# 【vMaker Edge AI專欄 #13】 誰說單晶片沒有神經網路加速器NPU就不能玩微型AI應用?
作者:Jack OmniXRI, 2024/01/15

講到AI相信大家第一時間多半是聯想到大型語言模型(LLM)和生成式AI(genAI, AIGC)應用,可以對話聊天、查詢資料、生成文章圖像和音樂,而這些應用多半需要用到極大的雲端算力才能完成。對於微型AI應用,如語音喚醒(語音命令)、異常偵測(振動、異音、環境感測器)、運動偵測(手勢、跌倒)、影像分類、影像物件偵測、影像姿態偵測(全身、手指)等,通常可利用單晶片(MCU)或微處理器(MPU)配合較小的AI模型就有機會辦到邊緣(離網)就完成推論工作。
在「[MCU攜手NPU讓tinyML邁向新里程碑](https://omnixri.blogspot.com/2022/10/mcunputinyml.html)」[1]一文中提到,AI推論主要都是在進行巨量的矩陣乘加運算(MAC),就是「**a×b+c**」。而加速計算方式可使用「**提高工作時脈速度**」、「**平行/向量指令集加速**」、「**多核心加速**」、「**NPU神經網路加速器**」等硬體加速作法。而一般單晶片在單核CPU的情況下,最容易達成的作法就是前兩項,而本文將從「**平行/向量指令集加速**」的角度來為大家說明如何在沒有神經網路加速器NPU時也能順利玩微型AI應用。
## 1. Arm精簡指令集的演進
目前市售32bit單晶片大約有八到九成都是使用Arm Cortex-M系列矽智財(SIP)完成的,不同系列分別對應到不同的指令集(ARMv6-M~v8.1-M),而「-M」就是指將該版本指令集濃縮後專門提供給單晶片使用的。相關指令集對應的矽智財如下所示。[2]
* **ARMv6-M:** Cortex M0(2009) / M0+(2012) / M1(2007)
* **ARMv7-M:** Cortex M3(2004)
* **ARMv7E-M:** Cortex M4(2010) / M7(2014)
* **ARMv8-M Baseline:** Cortex M23(2016)
* **ARMv8-M Marnline:** Cortex M33(2016) / M35P(2018)
* **ARMv8.1-M:** Cortex M55(2020) / M85(2022) / M52(2023)
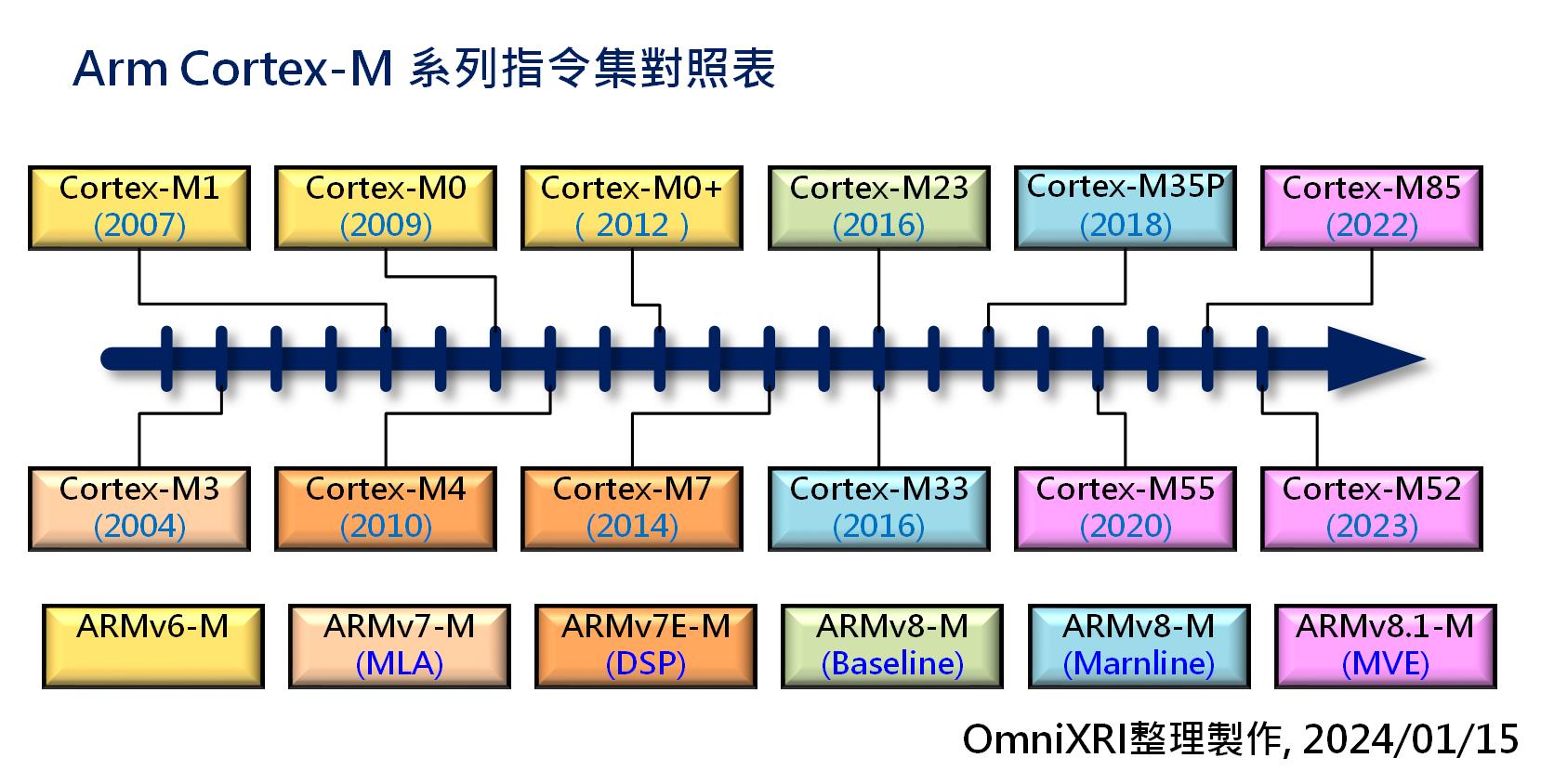
Fig. 1 Arm Cortex-M 系列指令集對照表。(OmniXRI整理製作,2024/01/15)
## 2. Cortex-M指令如何加速計算
其中「v7-M」指令集就開始支援單時脈乘加指令**MLA**,即將原來需要二道指令MUL, ADD分別計算乘法和加法變成一道指令,如此就能將計算速度提升兩倍。到了「v7E-M」DSP擴展指令集時開始支援單指令多資料流(Single Instruction Multiple Data, **SIMD**),如QADD, QADD16, QADD8等,可將32bit分拆成2個16bit或4個8bit資料一起計算,如此就能增加2~4倍計算速度。當再搭配工作時脈從數十MHz提升到數百MHz後,對於語音喚醒詞(Key Word Spotting, **KWS**), 感測器異常偵測(Anomaly Detection, **AD**), 運動手勢辨識(Motion / Gesture Dectection)等微型AI應用大概都能完成,但若遇到有影像類應用則遠遠不夠。
Arm Cortex-A系列為64bit CPU,所以其上有**NEON**(進階SIMD)指令集,可處理128bit或64bit的SIMD計算,讓計算速度更快,但這樣的指令在32bit的Cortex-M並沒有支援,所以Arm在v8.1M指令中加入Helium M型向量擴展指令(M-Profile Vector Extension, **MVE**)來提升Cortex-M單晶片的算力。Helium可以處理128bit的向量運算(相當於SIMD 16x8bit, 8x16bit, 4x32bit),共有8個向量暫存器,可處理整數、定點數(Q7,Q15,Q31)及浮點數(半精度FP16/單精度FP32)計算,有超過150個新指令。[3]
若為了處理128bit的向量計算就把資料匯流排(Data bus)及單晶片內部靜態記憶體(SRAM)都改成128bit寬是不合理的。最簡單的作法是利用四個時脈週期將128bit資料當成4個32bit的資料來處理,但這樣就會變成和單指令週期32bit SIMD指令沒什麼不同。因此Helium在向量計算時可以將載入(VLDR)和乘加(VMLA)計算進行重疊,一邊載入一邊計算,這樣就可以再加速一倍以上。如Fig. 2右下所示。
在Cortex-M55/M85採取雙節拍(Dual Beat)作法,就是1個時脈週期(Clock Cycle)讀取二個節拍(Beat),即2×32=64bit,所以128bit的向量要2個時脈週期才能處理完成,而1個時脈週期處理的內容可以是下列組合。
* 2個32bit(Q31定點數或32位元整數或32位元浮點數)
* 4個16bit(Q15定點數或16位元整數或16位元浮點數)
* 8個8bit(Q7定點數或8位元整數)
而Cortex-M52則採單節拍(Single Beat)作法,可處理長度則減半為32bit(1x32bit, 2x16bit, 4x8bit),128bit的向量需要4個時脈週期才能處理完成。
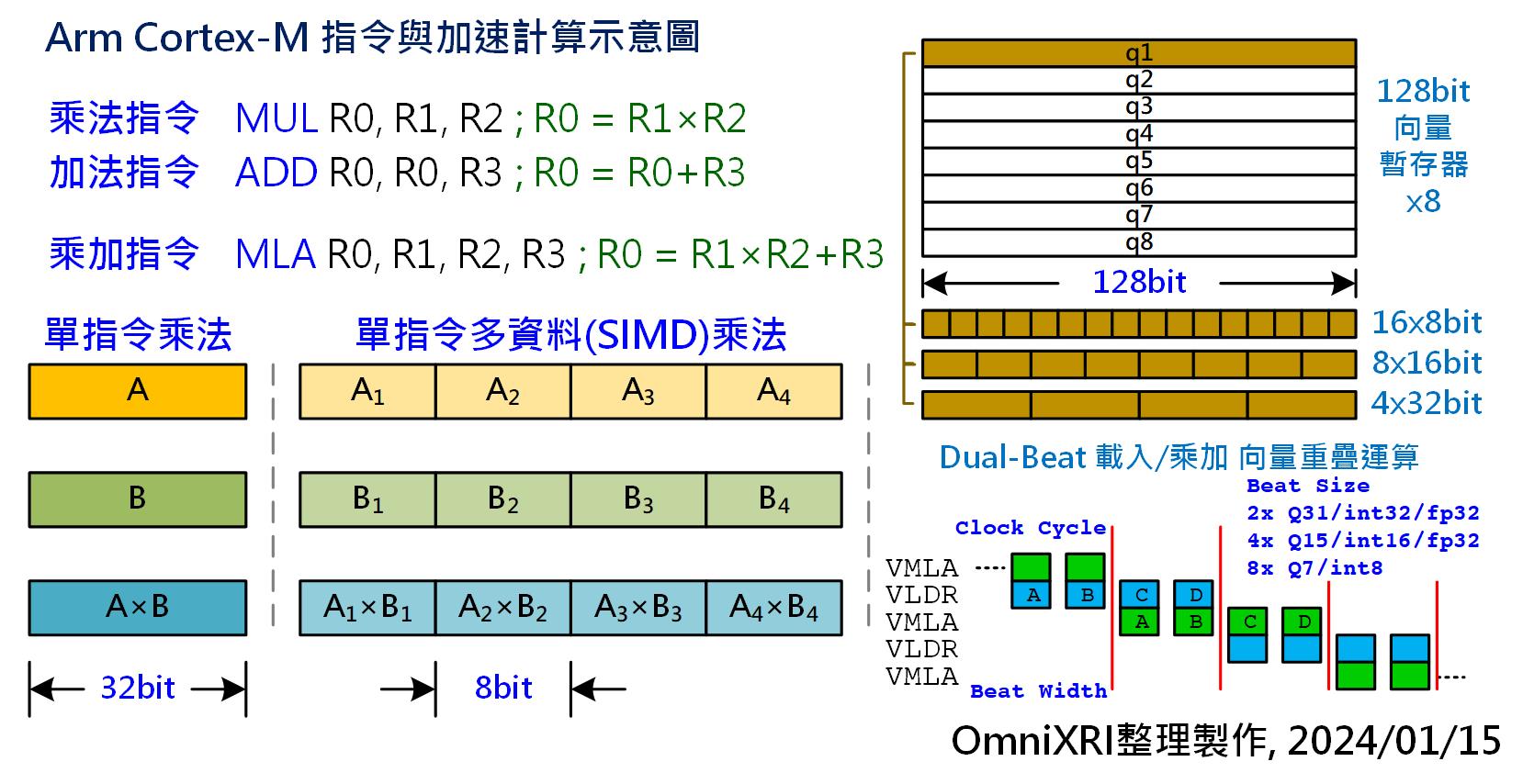
Fig. 2 Arm Cortex-M指令與加速計算示意圖。(OmniXRI整理製作,2024/01/15)
## 3. Helium指令集效能比較
目前有支援Helium指令的MCU共有四家公司,如下所示。
**Cortex-M55:**
* ALIF - Ensemble E1(@160MHz), E3(@160MHz), E5(dual core,@160MHz, 400MHz), E7(dual core,@160MHz, 400MHz) [4]
* 奇景(Himax) - WiseEye2 HX6538(dual Core, @150MHz, 400MHz) [5]
* 新唐(Nuvoton) - NuMicro M55M1(@200MHz) [6]
**Cortex-M85:**
* 瑞薩(Renesas) - RA8D1(@480MHz), RA8M1(@480MHz) [7]
**Cortex-M52:**
* None
以下就以Cortex-M7為基準(100%)和Cortex M55/M85/M52進行比較。如Fig. 3所示,橫軸為傳統性能(DMIPS/MHz),縱軸則為機器學習推論性能(ML Performance)。以M55為例,雖然傳統性能較M7低,但機器學習性能卻高出3倍,由此可看出Helium指令集提供的效能提升。
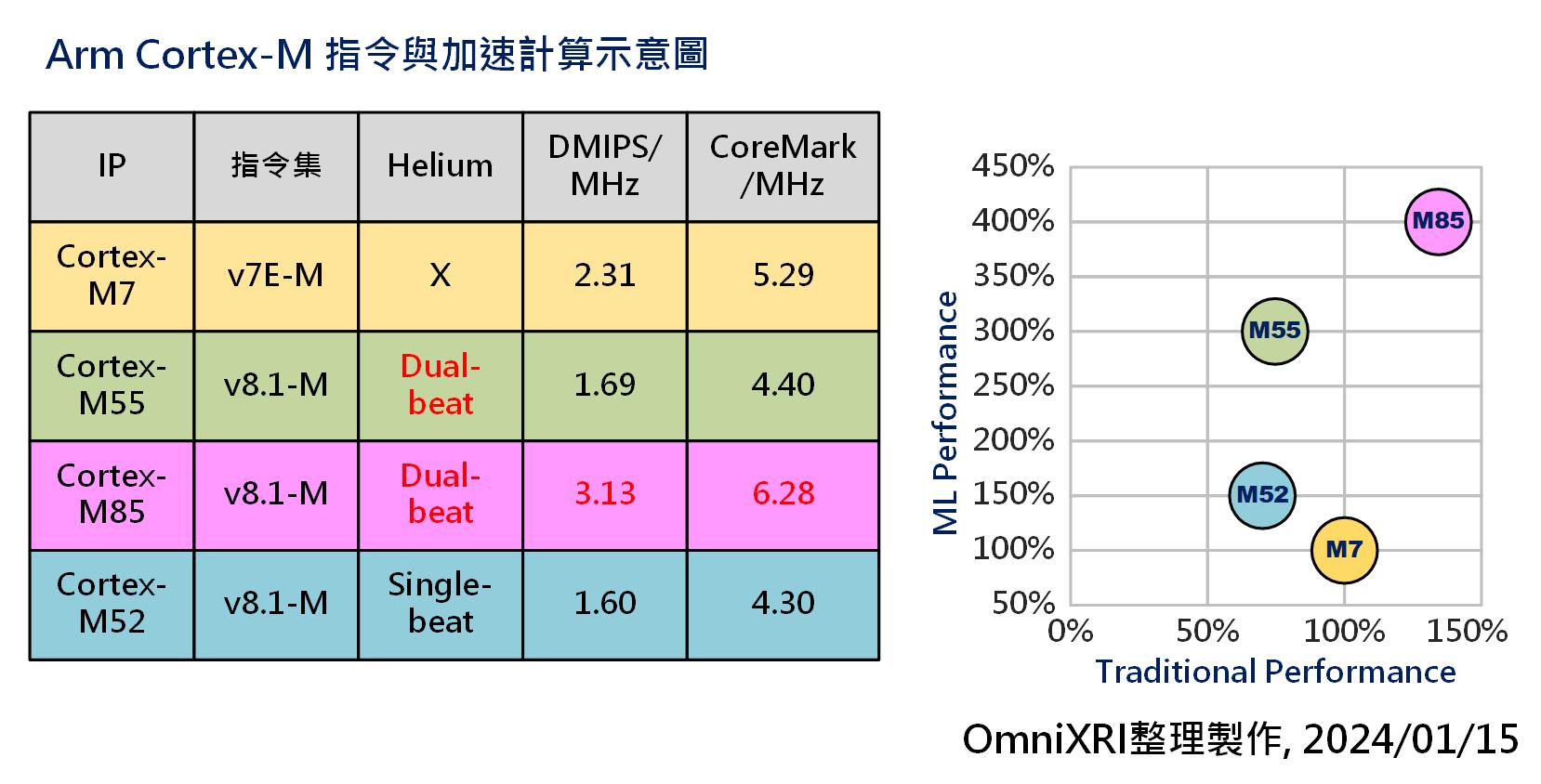
Fig. 3 Arm Cortex-M 指令與加速計算示意圖。(OmniXRI整理製作,2024/01/15)
以上算力對於非影像的微型AI應用大致能滿足,但若遇到影像類應用則單靠CPU的SIMD及MVE指令集可能還是不夠。幸運地是以上提及的ALIF, Himax, Nuvoton的MCU都有內建Arm Ethos U55 NPU,這樣就能將算力再推高數十倍,可以滿足低解析度、低頻度的影像分類、物件偵測甚至姿態估測等應用。
## 小結
隨著半導體技術的提升及配套的軟體開發工具逐漸到位,利用單晶片提高工作時脈及高度平行乘加運算(SIMD, MVE),開啟了可以不依靠網路就能完成微型AI運算的契機,使得平價、低耗能的邊緣智慧裝置(Edge AI & TinyML Device)有了更大的創意發揮空間,讓智慧生活、智慧照護、智慧製造、智慧建築等更多應用能快速實現。
## 參考文獻
[1] 許哲豪,MCU攜手NPU讓tinyML邁向新里程碑
https://omnixri.blogspot.com/2022/10/mcunputinyml.html
[2] Wikipedia, ARM Cortex-M
https://en.wikipedia.org/wiki/ARM_Cortex-M
[3] Github, arm-university/Arm-Helium-Technology - Reference Book
https://github.com/arm-university/Arm-Helium-Technology
[4] ALIF, Ensemble MCU
https://alifsemi.com/products/ensemble/
[5] Himax, WiseEye2 AI Processor
https://www.himax.com.tw/zh/products/intelligent-sensing/always-on-smart-sensing/wiseeye2-ai-processor/
[6] Nuvoton, AI Products
https://www.nuvoton.com.cn/ai/product/
[7] Renesas, RA Family of Arm Cortex-M based MCUs
https://www.renesas.com/us/en/products/microcontrollers-microprocessors/ra-cortex-m-mcus
## 延伸閱讀
[A] 許哲豪,當智慧物聯網(AIoT)遇上微型機器學習(tinyML)是否會成為台灣單晶片(MCU)供應鏈下一個新商機!?
https://omnixri.blogspot.com/2021/09/aiottinymlmcu.html
[B] Arm, 學習Arm-架構M系列
https://www.arm.com/zh-TW/architecture/learn-the-architecture/m-profile
[C] Arm, CPU架構-M系列
https://www.arm.com/zh-TW/architecture/cpu/m-profile
[D] Arm, 技術-Arm Helium
https://www.arm.com/zh-TW/technologies/helium
**本文同步發表在[【台灣自造者 vMaker】](https://vmaker.tw/archives/category/%e5%b0%88%e6%ac%84/jack-omnixri)**
---
OmniXRI 整理製作,歡迎點贊、收藏、訂閱、留言、分享
###### tags: `vMaker` `Edge AI`