# Why we open new connection for every request
> Infrastructure doesn't support service mesh, so we need to dial new connection for every request.
[Slack conversation](https://deliveryhero.slack.com/archives/C4U7N89PZ/p1639476059219900?thread_ts=1614839138.360600&cid=C4U7N89PZ)
> you will have a lot od failed conenctions and downtime when pods reschedule and rotate
[Slack conversation](https://deliveryhero.slack.com/archives/C4TL8T5U4/p1675245946130519)
> yes, just to confirm - right now to use gRPC you need to bring up and tear down the connection every time, similar to how you would handle a REST connection - the reason for this is that if you don't, then when the cluster starts to scale, your persistent connections will still go to the existing pods, meaning the new pods won't get traffic, which in turn means that a. you won't get the benefit of the new pods and b. the service won't scale further as the new pods will have no traffic and so the average CPU usage across the pods won't trigger a scaling event
# Why GRPC is fast
1. HTTP/2
* Connection Multiplexing - streams provide concurrency
* Flow Control
2. Protocol Buffer
* Efficient and compact binary encoding
# What is HTTP/2
[Reference](https://www.cncf.io/blog/2018/07/03/http-2-smarter-at-scale/)
## Streams
* Open connection is a expensive operation
* Establish TCP connection / Handshake
* Secure connection using TLS
* Exchange Headers and Setting
* HTTP/1.1 - Providing a long-lived, reusable connection
* One request at a time - Starving if processing a large payload request
* New request either waits for its completion or, more frequently, open a new connection
* HTTP/2 Stream comes to the rescue
* A series of semantically connected messages, called **frames**
* connection concurrency, i.e. the ability to interleave messages on a single connection.
* Concurrency does not mean parallelism, though; we can only send one packet at a time on the connection
* Round Robin
* User Customized priority


## Flow Control
* Without Flow Control, a large stream would still break the TCP buffer size.
* Stream A might be interfered by the Stream B with large payload
* Flow control is used to limit the amount of outstanding data on a per-stream (and per-connection) basis
* It operates as a credit system in which the receiver allocates a certain “budget” and the sender “spends” that budget
# gRPC on HTTP/2 Engineering a Robust, High-performance Protocol
[Reference](https://grpc.io/blog/grpc-on-http2/)
## GRPC semantics
* Channel(ClientConn in Go)
* RPC
* Message
Each channel may have many RPCs while each RPC may have many messages.
how gRPC semantics relate to HTTP/2
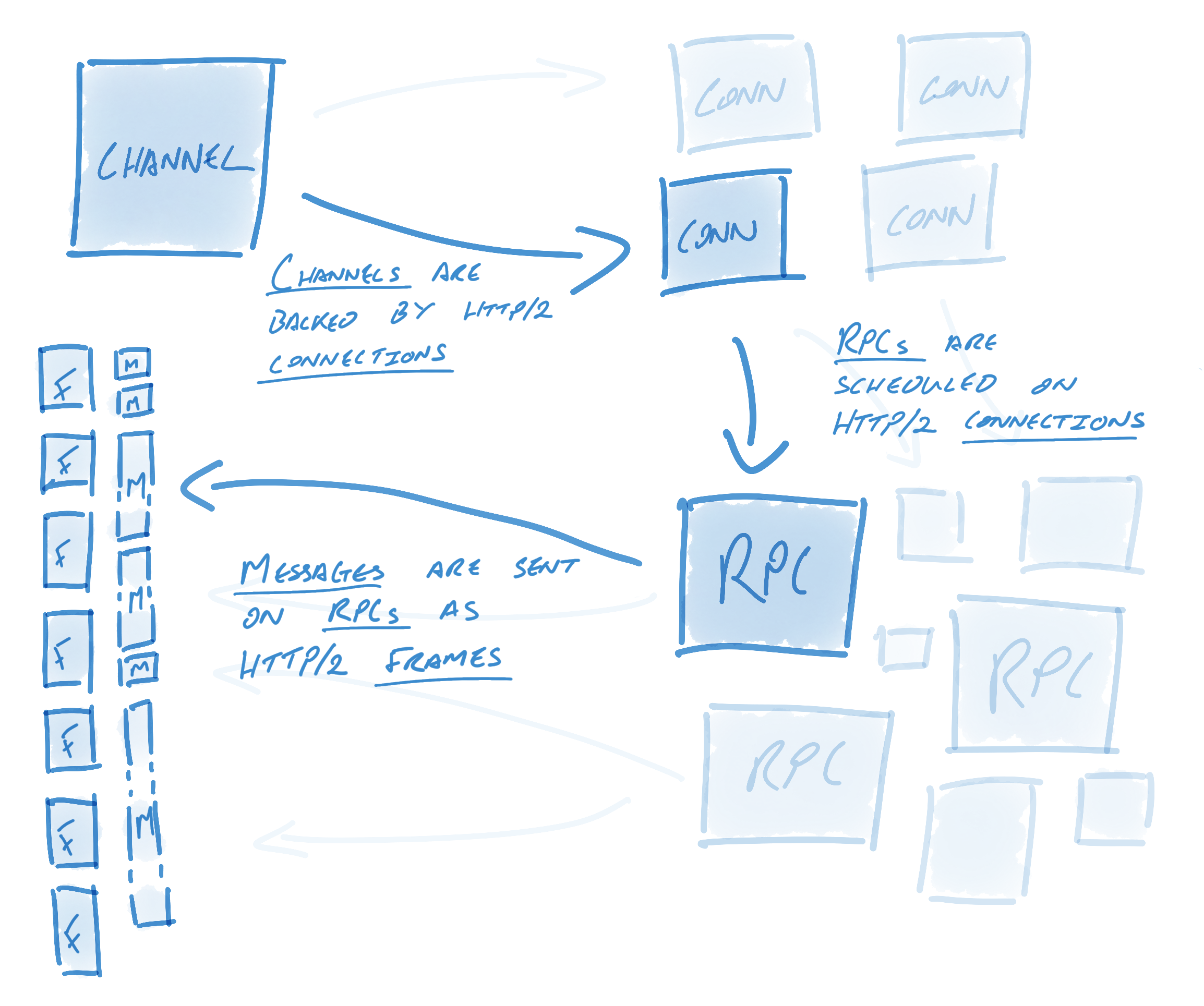
* HTTP/2 enable mutiple concurrent conversation on a single connection
* Channel Extend this concept by multiple streams over multiple concurrent connections
* an incredible amount of engineering goes into keeping these connections **alive, healthy, and utilized.**
* Channels represent virtual connections to an endpoint, which in reality may be backed by many HTTP/2 connections
* RPCs are in practice plain HTTP/2 streams
* Messages are associated with RPCs and get sent as HTTP/2 data frames.
## Resolvers and Load Balancer
* In order to keep connections alive, healthy, and utilized, gRPC utilizes a number of components, foremost among them name resolvers and load balancers
* Resolver: turn name into address and hand them to the load balancer.(Example: DNS resolver)
* Load Balancer: In charge of creating connection from these addresses & load balancing RPCs between them
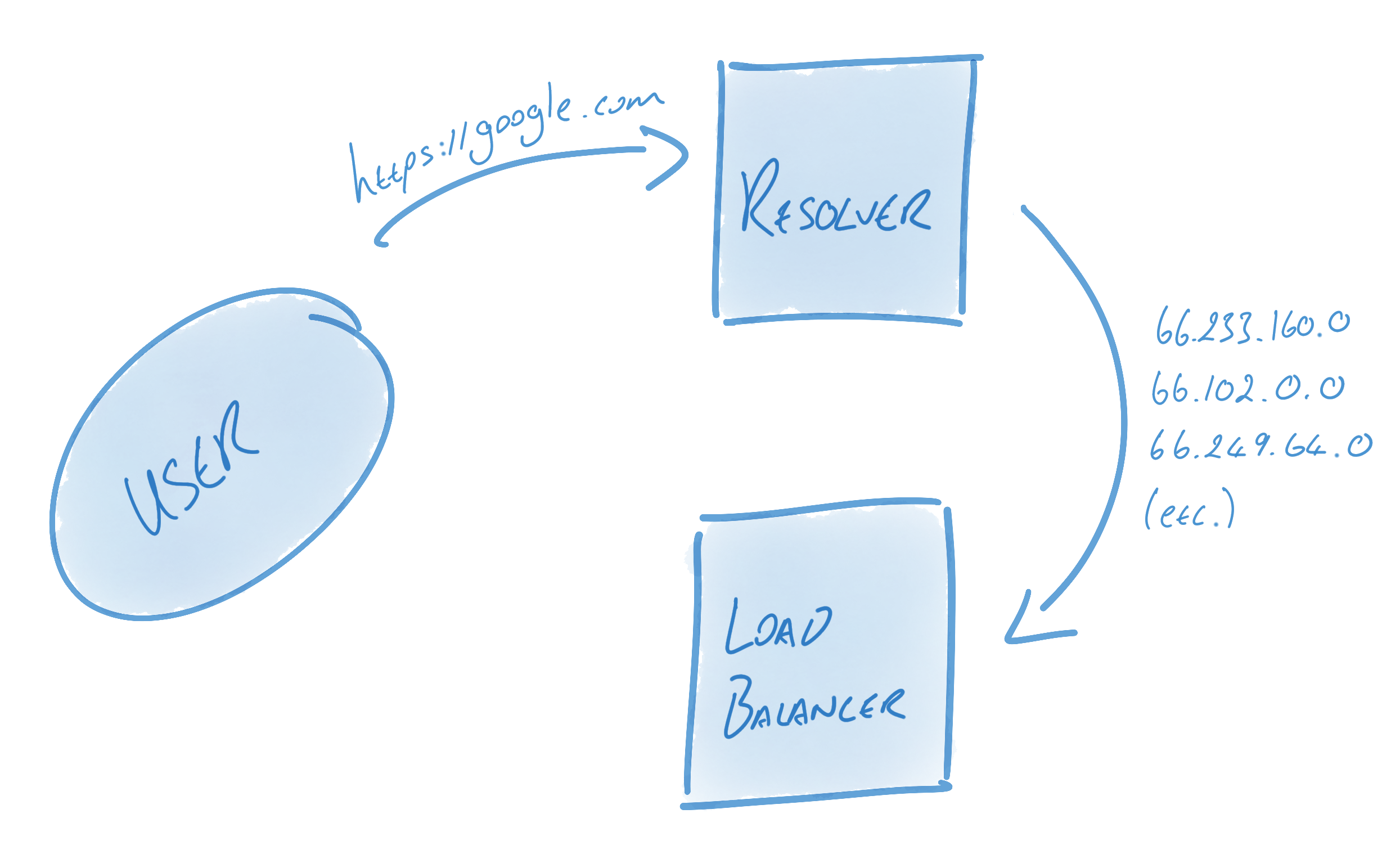
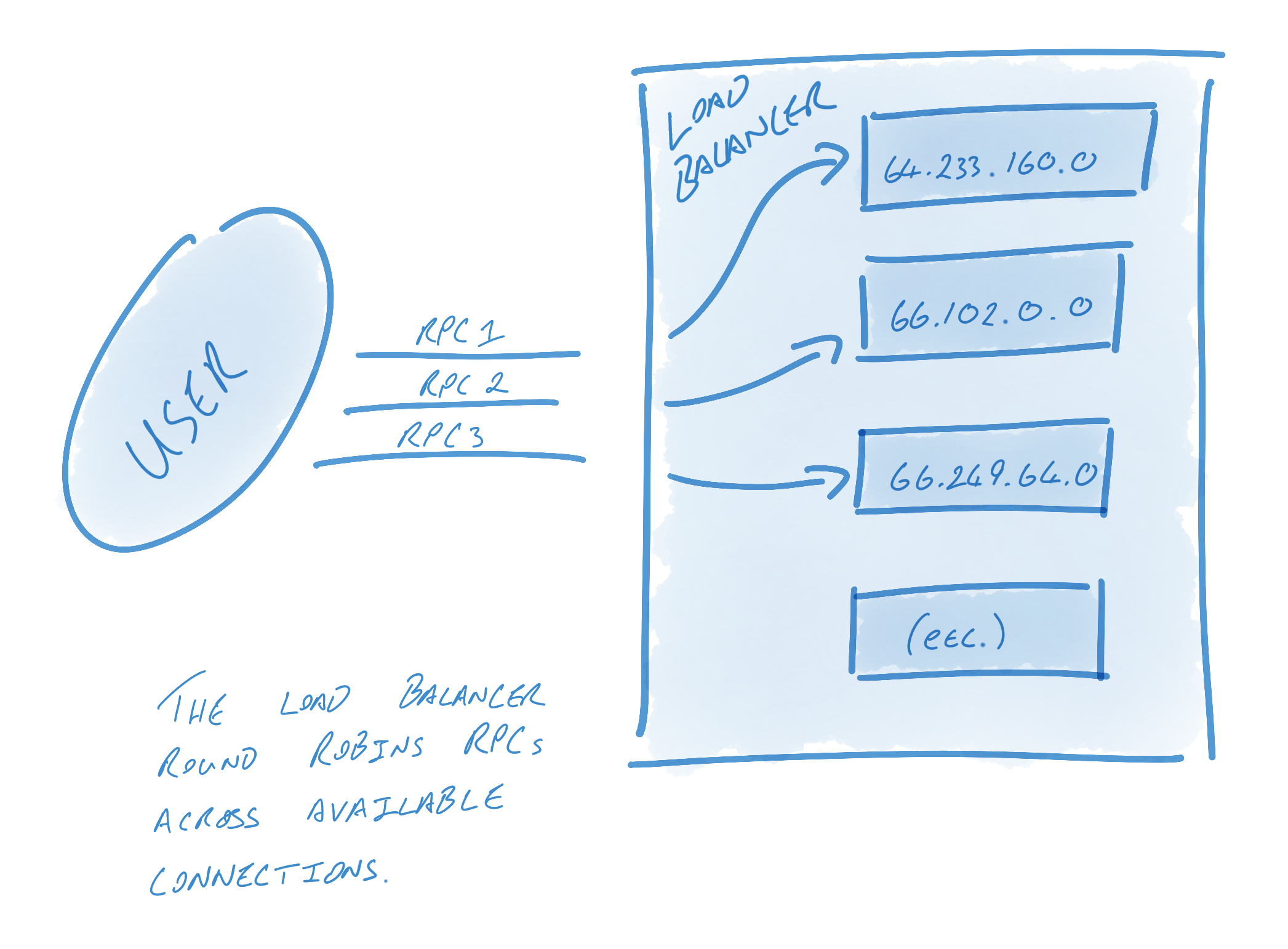
> Alternatively, a user who wants multiple connections but knows that the host name will only resolve to one address might have their balancer create connections against each address 10 times to ensure that multiple connections are used.
[GRPC balancer package](https://pkg.go.dev/google.golang.org/grpc/balancer)
* Take away
* GRPC manage the connection pool in nature
* GRPC provides the client side load balancing if a name can resolves to multiple ip addresses.
## Connection Management
* Once configured, gRPC will keep the pool of connections - as defined by the resolver and balancer - healthy, alive, and utilized.
* When a connection fails
* Load Balancer would reconnection using the last know addresses
* The Resolver would re-resolve the addresses
* Once resolution is done
* Load balancer would tear down the connection to address not present in the list
* Load balancer would create new connection to addresses that weren't here previously
## Identifying Failed Connections
1. Clean Failure: the failure is communicated
* For example, the server gracefully shutdown(morty deployment)
* This ends the HTTP/2 connection, GRPC would reconnect as described above
3. less-clean Failure
* when configured using KeepAlive, gRPC will periodically send HTTP/2 PING frames
* If a PING response does not return within a timely fashion, gRPC will consider the connection failed, close the connection, and begin reconnecting (as described above)
* Take away
* The first statement is not fully ture: "you will have a lot od failed conenctions and downtime when pods reschedule and rotate".
* Grpc would manage the failed connection in the background in theory. For less-clean failure, we can resolve through keep-alive grpc feature([Go example code](https://github.com/grpc/grpc-go/tree/master/examples/features/keepalive))
* Load Balancing is built in the GRPC, should be no problem? Would discover this in the following chapters.
# K8s load balancing
## [Services](https://kubernetes.io/docs/concepts/services-networking/service/)
* Pods are ephemeral resources - the set of Pods running in one moment in time could be different from the set of Pods running that application a moment later
* The Service API, part of Kubernetes, is an abstraction to help you expose groups of Pods over a network. Each Service object defines a logical set of endpoints (usually these endpoints are Pods) along with a policy about how to make those pods accessible.
* [Cluster IP](https://kubernetes.io/docs/concepts/services-networking/service/#type-clusterip) by default: One host can be resolved to only one cluster IP address.
* [gRPC Load Balancing on Kubernetes without Tears](https://kubernetes.io/blog/2018/11/07/grpc-load-balancing-on-kubernetes-without-tears/)
* Service Mesh - gRPC load balancing on Kubernetes with Linkerd
* these proxies watch the Kubernetes API and do gRPC load balancing automatically
* It would require a control plane installed in our cluster, which requires infra support. It's still in progress
# What's our option to improve our client
1. Customize the grpc balancer component
2. Refresh the connection in a interval
* The rationale behind this is that opening a new connection and let k8s connection load balancing reschule a pod for us to connect.
3. [KubeResolver](https://github.com/sercand/kuberesolver)
# Other useful References
[gRPC Load Balancing on Kubernetes examples](https://github.com/jtattermusch/grpc-loadbalancing-kubernetes-examples)
[Load balancing and scaling long-lived connections in Kubernetes](https://learnk8s.io/kubernetes-long-lived-connections)
[API Gateway to Service Mesh: Navigating a Changing Landscape - Zhamak Dehghani](https://www.youtube.com/watch?v=QYdOJ0QJptE)
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet