDpmkSexw6nLMDjNk6
8_LOD1.glb QmPUn2xCPtjbXRrRqFDvQTHrUFC6DbKxjrpRjJxpnjbVny
9_LOD0.glb QmR5K1d1iARhVgq72ykCAEx6VFU5GaeGAWura9DVsaZa6F
9_LOD1.glb QmWKBuxzujKxFPLrpnpW94g5J3rH82mts6JbYNQuYNgQgJ
```
Split into 2 files for LOD1 and LOD2 for easier scripting
```bash!
cat out.txt| grep LOD0 > LOD0.txt
cat out.txt| grep LOD1 > LOD1.txt
```
Write to combined json file
Write out to separate files
```bash
for i in {1..420}; do
./script.sh | tee $i.json
done
```
Convert final_XMP metadata to ETM
**Example of final_XMP metadata, based on opensea / zora**
```json!
{
"name": "Boomboxhead #1",
"created_by": "Boomboxhead",
"external_url": "https://twitter.com/boomboxheads",
"description": "Boomboxheads V2 is a collection of 420 CC0 avatars on the Ethereum Network. They are 3d multi-format NFTs including artwork, a VRM avatar, and a posed GLB. The assets are available for public use under the CC0 license. This project was produced with boom-tools, an open-source project, running on Unity3d.",
"vrm_url": "ipfs://bafybeihcvozjze2ktj6cjvcs6pvtn7o567isy4vquukktlwcnaspllzhre/1.vrm",
"animation_url": "ipfs://bafybeih72megza2qhvsuvrewlsf5gk5msaqz7dvb2bmpwxs6z7dlbjkpxy/1.glb",
"image": "ipfs://bafybeid7hu5uncizahitkv2jc5vpov2wv4m2e4zq3sb2sgeemglmz7pz4a/1.jpg",
"attributes": [
{
"trait_type": "Hat",
"value": "Antenna"
},
{
"trait_type": "Eyes",
"value": "Nouns"
},
{
"trait_type": "BodyTexture",
"value": "Lines"
},
{
"trait_type": "Pose",
"value": "Joy"
},
{
"trait_type": "BGColor",
"value": "Blue"
},
{
"trait_type": "BBTexture",
"value": "Backwards"
},
{
"trait_type": "Border",
"value": "Gizmos"
}
],
"background_color": "0000FF"
}
```
**Example of the converted metadata, ETM**
```json!
{
"name": "Boomboxhead #1",
"created_by": "Boomboxhead",
"external_url": "https://twitter.com/boomboxheads",
"description": "Boomboxheads V2 is a collection of 420 CC0 avatars on the Ethereum Network. They are 3d multi-format NFTs including artwork, a VRM avatar, and a posed GLB. The assets are available for public use under the CC0 license. This project was produced with boom-tools, an open-source project, running on Unity3d. https://github.com/gm3/boom-tools",
"metadataStandard": "ETM_v1.0.0",
"animation_url": "ipfs://bafybeih72megza2qhvsuvrewlsf5gk5msaqz7dvb2bmpwxs6z7dlbjkpxy/1.glb",
"image": "ipfs://bafybeid7hu5uncizahitkv2jc5vpov2wv4m2e4zq3sb2sgeemglmz7pz4a/1.jpg",
"extensions": [
"ETM_MULTIASSET_v1.0.0"
],
"assets": [
{
"media_type": "model",
"files": [
{
"name": "1.vrm",
"url": "ipfs://bafybeihcvozjze2ktj6cjvcs6pvtn7o567isy4vquukktlwcnaspllzhre/1.vrm",
"file_type": "model/vrm"
},
{
"name": "1_LOD0.glb",
"url": "ipfs://QmRoCb3HD4q7tJqwBg943BC6QVcZ4VJiq2mj13DRBcZM65",
"file_type": "model/gltf"
},
{
"name": "1_LOD1.glb",
"url": "ipfs://QmeXr3P4sLcPkCFmExC2RKuj8U2kohktoetx1xhV5PHRre",
"file_type": "model/gltf"
}
],
"attributes": [
{
"trait_type": "Hat",
"value": "Antenna"
},
{
"trait_type": "Eyes",
"value": "Nouns"
},
{
"trait_type": "BodyTexture",
"value": "Lines"
},
{
"trait_type": "Pose",
"value": "Joy"
},
{
"trait_type": "BGColor",
"value": "Blue"
},
{
"trait_type": "BBTexture",
"value": "Backwards"
},
{
"trait_type": "Border",
"value": "Gizmos"
}
]
}
],
"background_color": "0000FF"
}
```
:dancer: :star-struck: :dancer: :raised_hands: :star:
Not yet actually..
https://etm-standard.github.io/ETM_MULTIASSET_v1.0.0
Want to add 1k and 4k images, 1k for image tag and 4k for high res in metadata
1024 size images
Average file size: 296.831k
Metadata descriptions
For VRM:
```!
{
"name": "YourModelName_VRM",
"description": "VRM version of the 3D model optimized for virtual reality and real-time applications. Tailored for compatibility with VRM platforms and environments."
}
{
"name": "YourModelName_LOD0",
"description": "High-quality 3D model with maximum details for close-up rendering and the best visual experience. Suitable for high-end applications."
}
{
"name": "YourModelName_LOD1",
"description": "Optimized 3D model with reduced polygon count for better performance in interactive applications or when rendering large scenes. Balanced trade-off between visual quality and resources."
}
```
These descriptions highlight the differences in quality, performance, and compatibility for each version of the file.
MIME
https://www.iana.org/assignments/media-types/model/gltf-binary
**Discussions**
https://github.com/ETM-Standard/etm-standard.github.io/discussions
Useful: https://github.com/infosia/avatar-asset-pipeline#create-level-of-details-lod
> gltfpack_pipeline pipeline implements an ability to run mesh optimization using gltfpack for your glTF file. For instance following pipeline creates multiple Level of Details (LOD) from glTF binary and converts them to VRM.
---
## Fails
First version I tried this, but forgot fields like created_by, external_url, and most importantly attributes. Also there's obvious typos, its just messy.
```json!=!
{
"name": "Boomboxhead #1",
"description": "Boomboxheads V2 is a collection of 420 CC0 avatars on the Ethereum Network. They are 3d multi-format NFTs including artwork, a VRM avatar, and a posed GLB. The assets are available for public use under the CC0 license. This project was produced with boom-tools, an open-source project, running on Unity3d.",
"metadataStandard": "ETM_v1.0.0",
"animation_url": "ipfs://bafybeih72megza2qhvsuvrewlsf5gk5msaqz7dvb2bmpwxs6z7dlbjkpxy/1.glb",
"image": "ipfs://bafybeid7hu5uncizahitkv2jc5vpov2wv4m2e4zq3sb2sgeemglmz7pz4a/1.jpg",
"extensions": ["ETM_MULTIASSET_v1.0.0"],
"assets": [
{
"media_type": "model",
"files": [
{
"name": "1.vrm",
"url": "ipfs://bafybeihcvozjze2ktj6cjvcs6pvtn7o567isy4vquukktlwcnaspllzhre/1.vrm",
"file_type": "model/vrm"
},
{
"name": "1"_LOD0.glb,
"url": "ipfs://QmRoCb3HD4q7tJqwBg943BC6QVcZ4VJiq2mj13DRBcZM65",
"file_type": "model/gltf"
},
{
"name": "1"_LOD1.glb,
"url": "ipfs://QmeXr3P4sLcPkCFmExC2RKuj8U2kohktoetx1xhV5PHRre",
"file_type": "model/gltf"
}
]
}
],
"background_color": "0000FF"
}
```
perhaps its helpful to see the fails to appreciate the wins
j
Basics of LOD
LOD improves performance by rendering simpler versions of models for distant objects
GPT4 John Carmack explaining LOD
Levels of detail (LOD) is a technique used in computer graphics to optimize the rendering of 3D models. By creating multiple versions of a model with varying polygon counts, we can display the most appropriate version based on the viewer's distance. This saves processing power and maintains performance without sacrificing visual quality. In essence, LOD dynamically adjusts the complexity of 3D objects to balance performance and visual fidelity.
glTF Transform + MSFT_lod
https://gltf-transform.donmccurdy.com/-glTF 2.0 SDK
https://github.com/takahirox/glTF-Transform-lod-script- Generate LODs
Results when testing 1.glb
LOD Triangles: 20k (original) -> 6.8k -> 6.6k tris
LOD File sizes: 2.6 MB (original) -> 485 KB -> 285 KB
Downside: Original total file size bloated from 2.6 MB → 3.1 MB with combined glTF
The file size of LOD 0 + 1 < original file size ❗
Here’s a look the size difference between the original glb files exported out of boom-tools and then draco compressed + draco compressed + MSFT_LOD (x2).
420 draco + MSFT_LOD (x2) glbs = 883 MB 😮
Wait a second, 20 MB difference for twice as many glbs? I’m not really sure how, because that’s like a 43x difference between the LODs in file size, and would mean on average the LOD1 is ~48 KB (48 * 420 = 20 MB). However, when I exported a few of these out manually, they seemed on average about 260 KB in size.
WUT DA!?
I tested a few more which is when I realized, the combined LOD version using MSFT_lod extension is smaller than separate exported glTF files. Here’s a visual:
Even if the file size of a combined LOD model is similar to a draco compressed, if the platform doesn’t have HTTP range requests it still downloads the whole file
Draw calls doubled, tested with gltf-viewer---### Progressive Loading
One of the main questions I’m wondering is this:
If you only need LOD1, does it make sense to download the entire file (~8x bigger)?
Could this also be a use case study for glXF,aWIP specification from the Khronos Group for creating a new file type in the glTF ecosystem for efficient composition of multiple glTF assets?
What about reading the paths to the files from the NFT metadata? 🤔
Multi-asset NFT Metadata
There’s a few multi-asset NFT metadata schemes that we’ve been looking at for the past year that are being developed by MetaFactory, NiftyIsland, Cryptoavatars, and Metamundo. I think it’s great that while still early we are all taking slightly different approaches to the same problem, experimenting to see which ones work out the best.
Extensible Token Metadata (ETM)
https://github.com/takahirox/glTF-Blender-IO-MSFT-lod* https://github.com/ETM-Standard/etm-python-module---
We are adding LOD glbs to the metadata for boomboxheads v2 and plan to do some experiments after the mint is finished to see how new specs compare with current NFT metadata standards and best practices. This is a big part of why we’re open sourcing the tools and making a CC0 collection, to help fund collaborative research projects that can level up 3D NFTs and advance the industry forward. Public goods are good! 🌱
https://zora.co/collect/0xb67ff46dfde55ad2fe05881433e5687fd1000312## Realization Moment (Move to another Post)
Another post with cooking analogies about LOD, metaverse salad bowls, optimization workflows, and the world computer thumbnail generator.
This lifts so a ton of upfront work for artists. Many of the platforms already do this for images, but don’t give you the files, instead it’s a system of CDNs sending this data around. I suppose that is for the best. The collectors and platforms that are more incentivized to run nodes powering this decentralized content network.
https://github.com/awesome-selfhosted/awesome-selfhosted#photo-and-video-gallerieshttps://www.clubnft.com/Idea: generate LODs and export with metadata encoded separately or as part of glTF
Reference other LODs inside one of the LODs (IPFS hash)
---
## Upgrading VRMs + Metadata
gunna go with filebase, pinned everything

now have to update the files
https://github.com/web3-storage/w3cli
npm install -g @web3-storage/w3cli
- https://nft.storage/docs/quickstart/
- https://docs.filebase.com/third-party-tools-and-clients/cli-tools
### Test Upgrade
We scrambled NFTs when minting, so now the json id no longer matches the name in the metadata. For example json 340 points to Boomboxhead #160.
Question: Does zora descramble by default, or do we manually update the metadata with these new rules in mind?

Test 1: Redownload the metadata from IPFS hash with new order, update fields accordingly and reupload. Simple as.
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet