# sqlalchemy
[](https://hackmd.io/@RogelioKG/sqlalchemy)
## References
+ 📄 [**SQLAlchemy - Unified Tutorial**](https://docs.sqlalchemy.org/en/20/tutorial/index.html)
+ 📄 [**SQLAlchemy - Using session**](https://docs.sqlalchemy.org/en/20/orm/session.html)
+ 💬 [**Reddit - Is it just me or are the docs for sqlalchemy a f*cking nightmare?**](https://www.reddit.com/r/Python/comments/12xrvwz/is_it_just_me_or_are_the_docs_for_sqlalchemy_a/)
## Controversy
### pros
+ Python 原生環境的支持
+ 型別、屬性提示
+ column 由屬性控制,若想改名可藉由 IDE 批量更改名稱
+ 生產力的提升
+ 更安全
+ 若使用 SQL,必須時時刻刻明白自己在做甚麼,且絕不犯錯
### cons
+ 性能開銷
+ 在執行期引入抽象層
+ 同一件事有太多種做法
+ 違反 Zen of Python:[*There should be one obvious way to do it.*](https://zen-of-python.info/there-should-be-one-and-preferably-only-one-obvious-way-to-do-it.html#13)
+ 文檔混亂
+ 筆者只推薦看 [References](#References) 列出的那兩篇文檔📄 (重點部分)
### well...
+ 替代品 (待觀察 👀)
+ [peewee](https://github.com/coleifer/peewee)
+ [sqlmodel](https://github.com/coleifer/peewee) (fastapi 自家)
## Nouns
### DB-API
[DB-API 2.0 (PEP 249) ](https://peps.python.org/pep-0249/)
Python 中存取資料庫的標準介面。\
經典方法 `close()` / `commit()` / `rollback()` / `cursor()` 的行為規範就是從這裡來的。
### ORM
[物件關係對映 (Object Relational Mapping)](https://www.explainthis.io/zh-hant/swe/orm-intro)
即開發者可通過操作類別與實例,來對資料庫進行 CRUD 等操作,\
而不必直接去操作 SQL 語句。
1. 將<span style="color: cornflowerblue">表格 (table)</span> 映射為<span style="color: firebrick">類別 (class)</span>
2. 將<span style="color: cornflowerblue">欄位 (column)</span> 映射為<span style="color: firebrick">屬性 (attribute)</span>
3. 將<span style="color: cornflowerblue">記錄 (record)</span> 映射為<span style="color: firebrick">實例 (instance)</span>
### ORM object
```py
# ORM 類別 (ORM class)
class Employee(Base):
__tablename__ = "employee"
id: Mapped[int] = mapped_column(primary_key=True, autoincrement=True)
emp_name: Mapped[str] = mapped_column(String(20), index=True)
birth_date: Mapped[date] = mapped_column(Date)
sex: Mapped[str] = mapped_column(String(1))
salary: Mapped[int] = mapped_column(Integer, CheckConstraint("salary >= 0"))
branch_id: Mapped[int] = mapped_column(ForeignKey("branch.id"), nullable=False)
```
```py
# ORM 實例 (ORM object)
Employee(
emp_name="RogelioKG",
birth_date=datetime(2002, 8, 13),
sex="M",
salary=0,
branch_id=1,
),
```
### Transaction
+ <mark>資料庫執行過程中的一個「邏輯單位」</mark>
+ 可以想像成<mark>一筆交易,其中所有操作應具有原子性</mark>
+ 所有操作要嘛全執行 ([commit](#commit))、要嘛因中途失誤而全倒帶 ([rollback](#rollback)),不能只做一半
+ 就比如訂單系統:使用者錢包扣款 -> 訂單新增
+ 結果扣款了但訂單新增失誤,等同沒下單
+ 此時就要一併倒帶使用者錢包扣款的動作才行
## Session
### what is session?
+ session 物件負責管理 <mark>ORM 實例與資料庫的交流</mark>
+ 快取 <mark>identity map</mark>
+ session 內部維護一個資料結構,你可以理解成快取
+ identity map 是一個 <mark>weakref value 字典</mark>
+ key: `(ORM class, primary_key)`
+ value: `ORM object` (weakref)
+ <mark>session 藉由這個字典,紀錄它找過的所有資料</mark>
+ query 資料
+ 使用 `primary_key`:會先去 identity map 找,找不到才會去資料庫找
+ 使用非 `primary_key`:直接去資料庫找
+ 無論如何,找到的資料都會紀錄回 identity map 中
```py
u1 = session.get(User, 5)
u2 = session.get(User, 5)
assert u1 is u2
```
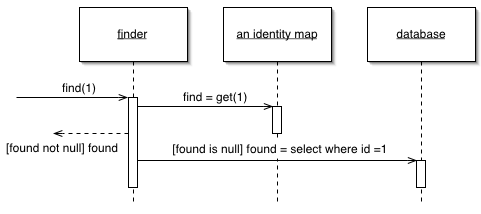
### `add()` / `add_all()`
+ <mark>這是 session 的變更</mark>
+ session 將指定 ORM 實例標記為新增狀態
+ 等到此變更被寫進資料庫 (比如 `flush`),才會出現在 identity map
### `delete()`
+ <mark>這是 session 的變更</mark>
+ session 將指定 ORM 實例標記為刪除狀態
+ 等到此變更被寫進資料庫 (比如 `flush`),才會出現在 identity map
### `get()`
+ 先去 identity map 找資料,找不到再去資料庫 query 資料
### `execute()`
+ 直接去資料庫 query 資料
+ 搭配 [2.0-style query](#20-style-query) 寫法或 [`text()`](#text) 寫法
### `flush()`
+ 將 session 的變更「暫時」寫回資料庫
+ 每當對資料庫發起 query 之前,自動執行一次
+ 不一定,此操作取決於 [sessionmaker](#sessionmaker) 的 `autoflush` 選項
### `expire()`
+ 讓指定的 ORM 實例過期 (清空它的所有屬性)
+ 等到下次你要存取這個屬性時,再去資料庫 query 一遍
```py
session.expire(u1)
u1.some_attribute # <-- lazy loads from the transaction
```
### `refresh()`
+ 讓指定的 ORM 實例[過期](#expire)
+ 然後立即向資料庫 query 一遍,補足所有屬性
```py
session.refresh(u1) # <-- emits a SQL query
u1.some_attribute # <-- is refreshed from the transaction
```
### `commit()`
+ 先 `flush()` 所有 session 的變更
+ 接著 session 中的所有 ORM 實例通通[過期](#expire)
+ 不一定,此操作取決於 [sessionmaker](#sessionmakr) 的 `expire_on_commit` 選項
+ 一次 transaction 完成
### `rollback()`
+ 本次 transaction 中,所有對資料庫的變更全部取消 (包含 `flush()` 的部分)
+ 一次 transaction 完成
### `begin()`
+ 自動管理 `rollback()` 與 `commit()`
+ style: <mark>commit as you go</mark>
```py
with Session(engine) as session:
try:
session.add(some_object)
session.add(some_other_object)
except:
session.rollback()
raise
else:
session.commit()
```
+ style: <mark>begin once</mark>
```py
# ✅ 此處開始一個 connection (lazy)
with Session(engine) as session:
# ✅ 此處開始一個 transaction
with session.begin():
session.add(some_object)
session.add(some_other_object)
# 🟧 此處結束一個 transaction
# 🟧 此處結束一個 connection
```
+ 這裡多補充一些關係,可看清它們背後管理的邏輯
```py
# Note:Session(engine) 回傳 session
# 其 __enter__() 回傳自身 (session)
with Session(engine) as session:
# Note:session.begin() 回傳 SessionTransaction(session)
# 其 __enter__() 回傳自身 (session_transaction)
with session.begin():
session.add(some_object)
session.add(some_other_object)
# session.commit() or session.rollback()
# session.close()
```
### `begin_nested()`
+ 即 SQL 中 `SAVEPOINT`:在 transaction 中還有個 nested transaction
+ 一旦發生 `rollback()`,只會回滾 nested transaction 的操作,不會回滾整個 transaction 的操作
```py
Session = sessionmaker()
with Session.begin() as session:
session.add(u1)
session.add(u2)
nested = session.begin_nested() # establish a savepoint
session.add(u3)
nested.rollback() # rolls back u3, keeps u1 and u2
# commits u1 and u2
```
### `expunge()`
+ 自 session 的 identity map 中移除指定的 ORM 實例 (這筆資料不想讓 session 管理了)
+ 此時 ORM 實例處於 detach 狀態
### `close()`
+ session 將 connection 歸還給 engine 的 connection pool
### `sessionmaker()`
+ `autoflush` (預設 True)
+ 說明
+ 每當對資料庫發起 query 之前,自動執行一次 `flush()` ([unit of work pattern](https://docs.sqlalchemy.org/en/20/glossary.html#term-unit-of-work))
+ <mark>常設定為:True</mark>。原因:
+ 不這麼做的話,資料庫與 ORM 實例容易產生不一致
+ `expire_on_commit` (預設 True)
+ 說明
+ `commit()` 後 session 中的所有 ORM 實例通通過期
+ <mark>常設定為:False</mark>。原因:
+ 若在結束 session 後還要用到這些資料,這會是非常重要的優化
+ 我們選擇 `False`
+ 若你的 ORM 實例在塞進資料庫時,有產生新的欄位,請記得手動 `refresh()`
### example
+ sync
```py
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from config import get_settings
from models.base import Base
from models.item import Item
from models.user import User
engine = create_engine(get_settings().database_uri)
SessionLocal = sessionmaker(bind=engine, expire_on_commit=False)
def get_session():
session = SessionLocal()
try:
yield session
finally:
session.close()
def init_db():
Base.metadata.create_all(bind=engine, tables=[User.__table__, Item.__table__])
```
```py
session = database.get_session()
user = User(...)
