---
slideOptions:
transition: slide
---
# FLatten Transformer:Vision Transformer using Focused Linear Attention
---
## 1.作者研究動機
---
### Vision TransFormer應用於影像分類技術
----
Vision TransFormer通過Split image與Linear Projection產生出patch embedding向量,並與position Embedding添加位置訊息的結果相加,最後通過 Encoder和MLP以及一層softmax,產生出這照張圖片的分類
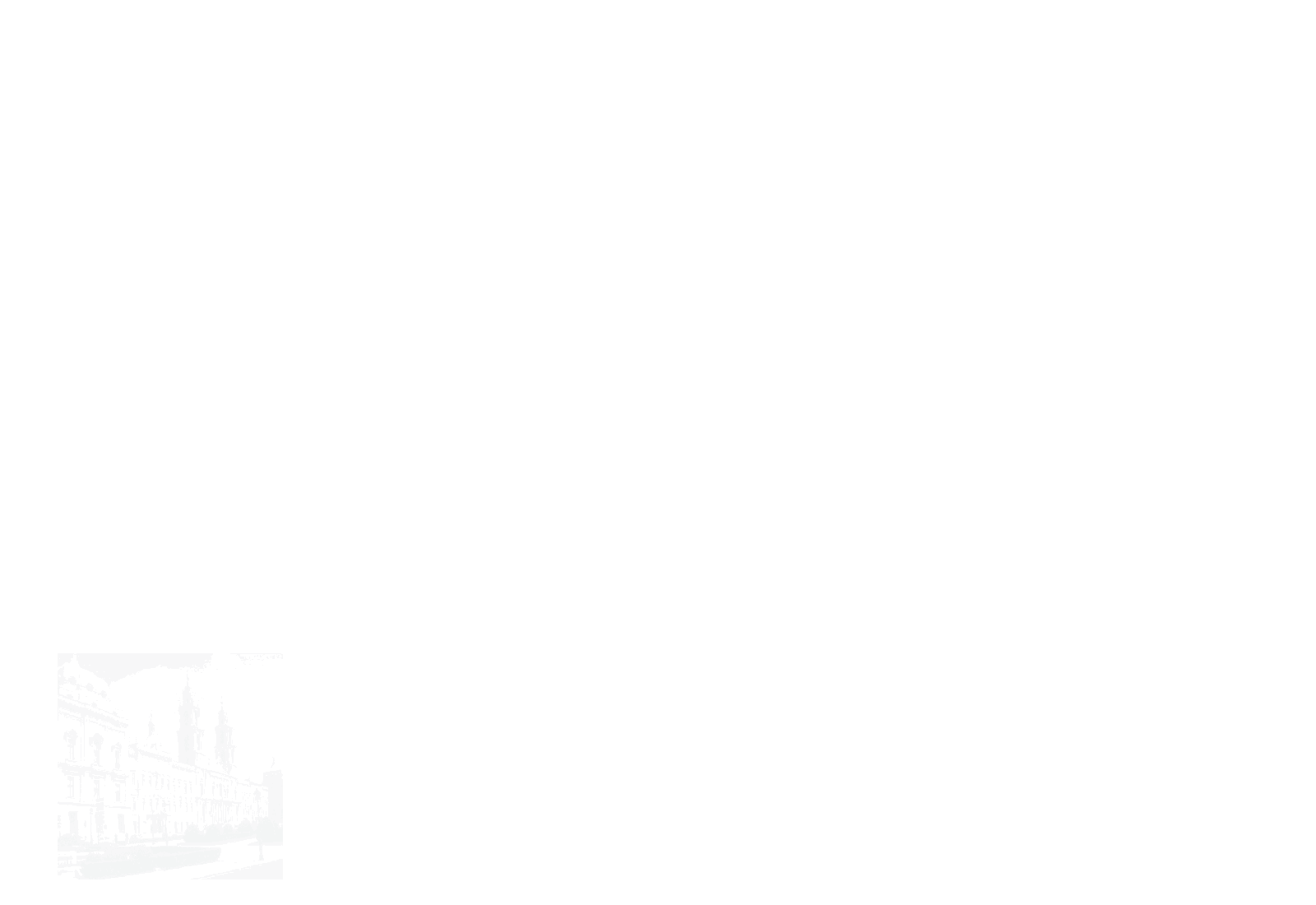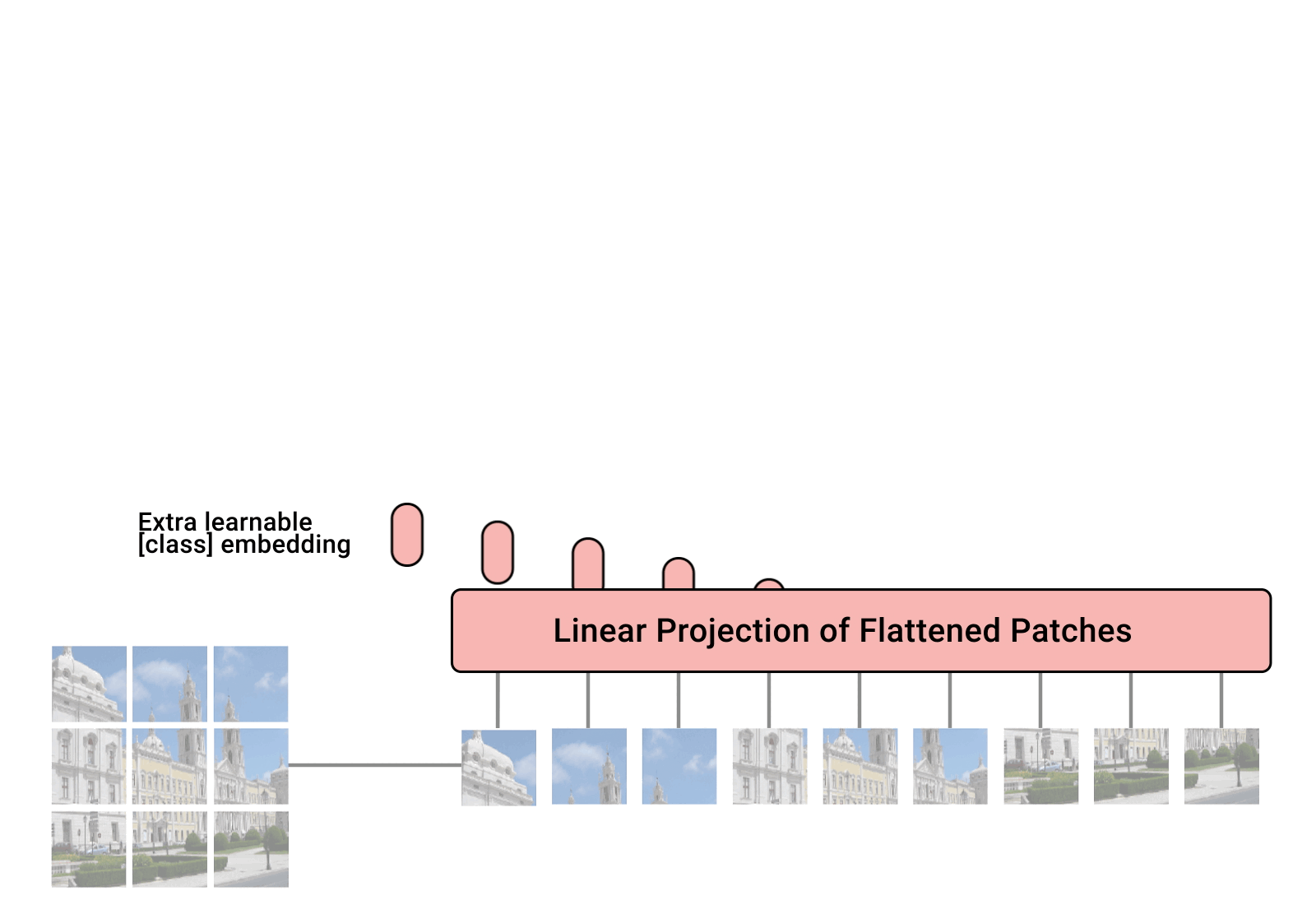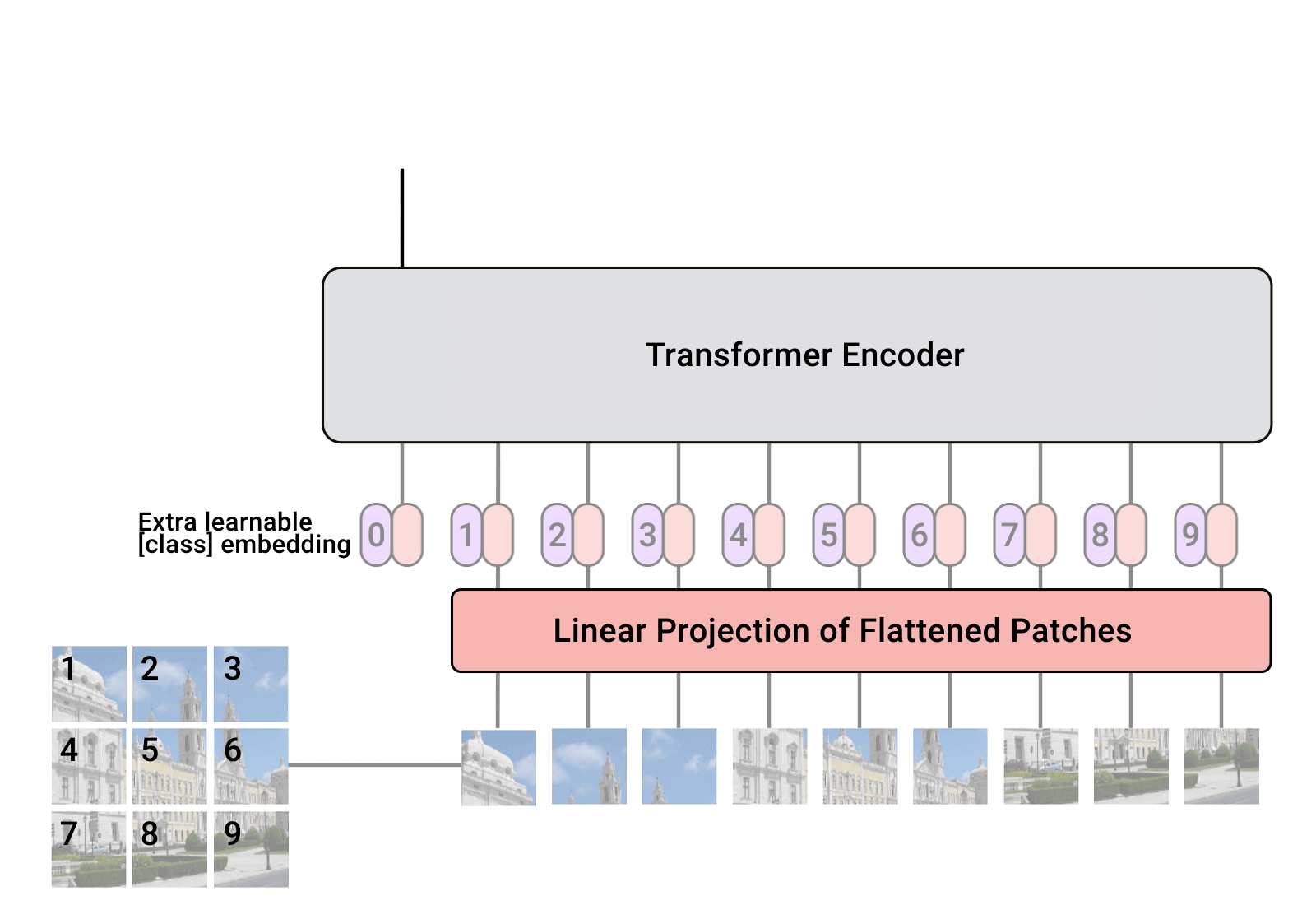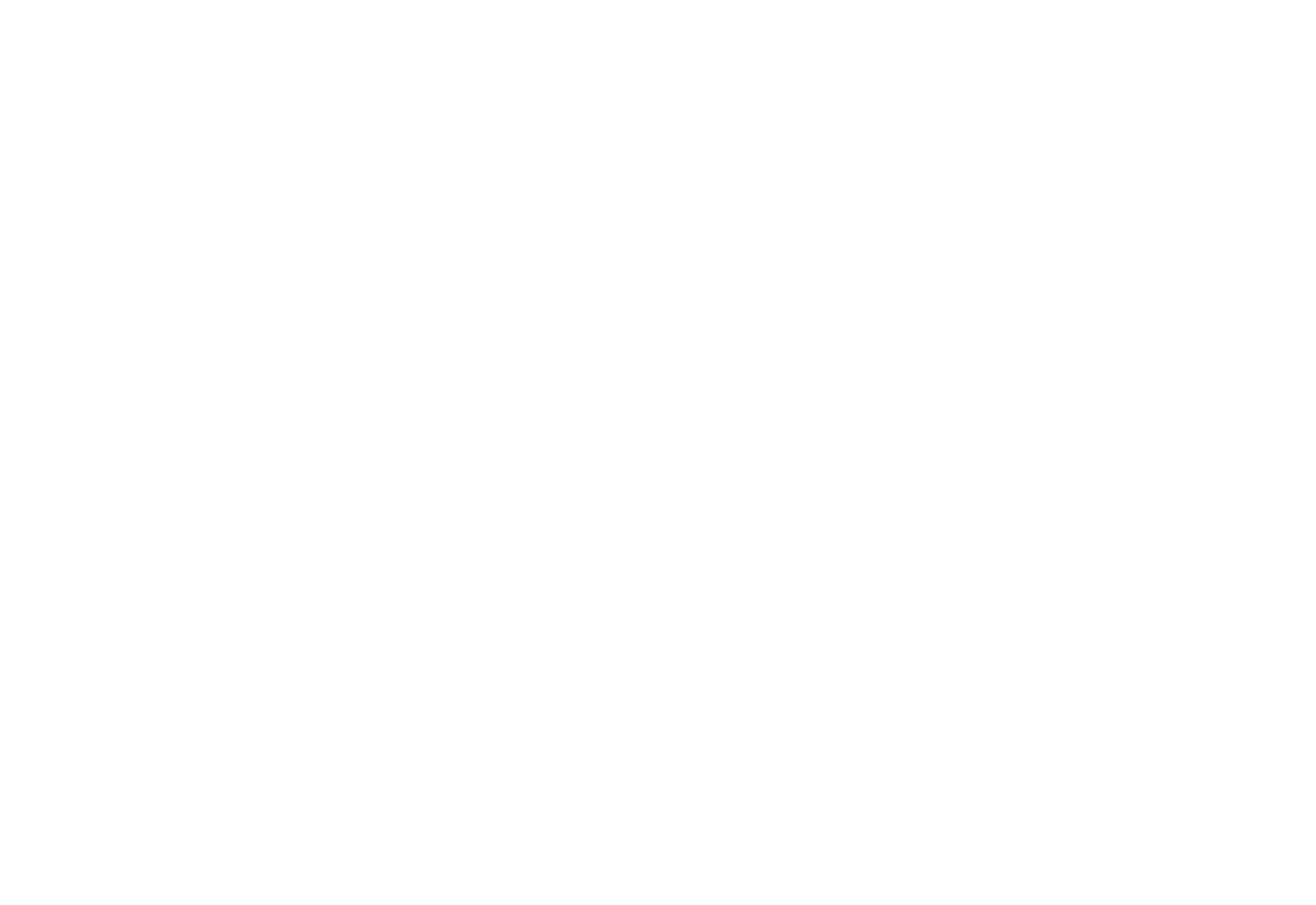
##### 詳細:https://arxiv.org/pdf/2010.11929
----
<font size=6>在這個過程中,Embedded會通過Encoder內部的self attention,取代CNN層去關注eceptive field
</font>
<font size=6>然而我們的輸入是一張圖片轉換過的向量,整個序列的長度比普通文字輸入還要長很多,這就會導致self attention成為整個模型的性能瓶頸</font>

<font size=3>李弘毅:Self-attension:是一種複雜的CNN,會考慮整張圖片,機器自己去學習receptive field的大小</font>
---
### Softmax attention的性能問題
self-attention步驟:
1. 兩個不同向量的q和k內積得到attention matrix
2. 縮小matrix避免softmax結果只有0和1
3. 通過softmax
4. 與V相乘得到q與v的相似度

----
* Q,K,V都是N\*D的矩陣,N=token數,D=channel維度
* Q必須先乘以K,$QK^T$就會變成N*N,整體複雜度來到$O(N^2d)$
* Vision transformer的N一定會大於D
* 如果能拿掉softmax,就可以利用結合律先算${K^t}\times{V}$
$Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V$

---
### Linear attention的優缺點
self-attention就是以qk為權重對v做加權平均,把公式一般化,可以寫成
<br>
$\sum_{j=1}^{n}\frac{sim(q_i,k_j)}{\sum_{j=1}^{n}sim(q_i,k_j)}V_j$
<br>
* sim代表一般函數
* sim結果不能是負數
<font size=3>詳細:<a herf = "https://arxiv.org/abs/2006.16236">Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention</a>
</font>
----
直接去掉softmax,sim就會變成
$sim(q,k) = qk^t$
為了確保q和k不為負數,必須加上kernal function變成
$sim(q,k) = \phi(q)\phi(k^t)$
----
所以可以把一般化公式改寫成
$\sum_{j=1}^{n}\frac{\phi(q_i)\phi(k_j^t)}{\sum_{j=1}^{n}\phi(q_i)\phi(k_j^t)}V_j$
這樣一來,就可以透過結合律先計算K和V
$\frac{\phi(q_i)(\sum_{j=1}^{n}\phi(k_j^t)V_j)}{\phi(q_i)(\sum_{j=1}^{n}\phi(k_j^t))}$
複雜度$O(N^2)$ ->$O(N)$
----
#### Linear attention的劣勢
因為替換成ReLU,結果變得寬鬆,顯示出來的結果就是顏色特別的淡

----
由於Rank受制於Q和K的d,導致Attention Map上會出現許多相同的排列,多樣性不足
$Rank(\phi(q_i)\phi(k^t)) \le min(Rank(\phi(q),Rank(\phi(k))$
$\le min(N,d)$

---
## 2.Focus Linear Attention Module
根據上面兩個痛點,作者提出了Focus Linear Attention改善,不只精準度比其他Linear attention高,甚至還贏過softmax

----
靠著以下兩點,讓Linear attention在Vision Transformer中可以超越 softmax attention
1. Focused Function:恢復注意力銳利度
2. DWC Module:恢復特徵多樣性
---
### Focused Function:恢復注意力銳利度
原始的一般化Linear attention function長這樣
$Sim(Q_i,K_j) = ϕ_p(Q_i)ϕ_p(K_j)^T$
Efficient Attn:kernel fn使用ReLU,確保non-negetive

##### EfficientViT內的Linear attention架構
----
作者重新設計了Kernal function
$ϕ_p(x)=f_p (ReLU(x))$
$f_p(x)=\frac{∥x∥}{∥x^{∗∗p}∥}x^{∗∗p}$
<br>
* $f_p$就是focus function,讓norm(長度)不變的情況下只改變方向
* $x^{**p}$代表x對p做element-wise power(把每個元素做n次方)
* p是一個超參數,相關數值Experinment會講
* 讓與訓練資料與越相近的query和key更接近
----
#### 根據$f_p$,作者提出了假設,說明如何影響注意力分布
> 給定條件: 兩個向量 $x = (x_1, ..., x_n)$ 和 $y = (y_1, ..., y_n)$,其中所有元素 $x_i$, $y_j$ 都大於等於 0。假設 x 和 y 分別只有一個最大值,分別為 $x_m$ 和 $y_n$。
$∃ p >1, s.t. ⟨ϕp(x),ϕp(y)⟩ > ⟨x,y⟩.$
<br>
斷言:當 m = n 時(即 x 和 y 的最大值在同一個位置),存在一個值 p > 1,使得經過聚焦函數 $ϕ_p$ 映射後的向量內積 $⟨ϕ_p(x), ϕ_p(y)⟩$ 會大於映射前的向量內積 $⟨x, y⟩$
----
$∃ p >1, s.t. ⟨ϕp(x),ϕp(y)⟩ < ⟨x,y⟩.$
<br>
斷言:當 m ≠ n 時(即 x 和 y 的最大值在不同位置),存在一個值 p > 1,使得經過聚焦函數 $ϕ_p$ 映射後的向量內積 $⟨ϕ_p(x), ϕ_p(y)⟩$ 會小於映射前的向量內積 $⟨x, y⟩$。
----
從圖表來看,$f_p$確實讓與query相近的key更加靠近,在attention map上的對比度也變得更尖銳
也就恢復了原本softmax該有的注意力

---
### DWC Module:恢復特徵多樣性
$O = (ϕ(Q)ϕ(K)^T +M_{DWC})V=M_{eq}V$
<br>
* DWC:(Depthwise convolution)輸入資料的每一個Channel都建立一個k\*k的Kernel,其對應的Kernel都各自做卷積。
* 特點:在降低傳統Conv運算量的同時保持差不多的性能
* $M_{DWC}$:完成DWC後的spare matrix,可以到Full rank(捕捉到的特徵更多)
* $M_{eq}$:完整的attention matrix
----
至此,我們可以得到完整的Focus Linear Attention Module
$O=Sim(Q,K)V =ϕ_p(Q)ϕ_p(K)TV +DWC(V)$
---
## 3.Experinment
1. ImageNet-1K分類
2. 使用ADE20K做Semantic Segmentation
3. COCO dataset做物件偵測
4. 與其他Linear attention比較
5. 不同平台上的推理時間
6. 消融實驗
---
### ImageNet-1K分類
* 模型選擇:DeiT、PVT、PVT2、Swin、CSwin
* optimizer:ADAMW(Weight decay=0.05)
* 超參數設置:
* epoch:300
* batch size:1024
* learning rate: 0.001
* Warn up: 20個epoch以後,cosine learning rate 到 0.05
* Trick:用DeiT上的技巧如:RandAugment、Mixup、CutMix、random erasing避免過擬合、EMA給予近期的數據更高的權重
----
#### 實驗結果
在相同的計算量下,增加Focus模組的模型表現會更好(能效比更佳)

---
### 使用ADE20K做Semantic Segmentation
* 骨幹Model:PVT-T、Swin-T/S
* Semantic Segmentation用Model:S-FPN、UperNet
mIOU(真實label面積與預測面積的比值)與mAcc皆有所上升

---
### COCO dataset做物件偵測
* 骨幹Model:ImageNet
* 偵測用Model:MaskR-CNN、CascadeMaskR-CNN
<font size=3>AP皆有上升</font>

<font size=1>
>Average precision,precision和recall畫成圖對應的面積
>$AP$、$AP_{50}$、$AP_{75}$:代表IOU在\[0.5,0.95,0.5]、50、70對應的面積
>$AP_s$、$AP_m$、$AP_l$:代表檢測範圍在小($32^2$)中($32^2~96^2$)大(96^2)
>Schedule:Training Schedule對應的長度
</font>
---
### 與其他Linear attention比較
* 基底Model:DeiT-T、Swin-T
* 預比較Attention:HydraAttn、EfficientAttn、LinearAngularAttn、EnhancedLinearAttn
Focus Linear Attention取得了相比於其他attention更好的成績,作者說甚至超越了softmax attention

---
### 不同平台上的推理時間
* 比較平台:Intel i5-8265U、RTX2080Ti、RTX3090
各平台都有提升,在CPU端的提升更佳明顯,足足有2.1倍

---
### 消融實驗
----
#### $f_p$ 和 DWC
從原始的Linear attention,逐漸加上focus function跟dwc模組,可以發現準確率逐步上升

----
可視化版本

----
#### Focus factor p
就是focus function內$x^{**p}$裡面的$p$,2~32測試下來準確率變化不大,證明抗干擾能力強
其中最好的是$p=3$,論文內的其他測試都是使用這個數值

----
#### Receptive field大小
Swin-T 引入了Sliding window機制讓注意力限制在一個窗口內,隨著窗口大小增加,準確度也在慢慢增加,證明window attention有效,但依然不如global attention

----
#### 在不同階段套用Focus linear attention
替換前兩個階段可以讓準確度提升最多,作者推測是因為 Swin的前兩個階段具有更大的解析度,更適合focus linear attention具有大Receptive field準確度越大的特性

---
## 4.總結
* 通過解決現有linear attention在聚焦能力和特徵多樣性方面的局限性,成功超越softmax
* 大量的實驗表明,作者的模組可以廣泛應用於各種ViT,並在計算效率和模型性能之間取得更好的平衡
---
### 小小心得
這是我碩士生涯第一篇看的論文,剛好抽到了一篇還算簡單好讀的,看到別人paper那個公式真的是完全看不懂(´。_。`)
在整理的時候把power的意思錯誤理解成相乘,講出來後老師也覺得很奇怪,最後還是學長提醒才知道是做次方,好險不用重報
路還很長,試試看把路上看到的東西都記錄下來,如果有哪邊有理解錯誤或可以改進的的也請多多指教(。・∀・)
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet