## 需求与问题
近期,剪映的自动识别字幕需升级到 SVIP 才能使用,看在豆包免费的份上就不吐槽,但我最常使用剪映的功能就是识别字幕,其他花哨的技巧我用的少,再继续升级氪金实属有点费钱。
其实,很早就知道 PotPlayer 支持自动生成字幕,而且很多大佬都说速度快、是标准,我们今天就用起来吧!
如何安装 potplayer 就不赘述,主要讲授使用 potplayer 自动生成字幕时,不会根据自己的电脑配置选择转换引擎、型号等这个问题。
希望一文带你实现免费、快速、好用AI 自动生成字幕的自由。
## 电脑配置
我的主机是零刻 GTR7 Pro——
CPU:AMD Ryzen 7 7840HS
内存:32GB
GPU:Radeon 780M
系统:Windows 11 Pro 24H2
> [!NOTE] 笔记
> 如果是同型号电脑那就照抄。
>
> 不同的话,各位可以更换上方的配置信息+生成有声字幕的截图,一并发送给 AI 询问`建议如何设置这个软件`。
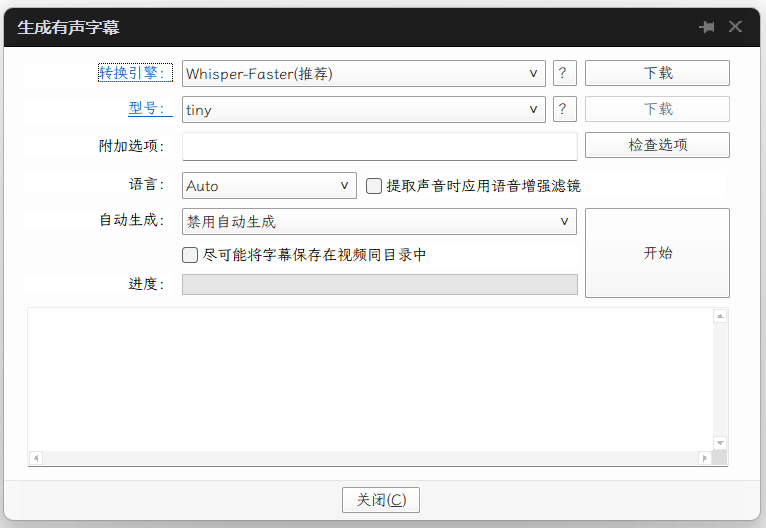
## 设置方法
**7840HS + Radeon 780M(Win11)最合适的引擎顺序是**:
① Whisper Const-me(DirectML)> ② whisper.cpp Vulkan > ③ Whisper-Faster(CPU)。
> [!NOTE] 笔记
> CUDA 专供 NVIDIA,不适合;
> whisper.cpp CPU/BLAS 仅作兜底。
### 不同场景的推荐设置
#### 场景A:日常转写(快速)
- **转换引擎**:Whisper Const-me
- **模型**:`small`(中文已很稳、速度快)
- **语言**:**可指定语言,如Chinese**,减少多语种混判。若是多语种则选择 Auto。
- **语音增强滤镜**:嘈杂素材才开“语音增强滤镜”,干净录音建议关闭以免音色失真。
- 自动生成:禁用;
- 备注:同目录保存可勾选
#### 场景B:需要高准确率(定稿级)
- **转换引擎**:Whisper Const-me
- **模型**:`medium`(更准,稍慢)
- 其余同上
### 如果 Whisper Const-me 不稳定/报显存不足
- 切换 **whisper.cpp Vulkan**(也能吃到 AMD GPU 加速)。
- 仍不行再用 **Whisper-Faster**(走 CPU,7840HS 也很能打),模型选 `small/medium`。
### 引擎简述
- **Whisper Const-me**:走 **DirectML**,最适合 AMD/Intel 显卡的 Windows;速度通常是纯 CPU 的 2–4 倍。
- **whisper.cpp Vulkan**:走 Vulkan GPU,兼容 780M;偶尔更挑驱动。
- **Whisper-Faster**:基于 CTranslate2,CPU 优化好;你这颗 Zen4 多核跑 `small/medium` 速度也可观。
- **CUDA**:仅 NVIDIA;**不要选**。
- **Faster-Whisper-XXL**:大模型/英文更强,但在你这边只能 CPU,**慢**;中文不一定优于 `medium`。
### 模型简述

> [!NOTE] 说明
> - `.en` 是**仅英文**版,体积与对应非 `.en` 基本相同。若素材多语混讲,就选**非 `.en`**。
> - 不同引擎的打包格式(GGML/GGUF/CT2)会让数字有±5~10%的出入,但量级不变。
> - 如果同时下了 `large`、`large-v2`、`large-v3`,会**各占一份**空间;只保留 **`large-v3`(或 v3-turbo)** 即可。
> - 实用组合:`small`(244 MB)+ `medium`(769 MB)+ `large-v3`(1.55 GB)合计**≈ 2.6 GB**,覆盖“草稿 → 定稿 → 高难片段”的全流程。
## 小技巧
### 模型大小怎么选
- `small`:≈0.5–1.2 GB;**草稿/常规**(硬件要求低)
- `medium`:≈2–4 GB;**定稿**(更准)
- `large-v3`:≥5 GB;对 iGPU 压力大,**除非特别追求极致,不建议**
> 若 DirectML 提示显存不足:把 BIOS 里的 UMA/iGPU 显存调到 4–8 GB(可选),或改用 `small`/Vulkan/CPU。
### 为什么不建议用 tiny?
- tiny/ base 在中文上**漏字、错词**会明显增多;`small` 是速度与准确率的更好平衡,`medium` 是稳定成片的常用选择。
### 何时开启“语音增强滤镜”?
- **开**:人多嘈杂/空房间混响/底噪重(空调、风声)。
- **关**:原本就干净的人声录音(避免过度处理导致失真)。
### “附加选项”留空更稳
- 这栏通常是传递底层引擎参数的,默认就很好;
- 当你遇到被自动翻译成英文、漏字、乱码之类情况,再尝试填(若软件不支持,会直接忽略,不影响使用):
~~~text
--task transcribe
--temperature 0
--vad_filter true
~~~
解释:
- `--task transcribe`:确保按照你选择的**语种转写**,不把非英语强行翻译成英文。
- `--temperature 0`:更稳定;若遇到漏字/乱码,可改为 `--temperature 0,0.2,0.4`(回退重试)。
- `--vad_filter true`:更好地跳过静音/噪声段(如果你的版本支持)。