session.add(user)
session.commit()
```
+ async
```py
from contextlib import asynccontextmanager
from sqlalchemy.ext.asyncio import async_sessionmaker, create_async_engine
from app.settings import get_settings
from app.table import Base
engine = create_async_engine(get_settings().SQLALCHEMY_DATABASE_URI, echo=True)
AsyncSessionLocal = async_sessionmaker(bind=engine, expire_on_commit=False)
@asynccontextmanager
async def get_session():
async with AsyncSessionLocal() as session:
async with session.begin():
yield session
async def init_db():
async with engine.begin() as conn:
await conn.run_sync(Base.metadata.create_all)
async def drop_db():
async with engine.begin() as conn:
await conn.run_sync(Base.metadata.drop_all)
async def close_db():
await engine.dispose()
```
```py
async with database.get_session() as session:
user = User(...)
session.add(user)
```
## function
### `create_engine()`
```py
engine = create_engine(
get_settings().database_uri,
# connection pool 的 connection 數量 (預設 5)
pool_size=100,
# 容許多出的 connection 數量 (預設 10)
max_overflow=100,
# 當 connection pool 沒有 connection 時,願意等多久來拿 connection (預設 30)
pool_timeout=15,
# 當一條 connection 存在超過幾秒時,主動關掉並分配一條新連線 (預設 -1)
pool_recycle=1800,
)
```
### `text()`
+ 直接執行 SQL
```py
from sqlalchemy import text
t = text("SELECT * FROM users")
result = connection.execute(t)
```
## 2.0-style query
### result
+ `scalars()`
> 返回多個結果
+ `first()`:取第一個
+ `all()`:取每個
+ `one()`:取一個,斷言僅一個
+ `scalar()`
> 返回單一結果
### `select()` / `where()`
```py
stmt = select(User).where(User.name == "Alice")
result = await session.execute(stmt)
user = result.scalars().first()
```
### `insert()` / `update()` / `delete()`
```py
from sqlalchemy import insert, update, delete
# 新增
stmt = insert(User).values(name="Alice", email="a@example.com")
await session.execute(stmt)
await session.commit()
# 更新
stmt = update(User).where(User.id == 1).values(name="Updated Name")
await session.execute(stmt)
await session.commit()
# 刪除
stmt = delete(User).where(User.id == 1)
await session.execute(stmt)
await session.commit()
```
### `and_()`
```py
stmt = select(User).where(
and_(
User.age >= 18,
User.email.like("%@gmail.com")
)
)
result = await session.execute(stmt)
users = result.scalars().all()
```
### `in()`
```py
stmt = select(User).where(User.id.in_([1, 2, 3]))
```
### `order_by()`
```py
stmt = select(User).order_by(User.created_at.desc())
```
### `join`
```py
stmt = select(User, Address).join(Address).where(User.id == Address.user_id)
result = await session.execute(stmt)
rows = result.all() # 回傳 list[tuple(User, Address)]
```
### `offset()` / `limit()`
```py
stmt = select(User).offset(10).limit(20) # 跳過 10 筆,取 20 筆
```
## Cool
+ [enable_repr](https://hackmd.io/@RogelioKG/typing#overload-函數多載)
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet