# 2020q3 Homework3 (dict)
contributed by < `Tim096` >
## :memo: 預期目標
* 學習 [ternary search tree](https://en.wikipedia.org/wiki/Ternary_search_tree) 作為 [auto-complete](https://en.wikipedia.org/wiki/Autocomplete) 和 prefix search 的實作機制
* 學習 [Bloom filter](https://en.wikipedia.org/wiki/Bloom_filter) 和 [ternary search tree](https://en.wikipedia.org/wiki/Ternary_search_tree) 的整合議題
* bit-wise operation 的實踐
* 設計效能評比 (benchmark) 的程式框架
* 學習 GNU make 和 `Makefile` 撰寫
* 透過 Valgrind 動態程式分析工具及其模組,排除記憶體錯誤和掌握執行時期的記憶體開銷,從而更好地掌握記憶體管理
* 學習 [perf](http://wiki.csie.ncku.edu.tw/embedded/perf-tutorial) 效能分析工具
:::info
:question: [Google Translate](https://translate.google.com/) 一類的線上辭典不僅能夠快速查詢詞彙,還可自動補完和提示相近詞彙,你知道背後的資料結構及數學原理嗎?
:::
## 事前準備
### :dart: Trie 和 Ternary search tree
[Binary Search Tree (BST)](https://zh.wikipedia.org/zh-tw/%E4%BA%8C%E5%85%83%E6%90%9C%E5%B0%8B%E6%A8%B9) 查詢與建立搜尋表的時間複雜度是 O(log~2~n),但是在最糟的情況下時間複雜度可能轉為 $O(n)$,除了要儲存的字串外不須另外分配空間。
[Trie](https://en.wikipedia.org/wiki/Trie) (亦稱 prefix-tree 或字典樹) 的時間複雜度是 $O(n)$,能夠實現 binary search tree 難以做到的 prefix-search,缺點是需要保存大量的空指標,空間開銷較大;
| 優缺點比較 | BST | Trie |
| -------- | -------- | -------- |
| 優點 | 不須另外分配空間 | 時間複雜度"快"(by binary search tree) |
| 缺點 | 時間複雜度"慢" | 空間開銷較大 |
[Ternary Search Tree](https://en.wikipedia.org/wiki/Ternary_search_tree) 是種 trie 資料結構,結合 trie 的時間效率和 BST 的空間效率優點。
* 每個節點 (node) 最多有三個子分支,以及一個 Key;
* Key 用來記錄 Keys 中的其中一個字元 (包括 EndOfString);
* low: 用以指向比目前節點的 Key 值小的節點;
* equal: 用來指向與目前節點的 Key 值一樣大的節點;
* high: 用來指向比目前節點的 Key 值大的節點;
Ternary Search Tree 的應用:
* spell check: Ternary Search Tree 可以當作字典來保存所有的單詞。一旦在編輯器中輸入單詞,可在 Ternary Search Tree 中並行搜尋單詞以檢查正確的拼寫方式;
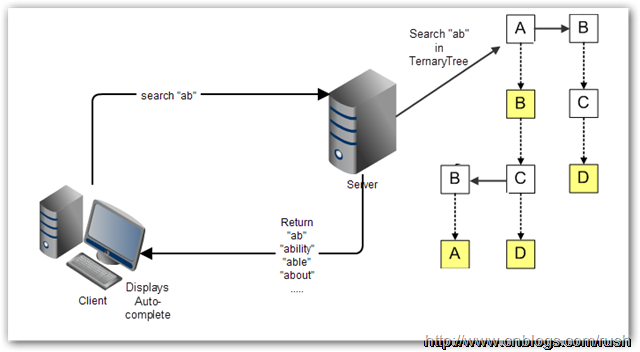
* Auto-completion: 使用搜尋引擎進行時,提供自動完成(Auto-complete)功能,讓使用者更容易查詢相關資訊
對於 Web 應用程式來說,自動完成的繁重處理工作絕大部分要交給伺服器。許多時候,自動完成不適宜一下子全都下載到客戶端,TST 是保存在伺服器上,客戶端把使用者已輸入的開頭詞彙提交到伺服器進行查詢,然後伺服器依據 TST 獲取相對應的資料列表,最後把候選的資料列表返回給客戶端。
## 修改 dict 中錯誤
[bloom.c 的錯誤更正](https://hackmd.io/@YLowy/HkyD5pqBv#%E5%B0%8D%E6%96%BC-bloomc-%E9%80%B2%E8%A1%8C%E9%8C%AF%E8%AA%A4%E6%9B%B4%E6%AD%A3)
## Code Overview
開始前先解讀 dict 程式碼
### test_common.c
- [ ] main()
```c=
int main(int argc, char **argv)
{
...
int CPYmask = -1;
...
if (!strcmp(argv[1], "CPY") || (argc > 2 && !strcmp(argv[2], "CPY"))) {
CPYmask = 0;
REF = DEL;
printf("CPY mechanism\n");
} else
printf("REF mechanism\n");
...
