# 分散式系統期中考
###### tags: `NCKU`
## 1
...
You are asking to design the K-means clustering algorithm with MapReduce.
(1) Please sketch algorithms for mappers and reducers.
(2) Please discuss the potential performance bottleneck for your algorithms. (PS: Ideally, we may have
k times speedup, compared with a single computing node, if we perform mapper and reducer
tasks over k computing nodes.)
### Ans:
1. Please sketch algorithms for mappers and reducers.
* Map:
1. 讀取數據
2. 與所選定中心做對比,求出該條紀錄對應的中心
3. 以中心的 ID 為 key,該條數據作為 value 做輸出
* Reducer:
1. 將相同的 key 歸併置一起
2. 集中與該 key 對應的數據
3. 求出已對應至 key 的數據的平均值
4. 輸出平均值,以進行選取新的中心的動作
* MapReducer:
1. 對比reduce求出的平均值與原來的中心,如果相同。則刪掉reduce的輸出目錄,運行一個沒有reduce的任務將中心ID與值對應輸出。
2. Please discuss the potential performance bottleneck for your algorithms. (PS: Ideally, we may have k times speedup, compared with a single computing node, if we perform mapper and reducer tasks over k computing nodes.)
由於 K-means 其基本思想是:將空間中的 n 個對象集合以 K 個點為中心進行劃分,歸類到與其距離最近的中心。通過疊代的方式,逐次更新聚類中心的值並重新劃分簇,直至目標函數收斂,假設共有n個數據對象,計劃劃分為K個簇,t為疊代次數,O為一次疊代中計算某一對象到各個類的中心距離的時間複雜度,那麼串行實現K-means算法的時間複雜度為 $n * K * t * O$ ,由此可知,數據集規模大時,算法的時間複雜度將成倍地增加。
當數據集的規模較小時,串行 K-means 算法的執行效率優於並行化 K-means 算法的執行效率,這是由於數據量小時,其計算任務所消耗的資源較少,但是在Hadoop平台上啟動、分配任務以及進行作業間的交互卻需要耗費固定的資源。
但隨著數據集規模的增大,計算任務所占用的資源的比例將不斷增大,使並行化算法的優勢得以體現,其運行時間的增長速度遠小於串行算法。另外,由於串行算法所消耗的資源快速地增長,系統將會報告內存不足。
---
## 2.
LevelDB implements the Log Structured-Merge Tree (LSM) algorithm for managing and compacting data flushed to the secondary storage.
1. Please state how LSM works.
### Ans:
LSM ( Log Structured-Merge Tree) 第一次發表是來自 Google BigTable 論文,他出現是為了大數據 OLAP 場景
* heavy write throughput
* 可以犧牲 read 的速度。
其中,HBase, Cassandra, LevelDB 等,都是使用 LSM Tree 來實現的。
LSM 的機制是盡可能使用到 disk sequential write ,提供比傳統的B+樹更好的寫操作吞吐量,read 部分雖然理論上會比 B Tree 要慢,但依然在可接受的程度。
通過消去隨機的本地更新操作來達到這個目標,因為磁盤隨機操作慢,順序讀寫快。
LSM 將 **寫操作** 順序的保存到一些相似的有序文件(也就是sstable)中。
* 因為文件是有序的,所以之後查找也會很快。
* 文件是不可修改的,他們永遠不會被更新,新的更新操作只會寫到新的文件中。
1. Please discuss how to perform read and write data flows in a DB engine based on LSM.
### Ans:
* Write:
1. LSM Write 一開始會先把 data 添加到 WAL File 裡面(日誌型),是一個 sequential write operation 的動作。
2. 在 memory 內,使用 AVL Tree or 其他 Tree 等 sorted tree 方式來 index data,此行為稱做 memtable。在這裡的 operation 都是 in memory(速度快)。memtable 因為已 sorted,所以很容易實體化成 SSTable (Sorted String Table) 這種 file format。
3. memtable 經過一段時間,或是達成某個 criteria 之後( size > 某個值), batch 會把 memtable 的東西實體化成 SSTable file 。這裡依舊是 sequential write operation
4. 由於每個 SSTable 皆為 immutable ,我們不會對 SSTable 進行 update in-place 的動作,SSTable File 會時間經過增加,且同一個 key 的值可能因為 update 次數多,其多個版本的 data 散落在多個 SSTable File 裡面。因此, backend process 會定期對 SSTable file 進行合併,稱做 compact。
當一定數量的 sstable file 被創建,例如有 10 個 sstable,每一個有15 行,他們被合併為一個 150 行的文件(或者更少的行數)。這個過程一直持續,最終會有 3 個 150 行的文件,這時會將這 3 個 150 行的文件合併成一個 450 行的文件,這個 Compact 過程會不停的創建更大的文件。
* Read:
1. 當一個讀操作請求時,系統首先檢查內存數據(memtable)
2. 如果沒有找到這個key,就會逆序的一個一個檢查sstable文件,直到key 被找到。
因為每個 sstable 都是有序的,所以查找比較高效(O(logN)),但是讀操作會隨著sstable的個數增加變的越來越慢,因為每一個 sstable 都要被檢查。 O(K log N), K 為 sstable 個數, N 為 sstable 平均大小)。
3. You are given SSD and typical magnetic hard drive. Consider that the data set cannot be completely accommodated by the SSD. Please state a data accessing scenario that LSM takes advantages of both SSD and magnetic hard drive. You shall state how LSM leverages the SSD and hard drive for the scenario you identify.
### Ans:
在傳統磁盤上,sequential IO 的性能大約是 random IO 的 100 多倍,LSMTree 基於此,將海量 KV 的隨機讀寫實現為內存隨機讀寫+順序刷盤+定期歸併(compact),以提高讀寫性能,尤其適用於寫多於讀且時效性比較強(最近數據最常訪問)的場景。 作為將隨機寫轉化為順序寫的代價,LSM 會有大量的重複寫入問題(寫放大)
以 LevelDB 為例,在最壞的情況下:
* 寫放大:10 * Level(Level N-1 向Level N 的 Compact 可能涉及多達 10 個 Level N-1 層文件)
也就是說,這個寫放大的係數大概在幾十到幾百之間。儘管如此,由於在傳統的機械盤上順序寫的性能遠遠好於其隨機寫性能,性能差異接近一千倍。因此,用數十倍的磁盤帶寬損失換取近千倍的性能提升,在寫入敏感的場景下這種交換的效果毋庸置疑。但不同的是,SSD 盤相對具有較高的隨機寫能力,與順序寫的差距本身只有十倍左右,並且還可以通過並行 IO 進一步提升,因此這種交換就有些不划算。同時,反复的寫入也會磨損 SSD 從而降低壽命。
當LSM中數據的長度很大時,這個問題變得尤為突出,這是因為:
* 數據長度越大,越易觸發 Compaction,造成寫放大
* 若把上層文件看做下層文件的 cache,大的數據長度會造成這個 cache 能存的數據個數變少,從而讀請求更大概率的需要訪問下層數據,從而造成讀放大
* 每條數據每次Merge需要更多的寫入量
進一步分析,LSM需要的其實是 key 的有序,並無關 value。
**因此,僅將Key值存儲在 LSM 中,並將 Value 區分存儲在 Log 中,數據訪問就變成了:**
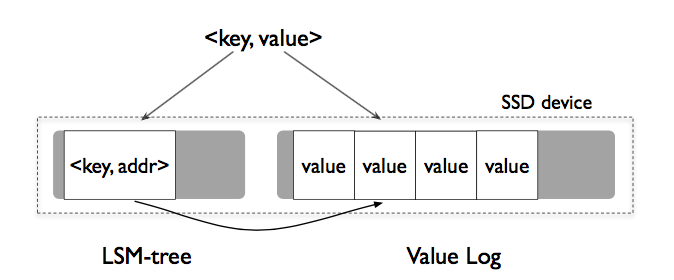(ref: https://pic3.zhimg.com/v2-295609fe3003aa8c2c3c6f3abb9150f6_r.jpg)
修改:先 append 到 vLog 末尾,再將 Key,Value 地址插入 LSM
刪除:直接從 LSM 中刪除,無效 Value 交給之後的垃圾回收
查詢:LSM 中獲得地址,vLog 中讀取
這樣帶來顯而易見的好處:
避免了歸併時無效的 value 而移動,從而極大的降低了讀寫放大
顯著減少了LSM 的大小,以獲得更好的 cache 效果
Key Value 分開存儲會導致以下三種問題,如果能解決或者容忍,那麼這種設計或可稱為成功的。
1. Key Value 分离带来的 Range 操作的低效
由於 Key Value 的分離,Range 操作從順序讀變成了順序加多次隨機讀,從而變得低效。此時利用 SSD 較強的隨機訪問性能與並行 IO 的能力,可以將這種損失盡量抵消。
2. 被用户删除或者过期版本的 Value 的空间回收
Compaction 過程,由於需要被刪除的數據只有 Key,因此, Value 還保留在分開的 Log 中,這就需要異步的回收。可以看出 LSM 本身的 Compaction 其實也是垃圾回收 (GC) 的思路,所以通過良好設計的 Value 回收方式其實並不會過多的增加系統的額外負擔。離線回收比較簡單,掃描整個 LSM 對 Value Log 進行 mark and sweep,但這相當於給系統帶來了負載帶來了陡峭的波峰,WiscKey論文又提出來了巧妙的在線回收方式:
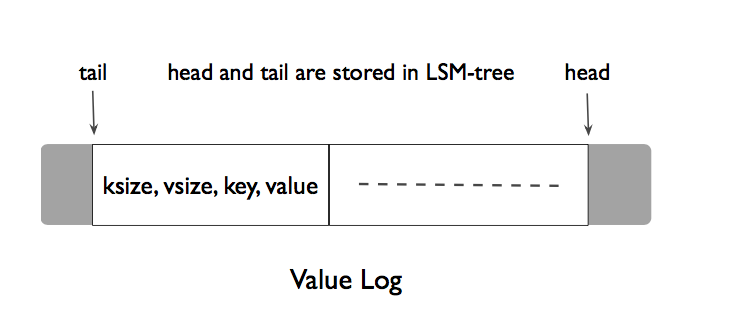(ref: https://pic4.zhimg.com/v2-c358992d92638a82e37aa29dc5ba8ba7_r.jpg)
head 的位置是新的 Block 插入的位置,tail 是 Value 回收操作的開始位置,垃圾回收過程被觸發後,順序從 Tail 開始讀取 Block,將有效的 Block 插入到Head。刪除空間併後移 Tail。可以看出,這裡的回收方式由於需要將有效的數據重新Append,其實也帶來了寫放大,這就需要很好的權衡空間放大和寫放大了,WiscKey 建議系統根據刪除修改請求的多少決定觸發垃圾回收的時機。
5. Crash Consistency
正式由於Key,Value的分離帶來了不可避免的在程序 Crash 發生時不一致的情況,因此,為了像標準的 LSM 一樣提供原子性操作與順序恢復的保證,可以有以下方法
在啟動時對Key, Value進行檢查:
* Key 成功寫入,Value 沒有,則從 LSM 中刪除 Key,並返回不存在
* Key 沒有成功寫入,Value 寫入,返回不存在,並在後續的 GC 中清除Value。
### 總結
* Value-Log Write Buffer: 給vLog維護一個緩存,來將短value合併為長value來提高磁盤吞吐
* Optimizing the LSM-tree Log:去掉LSM的Log,並週期性的更新Value Log的head值進LSM。 crash後的恢復僅需要從head開始遍歷所有的vLog同樣能保證上面提到的Crash Consistency
---
## 3.
Apache Spark supports a number of cluster managers such as Standalone, Apache Mesos, Hadoop YARN and Kubernetes. Please choose a cluster manager and discuss how Spark manages a Spark job lifecycle including job submission, resource allocation, tasks within a job assignment/computation, failure monitoring/recovery, etc. You are suggested to illustrate a Spark job for your discussions.
(https://img.itw01.com/images/2019/04/10/17/1532_1MAYtW_UFD9JEL.jpg!r800x0.jpg)
spark-submit 可直接用於將 Spark 應用程序提交到 Kubernetes 集群。提交機制的工作原理如下:
* Spark 創建在 Kubernetes pod 中運行的 Spark 驅動程序。
* 驅動程序創建也在 Kubernetes pod 中運行的執行程序並連接到它們,並執行應用程序代碼。
* 當應用程序完成時,executor pod 終止並被清理,但驅動程序 pod 保留日誌並在 Kubernetes API 中保持“已完成”狀態,直到最終被垃圾收集或手動清理。請注意,在完成狀態下,驅動程序 pod 不使用任何計算或內存資源。
也就是說當我們通過spark-submit提交作業的時候,會自動生成driver pod與exector pods。 除了這種直接向 Kubernetes Scheduler 提交作業的方式,還可以通過 Spark Operator 的方式來提交,而 Operator 就是 CRD + Controller 的組合形式。開發者可以定義自己的 CRD,比如定義一種 CRD 叫 EtcdCluster:
```yaml=
apiVersion: "etcd.database.coreos.com/v1beta2"
kind: "EtcdCluster"
metadata:
name: "example-etcd-cluster"
spec:
size: 3
version: "3.1.10"
repository: "quay.io/coreos/etcd"
```
提交到 Kubernetes 之後 Etcd 的 Operator 就針對這個 yaml 中的各個字段進行處理,最後部署出來一個節點規模爲 3 個節點的 etcd 集羣。
在引入 Spark Operator 後,Spark Operator 首先定義了兩種不同的 CRD 物件,分別對應普通的計算任務與定時週期性的計算任務,而後解析 CRD 的配置檔案,拼裝成為 spark-submit 的命令,通過暴露監控資料採集介面(prometheus),建立 Service 提供 spark-ui 的訪問。然後通過監聽 Pod 的狀態,不斷回寫更新 CRD 物件,實現了spark 作業任務的生命週期管理。
(https://img.itw01.com/images/2019/04/10/17/1543_KekZ4H_UFD9JEL.jpg!r800x0.jpg)
一個 Spark 的作業任務可以通過上述的狀態機轉換圖進行表示,一個正常的作業任務經歷如下幾個狀態:
```
New -> Submitted -> Running -> Succeeding -> Completed
```
當任務失敗的時候會進行重試,若重試超過最大重試次數則會失敗。也就是說如果在任務的執行過程中,由於資源、排程等因素造成 Pod 被驅逐或者移除,Spark Operator 都會通過自身的狀態機狀態轉換進行重試。此為 Spark Operator 對於生命週期管理增強的部分。
---
## 4.
Assume that you have a bunch of “small” files (e.g., 10 KBytes) to be stored in Hadoop. In Hadoop, NameNode takes at least 150 bytes for each file’s inode in its memory. Consequently, the total memory space runs up-to 130 GBytes in total for these small files. Please suggest a solution to minimize the memory space required.
### Ans:
首先先將大量小檔案問題分為兩種,
1. HDFS上的小檔案問題
處理小檔案並非Hadoop的設計目標,HDFS的設計目標是流式訪問大資料集(TB級別)。因而,在HDFS中儲存大量小檔案是很低效的。訪問大量小檔案經常會導致大量的尋找,以及不斷的從一個DatanNde跳到另一個DataNode去檢索小檔案,並不是一個很有效的訪問模式,嚴重影響效能。
最後,處理大量小檔案速度遠遠小於處理同等大小的大檔案的速度。每一個小檔案要佔用一個slot,而task啟動將耗費大量時間甚至大部分時間都耗費在啟動task和釋放task上。
3. MapReduce上的小檔案問題
Map任務(task)一般一次處理一個塊大小的輸入(input)(預設使用FileInputFormat)。如果檔案非常小,並且擁有大量的這種小檔案,那麼每一個map task都僅僅處理非常小的input資料,因此會產生大量的map tasks,每一個map task都會額外增加bookkeeping開銷
#### 解決 HDFS 上的小檔案問題
檔案是許多記錄(Records)組成的,那麼可以通過呼叫HDFS的sync()方法(和append方法結合使用),每隔一定時間生成一個大檔案。或者,可以通過寫一個程式來來合併這些小檔案。
#### 解決 MapReduce 上的小檔案問題
可以某種形式的容器使用特定方式來對這些檔案進行分組。Hadoop提供了一些選擇:
1. HAR File
Hadoop Archives 是為了緩解大量小檔案消耗NameNode記憶體的問題。HAR檔案是通過在HDFS上構建一個分層檔案系統來工作。HAR檔案通過hadoop archive命令來建立,而這個命令實 際上是運行了一個MapReduce作業來將小檔案打包成少量的HDFS檔案 (小檔案進行合併幾個大檔案)。對於client端來說,使用HAR檔案沒有任何的改變:所有的原始檔案都可見以及可訪問,,但是在HDFS中中檔案數卻減少了。
但是 Hadoop 在進行最終檔案的讀取時,需要先訪問索引資料,因此,HAR 在效率上會比直接讀取 HDFS 檔案慢一些。(參考下圖)
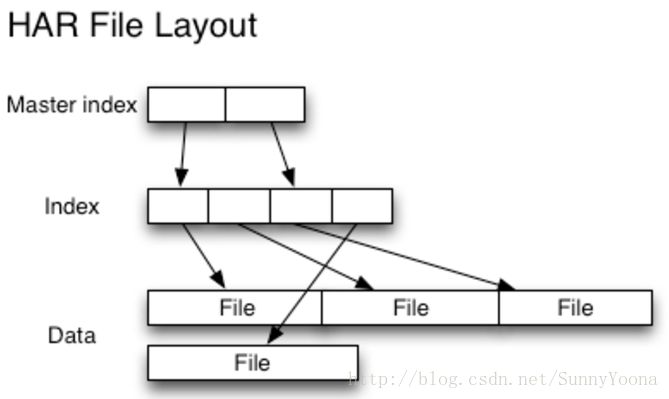(ref: https://img-blog.csdn.net/20161225153157287?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvU3VubnlZb29uYQ==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/SouthEast)
2. SequenceFile
使用檔名(filename)作為 key,並且檔案內容(file contents)作為 value。
在此情況我們可以將很多個小檔案放入一個 SequenceFile,以流式處理它們(直接處理或使用MapReduce)操作SequenceFile。

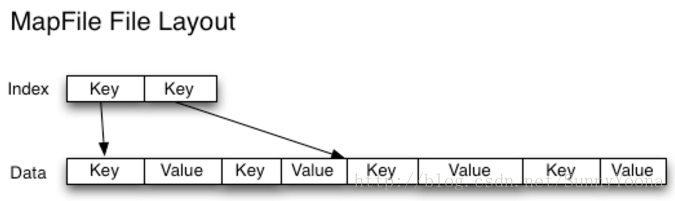
這樣同時會帶來兩個優勢:
* SequenceFiles是可拆分的,因此MapReduce可以將它們分成塊並獨立地對每個塊進行操作
* 同時支援壓縮,不像HAR。 在大多數情況下,塊壓縮是最好的選擇,因為它將壓縮幾個記錄為一個塊,而不是一個記錄壓縮一個塊。
3. HBase
HBase 以Map Files(帶索引的SequenceFile)方式儲存資料,如果您需要隨機訪問來執行MapReduce式流式分析,這是一個不錯的選擇。
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet