# Blurred Lines: Does Blurring preserve privacy?
DSAIT4125 - Computer Vision
Authors (Group 11):
- Gabriel Nascarella Hishida do Nascimento (6310931)
- Mayank Thakur (6310362)
- Saloni Saxena (6164579)
- Vaishnav Srinidhi (6211097)
## Introduction
### What's the problem?
Personal privacy has become increasingly critical in the digital age, particularly with the exponential growth of online content and media. This has led to an increased development of facial databases, which has induced fear in the public over what the images can be used for. Therefore, journalists and content creators face a persistent challenge: protecting individuals' identities while maintaining visual context.
The misuse of personal images is a violation of individual autonomy; facial photographs are no longer just visuals but unique identifiers intertwined with personal identity and dignity. As technology increasingly commodifies our likenesses, individuals find themselves vulnerable to unauthorized exploitation, with facial recognition systems, targeted advertising, and invasive data collection stripping away personal agency. The GDPR's strict regulations on biometric data [^RuleBio] highlight the ethical concerns surrounding consent and ownership, underscoring the fundamental right to control one's visual representation.
|  |  |
|------------------------------------------------------|------------------------------------------------------|
> Depiction of common usages of blurring on the in media
On the one hand, gaussian blur is a widely adopted technique for anonymizing faces across various media platforms, from news broadcasts to [YouTube videos](https://www.youtube.com/watch?v=dRFk0_XixKM). By softening facial features rather than completely obscuring them with harsh black boxes, this method offers a more "non-distracting" approach to preserving privacy. On the other hand, facial recognition models have become ubiquitous in today's world, and become more accessible every year. Given the vast amounts of facial data, is there a potential way to leverage them to bypass these obfuscation methods? Can a model learn to identify a face from environment pixels around the blurred face? In other words, do these seemingly elegant solutions truly protect individual identity, or does it merely create an illusion of anonymity?
## Relevant Work
### Face Recognition
Usually, in face recognition, rather than comparing similarities between RGB images, models compare the embeddings of the faces in these images. In 2015, FaceNet[^FaceNet] proposed the use of a Margin Triplet Loss [^Margin] to train models to learn embeddings using three different inputs simultaneously: two of the same person (anchor image and positive image), and one negative instance (different person). The model is trained so that the distance between embeddings of images of the same person is minimized while that between different persons is maximized (See depiction of Triplet Loss in Figure 1).
The baseline model we are comparing against (ArcFace[^ArcFace]) and the SOTA model GhostFaceNet [^GhostFaceNet] are also trained in a similar fashion, using a loss called ArcFace loss (Additive Angular Margin Loss), which is an adaptation of cosine similarity applied to classification cross-entropy loss. It's worth noticing that this loss requires a classification-based learning setup, unlike the embedding-based setup described in this work. For ease of use, we will be using ArcFace as our baseline.
The ArcFace approach works by mapping facial features to a hyperspherical embedding space where the angular distance between face embeddings effectively represents identity similarities. This is achieved through a convolutional neural network (typically ResNet-based) trained with a specialized loss function that maximizes inter-class differences while minimizing intra-class variations.
InsightFace is the actual model we will be using as our baseline. It is a powerful open-source face analysis toolkit that implements multiple advanced deep learning algorithms for face detection, recognition, and analysis. InsightFace uses a two-stage pipeline: first deploying RetinaFace [^retinaface] for accurate face detection, then applying ArcFace [^ArcFace] for face recognition and embedding extraction. Importantly, ArcFace recognition only considers the bounding box and no environment pixels. We will refer to this as tight crop from here onwards.
#### On blurred faces
When considering blurry or low quality faces, there are many works that aim to apply Super Resolution [^SuperResolution] first to help humans identify lower quality images or apply it as preprocessing for face recognition models.
There aren't many works that focus on identifying blurred images directly using two different networks; In 2016, Oh et al. [^Oh] conducted a study on different obfuscation methods and their effects on face recognition using the People in Photo Albums (PIPA) dataset. Oh et al. also hypothesized that facial recognition models can accomplish face verification on obscured faces not because the model generalized beyond the obfuscations but because it found a shortcut around it by learning the environment pixels of each face. That being said, the dataset is not available anymore due to privacy violations [^Exposing] and the algorithms used in the article were not made available.
## Experimental Methodology
The purpose of this project is to test the ability of deep learning models to generalize well to both sharp and blurred images. Formally put, the research question is:
*"Can a model accurately identify two facial images to be of the same person, given that one is obfuscated and the other is not?"*
Simply put, we are asking: given two images of a person, one normal and one obfuscated, to what extent can a facial recognition model verify that it is the same person? Based on the considerations presented by Oh et al. [^Oh], we have to split our research into smaller parts, to ensure that the model is actually learning to generalize beyond facial obfuscation. For the purpose of our research, we will be limiting the studied obfuscations to Gaussian blur, since it is the most commonly used method. Furthermore, we will also be changing the amount of environment pixels to gauge the impact of surrounding pixels on facial verification.
The Labelled Faces in the Wild (LFW) dataset is the most widely used in the literature, and we use it in our study to evaluate:
- Custom models based on a MobileNetV2 [^mobilenet] backbone
- The baseline ArcFace model
To study the generalization of the model, we will:
- Train the model on different amounts of "environment" pixels (the pixels around the bounding box of the face)
- Train and test the model on different levels of Gaussian blur (varying sigma values)
- Test the model on an unseen dataset (The CelebA Dataset)
:::info
All of our code including training and evaluation algorithms can be found in this GitHub repository: https://github.com/V41SH/FLUP-Face-Privacy
:::
We test the effectiveness of all the models on the task of face verification. Different variations of the model are trained, which allow us to see what the model is actually learning. All models are compared to the ArcFace baseline. Now, how do we test these models?
Let's discuss these one by one.
#### The Hypothesis
We believe that it is feasible to train a custom facial verification model that is resistant to facial obfuscation. Furthermore, since current facial recognition models are not trained on obfuscated images, their performance on facial verification should drop as the amount of obfuscation increases.
### Our custom model
To investigate our research question, we decided to take advantage of feature extraction offered by existing CNN architectures. We use the MobileNetV2 model as a backbone, which is based on a highly optimized residual CNN architecture that is relatively small and easier to train compared to competing architectures. Our model consists of two streams, which are trained simultaneously. Each model is a separate module composed by a MobileNetV2 followed by a fully connected layer. The goal of one stream (BlurNet) is to learn the embeddings of blurred faces, reinforced with non-blurred (sharp) faces, and the goal of the other stream (SharpNet) is to learn the embeddings of sharp faces reinforced with blurred images. The goal is to be able to embed the faces into a latent space and find the similarity in their embeddings. Hence the symmetric dual stream approach, which learns the embeddings of both normal and obfuscated images. Ideally, embeddings of the same person (normal and obfuscated) should be "close together" in the latent space.
To this effect, we use a Triplet Margin Loss on BlurNet and SharpNet. The Triplet loss,
$$
L(a_i, p_i, n_i) = \max \{ \| \mathbf{a}_i - \mathbf{p}_i \|_2 - \| \mathbf{a}_i - \mathbf{n}_i \|_2 + \text{margin},\ 0 \},
$$
takes as input the embeddings of an anchor ($a$), a positive ($p$) and a negative ($n$) image. It then tries to minimize the L2 distance ($\| x \|_2$) between the embeddings of the anchor and the positive image, while also trying to maximize the L2 distance between the embeddings of the anchor and the negative image. The margin serves as a hyperparameter, its default value is 1, which is also what we used.
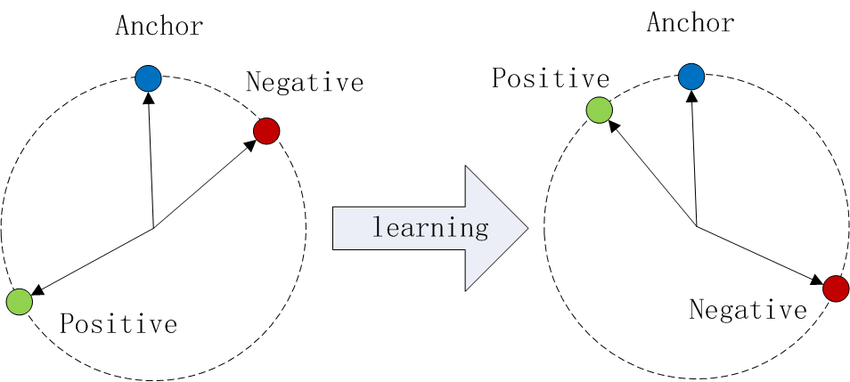
> Figure 1. Triplet loss, visualized. Each point is in a latent space, and the goal of training is to bring the anchor and positive closer together. Source: myscale.com/blog/what-is-triplet-loss/
During training, the anchor and positive images are of the **same** person, while the anchor and negative images are of **different** people. The positive and negative images also have the opposite *effect* to the anchor image. So, for BlurNet, the input is a blurred anchor, a sharp positive (of the same person) and a sharp negative (of a different person). For SharpNet, it is a sharp anchor, a blurred positive (of the same person) and a blurred negative (of a different person).
Therefore, in every epoch, the following operations occur:
- Four images are loaded, two anchor images (one sharp and one blurred) and two positive images (one sharp and one blurred). If an anchor is sharp, its positive is blurred and vice versa.
- Since each anchor needs a negative to complete the triplet, the corresponding negative is the remaining image with the opposite effect to that of the anchor.
- The embeddings are calculated and normalized, followed by a model-specific loss.
- The overall loss is the sum of the losses of BlurNet and SharpNet. This is then used in the backward pass.

> Figure 2. Model architecture. For the Sharp/ Blur components, the inputs (from top to bottom) are the Positive, Anchor, and Negative values for which the model will be trained. The triplet loss is calculated for both components for loss backpropagation.
To evaluate the effects of the two main parameters—blur intensity and amount of surrounding environment—we trained four distinct models:
- **Random Blurring Model**: This first model is trained on images with randomized gaussian blur variances (sigma values) ranging from 5 to 20, while maintaining a constant number of environment pixels. This approach allowed us to isolate and assess the specific impact of varying degrees of blur.

> Figure 3. Depiction of the effects of different Gaussian blur sigma values
- **Random Cropping Model**: This model is trained on images with varying numbers of environmental pixels surrounding the bounding box. We implemented this by identifying the bounding box edge closest to the image border, dividing that distance by the number of cropping steps, and then randomly selecting a cropping distance from these calculated intervals.

> Figure 4. Depiction of the effects of different Cropping levels
- **Random Cropping and Blurring Model**: This model is trained on data that is modified in terms of both the parameters randomly.
- **Tight Cropping and Random Blurring**: This model is trained on facial data cropped completely to the bounding box, with random amounts of gaussian blurring applied. This model leverages the spacial invariance of CNNs to verify faces. Moreover, this model can be fairly compared with ArcFace due to its property of only extracting features from within the bounding box.
<img src="https://hackmd.io/_uploads/S171wrbCJe.png" alt="drawing" width="150" style="display: block; margin: auto;">
>Figure 5. Depiction of tight crop
## Experiments and Results
To test our hypothesis, we perform Face Verification on 1800 pairs of test images. Our experiments involved varying two main parameters: The level of Gaussian blur (through value of sigma) and amount of environment included around the bounding box. Here we discuss the results and findings for the four different models that were trained:
### Effect of obfuscation on baseline and custom models, tested on seen dataset

>Figure 6. Results of all models. Models trained on tight crop (blue), baseline: ArcFace (orange), All surroundings (Random blur model) (green), Random crop and blur (red), Random crop (purple)
In Figure 6, we plot the cosine similarity of all models (baseline + custom) against the Gaussian blur sigma. Note that only 'Tight Crop' and 'ArcFace' can be fairly compared due to each of them embedding only within the bounding box. The other models create embeddings based on other aspects of the image as well, which makes them incomparable to the baseline.
The following observations are made:
- The ArcFace baseline model is unable to preserve similarity between images at higher sigma levels. The similarity drops to ~0 for sigma >= 12.
- "Tight Crop" is able to preserve a decent amount of similarity in embeddings at higher blur. Even at sigma = 24, a similarity of ~0.4 is observed.
- The three models involving surrounding pixels achieve similarity scores above 0.8 at all blur levels.
- "All surroundings" achieves the highest similarity scores in this test.
- The three models involving surrounding pixels seem to be invariant to the amount of blur.
- It is also notable that the same 3 models have a *higher* accuracy than "ArcFace" in the beginning, where there is little to no blur applied to the faces.
### Generalization to unseen dataset

> Figure 7. Results of all models on CelebA Dataset, for same person evaluation. Models trained on tight crop (blue), baseline: ArcFace (orange), All surroundings (Random blur model) (green), Random crop and blur (red), Random crop (purple)
Compared to Figure 6, the performance of all models drop signficantly when applied to an unseen dataset. The following observations are made:
- The "Tight Crop" model is unable to maintain similarity between same people as the amount of blur increases.
- "Tight Crop" *does* outperform the "ArcFace" for higher blur, but the difference in performance is negligible because the model can not accurately distinguish the same person.
- The other models seem to perform similar to before. Their accuracy is lower.
- The other models continue to demonstrate invariance to the blur level and seem to fluctuate in performance almost randomly (yet smoothly).
- The performance of the three models involving surrounding pixels is closer to random, ~0.5.

> Figure 8. Results of all models on CelebA Dataset for different person evaluation. Models trained on tight crop (blue), baseline: ArcFace (orange), All surroundings (Random blur model) (green), Random crop and blur (red), Random crop (purple)
- The three models involving surrounding pixels perform very similarly to the last task, ~0.5.
- "ArcFace" seems to be able to *always* accurately discern different people.
- The comparable model, "Tight Crop" starts off with a decently high accuracy and then *increases* with the amount of blur.
### Black box obfuscation on baseline
Finally, to check how a widely used model like Insightface performs on stronger forms of obfuscation, we evaluated it on complete face blackout.
<img src="https://hackmd.io/_uploads/HJim6HZCyg.png" alt="drawing" width="200" style="display: block; margin: auto;">
>Figure 9. Depiction of black box obfuscation
On complete facial obfuscation, the model could not identify the person at all. With cosine similar either zero or negative (for eg. in this case cosine similarity = -0.0096), the model does not recognize any face. This is due to the implementation of InsightFace where it uses RetinaFace to get a bounding box before embedding it with ArcFace. Since no face is detected in the first place, no embedding can be generated.
## Conclusion and Discusion
Our research reveals that facial blurring, while aesthetically preferable to alternatives like black boxes, may create a false sense of security regarding privacy protection:
- Specially trained models seem to match blurred faces to their unblurred counterparts with surprising accuracy
- Environmental context plays a significant role in identity verification
- The effectiveness of blurring decreases as models become more sophisticated
- Complete obfuscation (black boxes) remain the most effective for preserving privacy
The goal of this research was to determine the possibility of training a model to learn faces despite obfuscation. Through the results (Figure 6), we see that there is *something* that the model learns. However, it does not seem to generalize (Figure 7 and 8). As warned by Oh et al. [^Oh], it seems that the models we trained overfit on the training data and learned shortcuts around the obfuscations. This is made clear by the performance difference "Tight Crop" and the other 3 models we trained. Increasing the amount of non-facial information gives the models more data to overfit onto. Therefore, the latent space created by the models encodes too much information specific to the identities in the training set. This is further exemplified by the fact that the performance drop to ~0.5, which means it's performing as good as random.
"All Surroundings", "Random crop and blur", "Random crop" seem to be independent of the amount of blur that is applied to the face, both on the seen and unseen dataset. The drop in performance for "Tight Crop", and the performance of our models being higher than "ArcFace" altogether suggests that the models are overfitting on the training data. Although "Tight Crop" was supposed to avoid this by *only* training on the facial bounding box, there is background information that the model can learn regardless, since the face usually doesn't entirely fill its bounding box.
In the end, we were able to show that CNN based models do have the capacity to learn faces through obfuscation, but were unable to show that it can generalize to other scenarios or datasets.
## Future Work
We believe our work presents a foundation to build upon in the very relevant area of privacy preservation from deep learning. Future work may include:
- Training a model meant to bypass obfuscation on multiple datasets, to reduce overfitting
- Develop more robust privacy-preserving techniques beyond simple blurring
- Test against a wider range of state-of-the-art facial recognition systems
- Explore the effectiveness of adversarial examples as privacy-preserving techniques
- Investigate the minimum level of obfuscation required for genuine anonymity
- Develop techniques for different types obfuscations such as pixelization, black box, etc.
Last but not least, there is a bias in the custom model that we developed, which stems from the fact that MobileNetV2 is not trained on blurred faces. In our experiementation we found that SharpNet was better able to distinguish people than BlurNet, which is a result of MobileNetV2 being pretrained on facial data, which works for SharpNet, but might require more finetuning for BlurNet. A top down approach to this problem using a 2 stream network can be explored.
## References
[^cnet]: [CNET - Google begins blurring faces in Street VIew](https://www.cnet.com/culture/google-begins-blurring-faces-in-street-view/)
[^towards]: [Towards Data Science - Facial Blurring](https://towardsdatascience.com/unlocking-the-power-of-facial-blurring-in-media-a-comprehensive-exploration-and-model-comparison-261031603513/)
[^FaceNet]: [FaceNet: A Unified Embedding for Face Recognition and Clustering](https://arxiv.org/abs/1503.03832)]
[^Margin]: [MOTS R-CNN: Cosine-margin-triplet loss for multi-object tracking](https://arxiv.org/abs/2102.03512)
[^ArcFace]: [ArcFace Additive Angular Margin Loss for Deep Face Recognition](https://arxiv.org/abs/1801.07698)
[^GhostFaceNet]: [GhostFaceNets: Lightweight Face Recognition Model From Cheap Operations](https://ieeexplore.ieee.org/document/10098610)
[^SuperResolution]: [Face Super-Resolution Using Stochastic Differential Equations](https://raysonlaroca.github.io/papers/santos2022face.pdf)
[^Oh]: [Faceless Person Recognition
Privacy Implications in Social Media](https://arxiv.org/pdf/1607.08438v1)
[^Exposing]: [Exposing.ai: PIPA dataset](https://exposing.ai/pipa/)
[^RuleBio]: [Rules for the use of biometrics](https://www.autoriteitpersoonsgegevens.nl/en/themes/identification/biometrics/rules-for-the-use-of-biometrics)
[^mobilenet]: [MobileNetV2: Inverted Residuals and Linear Bottlenecks](https://arxiv.org/abs/1801.04381)
[^retinaface]: [RetinaFace: Single-stage Dense Face Localisation in the Wild](https://arxiv.org/abs/1905.00641)