```
:::warning
:warning: 上述程式碼寫得很差,你大可直接改寫。可參考 [x-compressor](https://github.com/jserv/x-compressor/blob/master/x.c#L59-L71),檢查 `argv[0]` 的名稱,後者就是執行檔的名稱,因此你可以建立 `test-common` 執行檔後,透過 [soft link](https://www.cyberciti.biz/faq/creating-soft-link-or-symbolic-link/) 來建立形如 `test-cpy` 和 `test-ref` 的檔案,再由 C 程式判斷其作用。對照看 [x-compressor/Makefile](https://github.com/jserv/x-compressor/blob/master/Makefile#L17-L19)
:notes: jserv
:::
CPYmask 預設為 0xFFFFFFFF
若是對此程式傳入參數 " CPY " 會將 CPYmask 值帶入成 0x00000000
並在之後讀檔案 cities.txt 之後, t1 紀錄當下時間
```c=61
t1 = tvgetf();
```
首先建立 bloom filter table
```c=63
bloom_t bloom = bloom_create(TableSize);
```
如果以 REF 機制會建立一個 memory pool , 並且讓 Top 指向該 pool 首位
```c=67
if (CPYmask) {
/* memory pool */
pool = (char *) malloc(poolsize * sizeof(char));
Top = pool;
}
```
再來做基本的資料處理
```c=74
while (fgets(buf, WORDMAX, fp)) {
int offset = 0;
for (int i = 0, j = 0; buf[i + offset]; i++) {
Top[i] =
(buf[i + j] == ',' || buf[i + j] == '\n') ? '\0' : buf[i + j];
j += (buf[i + j] == ',');
}
...
```
要解讀這裡首先要先觀察 cities.txt 內容
```
Shanghai, China
Buenos Aires, Argentina
Mumbai, India
Mexico City, Distrito Federal, Mexico
Karachi, Pakistan
İstanbul, Turkey
Delhi, India
Manila, Philippines
Moscow, Russia
...
```
...
ASCII " "(空格) -> 0x20
ASCII "\0"(NUL) -> 0x00
...
而這裡想要進行的處理為將該行讀取到的資料 ( buf ) 的逗號、逗號後的空格、跳行取代掉
舉例而言,
`Shanghai, China` 會轉變成 `Shanghai\0China\0`
`Mexico City, Distrito Federal, Mexico` 會轉變成 `Mexico City\0Distrito Federal\0Mexico\0`
所以讀取一行內的資料會穿插 "\0" 變成多組字串形成字串組
所以會用下面的 `while (*Top) {...` 將此字串組餵進 tst 以及 bloom filter 中
並讓 Top 指向轉換後資料的首位
```c=81
while (*Top) {
if (!tst_ins_del(&root, Top, INS, REF)) { /* fail to insert */
fprintf(stderr, "error: memory exhausted, tst_insert.\n");
fclose(fp);
return 1;
}
bloom_add(bloom, Top);
idx++;
int len = strlen(Top);
offset += len + 1;
Top += len + 1;
}
Top -= offset & ~CPYmask;
memset(Top, '\0', WORDMAX);
}
```
取得資料後,會將該資料餵進 tst_ins_del(...) 以及 bloom_add(...)
idx 為總加入單字數
offset 指派為 該資料長度 + 1 以計算位移
Top 為 pointer type ,用意為讓 Top 能夠指向 " 下一筆欲加入處理過後資料的位置 "
這邊還要解釋 CPY REF 兩種機制在此處不同的處理 :
1. REF 機制中 CPYmask 為 0xFFFFFFFF
在`Top -= offset & ~CPYmask;` 中
Top = Top - offset & 0x00000000
Top 並不會作修正
先前提到 REF 架構時候會建立一個 memory pool 並讓將位址指派給 Top
Top 會成為 memory pool 中紀錄下一筆資料的起始位址
2. CPY 機制中 CPYmask 為 0x00000000
在`Top -= offset & ~CPYmask;` 中
Top = Top - offset & 0xFFFFFFFF
Top 會成為原先的指向 word 的位址
```c=36
char word[WRDMAX] = "";
```
之後兩者都在該 Top 指標指向空間往後 WORDMAX 大小做資料清空,全部帶入"\0", 並重複動作讓所有 cities.txt 的資料寫入 tst 以及 bloom filter
全部做完之後會寫入到第二個時間 t2
```c=96
t2 = tvgetf();
```
t2 - t1
此處可以知道選用方法花費多少時間建立 ternary_tree
在 main 函式中的 tst_ins_del(&root, Top, INS, REF) 也必須了解
在一開始的 Enumeration 中宣告
```c=15
enum { INS, DEL, WRDMAX = 256, STKMAX = 512, LMAX = 1024 };
```
其中 INS , DEL 用來帶進 tst_ins_del 的參數
後面的 REF 在 main程式碼中用來表示為 CPY 或者 REF 機制
```c=49
REF = DEL;
```
我個人不喜歡這樣的的表達,應該要有更容易解讀方式實作
### tst.c
- [ ] tst_ins_del
```c=277
void *tst_ins_del(tst_node **root, const char *s, const int del, const int cpy)
{
int diff;
const char *p = s;
tst_stack stk = {.data = {NULL}, .idx = 0};
tst_node *curr, **pcurr;
```
diff 用來表示 加入字串的當時ASCII - 字元當前 node 的ASCII數值 (似乎可以省略這個變數?)
創建一個 stack stk (為何指標陣列大小要給 2 倍的WORDMAX?)
```c=225
if (!root || !s)
return NULL; /* validate parameters */
if (strlen(s) + 1 > STKMAX / 2) /* limit length to 1/2 STKMAX */
return NULL; /* 128 char word length is plenty */
```
檢查輸入是否合理
```c=230
pcurr = root; /* start at root */
while ((curr = *pcurr)) { /* iterate to insertion node */
diff = *p - curr->key; /* get ASCII diff for >, <, = */
if (diff == 0) { /* if char equal to node->key */
if (*p++ == 0) { /* check if word is duplicate */
if (del) { /* delete instead of insert */
(curr->refcnt)--; /* decrement reference count */
/* chk refcnt, del 's', return NULL on successful del */
return tst_del_word(root, curr, &stk, cpy);
} else
curr->refcnt++; /* increment refcnt if word exists */
return (void *) curr->eqkid; /* pointer to word / NULL on del */
}
pcurr = &(curr->eqkid); /* get next eqkid pointer address */
} else if (diff < 0) { /* if char less than node->key */
pcurr = &(curr->lokid); /* get next lokid pointer address */
} else { /* if char greater than node->key */
pcurr = &(curr->hikid); /* get next hikid pointer address */
}
if (del)
tst_stack_push(&stk, curr); /* push node on stack for del */
}
```
考慮到目前使用到 INSERT , 先預想 del = 0 可以把上述程式碼簡化成容易理解版本:
```c=230
pcurr = root;
while ((curr = *pcurr)) {
diff = *p - curr->key;
if (diff == 0) {
if (*p++ == 0) {
curr->refcnt++;
return (void *) curr->eqkid;
}
pcurr = &(curr->eqkid);
} else if (diff < 0) {
pcurr = &(curr->lokid);
} else {
pcurr = &(curr->hikid);
}
}
```
很容易看得出curr 會指向當前 tst 中正要開始做當下字串 INSERT 的 node
```c=257
for (;;) {
/* allocate memory for node, and fill. use calloc (or include
* string.h and initialize w/memset) to avoid valgrind warning
* "Conditional jump or move depends on uninitialised value(s)"
*/
if (!(*pcurr = calloc(1, sizeof **pcurr))) {
fprintf(stderr, "error: tst_insert(), memory exhausted.\n");
return NULL;
}
curr = *pcurr;
curr->key = *p;
curr->refcnt = 1;
curr->lokid = curr->hikid = curr->eqkid = NULL;
if (!*root) /* handle assignment to root if no root */
*root = *pcurr;
/* Place nodes until end of the string, at end of stign allocate
* space for data, copy data as final eqkid, and return.
*/
if (*p++ == 0) {
if (cpy) { /* allocate storage for 's' */
const char *eqdata = strdup(s);
if (!eqdata)
return NULL;
curr->eqkid = (tst_node *) eqdata;
return (void *) eqdata;
} else { /* save pointer to 's' (allocated elsewhere) */
curr->eqkid = (tst_node *) s;
return (void *) s;
}
}
pcurr = &(curr->eqkid);
}
```
上面會對於接下來要加入的字元建立並且新增該 tst_node 空間,並且在讀取到最後一個字元時 ( 也就是該字元的下一個字元為 '\0' ) 時檢查是 CPY 或者 REF 機制
如果是 CPY 機制以 strdup 複製一個等同 s 指向的字串,並指派給 eqkid
如果是 REF 機制則直接把該字串的 pointer (也就是 s) 指派給 eqkid
為什麼要那麼做?原因 :
#### [分飾多角的 eqkid](https://hackmd.io/@sysprog/2020-dict#%E5%88%86%E9%A3%BE%E5%A4%9A%E8%A7%92%E7%9A%84-eqkid)
Linux man page 對於 [strdup](https://man7.org/linux/man-pages/man3/strdup.3p.html) 的描述:
> The strdup() function returns a pointer to a new string which is a duplicate of the string s. Memory for the new string is obtained with malloc(3), and can be freed with free(3).
查 C11 規格書其實沒有講到 strdup() ,後來發現這其實並非規範在 ISO C standard 中,仰賴實作,以 malloc() 在 heap 中建立副本。
當在 Insert 新的單字的時候,會一路 malloc 建立一條 tst_node list 並在最後的 eqkid 指向一個 malloc 的字串。
在 Insert 像是 "Pneumonoultramicroscopicsilicovolcanoconiosis" 這種很難出現分支的單字,基本上在 Heap 中的 tst_node 以及最後的 eqkid 指向的空間會建立在一起。
- [ ] tst_del_word
這邊程式碼非常長,而且 branch 行為非常多,如果不從脈絡以及大綱開始看會很難看懂
這段程式碼的核心行為是對於每一種 del 前提條件下進行調整
主要行為分為兩種 :
1. 刪掉該點之後如何接上不該被刪掉的節點
2. 接上節點時候要考量的 Rotate 行為
以下拆成 5 個最大部分進行,當該 "tst_node" 成為欲刪除目標時候考量行為
```
static void *tst_del_word(tst_node **root,
tst_node *node,
tst_stack *stk,
const int freeword)
{
tst_node *victim = node; /* begin deletion w/victim */
tst_node *parent = tst_stack_pop(stk); /* parent to victim */
if (!victim->refcnt) { /* if last occurrence */
if (!victim->key && freeword) /* check key is nul */
free(victim->eqkid); /* free string (data) */
/* remove unique suffix chain - parent & victim nodes
* have no children. simple remove until the first parent
* found with children.
*/
while (!parent->lokid && !parent->hikid && !victim->lokid &&
!victim->hikid) {
// A Part
}
/* check if victim is prefix for others (victim has lo/hi node).
* if both lo & hi children, check if lokid->hikid present, if not,
* move hikid to lokid->hikid, replace node with lokid and free node.
* if lokid->hikid present, check hikid->lokid. If not present, then
* move lokid to hikid->lokid, replace node with hikid free node.
*/
if (victim->lokid && victim->hikid) { /* victim has both lokid/hikid */
// B Part
} else if (victim->lokid) { /* only lokid, replace victim with lokid */
// C Part
} else if (victim->hikid) { /* only hikid, replace victim with hikid */
//D Part
} else { /* victim - no children, but parent has other children */
//E Part
}
} else /* node->refcnt non-zero */
printf(" %s (refcnt: %u) not removed.\n", (char *) node->eqkid,
node->refcnt);
return victim; /* return NULL on successful free, *node otherwise */
}
```
#### A Part
最值觀的刪除條件,無後顧之憂所以我全都要刪

#### B Part
有了左右兩個子節點時,就要連同考慮該節點刪除後該如何接,rotate 方式其實與資料結構中的紅黑數相似,不過這邊要考慮三個節點,所以程式碼看起來比較多

#### C Part
直接將父節點的 eqkid 指向自己的子節點即可

#### D Part
同 C Part ,不過改成hikid

#### E Part
自身無子節點,可以父節點有其他的子節點,勢必要讓其中一個取代自己成為父節點指向的 eqkid ,這邊也要考慮 rotate 問題所以程式碼看起來很大

### bloom.c
觀察 bloom filter 所進行之行為
在 加入單字前會先建立 bloom filter table
資料結構如下:
test_common.c
`bloom_t bloom = bloom_create(TableSize);`
```graphviz
digraph A {
rankdir=L;
a [label="bloom" shape = circle]
b [shape=record fontsize=24 label="{<fun>func|<bits>bits|<sizes>size = 5000K}"]
c [shape=record fontsize=24 label="{bitTable}"]
d [shape=record fontsize=24 label="{function pointer = \"djb2\"|<next>next}"]
e [shape=record fontsize=24 label="{function pointer = \"jenkins\"|<next>next}"]
null [label="Null" shape = circle]
a->b
b:fun->d
b:bits->c
d:next->e
e:next->null
}
```
再來會對該單字進行 Hash 提並且記錄在 bitmap 中
`bloom_add(bloom, Top);`
其對應方式如下
```c=83
void bloom_add(bloom_t filter, const void *item)
{
struct bloom_hash *h = filter->func;
uint8_t *bits = filter->bits;
while (h) {
unsigned int hash = h->func(item);
hash %= filter->size;
bits[hash >> 3] |= 0x40 >> (hash & 7);
h = h->next;
}
}
```
由於用 bitmap 紀錄,先找到此對應的 byte 位置
bits[hash >> 3] :
```graphviz
digraph A{
rankdir=LR;
b [shape=record fontsize=24 label="{ 0| 0| 0| 0| 0| 0| 0| 0 }"]
}
```
hash>>3
hash & 7 => hash & 00000111
hash 值會剩下後 3 bit ,也就是該 byte 之 offset (000 ~ 111) 也就是 0 到 7
再來對該bytes 進行 " or " 操作紀錄 Hash map
|= 0x40 >> (hash & 7) ... 對該 bit 進行 0 -> 1 操作
```graphviz
digraph A{
rankdir=LR;
b [shape=record fontsize=24 label="{ 0|1| 0| 0| 0| 0| 0| 0 }"]
}
```
為何是 0x40 ?? 應該是 0x80 (0b10000000) 才對
### 對於 bloom.c 進行錯誤更正
早在一開始測試自己的輸入時就發現這個問題,有些原本記錄在 tst 中的資料並沒有能被找到, bloom filter 只會有 "顯示有但事實上沒有" 的錯誤情況,如果 bloom filter 沒能找到之後也不會再 tst 中找尋
```c=168
if (bloom_test(bloom, word)) {
t2 = tvgetf();
printf(" Bloomfilter found %s in %.6f sec.\n", word, t2 - t1);
printf(
" Probability of false positives:%lf\n",
pow(1 - exp(-(double) HashNumber /
(double) ((double) TableSize / (double) idx)),
HashNumber));
t1 = tvgetf();
res = tst_search(root, word);
t2 = tvgetf();
if (res)
printf(" ----------\n Tree found %s in %.6f sec.\n",
(char *) res, t2 - t1);
else
printf(" ----------\n %s not found by tree.\n", word);
} else
printf(" %s not found by bloom filter.\n", word);
```
在inputdata.txt:
```
ap, apple, applepen, applepencil,Penum
```
make 完之後會發現他載入5個單字
選用 serach ap
結果會找到 4 個單字
```
choice: s
find words matching prefix (at least 1 char): ap
ap - searched prefix in 0.000001 sec
suggest[0] : ap
suggest[1] : apple
suggest[2] : applepen
suggest[3] : applepencil
```
find ap :+1:
```
choice: f
find word in tree: ap
Bloomfilter found ap in 0.000001 sec.
Probability of false positives:0.000000
----------
Tree found ap in 0.000000 sec.
```
find apple :-1:
```
Commands:
a add word to the tree
f find word in tree
s search words matching prefix
d delete word from the tree
q quit, freeing all data
choice: f
find word in tree: apple
apple not found by bloom filter.
```
全部單字中只有 apple 並未能找到
我懷疑是 bloom filter 這裡寫錯了
對 bloom_add, bloom_test 進行修改 0x40 ->0x80
```c=83
void bloom_add(bloom_t filter, const void *item)
{
struct bloom_hash *h = filter->func;
uint8_t *bits = filter->bits;
while (h) {
unsigned int hash = h->func(item);
hash %= filter->size;
bits[hash >> 3] |= 0x80 >> (hash & 7);
h = h->next;
}
}
bool bloom_test(bloom_t filter, const void *item)
{
struct bloom_hash *h = filter->func;
uint8_t *bits = filter->bits;
while (h) {
unsigned int hash = h->func(item);
hash %= filter->size;
if (!(bits[hash >> 3] & (0x80 >> (hash & 7)))) {
return false;
}
h = h->next;
}
return true;
}
```
remake 之後以相同的 inputdata 再試一次
```
Commands:
a add word to the tree
f find word in tree
s search words matching prefix
d delete word from the tree
q quit, freeing all data
choice: f
find word in tree: apple
Bloomfilter found apple in 0.000002 sec.
Probability of false positives:0.000000
----------
Tree found apple in 0.000001 sec.
```
成功找到問題點,果然是這邊的問題
### GDB 實驗
新增 testinput.txt :
```
ap, apple
apple, Pneum
```
修改 test_common.c :
```c=32
#define IN_FILE "testinput.txt"
```
```
$ make clean
$ make
```
```
$ gdb -q ./test_common
```
```
Reading symbols from ./test_common...
(gdb) b main
Breakpoint 1 at 0x185f: file test_common.c, line 35.
(gdb) r CPY
Starting program: /home/ylowy/linux2020/dict/test_common CPY
Breakpoint 1, main (argc=0, argv=0x0) at test_common.c:35
35 {
(gdb) until 97
CPY mechanism
main (argc=2, argv=0x7fffffffe518) at test_common.c:97
97 fclose(fp);
(gdb) print t1
$1 = 1601403009.8308451
(gdb) print t2
$2 = 1601403009.8309977
```
執行到 tst 建立完成, t1 , t2 時間
```
(gdb) ptype tst_node
type = struct tst_node {
char key;
unsigned int refcnt;
struct tst_node *lokid;
struct tst_node *eqkid;
struct tst_node *hikid;
}
(gdb) print sizeof(tst_node)
$39 = 32
```
>先前提到的 alignment 問題
sizeof(char) = 1
sizeof(unsigned int) = 4
sizeof(tst_node *) = 8
```
(gdb) p *root
$3 = {key = 97 'a', refcnt = 1, lokid = 0x55555555ca90,
eqkid = 0x55555555c930, hikid = 0x0}
(gdb) p root
$4 = (tst_node *) 0x55555555c900
```
```
(gdb) print *(char*)(root->eqkid->eqkid->eqkid)
$11 = 97 'a'
(gdb) print *(char*)(root->eqkid->eqkid->eqkid+1)
$12 = 112 'p'
(gdb) print *(char*)(root->eqkid->eqkid->eqkid+2)
$13 = 0 '\000'
```
可以清楚了解第一個字串 " ap " 建立過程,以及在 " key = '\0' " node 建立的 eqkid指向字串空間 " 'a' , 'p' , '\0' "
```
(gdb) print*root
$7 = {key = 97 'a', refcnt = 1, lokid = 0x55555555ca90, eqkid = 0x55555555c930, hikid = 0x0}
(gdb) print root
$8 = (tst_node *) 0x55555555c900
(gdb) print root->eqkid
$11 = (struct tst_node *) 0x55555555c930
(gdb) print *(root->eqkid)
$12 = {key = 112 'p', refcnt = 1, lokid = 0x0, eqkid = 0x55555555c960, hikid = 0x0}
(gdb) print root->eqkid->eqkid
$13 = (struct tst_node *) 0x55555555c960
(gdb) print *(root->eqkid->eqkid)
$14 = {key = 0 '\000', refcnt = 1, lokid = 0x0, eqkid = 0x55555555c990, hikid = 0x55555555c9b0}
```
在 55 c9 00 中建立 root (32 bytes tst_node)
第一個 97 代表 'a' (char) -> 3 個 byte 是沒用的
第二個 1 代表 'refcnt' (unsigned int)
第三四個 1431685776 21845 ( 10進位的 lokid address ) -> 0x55555555ca90
第五六個 1431685424 21845 ( 10進位的 eqkid address ) -> 0x55555555c930
第七八個 0 0 ( 10進位的 hikid address ) -> 0x000000000000
`0x55555555c920: 0 0 49 0`
:::info
這行不確定存放甚麼 不過也說明就算是接著 malloc() 也不會把記憶體位置連續配置在一起
:::
root -> eqkid 指向的紀體空間 ( ASCII('p') = 112 )
`0x55555555c930: 112 1 0 0`
依序搜索下去
```
0x55555555c960: 0 1 0 0
0x55555555c970: 1431685520 21845 1431685552 21845
```
1431685520 21845 ( 0x55555555c990 ) -> 該 tst_node 的 eqkid 由於是尾端('\0') 該eqkid 會指向字串
```
0x55555555c900: 97 1 1431685776 21845
0x55555555c910: 1431685424 21845 0 0
0x55555555c920: 0 0 49 0
0x55555555c930: 112 1 0 0
0x55555555c940: 1431685472 21845 0 0
0x55555555c950: 0 0 49 0
0x55555555c960: 0 1 0 0
0x55555555c970: 1431685520 21845 1431685552 21845
0x55555555c980: 0 0 33 0
0x55555555c990: 28769 0 0 0
0x55555555c9a0: 0 0 49 0
0x55555555c9b0: 112 1 0 0
0x55555555c9c0: 1431685600 21845 0 0
0x55555555c9d0: 0 0 49 0
0x55555555c9e0: 108 1 0 0
0x55555555c9f0: 1431685648 21845 0 0
0x55555555ca00: 0 0 49 0
0x55555555ca10: 101 1 0 0
```
對於該 0x55555555c990 找尋
```
(gdb) print *(char*)(0x55555555c990)
$15 = 97 'a'
(gdb) print (char*)(0x55555555c990)
$16 = 0x55555555c990 "ap"
```
可以發現跟我們實作的內容相同
textinput.txt 在 Heap 空間中可以確定是字串是建構在該 list 下一個
```
(gdb) print (char*)(root->lokid->eqkid->eqkid->eqkid->eqkid->eqkid->eqkid)
$25 = 0x55555555cbb0 "Pneum"
```
再來試試看 REF 機制
`(gdb) r REF`
版面緣故直接找到尾端 node ,而 REF 架構中 eqkid 會指向遙遠的 0x7fffd9390010
```
(gdb) p *(root->eqkid->eqkid)
$6 = {key = 0 '\000', refcnt = 1, lokid = 0x0, eqkid = 0x7fffd9390010, hikid = 0x55555555c990}
```
該 process 的 Heap 到 Stack 的距離
以上是使用 GDB 觀察 test_common CPY 以及 REF 機制的 Insert Data.txt 行為的分析,剛好回顧一下 GDB 操作
### Perf 實驗
`make test`
```
Performance counter stats for './test_common --bench CPY s Tai' (100 runs):
510,9294 cache-misses # 52.157 % of all cache refs ( +- 0.50% )
979,6034 cache-references ( +- 0.12% )
5,8790,6063 instructions # 1.16 insn per cycle ( +- 0.02% )
5,0593,6526 cycles ( +- 0.18% )
0.189083 +- 0.000529 seconds time elapsed ( +- 0.28% )
```
```
Performance counter stats for './test_common --bench REF s Tai' (100 runs):
499,0523 cache-misses # 51.495 % of all cache refs ( +- 0.60% )
969,1313 cache-references ( +- 0.14% )
5,5442,8501 instructions # 1.11 insn per cycle ( +- 0.00% )
4,9995,3329 cycles ( +- 0.22% )
0.186238 +- 0.000442 seconds time elapsed ( +- 0.24% )
```
## 在 GitHub 上 fork dict,視覺化 ternary search tree + bloom filter 的效能表現並分析。注意,需要設計實驗,允許不同的字串輸入並探討 TST 回應的統計分佈
## 以 perf 分析 TST 程式碼的執行時期行為並且充分解讀
## 研讀 Xor Filters: Faster and Smaller Than Bloom and Cuckoo Filters 論文並參閱對應程式碼實作 xor_singleheader,引入上述 dict 程式碼中,需要比較原有的 bloom filter 和 xor filter 在錯誤率及記憶體開銷
## 如何縮減頻繁 malloc 帶來的效能衝擊呢?提示: memory pool
## 在現有的開放原始碼專案中,找出使用 bloom filter 的專案,並解析其導入的考量
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet