---
tags: 你所不知道的 C 語言, 進階電腦系統理論與實作, NCKU Linux Kernel Internals, 作業系統
---
# 指標、goto與流程控制、程式設計技巧
contributed by <`RusselCK` >
###### tags: `RusselCK`
* https://www.embedded.com
## [指標篇](/@sysprog/c-pointer?type=view) (上)
* [C 語言: 超好懂的指標](https://kopu.chat/2017/05/15/c%E8%AA%9E%E8%A8%80-%E8%B6%85%E5%A5%BD%E6%87%82%E7%9A%84%E6%8C%87%E6%A8%99%EF%BC%8C%E5%88%9D%E5%AD%B8%E8%80%85%E8%AB%8B%E9%80%B2%EF%BD%9E/)
* [Everything you need to know about pointers in C](https://boredzo.org/pointers/)
#### 頭腦體操
* [godbolt](http://gcc.godbolt.org/): 直接在網頁上看到 gcc 生成的程式碼
1. 科技公司面試題:
```cpp
void **(*d) (int &, char **(*)(char *, char **));
```
* 上述宣告的解讀:
* d is a pointer to a function that takes two parameters:
- a reference to an int and
- a pointer to a function that takes two parameters:
- a pointer to a char and
- a pointer to a pointer to a char
- and returns a pointer to a pointer to a char
* and returns a pointer to a pointer to void
2. [How to read this prototype?](http://stackoverflow.com/questions/15739500/how-to-read-this-prototype)
```cpp
void ( *signal(int sig, void (*handler)(int)) ) (int);
```
* The whole thing declares a function called signal:
* signal takes an int and a function pointer
* this function pointer takes an int and returns void
* signal returns a function pointer
* this function pointer takes an int and returns a void
* Breaks douwn
```cpp
signal -- signal
signal( ) -- is a function
signal( sig ) -- with a parameter named sig
signal(int sig, ) -- of type int
signal(int sig, handler ) -- and a parameter named handler
signal(int sig, *handler ) -- which is a pointer
signal(int sig, (*handler)( )) ) -- to a function
signal(int sig, (*handler)(int)) ) -- taking an int parameter
signal(int sig, void (*handler)(int)) ) -- and returning void
*signal(int sig, void (*handler)(int)) ) -- returning a pointer
( *signal(int sig, void (*handler)(int)) )( ) -- to a function
( *signal(int sig, void (*handler)(int)) )(int) -- taking an int parameter
void ( *signal(int sig, void (*handler)(int)) )(int); -- and returning void
```
* 該如何解釋 [qsort(3)](https://linux.die.net/man/3/qsort) 的參數和設計考量呢?
* 為何我看到的程式碼往往寫成類似下面這樣?
```cpp
struct list **lpp;
for (lpp = &list; *lpp != NULL; lpp = &(*lpp)->next)
```
#### 回頭看 C 語言規格書
- C 語言 發展的目的:開發 UNIX OS
* ==我學一個東西,是為了什麼?==
* `&a` : address of a
* `*a` : dereference (value) of a
* `=` : assignment
* ==C 語言只有 call-by-value==,沒有 call by address 這種說法
* Pointer type 是 scalar types
* 可作 + - ( 遞增或遞移 1 個「單位」)
* 不能做 * /
* incomplete type : An array type of **unknown size**
* 不為 object ( 物件 )
* forward declaration 技巧
```cpp
// declare
struct GraphicsObject; // 無細部定義
// instance
struct GraphicsObject obj; // 不合法
struct GraphicsObject *obj; // 合法
```
* 看起來三個不相關的術語「陣列」、「函式」,以及「指標」都稱為 derived declarator types
- **(練習題)** 設定絕對地址為 `0x67a9` 的 32-bit 整數變數的值為 `0xaa6`,該如何寫?
```cpp
*(int32_t * const) (0x67a9) = 0xaa6;
/* 稱為 Lvalue = Locator value */
```
* 將地址 ( `0x67a9` ) 先轉為 指標,且使用 dereference
* 地址不應該被更動,因此使用 `constant`
- A pointer to void shall have the same representation and alignment requirements as a pointer to a character type.
> 關鍵描述!規範 `void *` 和 `char *` 彼此可互換的表示法
```cpp
int a[3];
int *p;
p = a; /* p points to a[0] */
*a = 5; /* sets a[0] to 5 */
*(a+1) = 5; /* sets a[1] to 5 */
```
* The only difference is in sizeof:
```clike
sizeof(a) /* returns the size of the entire array not just a[0] */
```
#### `void *` - Explicit (顯式) 轉型
* 任何函式若沒有特別標注返回型態,一律變成 `int` (伴隨著 `0` 作為返回值)
```cpp
int main()
{
char *X = 0;
void *Y = 0; // unknown size
char c = X;
char d = Y; // error: void value not ignored as it ought to be
char e = * (char *) Y; // 轉型後 合法
char f = * (double *) Y; // 會有 alignment 問題
}
```
* `void *` 存在的目的就是為了強迫使用者使用 ==顯式轉型== 或是 ==強制轉型==,以避免 Undefined behavior 產生
- C/C++ [Implicit conversion](http://en.cppreference.com/w/cpp/language/implicit_conversion) vs. [Explicit type conversion](https://en.cppreference.com/w/cpp/language/explicit_cast)
- C99 不保證 pointers to data (in the standard, "objects or incomplete types" e.g. `char *` or `void *`) 和 pointers to functions 之間相互轉換是正確的
- 可能會招致 undefined behavior (UB)
- C++ 對此有做改善: [`static/dynamic/reinterpret/const_cast`](http://windsplife.blogspot.com/2010/09/cstaticcast-dynamiccast-reinterpretcast.html)
* [The Lost Art of Structure Packing](http://www.catb.org/esr/structure-packing/) ([中譯版](https://blog.csdn.net/chrovery/article/details/18989779))
* slop only happens in two places.
* storage bound to a larger data type (with stricter alignment requirements) follows storage bound to a smaller one.
* a struct naturally ends before its stride address, requiring padding so the next one will be properly aligned.
* Reordering
( reordering is not guaranteed to produce savings )
* `*a` (pointer): 8 bytes
* ==任何 Data type 的 Pointer 大小都一樣==
* 能兼顧二進位的相容性 (binary compatibility)
* `double` : 8 bytes
* `int` : 4 bytes
* `short` : 2 bytes
* `char` : 1 bytes
* padding
* it’s best to use sizeof() to check the storage size
* The clang compiler has a `-Wpadded`option that causes it to generate messages about alignment holes and padding.
```cpp
#include <assert.h>
struct foo4 {
short s; /* 2 bytes */
char c; /* 1 byte */
};
static_assert(sizeof(struct foo4) == 4, “Check your assumptions");
```
#### 英語 和 C 語言
安裝 `cdecl` 程式,可以幫你產生 C 程式的宣告。
```shell
$ sudo apt-get install cdecl
```
使用案例:
```shell
$ cdecl
cdecl> declare a as array of pointer to function returning pointer to function returning pointer to char
```
會得到以下輸出:
```cpp
char *(*(*a[])())()
```
把前述 C99 規格的描述帶入,可得:
```shell
cdecl> declare array of pointer to function returning struct tag
```
```cpp
struct tag (*var[])()
```
==如果你沒辦法用英文來解說 C 程式的宣告,通常表示你不理解!==
`cdecl` 可解釋 C 程式宣告的意義,比方說:
```shell
cdecl> explain char *(*fptab[])(int)
declare fptab as array of pointer to function (int) returning pointer to char
```
#### Pointer to Pointer
考慮以下程式碼:
```cpp=1
int B = 2;
void func(int *p) { p = &B; }
int main() {
int A = 1, C = 3;
int *ptrA = &A;
func(ptrA);
printf("%d\n", *ptrA);
return 0;
}
```
```
Output :
1
```
在第 5 行 (含) 之前的記憶體示意:
```graphviz
digraph structs {
node[shape=record]
{rank=same; structa,structb,structc}
structptr [label="ptrA|<ptr> &A"];
structb [label="<B> B|2"];
structa [label="<A> A|1"];
structc [label="<C> C|3"];
structptr:ptr -> structa:A:nw
}
```
第 6 行 `ptrA` 數值傳入 `func` 後的記憶體示意:
* ==這裡的 `p` 是 `ptrA` 的副本,只存活在 `func` 中==
```graphviz
digraph structs {
node[shape=record]
{rank=same; structa,structb,structc}
structp [label="p|<p>&A"]
structptr [label="<name_ptr> ptrA|<ptr> &A"];
structb [label="<B> B|2"];
structa [label="<A> A|1"];
structc [label="<C> C|3"];
structptr:ptr -> structa:A:nw
structp:p -> structa:A:nw
}
```
- `func` 依據 [函式呼叫篇](https://hackmd.io/s/HJpiYaZfl) 描述,將變數 `p` 的值指定為 `&B`
```graphviz
digraph structs {
node[shape=record]
{rank=same; structa,structb,structc}
structp [label="p|<p>&B"]
structptr [label="<name_ptr> ptrA|<ptr> &A"];
structb [label="<B> B|2"];
structa [label="<A> A|1"];
structc [label="<C> C|3"];
structptr:ptr -> structa:A:nw
structp:p -> structb:B:nw
}
```
由上圖可見,原本在 main 中的 `ptrA` 內含值沒有改變。這不是我們期望的結果,該如何克服呢?可透過「指標的指標」來改寫,如下:
```cpp=1
int B = 2;
void func(int **p) { *p = &B; }
int main() {
int A = 1, C = 3;
int *ptrA = &A;
func(&ptrA);
printf("%d\n", *ptrA);
return 0;
}
```
```
Output:
2
```
在第 5 行 (含) 之前的記憶體示意:
```graphviz
digraph structs {
node[shape=record]
{rank=same; structa,structb,structc}
structptr [label="ptrA|<ptr> &A"];
structb [label="<B> B|2"];
structa [label="<A> A|1"];
structc [label="<C> C|3"];
structptr:ptr -> structa:A:nw
}
```
第 6 行時,傳入 `func` 的參數是 `&ptrA`,也就是下圖中的 `&ptrA(temp)`:
```graphviz
digraph structs {
node[shape=record]
{rank=same; structa,structb,structc}
structadptr [label="&ptrA(temp)|<adptr> &ptrA"]
structptr [label="<name_ptr> ptrA|<ptr> &A"];
structb [label="<B> B|2"];
structa [label="<A> A|1"];
structc [label="<C> C|3"];
structptr:ptr -> structa:A:nw
structadptr:adptr -> structptr:name_ptr:nw
}
```
進入 func 執行後,在編譯器產生對應參數傳遞的程式碼中,會複製一份剛傳入的 `&ptrA`,產生一個自動變數 `p`,將 `&ptrA` 內的值存在其中,示意如下:
```graphviz
digraph structs {
node[shape=record]
{rank=same; structa,structb,structc}
structp [label="p(in func)|<p> &ptrA"]
structadptr [label="&ptrA(temp)|<adptr> &ptrA"]
structptr [label="<name_ptr> ptrA|<ptr> &A"];
structb [label="<B> B|2"];
structa [label="<A> A|1"];
structc [label="<C> C|3"];
structptr:ptr -> structa:A:nw
structadptr:adptr -> structptr:name_ptr:nw
structp:p -> structptr:name_ptr:nw
}
```
在 `func` 中把 `p` 指向到的值換成 `&B`:
```graphviz
digraph structs {
node[shape=record]
{rank=same; structa,structb,structc}
structp [label="p(in func)|<p> &ptrA"]
structadptr [label="&ptrA(temp)|<adptr> &ptrA"]
structptr [label="<name_ptr> ptrA|<ptr> &B"];
structb [label="<B> B|2"];
structa [label="<A> A|1"];
structc [label="<C> C|3"];
structptr:ptr -> structb:B:nw
structadptr:adptr -> structptr:name_ptr:nw
structp:p -> structptr:name_ptr:nw
}
```
經過上述「指標的指標」,`*ptrA` 的數值從 1 變成 2,而且 `ptrA` 指向的物件也改變了。
#### Forward declaration 搭配指標的技巧
* ==利用 incomplete type 將 界面 和 實作 分離==
- [ ] [oltk.h](https://github.com/openmoko/system-test-suite/blob/master/gta02-dm2/src/oltk/oltk.h)
```cpp
struct oltk; // 宣告 (incomplete type, void)
struct oltk_button;
typedef void oltk_button_cb_click(struct oltk_button *button, void *data);
typedef void oltk_button_cb_draw(struct oltk_button *button,
struct oltk_rectangle *rect, void *data);
struct oltk_button *oltk_button_add(struct oltk *oltk,
int x, int y,
int width, int height);
```
`struct oltk` 和 `struct oltk_button` 沒有具體的定義 (definition) 或實做 (implementation),僅有宣告 (declaration)。
:::info
* `xx_cb_xx` : callback 間接呼叫
* 在某一函式執行時或執行後,依條件或依序去執行所傳遞進來的函式
:::
- [ ] [oltk.c](https://github.com/openmoko/system-test-suite/blob/master/gta02-dm2/src/oltk/oltk.c)
```cpp
struct oltk {
struct gr *gr;
struct oltk_button **zbuttons;
...
struct oltk_rectangle invalid_rect;
};
```
軟體界面 (interface) 揭露於 oltk.h,不管 struct oltk 內容怎麼修改,已公開的函式如 `oltk_button_add` 都是透過 pointer 存取給定的位址,而不用顧慮具體 struct oltk 的實做,如此一來,不僅可以隱藏實做細節,還能兼顧**二進位的相容性 (binary compatibility)**。
同理,==struct oltk_button 不管怎麼變更,在 struct oltk 裡面也是用給定的 pointer 去存取,保留未來實做的彈性==。
#### Pointers vs. Arrays
- array vs. pointer
- in declaration
- **extern**, 如 `extern char x[];` $\to$ <font color=red>不能</font>變更為 pointer 的形式
( 已在別處宣告 )
- **definition/statement**, 如 `char x[10]` $\to$ <font color=red>不能</font>變更為 pointer 的形式
( 已配置連續記憶體 complete type )
- parameter of function, 如 `func(char x[])` $\to$ 可變更為 pointer 的形式 $\to$ `func(char *x)`
( incomplete type )
- in expression
- array 與 pointer 可互換
- [C陷阱: extern & static & 多檔案、宣告、定義、變數、函式](http://ashinzzz.blogspot.com/2013/12/extern-static.html)
```cpp
int main() {
int x[10] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
printf("%d %d %d %d\n", x[4], *(x + 4), *(4 + x), 4[x]);
}
```
```
Output:
4 4 4 4
```
:::info
- `x[i]` 總是被編譯器改寫為 `*(x + i)` <== in expression
- `x[i]` = `*(x + i)` = `*(i + z)` = `i[x]`
:::
* ==C 語言中 沒有 真正的陣列==
## 指標篇 ( 下 )
#### Array declaration with GDB
1. 善用 GDB,能省下沒必要的 `printf()`,並可互動分析: (下方以 GNU/Linux x86_64 作為示範平台) ( **務搭配[原文章]((https://hackmd.io/@sysprog/c-pointer?type=view#Pointers-vs-Arrays))閱讀** )
```cpp
int a[3];
struct { double v[3]; double length; } b[17];
int calendar[12][31];
```
* `*` 放哪好?
```cpp
int *ptr, value; // 是指標就配 * ,清楚明瞭
int* ptr, value; // 會誤會 value 是 pointer
```
* 關於 +1
```shell
(gdb) p &b
$5 = (struct {...} (*)[17]) 0x601060 <b>
(gdb) p &b+1
$6 = (struct {...} (*)[17]) 0x601280 <a>
// 遞移一個 b 的大小 (8*4*17=544)
(gdb) p &(b[0])+1
$7 = struct {...} *) 0x601080 <b+32>
// 遞移一個 b[0] 的大小 (8*4=32)
```
* `p` 命令不僅能 print,還可拿來==變更記憶體內容==:
```shell
(gdb) p (&b[0])->v = {1, 2, 3}
$12 = {1, 2, 3}
(gdb) p b[0]
$13 = {
v = {1, 2, 3},
length = 0
}
```
```shell
(gdb) p &(&b[0])->v[0]
$15 = (double *) 0x601060 <b>
(gdb) p (int *) &(&b[0])->v[0]
$16 = (int *) 0x601060 <b>
(gdb) p *(int *) &(&b[0])->v[0]
$17 = 0
// 因為只取前 4 bytes (int)
(gdb) p *(double *) &(&b[0])->v[0]
$18 = 1
// 取 8 bytes (double)
```
* GDB 強大之處不只如此,你甚至在動態時期可呼叫函式 (改變執行順序),比方說 `memcpy`:
```shell
(gdb) p calendar
$19 = {{0 <repeats 31 times>} <repeats 12 times>}
(gdb) p memcpy(calendar, b, sizeof(b[0]))
$20 = 6296224
(gdb) p calendar
$21 = {{0, 1072693248, 0, 1073741824, 0, 1074266112, 0 <repeats 25 times>}, {0 <repeats 31 times>} <repeats 11 times>}
```
```shell
(gdb) p (void *) 6296224
// 純量 轉成 pointer type
$22 = (void *) 0x6012a0 <calendar>
// 查出位址是 <calendar>
// 得知 6296224 是 memcpy 的目的位址
```
```shell
(gdb) p calendar[0][0]
$33 = 0
(gdb) whatis calendar[0][0]
$34 = int
// 代表 calendar[0][0] 是以 int (4 bytes) 儲存
(gdb) p *(double *) &calendar[0][0]
$23 = 1
// 指標 可以改變存取方式
(gdb) p *(double *) &calendar[0][2]
$24 = 2
(gdb) p *(double *) &calendar[0][4]
$25 = 3
```
2. Adding an integer to a pointer is different from adding that integer to the bit representation of that pointer
```cpp
int a[10];
...
int *p;
p = a; /* take the pointer to a[0] */
p++; /* next element */
p--; /* previous element */
p = p + 1; /* this advances p's value (pointed-address) by sizeof(int) which is usually not 1 */
```
#### Concatenate ( 串接 ) string ( `strcpy()` and `strcat()` )
Suppose we want to concatenate string s and string t into a single string
* Incomplete type
```clike
char *r;
strcpy(r, s);
strcat(r, t);
```
:::danger
Doesn’t work cause r doesn’t point anywhere.
:::
* Lets make r an array – now it points to 100 chars
```cpp
char r[100];
strcpy(r, s);
strcat(r, t);
```
:::warning
This works as long as the strings pointed to by s and t aren’t too big.
:::
* We would like to write something like:
```clike
char r[strlen(s) + strlen(t)];
strcpy(r, s); strcat(r, t);
```
:::warning
However C requires us to state the size of the array as constant.
:::
```clike
char *r = malloc(strlen(s) + strlen(t));
strcpy(r, s); strcat(r, t);
```
:::warning
This fails for three reasons:
1. `malloc()` might fail to allocate the required memory
* 配置失敗 或 malloc(0) 都會回傳 `null`
3. It is important to free the memory allocated
4. We did not allocate enough memory
:::
* The correct code will be:
```cpp
char *r = malloc(strlen(s) + strlen(t) + 1); // use sbrk; change progrram break
if (!r) exit(1); /* print some error and exit */
strcpy(r, s); strcat(r, t);
...
free(r);
r = NULL; /* Try to reset free’d pointers to NULL */
```
#### Duplicate ( 複本 ) a string ( `strdup()` )
- A common C pitfall is to confuse a pointer with the data to which it points
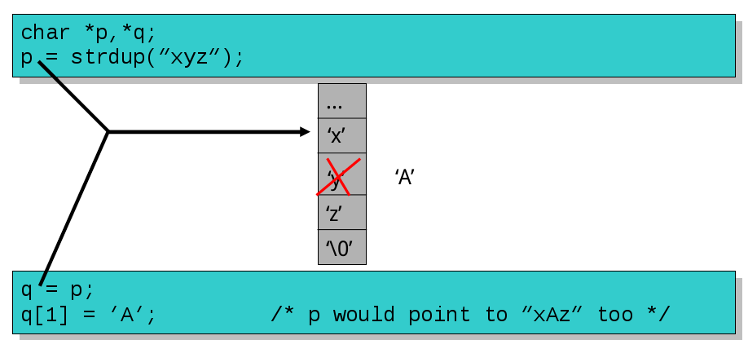
依據 man page [strdup(3)](http://linux.die.net/man/3/strdup) :
> The strdup() function returns a pointer to a new string which is a duplicate of the string s. Memory for the new string is obtained with [malloc(3)](http://linux.die.net/man/3/malloc), and can be freed with [free(3)](http://linux.die.net/man/3/free).
* `strdup()` 實際上會呼叫 `malloc()`,來配置足以放置給定字串的「新空間」。
```cpp
char *strdup(const char *s);
```
* 可能會配置失敗,或 配置的內容不合法
* 你需要適時呼叫 free 以釋放資源。 [==heap==]
* `strdupa()` 透過 [alloca 函式](http://man7.org/linux/man-pages/man3/alloca.3.html)來配置記憶體
```cpp
char *strdupa(const char *s);
```
* 存在 [==stack==],而非 heap,當函式返回時,整個 stack 空間就會自動釋放,不需要呼叫 free。
* `alloca()` 在不同軟硬體平台的落差可能很大
`alloca()` function is machine- and compiler-dependent
* `alloca` function is not in POSIX.1.
* 安全疑慮:若呼叫空間太大,可能會蓋掉 stack上 原有的指令
If the allocation causes stack overflow, program behaviour is ==undefined==.
#### `int main(int argc, char *argv[], char *envp[])` 的奧秘
* [C/C++ 程式設計教學:main 函數讀取命令列參數,argc 與 argv 用法](https://blog.gtwang.org/programming/c-cpp-tutorial-argc-argv-read-command-line-arguments/)
* 用於 ==讀取使用者所輸入的命令列參數==
- `argc`: argument count
- `argv`: argument vector ( 連續的數值 )
```shell
(gdb) x/4s ((char **) argv)[0]
0x7fffffffe7c9: "/tmp/x"
0x7fffffffe7d0: "LC_PAPER=zh_TW"
0x7fffffffe7df: "XDG_SESSION_ID=91"
0x7fffffffe7f1: "LC_ADDRESS=zh_TW"
```
* 後三項是 `envp` (environment variable)
#### C Array 的性質 ( 複習 )
* C array 大概是 C 語言中數一數二令人困惑的部分。根據你使用的地方不同,Array 會有不同的意義:
* 如果是用在 expression,array 永遠會被轉成一個 pointer
* 用在 function argument 以外的 declaration 中它還是一個 array,而且「不能」被改寫成 pointer
* function argument 中的 array 會被轉成 pointer
* 若現在這裡有一個全域變數 (global)
```cpp
char a[10];
```
在另一個檔案中,我不能夠用 `extern char *a` 來操作原本的 `a`,因為實際上會對應到不同的指令 (instruction)。但若你的 declaration 是在 function argument 中,那麼:
* `void function(char a[])` 與 `void function(char * const a)` 是等價的
* 而且,真實的型態會是 pointer
因此你不能用 `sizeof` 來抓它的大小!(array 是 unmodifiable l-value,所以除了被轉成 pointer,它還會是一個不能再被設定數值的指標,因此需要加上 const 修飾。)
最後,用在取值時,array 的行為與 pointer 幾乎雷同,但 array 會是用兩步取值,而 pointer 是三步。(array 的位址本身加上 offset,共兩步,而使用 pointer時,cpu 需先載入 pointer 位址,再用 pointer 的值當作位址並加上 offset 取值)
* 延伸閱讀
* [C 語言雜談:指標和陣列 (上)](http://blog.jobbole.com/86400/)
* [C 語言雜談:指標和陣列 (下)](http://blog.jobbole.com/86412/)
* [C 語言的指標和記憶體洩漏](http://blog.jobbole.com/84548/)
#### Function pointer
1. 為何
```cpp
int main() { return (********puts)("Hello"); }
```
可運作?
:::info
* [putchar、getchar、puts、fgets - OpenHome.cc](https://openhome.cc/Gossip/CGossip/PutcharGetcharPutsGets.html)
* **`int puts ( const char * str );`**
* **Write string to stdout**
* Writes the C string pointed by `str` to the standard output (stdout) and appends a newline character (`'\n'`).
:::
- C99 [ 6.3.2.1 ] A ==function designator== is an expression that has function type
- **Except** when it is the operand of the **sizeof** operator or the unary **&** operator, a **function designator** with type ‘‘function returning type’’ **is converted to** an expression that has type ‘‘**pointer to function returning type’**’.
- `*` is Right associative operator
- C99 [6.5.1 ] It is an ==lvalue==, a function designator, or avoid expression if the unparenthesized expression is, respectively, an lvalue, a function designator, or avoid expression.
- C99 [6.5.3.2-4] The unary * operator denotes indirection. **If the operand points to a function, the result is a function designator**
* (注意到 designator 的發音,KK 音標為 [͵dɛ**zɪg**ˋnetɚ])
:::success
* 程式碼 `(********puts)` 可看作 `(*(*(*(*(*(*(*(*puts))))))))`
* 最裡面的括號 `(*puts)` 由 [ 6.5.3.2-4 ] 可知它是一個 function designator。
* 再根據 [ 6.3.2.1 ],它最後會被轉為 pointer to function returning type。
* 往外延伸一個括號 `(*(*puts))`
* 由於最裡面的括號是一個 function designator,再多一個 * operator 它還是一個 function designator,最後也會被轉為 pointer to function returning type,
* 依此類推最後 `(********puts)` 仍會是一個 function designator。
:::
2. `**fptr` 會是什麼?
```cpp
void (*fptr)();
void test();
fptr = test;
```
* `fptr` is a pointer to function with returning type,
* test 是一個 function designator ,因為不是搭配 `&`, sizeof 使用,所以會被轉成為 pointer to function
* `(*fptr)` 是一個 function pointer
* 搭配 * (dereference, indirection) operator 使用,則它的結果會被轉成為一個 function designator
* `(**fptr)`= `(* ( *fptr) )` ,要拆成兩個部份:
* `*fptr` 是個 function designator, 但是還是會被轉成一個 pointer to function
* 我們可註記為 `(*fptr)`=`fptr'`。
* `(**fptr)`=`*(fptr’) ` 是個 function designator, 最後還是會被轉化為 pointer to function
- 我們可利用 gdb 去查看這些數值,搭配 print 命令:
```shell
(gdb) print test
$1 = {void ()} 0x400526 <test>
(gdb) print test
$2 = {void ()} 0x400526 <test>
(gdb) print fptr
$3 = (void (*)()) 0x400526 <test>
(gdb) print (*fptr)
$4 = {void ()} 0x400526 <test>
(gdb) print (**fptr)
$5 = {void ()} 0x400526 <test>
```
* `$5 = {void ()} 0x400526 <test>` 的 `0x400526` 這個數值是怎麼來的呢?
:::success
* 我們可用以下命令觀察:
```shell
$ gdb -o fp -g fp.c
$ objdump -d fp
```
* 參考輸出裡頭的一段:
```shell
0000000000400526 <test>:
400526: 55 push %rbp
400527: 48 89 e5 mov %rsp,%rbp
40052a: 90 nop
40052b: 5d pop %rbp
40052c: c3 retq
```
* 這個數值其實是==執行檔反組譯後的函式進入點==,但這數值**並非存在實體記憶體的實際數值**,而是**虛擬記憶載入位址**。
:::
#### Address and indirection operators
對應到 C99/C11 規格書 [ 6.5.3.2 ],`&` 所能操作的 operand 只能是:
* function designator - 基本上就是 function name
* `[]` or `*` 的操作結果:跟這兩個作用時,基本上就是相消
- `*` - operand 本身
- `[]` - `&` 會消失,而 `[]` 會被轉換成只剩 `+` (註:原本 `[]` 會是 `+` 搭配 `*`)
+ 例如: `&(a[5]) == a + 5`
* 一個指向非 bit-field or register storage-class specifier 的 object 的 lvalue
> [bit-field](https://hackmd.io/@sysprog/c-bitfield):一種在 struct 或 union 中使用用來節省記憶體空間的物件;
> 特別的用途:沒有名稱的 bit-field 可以做為 padding
除了遇到 `[]` 或 `*` 外,使用 `&` 的結果基本上都是得到 pointer to the object 或是 function 的 address
考慮以下程式碼:
```cpp
char str[123];
```
為何 `str == &str` 呢?
* 實際上左右兩邊的型態是不一樣的,只是值相同。
* 左邊的是 pointer to char:`char *`
- 規格書中表示:除非遇到 sizeof 或是 & 之外,array of type (在這就是指 str) 都會被直接解讀成 pointer to type (在這就是 pointer to char),而這個 type 是根據 array 的第一個元素來
> Except when it is the operand of the sizeof operator or the unary & operator, or is a string literal used to initialize an array, an expression that has type ‘‘array of type’’ is converted to an expression with type ‘‘pointer to type’’ that points to the initial element of the array object and is not an lvalue. (C99 6.3.2.1)
* 右邊的則是 pointer to an array: `char (*)[123]`
- 上面提到:遇到 & 時,str 不會被解讀為 pointer to type,而是做為原本的 object,在這就是 array object,而 address of array object 也就是這個 array object 的起始位址,當然也就會跟第一個元素的位址相同
- 除了用值相同來解釋外,規格書在提到 equality operators 時,也有說到類似情境
> Two pointers compare equal if and only if both are null pointers, both are pointers to the same object (including a pointer to an object and a subobject at its beginning) or function (C99 6.5.9)
#### 針對指標的修飾 (qualifier)
* 指標本身不可變更 (Constant pointer to variable): `const` 在 `*` 之後
> char ==*== const pContent;
* 指標所指向的內容不可變更 (Pointer to constant): `const` 在 `*` 之前
> const char ==*== pContent;
> char const ==*== pContent;
* 兩者都不可變更
> const char ==*== const pContent;
#### ( 習題 ) [Learn C The Hard Way](https://hackmd.io/@sysprog/c-pointer?type=view#Learn-C-The-Hard-Way)
- [電子書](https://users.elis.ugent.be/~jrvdnbro/learn_c_the_hard_way.pdf) / [練習題 ( 中文版 )](https://www.kancloud.cn/wizardforcel/lcthw/169195)
* 編譯器最佳化時,會嘗試用 `memcpy()` 取代 `strcpy()`,前者通常有平台相依的最佳化,而後者因為不能事先知道長度,無法做更有效率的最佳化。
* `strcpy()` 要檢測 `'\0'`
* 但這樣的最佳化技巧要讓編譯器自動施行,導致額外的維護成本
- Security Costs: 一個 `gets()` 就有機會搞垮系統,對照看 [Insecure coding in C](http://www.slideshare.net/olvemaudal/insecure-coding-in-c-and-c)
* [callback function](https://zh.wikipedia.org/wiki/%E5%9B%9E%E8%B0%83%E5%87%BD%E6%95%B0)
* `qsort()`
#### 重新探討「字串」
- [USART](http://wiki.csie.ncku.edu.tw/embedded/USART)
- 多國語言議題
* C 語言規格中定義 string literals 會被分配於 "static storage" 當中 (C99 [6.4.5]),並說明==如果程式嘗試修改 string literals 的內容,將會造成未定義行為==
- 以 gcc 的 ELF target 來說,將 string literals 分配在 read-only data section 中 (當然包含 `\0` 結尾)
- 由於 C 語言提供了一些 syntax sugar 來初始化陣列,這使得 `char *p = "hello world"` 和 `char p[] = "hello world"` 寫法相似,但底層的行為卻大相逕庭
- 以指標的寫法 `char *p` 來說
- ==`p` 將會是指向 static storage 的一個指標==。
- 如此的寫法有潛在問題,因為當開發者嘗試修改 string literals 的內容,將會造成未定義行為,而編譯器並不會對存取 p 的元素提出警告
- 值得注意的是,陣列的寫法依據 C99 規範,string literals 是必須放在 "static storage" 中
- 而 `char p[]` 的語意則表示
- ==要把資料分配在 stack 內==,所以這會造成編譯器 (gcc) 隱性地 (implicitly) 產生額外的程式碼,使得 C 程式在執行時期可把 string literals 從 static storage 複製到 stack 中。
- 雖然字串本身並非存放於 stack 內,但 `char p[]` 卻是分配在 stack 內,這也造成 `return p` 是未定義行為
```cpp=
char *func(){
char p[] = "hello world";
puts(p);
return p;
}
char *func2(){
char *p = "hello world";
puts(p);
return p;
}
int main(){
printf("%p\n", func());
printf("%x\n", func());
printf("%x\n", func2());
}
```
```
Output:
hello world
(nil)
hello world
0
// 空的
hello world
400634
// 位址
```
* 在字串上進行若干操作
* C 語言的規格書中定義了標準函式庫,在 [7.21] ***String handling \<string.h\>*** 提及,以避免製造重複的輪子。
* 接下來問題來了,這些字串處理函式的原型大部分是使用 `char *` 或 `void *` 的型別來當參數,那這些參數到底能不能接受 null pointer `(void *) 0` 呢?
- 答案是,像 `strlen` 一類的 "string handling function" ++**不可**++ 接受 null pointer 作為參數,因為在絕大部分的狀況中,null pointer 並非合法字串 (why?),所以將 null pointer 代入 `strlen()` 也造成未定義行為
- 多數函式庫實作 (glibc) 也不會在內做 null pointer 檢查 (有些函式庫的實作會使用編譯器的延伸語法來提出警告),這意味著,開發者要肩負檢查 null pointer 的一切責任!
- 多做簡查 -> 更多 branch -> 影響效能
#### [array argument 的正確使用時機](https://hackmd.io/@sysprog/c-array-argument)
```cpp
int fn(int a[][10])
```
- ends up being equivalent to something like
```cpp
int fn(int (*a)[10])
```
* "a+1" is actually 40 bytes ahead of "a", so it does *not* act like an "int *".
#### Lvalue 的作用
```cpp
int a = 10;
int *E = &a;
++(*E); // a = a + 1
++(a++); // error
```
E 就是上面 C99 註腳提及的 "a pointer to an object" (這裡的 object 指的就是 a 佔用的記憶體空間),下面列舉 E 這個 identifier 不同角度所代表的身份:
* `E`
+ object: 儲存 address of int object 的區域
+ lvalue: E object 的位置,也就是 E object 這塊區域的 address
* `*E`
+ lvalue: 對 E 這個 object 做 dereference 也就是把 E object 所代表的內容 (address of int object) 做 dereference,也就得到了 int object 的位置,換個說法就是上面所提到的 lvalue that designates the object which E points
以 gcc 編譯上方程式碼會產生
> error: **lvalue** required as increment operand
錯誤訊息,因為 `a++` 會回傳 a 的 value,而這個 value 是暫存值也就是個 non-lvalue,而 `++()` 這個 operator 的 operand 必須要是一個 lvalue,因為要寫回 data,需要有地方 (location) 可寫入
* 延伸閱讀: [Understanding lvalues and rvalues in C and C++](http://eli.thegreenplace.net/2011/12/15/understanding-lvalues-and-rvalues-in-c-and-c)
透過 Lvalue 解釋 compound literal 效果的[案例](http://stackoverflow.com/questions/14105645/is-it-possible-to-create-an-anonymous-initializer-in-c99/14105698#14105698):
```cpp
#include <stdio.h>
struct s { char *a; };
void f(struct s *p) { printf("%s\n", p->a); }
int main() {
f(&(struct s){ "hello world" });
return 0;
}
```
#### 延伸閱讀
- [C 語言常見誤解](https://docs.google.com/document/d/12cR0qb-kl7jB8RA_eHQu8OSmGKEOshwLeX4Mx5qBzUE/edit) by PTT littleshan + Favonia
- 注意:部份以 32-bit 架構為探討對象
- 建議把前面幾節閱讀完,再來讀這篇 FAQ
- [漫談 C 語言](http://www.douban.com/group/topic/55441892/) (更多參考資料)
- [C Traps and Pitfalls](http://www.literateprogramming.com/ctraps.pdf)
- [The Descent to C](http://www.chiark.greenend.org.uk/~sgtatham/cdescent/)
## [goto 和流程控制篇](https://hackmd.io/@sysprog/c-control-flow?type=view)

* [Go To 有害大論戰](http://www.iis.sinica.edu.tw/~scm/ncs/2009/07/go-to-considered-harmful/)
* [[筆記] 深入了解 switch-case](https://airfishqi.blogspot.com/2016/11/switch-case.html)
#### MISRA C 禁用 goto 和 continue (但可用 break)
* [MISRA - the Motor Industry Software Reliability Association](https://www.misra.org.uk/) 針對產業界軟體可靠性與穩定度,提出一系列的方針與準則,而針對 C Programming Language 的部份則稱為 "MISRA-C",目的是在增進嵌入式系統的安全性及可移植性。針對 C++ 語言也有對應的標準 MISRA C++。
* MISRA C 一開始主要是針對汽車產業,不過其他產業也逐漸開始使用 MISRA C,像是航太、電信、國防、醫療設備、鐵路等領域。
- 《[Guidelines for the use of the C language in critical systems](http://caxapa.ru/thumbs/468328/misra-c-2004.pdf)》(或稱 MISRA-C:2004)
[MISRA minimizes mishaps](https://www.embedded.com/electronics-blogs/break-points/4025734/MISRA-minimizes-mishaps) 以 "MISRA-C" 的規範為基礎,標示以下五個原則:
1. C is incompletely specified. **How does process(j++, j); behave?** And exactly what is the size of an int? How astounding that such a basic component of any program is undefined!
* 未定義行為
2. Developers make mistakes, and the language does little to point out many of the even obvious screwups. **It's so easy to mix up "=" and "==."**
3. Programmers don't always have a deep knowledge of the language and so make incorrect assumptions. Compilers have bugs, or purposely deviate from the ANSI standard.
4. Most 8051 compilers, for instance, have run-time packages that take and return single precision results for trig functions instead of the prescribed doubles.
5. C offers little intrinsic support for detecting run-time errors.
* C 語言 是個 包著高階語言外皮的低階語言
* MISRA C forbids goto statements primarily because it can mess up **static analysis**.
* 編譯器最佳化
#### GOTO 沒想像中那麼可怕
* [13118 個 goto 在 Linux 核心原始程式碼](https://github.com/torvalds/linux/search?utf8=%E2%9C%93&q=goto)
* [有時不用 goto 會寫出更可怕的程式碼](http://eli.thegreenplace.net/2009/04/27/using-goto-for-error-handling-in-c)
* 要看!!
* [Common usage patterns of Goto](https://en.wikipedia.org/wiki/Goto#Common_usage_patterns_of_Goto)
* [Finite-state machine](https://en.wikipedia.org/wiki/Finite-state_machine)
* 例外處理 : RAII
- OpenBSD httpd 的「下水道風格」例外處理: [OpenBSD's httpd](https://github.com/reyk/httpd/blob/master/httpd/httpd.c#L564)
- 將==例外全部 `goto fail`==
```cpp
const char *canonicalize_host(const char *host, char *name, size_t len)
{
if (len < 2)
goto fail;
...
plen = strlen(host);
memset(name, 0, len);
for (i = j = 0; i < plen; i++) {
if (j >= (len - 1))
goto fail;
c = tolower((unsigned char) host[i]);
if ((c == '.') && (j == 0 || name[j - 1] == '.'))
continue;
name[j++] = c;
}
for (i = j; i > 0; i--) {
if (name[i - 1] != '.')
break;
name[i - 1] = '\0';
j--;
}
if (j <= 0)
goto fail;
return (name);
fail:
errno = EINVAL;
return (NULL);
}
```
* Linux kernel 裡 nfs 初始化的函式 [fs/nfs/inode.c:2192](https://elixir.free-electrons.com/linux/latest/source/fs/nfs/inode.c#L2192)
#### switch 背後的 goto 和實作考量 ( Label as Value )
* [Computed goto for efficient dispatch tables](https://eli.thegreenplace.net/2012/07/12/computed-goto-for-efficient-dispatch-tables) 這篇提到了兩種實作方式,
* switch-case
* computed goto.
:::success
- 為了有效處理 `switch` 一類的多重分支,GCC 引入 computed goto 這個 GNU extension,參照 [gcc - labels as values](https://gcc.gnu.org/onlinedocs/gcc/Labels-as-Values.html),可以將 label 的記憶體地址存入 `void *` 型態的 pointer 中,用法如下:
```cpp
void *ptr = &&label;
...
goto *ptr;
```
也能一次跟陣列搭配使用:
```cpp
static void *array[] = { &&foo, &&bar, &&hack };
...
goto *array[0];
```
:+1: 執行時期能計算要跳去哪裡、JIT compiler 最佳化
:::
1. switch-case
* 透過一個無窮迴圈內含一個 switch 來判斷目前的 bytecode 應該執行什麼程式
* 程式碼大致如下:( 類似的實作還有 [這篇](http://bartoszsypytkowski.com/simple-virtual-machine/) )
```cpp
while (1) {
switch (instr[pc++]) {
case OP_1:
OP_1();
break;
case OP_2:
OP_2();
break;
...
}
}
```
* 若 沒有 `break`,程式會繼續做下一行
* `case` 只是一個 label,用來標示位址
2. computed goto 來進行 opcode dispatch 的話,程式碼大致如下:
```cpp
static void *op_labels[] = { &&OP_1, &&OP_2, .... };
#define DISPATCH() goto *op_labels[instr[pc++]]
...
OP_1:
OP_1();
DISPATCH();
OP_2:
OP_2();
DISPATCH();
...
```
* 這兩種的效能比較可以從兩個地方來看:
- bounds checking
- branch prediction
bounds checking 是在 switch 中執行的一個環節,每次迴圈中檢查是否有 default case 的狀況,即使程式中的 switch 沒有用到 default case,編譯期間仍會產生強制檢查的程式,所以 switch 會較 computed goto 多花一個 bounds checking 的步驟
branch prediction 的部分,switch 需要預測接下來跳到哪個分支 case,而 computed goto 則是在每個 instruction 預測下一個 instruction,這之中比較直覺的想法是 computed goto 的可以根據上個指令來預測,但是 switch 的每次預測沒辦法根據上個指令,因此在 branch prediction accuracy 上 computed goto 會比較高。
* 延伸閱讀: [實作 simulator](https://hackmd.io/s/Hkf6pkPAb)
#### 用 goto 實作 RAII 開發風格
- C++ 常見的 RAII 指的是 "Resource Acquisition Is Initialisation"
* 字面上的意思是:「資源獲得即進行初始化」。
* 意即:一旦在程式中有「資源配置」的行為,也就是一旦有「配置、釋放」的動作,就讓「配置」成為一個初始化的動作,如此,釋放動作就變成自動的了(依物件的作用範圍 [scope] 決定)。
* C 語言 用 goto 的實作 : ( [RAII in C](https://vilimpoc.org/research/raii-in-c/) )
```cpp
void foo() {
if (!doA())
goto exit;
if (!doB())
goto cleanupA;
if (!doC())
goto cleanupB;
/* everything has succeeded */
return;
cleanupB:
undoB();
cleanupA:
undoA();
exit:
return;
}
```
* 不用 goto 的話,需要寫成這樣:
```cpp
int foo() {
if (!doA())
return;
if (!doB()) {
undoA();
return;
}
if (!doC()) {
undoB();
undoA();
return;
}
}
```
不僅可讀性差,而且要擴充困難。
- 使用 goto 的版本甚至可透過 macro 來包裝例外處理。
- [Cello: High Level C](http://libcello.org/)
* Linux 核心原始程式碼: [shmem.c](https://github.com/torvalds/linux/blob/master/mm/shmem.c)
#### 回頭檢閱 C 語言規格書
:::success
$6.8.6 \space Jump \space statements$
* jump-statement:
- `goto` identifier `;`
- `continue ;`
- `break ;`
- `return` expression~opt~ `;`
* Semantics
A jump statement causes an **unconditional jump** to another place
* 無條件跳躍,注意到範圍是 “another place”,而不是「到任意程式碼」
:::
* 後方的範例:
```cpp
/* ... */
goto first_time;
for (;;) {
// determine next operation
/* ... */
if (need to reinitialize) {
// reinitialize-only code
/* ... */
first_time:
// general initialization code
continue;
}
// handle other operations
/* ... */
}
```
:::info
* 較大的 C 語言專案中用到 `goto`,常見的情境是例外處理。
* 因為 C 語言的特性,出錯了的時候,很多動態配置的記憶體會需要回收掉,
要不然會造成 memory leak,這時候 goto 就變得很方便。
:::
* Jave try catch
* 舉例: CPython 的 [Modules/_asynciomodule.c](https://github.com/python/cpython/blob/master/Modules/_asynciomodule.c#L1711)
```cpp
static void
TaskObj_finalize(TaskObj *task)
{
/* ... */
if (task->task_state != STATE_PENDING ||
!task->task_log_destroy_pending) {
goto done;
}
/* ... */
context = PyDict_New();
if (context == NULL) {
goto finally;
}
message = PyUnicode_FromString("Task was destroyed...");
if (message == NULL) {
goto finally;
}
/* ... */
finally:
Py_XDECREF(context);
Py_XDECREF(message);
/* Restore the saved exception. */
PyErr_Restore(error_type, error_value, error_traceback);
done:
FutureObj_finalize((FutureObj*)task);
}
```
* 第一個 `goto done`,因為還沒 allocate context 或是 message,所以不需要去做善後的工作,如果這時候觸發這個 goto 的話,就直接到底就好。
* 但是如果遇到 context 或是 message allocate 失敗的話,因為已經有 allocate 一些資源,就必須要跳到 finally 去把這些資源給清空以及還原。
:::success
在 [Modern C](http://icube-icps.unistra.fr/img_auth.php/d/db/ModernC.pdf),作者 Jens Gustedt 總結 3 項和 `goto` 有關的規範:
* Rule 2.15.0.1: Labels for goto are visible in the whole function that contains them.
* Rule 2.15.0.2: goto can only jump to a label inside the same function.
* Rule 2.15.0.3: goto should not jump over variable initializations.
:::
#### 和想像中不同的 switch-case ( Clifford’s Device )
1. 考慮以下程式碼:(test.c)
```cpp=
#include <stdio.h>
#define DEBUG 1
#define DBG( ... ) \
if (DEBUG) { __VA_ARGS__; }
int main(int argc, char *argv[]) {
char *num;
switch (argc - 1) {
case 0: num = "zero";
DBG( case 1: num = "one"; )
DBG( case 2: num = "two"; )
DBG( case 3: num = "three"; )
DBG( default: num = "many"; )
while (--argc)
printf("%s ", argv[argc]);
printf("\nArgument count: %s\n", num);
break;
}
return 0;
}
```
```shell
$ gcc -Wall -o test test.c
$ ./test 1 && ./test 1 2 && ./test 1 2 3 && ./test 1 2 3 4
1
Argument count: many
2 1
Argument count: many
3 2 1
Argument count: many
4 3 2 1
Argument count: many
```
2. 若我們將第二行的 DEBUG 定義修改為以下:
```cpp=2
#define DEBUG 0
```
再來重新編譯與執行看看:
```shell
$ gcc -Wall -o test test.c
$ ./test 1 && ./test 1 2 && ./test 1 2 3 && ./test 1 2 3 4
1
Argument count: one
2 1
Argument count: two
3 2 1
Argument count: three
4 3 2 1
Argument count: many
```
:::warning
* 被一串 `if (0) { ... }` 包圍的 switch-case 竟然會被處理,而且 break 巧妙地伴隨每個敘述出現。
* 也就是說,原本的 `DBG( case 1: num = "one"; )`
相當於 `break; case 1: num = "one; break;` 的效力。
:::
:::success
【 [Clifford's Device](http://www.clifford.at/cfun/cliffdev/) 】
```cpp
if (0) { label: ... }
```
* 在普通的執行流程中,`if (0) { ... }` 包圍的陳述指令會被忽略
* 但倘若配合 goto 時 (本例是 switch-case,一個 C 語法的變形),就不是這麼一回事,翻譯成組合語言或機械碼時,其實是很清楚且常見的結構。
* 這樣的結構對於縮減煩冗的程式碼有些特別用途。上述程式碼有趣之處,就在於像 `DBG()` 這類的 macro 在前期開發階段通常被設定為 "`1`",在後期則會逐步取消偵錯 / 驗證的程式碼時,將 macro 改為 `if (0) { ... }` 型態,而使開發者誤踩到「未爆彈」。
:::
* 範例 :
```cpp
#include <stdio.h>
typedef enum tagCmd { cmd1, cmd2, cmd3 } Cmd;
void doCmd(Cmd cmd) {
switch (cmd) {
case cmd1:
printf("Cmd1\n");
break;
case cmd2:
printf("Cmd2\n");
break;
}
int main() {
doCmd(cmd1);
return 0;
}
```
用 gcc 編譯會出現以下警告:
```shell
$ gcc -Wall -Werror switch.c
switch.c: In function 'doCmd':
switch.c:5:5: error: enumeration value 'cmd3' not handled in switch [-Werror=switch]
```
如果補上 `if (0) { case cmd3: break; }` 則不會有任何警告。
* 在 OpenSSL 的程式碼中,有類似的用法:
```cpp
if (!ok) goto end;
if (0) {
end:
X509_get_pubkey_parameters(NULL, ctx->chain);
}
```
* 延伸閱讀:
* [Something You May Not Know About the Switch Statement in C/C++](https://www.codeproject.com/Articles/100473/Something-You-May-Not-Know-About-the-Switch-Statem)
* Switch -> 編譯器 做表格、查表格
* [How to Get Fired Using Switch Statements & Statement Expressions](http://blog.robertelder.org/switch-statements-statement-expressions/)
#### [Duff's Device](https://en.wikipedia.org/wiki/Duff%27s_device)
* 關於 [Duff's Device 的詳盡解釋](http://c-faq.com/misc/duffexpln.html)
* [冷知識:達夫裝置(Duff's Device)效率真的很高嗎?](https://iter01.com/514878.html)
* 在 Linux 核心一類的專案中,可見到 [Duff's Device](https://en.wikipedia.org/wiki/Duff%27s_device) 技巧的運用:
```cpp
void dsend(int count) {
if (!count)
return;
int n = (count + 7) / 8;
switch (count % 8) {
case 0:
do {
puts("case 0");
case 7:
puts("case 7");
case 6:
puts("case 6");
case 5:
puts("case 5");
case 4:
puts("case 4");
case 3:
puts("case 3");
case 2:
puts("case 2");
case 1:
puts("case 1");
} while (--n > 0);
}
}
```
#### co-routine 應用
* [Building Coroutines](https://www.csl.mtu.edu/cs4411.ck/www/NOTES/non-local-goto/coroutine.html)

* Donald E. Knuth 的經典著作《The Art of Computer Programming》
* 提到 coroutine 這個自 1960 年代即現身的多工實做技術,
* 原理相當單純,在多數的文獻中會以 "yield" 來闡述,但不免令人困惑。
* coroutine 的 "yield" 是屬於程式語言層面,透過特定技巧或機制,讓原本循序執行的陳述指令,得以做出交錯執行的結果,
* 而 multi-threading 的 "yield" 則偏重於系統層面 (如 CPU resource),
* 簡單來說,該如何一方面允許多 thread 交錯執行,又能適當規劃個別單元對系統資源的使用。
* 我們可試著在 Linux 上模擬一個 user-level thread system
以下是實做程式碼:
```cpp=
#include <stdio.h>
#include <unistd.h>
#define THREAD_INTERVAL 500
#define cr_start() \
static int __s = 0; \
switch (__s) { \
case 0:
#define cr_yield \
{ \
__s = __LINE__; \
usleep(THREAD_INTERVAL); \
return; \
case __LINE__:; \
}
#define cr_end() \
} \
__s = 0;
static int condition = 1;
static void user_thread_1() {
cr_start();
for (;;) {
/* do something */
printf("Run %s\n", __FUNCTION__);
cr_yield;
}
cr_end();
}
static void user_thread_2() {
cr_start();
for (;;) {
if (condition) {
/* do something conditional */
printf("Run %s - (1)\n", __FUNCTION__);
cr_yield;
}
/* do something */
printf("Run %s - (2)\n", __FUNCTION__);
condition = !condition;
cr_yield;
}
cr_end();
}
int main() {
for (;;) {
user_thread_1();
user_thread_2();
}
return 0;
}
```
```shell
$ ./user-thread
Run user_thread_1
Run user_thread_2 - (1)
Run user_thread_1
Run user_thread_2 - (2)
Run user_thread_1
Run user_thread_2 - (2)
Run user_thread_1
Run user_thread_2 - (1)
Run user_thread_1
Run user_thread_2 - (2)
Run user_thread_1
Run user_thread_2 - (2)
Run user_thread_1
Run user_thread_2 - (1)
...
```
* PuTTY 作者 Simon Tatham
[Coroutines in C](https://www.chiark.greenend.org.uk/~sgtatham/coroutines.html)
對應的 [ssh.c 程式碼](https://github.com/Yasushi/putty/blob/31a2ad775f393aad1c31a983b0baea205d48e219/ssh.c#L414)
* Run-length encoding
* 解碼 與 解析 交錯進行
* `crReturn()`
- [Protothreads](http://dunkels.com/adam/pt/): extremely lightweight stackless threads
http://www.dunkels.com/adam/
* 檔案 `lc-addrlabels.h`
```cpp
#define LC_RESUME(s) \
do { \
if (s != NULL) { \
goto *s; \
} \
} while(0)
...
#define LC_SET(s) \
do { \
LC_CONCAT(LC_LABEL, __LINE__): \
(s) = &&LC_CONCAT(LC_LABEL, __LINE__); \
} while(0)
```
Implementation of local continuations based on the "Labels as values" feature of gcc.
## [技巧篇](https://hackmd.io/@sysprog/c-trick?type=view)
#### 矩陣操作
```cpp=
typedef struct matrix_impl Matrix;
struct matrix_impl {
float values[4][4];
/* operations */
bool (*equal)(const Matrix, const Matrix);
Matrix (*mul)(const Matrix, const Matrix);
};
static Matrix mul(const Matrix a, const Matrix b) {
Matrix matrix = { .values = {
{ 0, 0, 0, 0, }, { 0, 0, 0, 0, },
{ 0, 0, 0, 0, }, { 0, 0, 0, 0, },
},
};
for (int i = 0; i < 4; i++)
for (int j = 0; j < 4; j++)
for (int k = 0; k < 4; k++)
matrix.values[i][j] += a.values[i][k] * b.values[k][j];
return matrix;
}
int main() {
Matrix m = {
.equal = equal,
.mul = mul,
.values = { ... },
};
Matrix o = { .mul = mul, };
o = o.mul(m, n);
```
* 好的封裝,能夠處理不同的內部資料表示法 (data structure) 和演算法 (algorithms),對外提供一致的介面
* Goal : 使 `#2` ~ `#21` 能放入 `*.h`
* `static`
```cpp
static Matrix mul(const Matrix a, const Matrix b) {
```
* 使 `mul()` 只在這一份檔案有效 ( 其他檔案可能也有 `mul()` )
* 避免 Linking 時 重複定義
* 只要特定實作存在獨立的 C 原始程式檔案中,就不會跟其他 compilation unit 定義的符號 (symbol) 有所影響,最終僅有 [API gateway](https://github.com/embedded2016/server-framework/blob/master/async.c#L258) 需要公開揭露
* `Matrix m`,可以很容易指定特定的方法 (method),藉由 ==[designated initializers](https://gcc.gnu.org/onlinedocs/gcc/Designated-Inits.html)==,在物件初始化的時候,就指定對應的實作,日後要變更 ([polymorphism](https://en.wikipedia.org/wiki/Polymorphism_(computer_science))) 也很方便
* [Why does C++11 not support designated initializer list as C99?](https://stackoverflow.com/questions/18731707/why-does-c11-not-support-designated-initializer-list-as-c99)
* 從 C99 (含) 以後,C 和 C++ 的發展就走向截然不同的路線。[Incompatibilities Between ISO C and ISO C++](http://david.tribble.com/text/cdiffs.htm)
:::info
:girl: ==[Prefer to return a value rather than modifying pointers](https://github.com/mcinglis/c-style#prefer-to-return-a-value-rather-than-modifying-pointers)==
:-1: unnecessary mutation (probably), and unsafe
```cpp
void drink_mix(Drink * const drink, Ingredient const ingr) {
assert(drink);
color_blend(&(drink->color), ingr.color);
drink->alcohol += ingr.alcohol;
}
```
* drink 的成員有被更動到,一番操作後,我們會不知道指標所指的位置是哪裡
:+1: immutability rocks, pure and safe functions everywhere
```cpp
Drink drink_mix(Drink const drink, Ingredient const ingr) {
return (Drink) {
.color = color_blend(drink.color, ingr.color),
.alcohol = drink.alcohol + ingr.alcohol
};
}
```
* C 語言 的 物件 有明確的空間,因此不用 `assert()` 檢查
:::
* 可以改進的地方:
1. Matrix 物件的 `values` 欄位仍需要公開,我們就無法隱藏實作時期究竟用 `float`, `double`, 甚至是其他自訂的資料表達方式 (如 [Fixed-point arithmetic](https://en.wikipedia.org/wiki/Fixed-point_arithmetic))
2. 天底下的矩陣運算當然不是只有 4x4,現有的程式碼缺乏彈性 (需要透過 malloc 來配置空間)
3. 如果物件配置的時候,沒有透過 [designated initializers](https://gcc.gnu.org/onlinedocs/gcc/Designated-Inits.html) 指定對應的方法,那麼後續執行 `m.mul()` 就注定會失敗
4. 如果 Matrix 物件本身已初始化,以乘法來說,我們期待`matrixA * matrixB`,對應程式碼為 `matO = matA.mul(matB)`,但在上述程式碼中,我們必須寫為 `Matrix o = m.mul(m, n)`,後者較不直覺
5. 延續 `2.`,如果初始化時配置記憶體,那要如何確保釋放物件時,相關的記憶體也會跟著釋放呢?若沒有充分處理,就會遇到 memory leaks
6. 初始化 Matrix 的各欄、各列的數值很不直覺,應該設計對應的巨集以化簡
7. 考慮到之後不同的矩陣運算可能會用 [plugin 的形式](http://eli.thegreenplace.net/2012/08/24/plugins-in-c) 載入到系統,現行封裝和 RTTI 不足
* 要考慮的議題非常多,可見 [Beautiful Native Libraries](http://lucumr.pocoo.org/2013/8/18/beautiful-native-libraries/)
* 延伸閱讀:
* 更多矩陣運算: [matrix.h](https://github.com/openvenues/libpostal/blob/master/src/matrix.h), [matrix.c](https://github.com/openvenues/libpostal/blob/v0.3.4/src/matrix.c)
* "Object-oriented design patterns in the kernel" 中文翻譯
* [Part 1](https://paper.dropbox.com/doc/Object-oriented-design-patterns-in-the-kernel-part-1-kkc4L7OdvowY07GTfaOWZ#:a2=1441167125), [Part 2](https://hackmd.io/AwdgpgxgTAHAnAVgLQDYBGCRICwDMDMyauwAJkpiBMHMGjBBCEA=)
#### 明確初始化特定結構的成員
* C99 給予我們頗多便利,比方說:
```cpp
const char *lookup[] = {
[0] = "Zero",
[1] = "One",
[4] = "Four"
};
assert(!strcasecmp(lookup[0], "ZERO"));
```
* 也可變化如下:
```cpp
enum cities { Taipei, Tainan, Taichung, }; // 最後的 , 可以方便擴充
int zipcode[] = {
[Taipei] = 100,
[Tainan] = 700,
[Taichung] = 400,
};
```
* [列舉 enum](https://openhome.cc/Gossip/CGossip/enum.html)
* [Initializing a heap-allocated structure in C](https://tia.mat.br/posts/2015/05/01/initializing_a_heap_allocated_structure_in_c.html)
* `malloc()` 初始化成自己想要的內容
```cpp
void *memdup(const void *src, size_t sz) {
void *mem = malloc(sz);
return mem ? memcpy(mem, src, sz) : NULL;
}
#define ALLOC_INIT(type, ...) \
(type *)memdup((type[]){ __VA_ARGS__ }, sizeof(type))
struct foobar *foobar = ALLOC_INIT(struct foobar, {
.field = value,
.other_field = other_value,
.yet_another_field = yet_another_value
});
```
#### 追蹤物件配置的記憶體
* 前述矩陣操作的程式,我們期望能導入下方這樣自動的處理方式:
```cpp
struct matrix { size_t rows, cols; int **data; };
struct matrix *matrix_new(size_t rows, size_t cols) {
struct matrix *m = ncalloc(sizeof(*m), NULL);
m->rows = rows; m->cols = cols;
m->data = ncalloc(rows * sizeof(*m->data), m);
for (size_t i = 0; i < rows; i++)
m->data[i] = nalloc(cols * sizeof(**m->data), m->data);
return m;
}
void matrix_delete(struct matrix *m) { nfree(m); }
```
* 其中 `nalloc` 和 `nfree` 是我們預期的自動管理機制,對應的實作可見 [nalloc](https://github.com/jserv/nalloc)
- [Dynamic Strings in C](http://locklessinc.com/articles/dynamic_cstrings/)
* C 語言: ==字串 = 陣列 = 一段連續的記憶體==,差別在結束的判定
* 字串:null character (`'\0'`)
* 陣列:事先配置好大小
* 延伸閱讀:
* [停止使用 strncpy 函數!](http://www.360doc.com/content/17/0503/10/33093582_650551725.shtml)
* [Handling out-of-memory conditions in C](http://eli.thegreenplace.net/2009/10/30/handling-out-of-memory-conditions-in-c)
#### Smart Pointer
* 假設指標所指向的內容已被釋放,若此時對指標 dereference,會出現錯誤
為避免這類事情,在 C++11 的 STL,針對使用需求的不同,提供了三種不同的 Smart Pointer
* unique_ptr
* shared_ptr
* weak_ptr
* [C++ 智慧型指標(Smart Pointer):自動管理與回收記憶體](https://msdn.microsoft.com/zh-tw/library/hh279674.aspx)
- [Implementing smart pointers for C](https://snai.pe/c/c-smart-pointers/)
* 原理:利用 GCC extension: [attribute cleanup](https://stackoverflow.com/questions/42025488/resource-acquisition-is-initialization-in-c-lang)
```cpp
#define autofree \
__attribute__((cleanup(free_stack)))
__attribute__ ((always_inline))
inline void free_stack(void *ptr) { free(*(void **) ptr); }
```
* 接著就可以這樣用:
```cpp
int main(void) {
autofree int *i = malloc(sizeof (int));
*i = 1;
return *i;
}
```
* [Smart pointers for the (GNU) C](https://github.com/Snaipe/libcsptr)
#### 不夠謹慎的 ARRAY_SIZE 巨集
* [Linux Kernel: ARRAY_SIZE()](https://frankchang0125.blogspot.tw/2012/10/linux-kernel-arraysize.html)
* 從 Linux 核心「提煉」出的 [array_size](http://ccodearchive.net/info/array_size.html)
#### [C99 Variable Length Arrays](https://msdn.microsoft.com/zh-tw/library/zb1574zs.aspx)
- 開發者可不用考慮去記憶體配置與釋放
* Visual C++ 目前不支援可變長度陣列
* Linux Kernel 不可使用
* 因為 VLA 是透過 alloc() 實作
* 會有安全問題
- 一個特例是 [Arrays of Length Zero](https://gcc.gnu.org/onlinedocs/gcc/Zero-Length.html),GNU C 支援,在 Linux 核心出現多次
* C90 和 C99 語意不同
```cpp
struct line {
int length;
char contents[0];
};
struct line *thisline = (struct line *)
malloc (sizeof (struct line) + this_length);
thisline->length = this_length;
```
* contents 可被擴充
#### 字串和數值轉換
* [Integer to string conversion](https://tia.mat.br/posts/2014/06/23/integer_to_string_conversion.html)
* [數值系統筆記](https://hackmd.io/GSuuqlufRHGzar6WEFFPPg)
* [qrintf](https://github.com/h2o/qrintf): [`sprintf`](http://tw.gitbook.net/c_standard_library/c_function_sprintf.html) accelerator ( 加速器 ) for GCC and Clang
#### `do { ... } while(0)` 巨集
* ==避開 dangling else==
* C語言規定,else 總是和它上面最近的一個 if 配對
* [ multi-line macro: do/while(0) vs scope block](https://stackoverflow.com/questions/1067226/c-multi-line-macro-do-while0-vs-scope-block)
* 要看 !!!
#### 計算時間不只在意精準度,還要知道特性
* 參照 [時間處理與 time 函式使用](https://hackmd.io/s/HkiJpDPtx) 和 [计算机系统中的时间](http://blog.haipo.me/?p=906)
* [High Resolution Timers](http://elinux.org/High_Resolution_Timers)
#### goto 使用的藝術
* goto 筆記
...未完 影片 2:31:24 ~ 2:42:28
#### 上面技巧的整合:高階的 C 語言「開發框架」: Cello
* [Cello](http://libcello.org/) 在 C 語言的基礎上,提供以下進階特徵:
* Generic Data Structures
* Polymorphic Functions
* Interfaces / Type Classes
* Constructors / Destructors
* Optional Garbage Collection
* Exceptions
* Reflection
#### 善用 GNU extension 的 [typeof](https://gcc.gnu.org/onlinedocs/gcc/Typeof.html)
* typeof 允許我們傳入一個變數,代表的會是該變數的型態。舉例來說:
```cpp
int a;
typeof(a) b = 10; // equals to "int b = 10;"
char s[6] = "Hello";
char *ch;
typeof(ch) k = s; // equals to "char *k = s;"
```
1. 以 max 巨集為例:
```cpp
#define max(a, b) \
{(typeof(a) _a = a; \
typeof(b) _b = b; \
_a > _b ? _a : _b;) \
}
```
至於為什麼我們需要將 max 的巨集寫成這樣的形式呢?為何不可簡單寫為 `#define max(a,b) (a > b ? a : b)` 呢?
這樣的寫法會導致 **double evaluation** 的問題,顧名思義就是會有某些東西被執行 (evaluate) 過兩次。
試想如下情況:
```cpp
#define max(a, b) (a > b ? a : b)
void doOneTime() { printf("called doOneTime!\n"); }
int f1() { doOneTime(); return 0; }
int f2() { doOneTime(); return 1; }
int result = max(f1(), f2());
```
實際執行後,我們會發現程式輸出竟有**3 次** `doOneTime` 函式,但在 `max` 的使用,我們只期待會呼叫 2 次?
這是因為在巨集展開後,原本 `max(f1(), f2())` 會被改成這樣的形式
```cpp
int result = (f1() > f2() ? f1() : f2());
```
為了避免這個問題,我們必須在巨集中先用變數把可能傳入的函式回傳值儲存下來,之後判斷就不要再使用一開始傳入的函式,而是是用後來宣告的回傳值變數。
2. 解釋以下巨集的原理
```cpp
#define container_of(ptr, type, member) \
__extension__({ \
const __typeof__(((type *) 0)->member) *__pmember = (ptr); \
(type *) ((char *) __pmember - offsetof(type, member)); \
})
```
* 首先看到的是 `__extension__`,是一個修飾字,用來防止 gcc 編譯器產生警告。
* 在編譯階段,編譯器可能會提醒我們,程式使用到非 ANSI C 標準的語句,我們開發的程式在現在的編譯器可能可以過,但是用其他的編譯器可能就不會過了。
* 出問題的地方應該是在開頭的 `({})`(braced-group within expression)
* 實際編譯過後我們可以看到這樣的警告訊息
```shell
warning: ISO C forbids braced-groups within expressions [-Wpedantic]
```
* 這是 gcc 一個 extension,透過這種寫法可以讓我們的 macro 更**安全**。
* 如果不想要看見這個警告,可在最前面加上 `__extension__` 修飾字。
* 再來的話看到 `__typeof__(((type *) 0)->member) * __pmember`
* 可以看到我們用 `((type*)0)->member` 的型態再宣告一個新的指標 `__pmember`
* `(type*)0` 代表的是一個被轉型成 `type` 型態的 struct,再來我們讓他指向 `member`
* 這裡我們不用理會是否為一個合法的位址,所以可以直接寫 `0` 就好
* `__typeof__(((type*)0)->member)` 代表的便是 `member` 的資料型態
* 再往下看到 `(type *) ((char *) __pmember - offsetof(type, member));`
* 把 member 的位址扣除 member 在整個 struct 裡面的偏移後,得到整個 struct 的開頭位址

#### Block
* 巨集限制很多,因為本質是「展開」,這會導致多次的 evalution
1. 考慮以下程式碼:
```cpp
#define DOUBLE(a) ((a) + (a))
int foo() {
printf(__func__);
return 3;
}
int main () {
DOUBLE(foo()); /* 呼叫 2 次 foo() */
}
```
為此,我們可以使用區域變數,搭配 GNU extension `__typeof__`,改寫上述巨集:
```cpp
#define DOUBLE(a) ({ \
__typeof__(a) _x_in_DOUBLE = (a); \
_x_in_DOUBLE + _x_in_DOUBLE; \
})
```
* 為什麼有 `_x_in_DOUBLE` 這麼不直覺的命名呢?
* 因為如果 `a` 的表示式中恰好存在與上述的區域變數同名的變數,那麼就會發生悲劇。
* 如果你的編譯器支援 [Block](https://en.wikipedia.org/wiki/Blocks_(C_language_extension)),比方說 clang,就可改寫為:
```cpp
#define DOUBLE(a) \
(^(__typeof__(a) x){ return x + x; }(a))
```
:::info
* Block in C uses a lambda expression-like syntax to create closures.
* 在 clang 使用時,要加上 `-fblocks` 編譯選項
:::
#### Linked List 的各式變種 ( Compound literals )
* [[心得] Compound literals, flexible array members](https://www.ptt.cc/man/C_and_CPP/DB9B/DC33/M.1271034153.A.7F9.html)
1. 考慮以下實作:
```cpp
#include <stdio.h>
#define cons(x, y) (struct llist[]){x, y}
struct llist { int val; struct llist *next; };
int main() {
struct llist *list = cons(9, cons(5, cons(4, cons(7, NULL))));
struct llist *p = list;
for (; p; p = p->next)
printf("%d", p->val);
printf("\n");
return 0;
}
```
* 以下分析其原理:
```cpp
#define cons(x, y) (struct llist[]){x, y}
```
* 利用 ==compound literal== 建立 static linked list
* 可針對未知大小的 array/struct 初始化,也可以直接對特定位置的 array 或 struct 的內容賦值
* compound literal 可以做 lvalue ,可以傳特定型別或自己定義的 struct
* 將上述程式碼的 `cons(9, cons(5, cons(4, cons(7, NULL))))` 展開如下:
```cpp
// 展開 cons(9, cons(5, cons(4, cons(7, NULL))))
llist.val = 9;
llist.next = &cons(5, cons(4, cons(7, NULL)));
// 展開 cons(5, cons(4, cons(7, NULL)))
llist.val = 5;
llist.next = &cons(4, cons(7, NULL))
// 展開 cons(4, cons(7, NULL))
llist.val = 4;
llist.next = &cons(7, NULL);
//展開 cons(7, NULL)
llist.val = 7;
llist.next = NULL;
```
便會得到如下的 linked list
```
+------+------+ +------+------+ +------+------+ +------+------+
| | | | | | | | | | | |
| 9 | next +---->| 5 | next +---->| 4 | next +---->| 7 | NULL |
| | | | | | | | | | | |
+------+------+ +------+------+ +------+------+ +------+------+
^
|
head
```
從 `cons(7, NULL)` 往外面拆開會比較容易理解指標的方向。因此最終程式輸出結果會是 `9547`
* 延伸閱讀:
* [Doubly Linked Lists in C](http://locklessinc.com/articles/dlist/)
* [linked list 和非連續記憶體操作](https://hackmd.io/@sysprog/SkE33UTHf)
#### 充分掌握執行時期的機制
* [oomalloc](https://github.com/dextero/oomalloc): A library meant for testing application behavior in out-of-memory conditions with the use of LD_PRELOAD trick
* 延伸閱讀:
* [動態連結器](https://hackmd.io/@sysprog/HkK7Uf4Ml)
* [連結器和執行檔資訊](https://hackmd.io/@sysprog/SysiUkgUV)
* [執行階段程式庫 (CRT)](https://hackmd.io/@sysprog/Hkcr5cn97)