---
layout: default
title: RISC-V Business Part 2
author: Ramshreyas Rao
---
# RISC-V Business part 2: The Road to Real-time Proving

[Image by Somesh](https://www.deviantart.com/somesh7322/art/00009-969351387-0000-1012953609)
In [Part 1](https://hackmd.io/zl82XRhXQYuVB84GEZmBJg) of this series, we explored at a high level how the adoption of RISC-V as an open standard is likely to be the foundation on which the [programmable cryptography](https://0xparc.org/blog/programmable-cryptography-1) future of Ethereum will be built, using [Glue and Coprocessor architectures](https://vitalik.eth.limo/images/gluecp/BJdoaxqo0.png). We then used Risc0's VM to 'host' a simple piece of external code, executed it, and then produced a proof that it was executed correctly, to get a concrete, albeit simple caricature of this paradigm.
In Part 2, we will dive deeper first with an overview of [the recently launched ETHProofs.org](https://ethproofs.org), followed by an in depth examination of how we can achieve real-time proving in the execution layer by looking at the anatomy of an Ethereum State Transition, identifying which steps can be 'coprocessed', and finally addressing how the proving of the entire execution trace can itself be sped up.
Once we have the lay of the land, we can proceed to lay out the road to real time proving and discuss how RISC-V can help get us there.
*If you're interested in articles like this, consider subscribing to [our Substack, 0xFutures](https://0xfutures.substack.com)*
---
### The 'ZK' Schelling point with Ethproofs.org
> Ethproofs is a block proof explorer for Ethereum. It aggregates data from various zkVM teams to provide a comprehensive overview of proven blocks, including key metrics such as cost, latency, and proving time.
>
> Users can compare proofs by block, download them, and explore various proof metadata(size, clock cycle, type) to better understand the individual zkVMs and its proof generation process.
Ethproofs aggregates the proving time for multiple proof providers (currently [Snarkify](https://ethproofs.org/prover/1a13f366-1a1a-455e-8d82-9516b32dda75), [Succinct](https://ethproofs.org/prover/789bd1d9-158a-4dc7-bb9e-e0f12efda0d1) and [ZKM](https://ethproofs.org/prover/00a4d8ed-9272-42f8-a716-af1eead50de9)) and reports on all their performance parameters, highlighting the best one. The proofs for each can even be downloaded and verified by anyone. These provers are being run as single AWS instances in comparable and non-optimized deployments for all providers purely for the purposes of benchmarking and comparison - so only one out of every hundred Ethereum blocks is being tested currently.
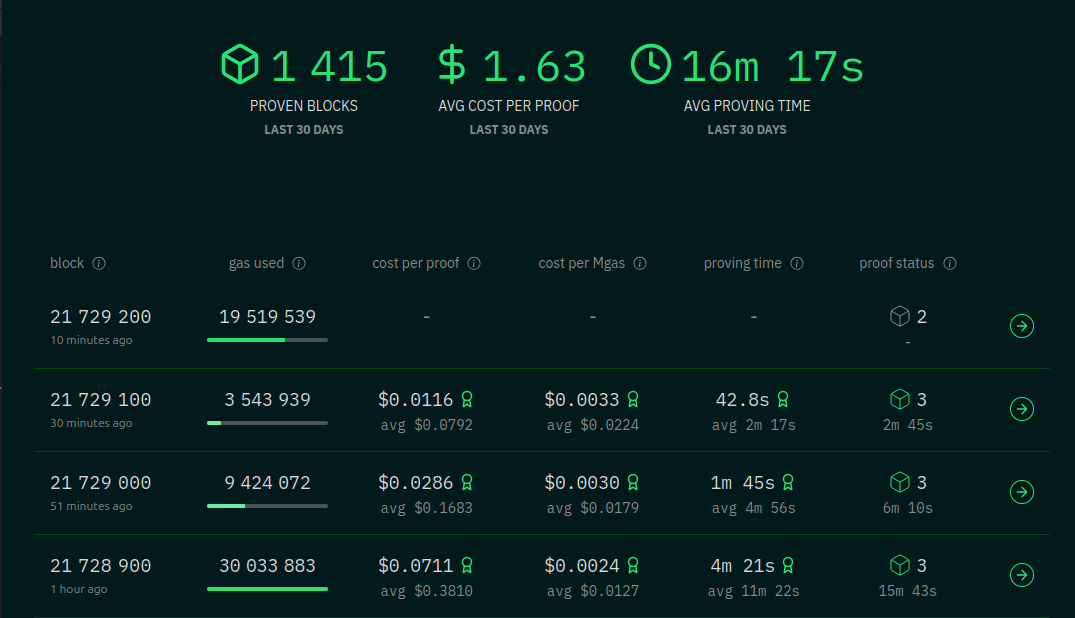
In the image above from the landing page of the website, for each block that is proven, we can see multiple metrics:
1. **Gas used**: This is the total gas that was executed in that particular block, and is a proxy for the computational effort required to execute said block, and therefore the effort required to prove it. The bar gives an indication of its proportion of the total gas limit per block.
2. **Cost per proof**: This is an AWS-equivalent, hourly US dollar price estimate for the cost of producing the proof using hardware most similar to that being used by competing provers. The numbers for the best are shown with the average displayed below.
3. **Cost per Mgas**: This is a US dollar estimate of the cost of proving 1 Mgas worth of compute, using the two estimates above.
4. **Proving time**: The time taken to produce the proof of the given block.
5. **Proof status**: How many of the provers successfully completed the proof, are in progress, or are in queue to begin proving.
To understand this better, let us identify a block with almost complete gas limit utilization - [21728900](https://etherscan.io/block/21728900) (which will be buried in the history when you read this) and dig deeper on [Ethproofs.org](https://ethproofs.org/block/21728900) to get a sense of what the current state of the art (at the time of writing) is for block proving:
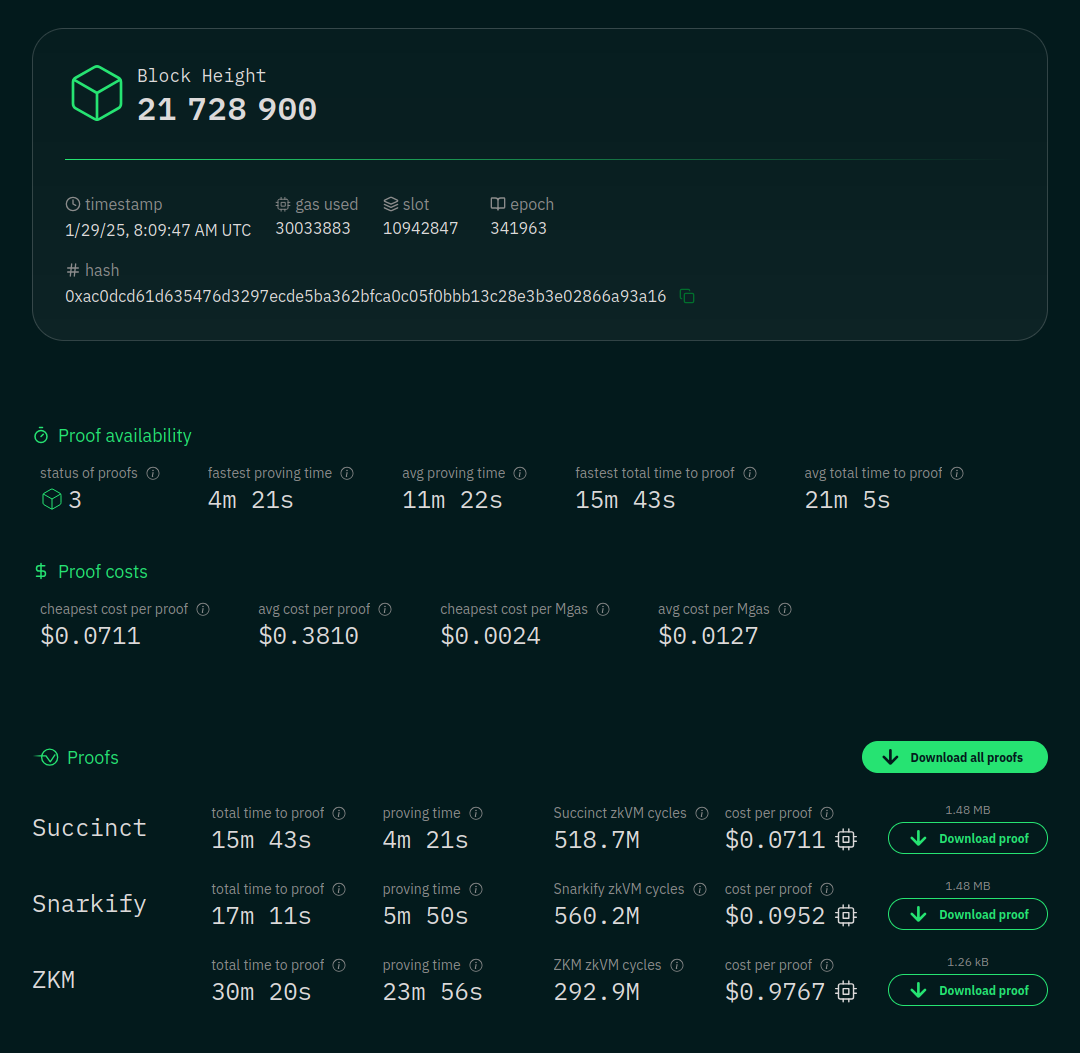
These are the performance figures for each prover on block 21728900. As we can see, Succinct was the fastest at ~15 mins, and also the cheapest at ~7 cents an hour. Of course we must remember these are just unoptimized single-aws-instance deployments that are meant for comparisons - provers in production can use many kinds of optimizations and accelerations to deliver much faster proving times. The purpose of this is to establish the performance of 'raw' software, without any other confounders. As you can see in the last column of the table, we can also download the proof of the validity of the block and verify it.
[Ethproofs.org](https://ethprooks.org) is a public good creating a Schelling point around the performance proving of zkEVMs. Companies like Succinct, Snarkify and ZKM stand to gain tremendously by topping this leaderboard, and the competition is just heating up - moving the entire space of zk proving forward in true Ethereum fashion.
So the race to achieve real-time proving is off to a great start. And clearly, proving is not commoditized yet, with zkVM companies already developing their own optimizations and acceleration technologies to keep pushing the performance frontier. But what exactly are they doing? How does one get from the current state of the art to real-time proving?
To get a better sense of that, let's dissect an Ethereum State Transition (Execution Layer only), and look at how a proof is generated for a valid transition.
---
### 👋👋👋 Hand-wavy anatomy of proving the validity of an Ethereum block 👋👋👋
.png?table=block&id=5aeb1325-0fa7-4865-930a-9a2592330e41&cache=v2)
[From risc0's blog - Designing High-performance zkVMs](https://risczero.com/blog/designing-high-performance-zkVMs)
**First,** let's back up a bit and review what we learnt in [Part 1](https://hackmd.io/zl82XRhXQYuVB84GEZmBJg). In this paradigm, we pass 'guest' code and inputs into a 'host' (the zkVM above), which then executes and produces the results along with a proof of the validity of said execution. So in the Ethereum context:
- The 'guest' code - ('Program' in the image above) is basically an EVM/STF
- The 'program inputs' are all the transactions included in the block, and the previous block state.
- The 'host' uses these inputs to execute the EVM State Transition Function (STF)
- The 'host' then produces the 'output' (a new block), along with a proof of valid execution
**Second,** let us remember:
### 🍼 Glue and Coprocessor Architectures ⚙️
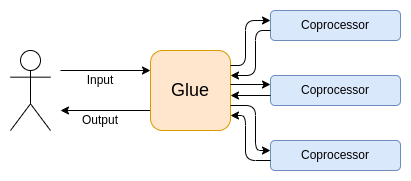
*[Diagram from 'Glue and coprocessor architectures'](https://vitalik.eth.limo/images/gluecp/BJdoaxqo0.png)*
As discussed in [Part 1](https://hackmd.io/zl82XRhXQYuVB84GEZmBJg) we have the rising paradigm of (complex, but not computationally expensive) glue code that calls (highly structured, but computationally expensive) coprocessor code that can be run in a more optimized environment.
**Let's slice and dice the (pre-PECTRA) Ethereum State Transition Function (STF) into glue and coprocessor buckets:**
This is what the STF looks like in [the python spec on the ethereum github repo](https://github.com/ethereum/execution-specs/blob/master/src/ethereum/cancun/fork.py):
```python
def state_transition(chain: BlockChain, block: Block) -> None:
"""
Attempts to apply a block to an existing block chain.
All parts of the block's contents need to be verified before being added
to the chain. Blocks are verified by ensuring that the contents of the
block make logical sense with the contents of the parent block. The
information in the block's header must also match the corresponding
information in the block.
To implement Ethereum, in theory clients are only required to store the
most recent 255 blocks of the chain since as far as execution is
concerned, only those blocks are accessed. Practically, however, clients
should store more blocks to handle reorgs.
Parameters
----------
chain :
History and current state.
block :
Block to apply to `chain`.
"""
parent_header = chain.blocks[-1].header
excess_blob_gas = calculate_excess_blob_gas(parent_header)
if block.header.excess_blob_gas != excess_blob_gas:
raise InvalidBlock
validate_header(block.header, parent_header)
if block.ommers != ():
raise InvalidBlock
apply_body_output = apply_body(
chain.state,
get_last_256_block_hashes(chain),
block.header.coinbase,
block.header.number,
block.header.base_fee_per_gas,
block.header.gas_limit,
block.header.timestamp,
block.header.prev_randao,
block.transactions,
chain.chain_id,
block.withdrawals,
block.header.parent_beacon_block_root,
excess_blob_gas,
)
if apply_body_output.block_gas_used != block.header.gas_used:
raise InvalidBlock(
f"{apply_body_output.block_gas_used} != {block.header.gas_used}"
)
if apply_body_output.transactions_root != block.header.transactions_root:
raise InvalidBlock
if apply_body_output.state_root != block.header.state_root:
raise InvalidBlock
if apply_body_output.receipt_root != block.header.receipt_root:
raise InvalidBlock
if apply_body_output.block_logs_bloom != block.header.bloom:
raise InvalidBlock
if apply_body_output.withdrawals_root != block.header.withdrawals_root:
raise InvalidBlock
if apply_body_output.blob_gas_used != block.header.blob_gas_used:
raise InvalidBlock
chain.blocks.append(block)
if len(chain.blocks) > 255:
# Real clients have to store more blocks to deal with reorgs, but the
# protocol only requires the last 255
chain.blocks = chain.blocks[-255:]
```
Let's break it down:
1. Retrieve Parent Header
- Obtain the header from the chain’s last block (the parent).
- Reference: `parent_header = chain.blocks[-1].header`
Glue — Simple pointer-based retrieval; no heavy computation.
2. Excess Blob Gas Calculation
- Compute `excess_blob_gas` based on the parent block’s header.
- Reference: `excess_blob_gas = calculate_excess_blob_gas(parent_header)`
Glue — Straightforward arithmetic, minimal overhead.
3. Validate Excess Blob Gas
- Compare the computed value with the current block’s `excess_blob_gas` header field.
- Reference: `if block.header.excess_blob_gas != excess_blob_gas: raise InvalidBlock`
Glue — A condition check to raise `InvalidBlock` if mismatched.
4. Header Validation
- Confirm the block header is valid (base fee logic, gas usage, timestamps, etc.).
- Reference: `validate_header(block.header, parent_header)`
Glue — Multiple logical checks and small arithmetic; no major cryptographic operations.
5. Ommers/Uncles Check
- Ensure the `ommers` field is empty (no uncles).
- Reference: `if block.ommers != (): raise InvalidBlock`
Glue — Another conditional check, minimal overhead.
6. Apply Body
- Execute all transactions and withdrawals in the block, producing:
- Gas used
- Updated tries (transactions, receipts, withdrawals)
- Logs bloom
- Final state root
- Blob gas usage
- Reference: `apply_body(...)`
Mixed (Glue + Coprocessor) — The orchestration (transaction loop, environment setup) is Glue,
but inside you have cryptographic checks (signatures, hashing) that can be Coprocessor-heavy.
7. Verify Execution Outputs
- Compare outputs from `apply_body` (gas used, state root, etc.) to corresponding fields in the block header.
- Reference (example):
if apply_body_output.block_gas_used != block.header.gas_used: raise InvalidBlock
if apply_body_output.state_root != block.header.state_root: raise InvalidBlock
...
Glue — Simple comparisons to ensure consistency.
8. Append Block
- Add the new block to the chain if all checks pass.
- Reference: `chain.blocks.append(block)`
Glue — Pointer/index updates, minimal overhead.
9. Prune Old Blocks
- Keep only the last 255 blocks in `chain.blocks` (minimal protocol requirement).
- Reference:
if len(chain.blocks) > 255:
chain.blocks = chain.blocks[-255:]
Glue — Removing old entries, again mostly logic.
10. Error Handling
- Raise `InvalidBlock` if any step fails; otherwise, return successfully.
- Reference: Throughout validation checks (e.g., `raise InvalidBlock`).
Glue — Control flow for invalid conditions, no heavy math.
As we can see the only **Coprocessor-heavy** code is in step 7 - 'Apply Body'. Let's zoom into this and understand exactly how we can speed up this process using 'coprocessors':
1. System Transaction Setup
- Construct and execute a “system transaction” (e.g., updating beacon roots) using special addresses or code.
Potential Coprocessor Acceleration: If the system transaction requires hashing, signature checks,
or heavy math, offload to coprocessor.
2. Initialize Block Structures
- Create empty tries for transactions, receipts, withdrawals.
- Track block-level data like `gas_available`, `blob_gas_used`, and `block_logs`.
Potential Coprocessor Acceleration: Tries typically involve hashing (Merkle, Patricia, or Verkle tries).
Bulk hashing can be speeded up.
3. Transaction Loop
- For each transaction:
1. Store Transaction in the transaction trie (RLP-encoded).
2. Check Transaction with `check_transaction(...)` (nonce, gas limit, ECDSA signature, etc.).
3. Execute EVM (`process_transaction(...)`), which does gas accounting, runs opcodes,
updates state, produces logs.
4. Record Receipts in the receipts trie.
Potential Coprocessor Acceleration:
- Signature checks
- Hashing for RLP data and trie updates
- Big-integer ops for BN256 or other precompile calls
4. Apply Withdrawals
- Process each withdrawal (e.g., validator withdrawals), updating state and a separate trie.
Potential Coprocessor Acceleration: Hashing for updating the withdrawals trie
5. Finalize and Construct Output
- Calculate final block gas usage (`block_gas_used`), logs bloom filter, state root,
and the transaction/receipt/withdrawal trie roots.
- Return an `ApplyBodyOutput` struct with the aggregated results.
Potential Coprocessor Acceleration:
- Logs Bloom (bitwise ops over large data sets)
- Trie Root Hashing
As we can see, there are a series of signature checks and hashing functions in multiple places. So the first step would be to accelerate the sorts of operations.
**Accelerating Execution**
There are largely two ways to speed up the code in the coprocessor buckets. Precompiles in Ethereum act like built-in contracts that handle heavy-lift operations in a more optimized way than raw EVM bytecode. For example, cryptographic primitives such as [BLS12-381 curve operations](https://eips.ethereum.org/EIPS/eip-2537) can be invoked via these precompile addresses. At the protocol level, this cuts down on the large number of instructions a normal contract would need to perform these operations. Conceptually, these precompiles are a software-level “coprocessor”—the EVM recognizes them as special addresses that execute native code, returning results at a fraction of the gas cost and time it would otherwise require.
Pushing this idea further, one can imagine hardware acceleration of these same precompile tasks—particularly under RISC-V extensions—where specialized instructions handle elliptic-curve arithmetic, large integer math, or hashing at the hardware layer. Instead of funneling big cryptographic workloads through general-purpose CPU instructions, these expansions let you run them on dedicated circuits or co-processors optimized for parallel computation and low-latency arithmetic.
**Accelerating *Proving***
But remember - our task is not just to execute the block efficiently, we now want to run the whole STF inside a zkVM, *and then produce a proof for the validity of the execution*. In this scenario, each step of block validation—header checks, transaction execution, Merkle trie updates—generates a cryptographic proof that every operation was carried out correctly, without needing a third party to re-run the computations. Because the zkVM must handle voluminous cryptographic operations (especially if it’s proving large arithmetic or hashing circuits), specialized RISC-V extensions become even more valuable here:
1. **Reducing the Arithmetic Bloat**
- zk proofs are largely about proving that every arithmetic operation (e.g., hashing, big integer math) was done correctly.
- If a specialized RISC-V instruction can handle a Keccak round or an elliptic-curve multiplication in *fewer CPU instructions*, the resulting zk circuit is smaller and faster to prove.
- **Example**: A single “Keccak round” instruction replaces dozens (or hundreds) of general-purpose RISC-V ops, cutting down the total steps the zk proof must cover.
2. **Parallel/Offloaded Computation**
- Heavy tasks—signature checks, Merkle trie hashing, polynomial arithmetic—can be offloaded to dedicated coprocessor blocks or precompiles that run in constant or near-constant time.
- Since the zkVM is proving the *RISC-V execution* itself, every CPU instruction is part of the proof. A specialized unit providing a “hardware call” for, say, big-integer multiplication can be treated as one instruction call, rather than expanding many micro-operations in the proof.
- **Example**: Instead of proving each step of a large multiplication in software, you prove just the single instruction that invoked the “big-int multiply” coprocessor—saving thousands of constraints.
This combination of zkVM + hardware-enhanced cryptography unlocks new performance ceilings, potentially allowing real-time or near-real-time proof generation for complex Ethereum transactions and block validation. Taking this one step further, if we run this code directly on a RISC-V processor with cryptographic extentions rather than a VM, we can gain a large speedup just from losing the massive overhead of virtualization.
**Leveraging Formal Verification of RISC-V**
Finally, [ensuring the correctness of the underlying RISC-V architecture itself via formal verification](https://verified-zkevm.org/) further cements trust in this zkVM model. If the RISC-V extensions and base ISA are proven to adhere to a rigorously specified, mathematically checked model, then the proof of execution isn’t just attesting to the correctness of higher-level operations (like hashing or signature checks)—it’s also anchored in the guarantee that each instruction in the CPU pipeline conforms precisely to the specification. This end-to-end assurance means that no hidden bugs or deviations in the hardware instructions can silently undermine the zero-knowledge proof process. In other words, formal verification of the RISC-V spec ensures that both the “coprocessor” tasks (like cryptographic math) and the “glue” logic (like branching and state transitions) faithfully follow the intended logic at the hardware level, extending trust from the software stack all the way down to the silicon.
---
### Conclusion - why RISC-V
In conclusion, RISC-V stands out as the natural foundation for a “glue + coprocessor + zkVM” paradigm precisely because it unifies all the qualities necessary for real time proving. By design, modern zkVMs such as the current leader [SP1](https://www.succinct.xyz/) already use RISC-V as their core instruction set, leveraging its openness and flexibility. Because RISC-V is open source, developers can freely add cryptographic extensions - whether it’s specialized big-integer arithmetic, hardware Keccak, or elliptic-curve engines - without the licensing barriers of proprietary architectures.
Meanwhile, the RISC-V ecosystem continues to grow and mature, offering a broader support base, toolchains, and commercial-ready solutions. Critically, formal verification work on the RISC-V spec ensures that these hardware-level enhancements remain provably correct, extending end-to-end trust from the software proof to the silicon.
All of these factors help bridge today’s reality—where a single Ethereum block proof might take 15 minutes—toward a future of real-time proving. By accelerating the cryptographic heavy lifting through specialized hardware, offloading structured tasks to “coprocessors,” and relying on a robust open architecture to handle “glue code,” RISC-V paves the way for generating valid zk proofs well within an Ethereum slot, and the road to real-time proving.
*If you're interested in articles like this, consider subscribing to [our Substack, 0xFutures](https://0xfutures.substack.com)*
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet