# 衍生資料—串流處理
資料隨時都在產生,透過串流處理算出最即時的結果。
[文本於此](https://evan361425.github.io/feedback/designing-data-intensive-applications/derived-stream/)
----
## 串流
串流(stream)是什麼?
note:
串流代表者資料是連續性的而非一次性的傳遞。
> 一開始接觸網路應用程式時,我對於一些檔案(或網路)的輸入輸出函式(例如 [PHP](https://www.php.net/manual/en/stream.contexts.php) 和 [JS](https://developer.mozilla.org/en-US/docs/Web/API/Streams_API))用 stream 很不解,為什麼不用 read/write 就好,幹嘛搞個新名詞。其實用 stream 更能表現出:資料是一點一點傳過去,而非一次性送出。使用 stream 這個名詞能幫助我們更了解其內部實作的內容。過去的疑問總在不經意間得到解答。
----
### 狀態的成形
想像一下銀行是怎麼存資料的?
https://youtu.be/JHGkaShoyNs
note:
當你帳戶有問題打去給銀行時,他們不會告訴你根據我們在資料庫的表格中,你現在的帳戶就是 300 塊,所以沒錯你的帳戶目前就是 300 塊,相反的他們會告訴你你在某一天買了什麼東西花了多少錢,帳戶從多少錢變到多少錢。這種方式並非從電腦時代才開始,而是在很久以前金融業就是這麼做的,以前客服員手上可能會拿著一本帳單,上面不會只有一個數字,而是一連串不同時間的異動(即使該異動本身是錯的)。他們會從中告訴你上一次交易在什麼時候,帳戶從多少錢變到多少錢,然後再依序往上追問題出在哪裡。
這種儲存的方式不是儲存資料**最終的狀態**,而是儲存可以變成現在狀態的所有歷史紀錄。這種「紀錄」,一般稱為**事件**。而一連串的事件就是本次要討論的串流
----
**事件是不變的**
note:
所有的狀態都是事件的累積,我們常使用的資料庫就是儲存這些累積事件後的「狀態」(為了提高讀取的效率)。
不論使用者是否真的做了哪些改變(座位可能因為滿了訂票失敗或者購物車的商品增加後又被移除),這些事件一旦產生都無法被異動(儘管可能因為隱私等原因被迫移除,但哲學上保持不變),相對而言「狀態」卻是常常被改變的,但這兩者是相輔相成的:**我們透過事件產生狀態,再從狀態產生事件**。
很多資料庫應用(例如 MVCC)或者應用程式(例如 Git)背後都有這個概念。
----
- 單一領袖的複製日誌
- 全域順序廣播
note:
我們來簡單提一下再資料庫中使用串流處理的機制。
資料庫的寫入就是事件,想想**單一領袖的複製**,當領袖收到寫入請求時會把請求丟進複製日誌中,然後各個追隨者會追蹤這些複製日誌並根據其中的內容異動資料庫的資料,這些請求就是所謂的「事件」。
我們也有在**全域順序廣播**提到有一群協調者會把全域順序告知給各個節點,達成正確的因果關係,這其中的「順序」就是一種事件,並傳遞給各個節點。
---

note:
從上面的例子中可以看到,我們有了事件就會有獲得該事件的角色和產生該事件的角色,這些角色分別稱為**追蹤者**(consumer, subscriber, recipient)和**發布者**(publisher, sender, producer)。
就好像在批次處理中有一個工作流或程序會把結果輸出成一份檔案,接下來就可以讓其他批次程序把這份檔案當成輸入(或聯合表)進行下一個工作流或程序。對應於串流處理的發布者和追蹤者是一樣的,而這份「檔案」在串流處理中代表著一連串的事件,也就是**串流**或**主題**(topic, stream)。
關聯式資料庫有 `trigger` 這種類似功能,但是這會讓單台資料庫變很複雜,影響其他應該做的事情的效率,且 `trigger` 能做的事也[很有限](https://www1.udel.edu/evelyn/Sybase-02/triggers5.html)。
----
#### 追蹤者主動
定期拉收資料
note:
我們通常可以讓追蹤者定期去和發布者要資料,這樣也能達成所謂的即時資料更新,但是這會讓問題提升到我該多久和發布者要資料?而這問題常常沒有一個好答案,同時當追蹤者變多的時候,發布者會變得很忙,這通常不是個好方法。
----
### 容錯
追蹤者如果在忙或者失能時該怎麼做?
- block
- queue
- backpressure
note:
當追蹤者不能正常運作時有可能是因為:
- 在忙,這時可以做一些手法
- 阻擋(block)後續的請求
- 讓後續的請求排隊(queue)
- 阻擋並告知 _發布者_ 目前在忙(後壓,backpressure),TCP 和 Unix 的管線的都這功能
- 失能,這時做法會根據追蹤者和發布者的關係而有不同
:::info
有些應用允許資料有一點錯(例如 metric 漏掉一兩分鐘的資訊是可被接受的),就不需要嚴謹的容錯。
:::
---
## 如何傳送事件
- 直接傳送
- 中介者
- 日誌型中介者
note:
追蹤者和發布者的關係會影響事件是怎麼傳遞的。
----
### 直接傳送
- SDK/Library
- UDP
- 單一追蹤者
note:
發布者直接把事件送給追蹤者,有幾個特點
- 通常需要 SDK 或程式庫的幫忙
- 通常基於 UDP,避免讓追蹤者影響發布者的回應時間
- 通常不在乎追蹤者的失能,也就是沒有相關容錯機制
- 或者用 TCP 並嘗試重新連線
- 通常只有一個追蹤者,否則很容易影響發布者的複雜度
相關軟體有
- ZeroMQ
- StatsD
- nanomsg
----
### 中介者

note:
發布者把事件送到中介者(broker, queue)
- (根據設定)可調整容錯機制:阻擋、排隊、後壓
- (根據設定)可透過檔案系統維持耐用性(durability)
- 可以納進 [XA](https://evan361425.github.io/feedback/designing-data-intensive-applications/distributed-ft/#xa)
- 有定義一些實作的標準:[JMS](https://www.oracle.com/java/technologies/java-message-service.html)、[AMQP](https://www.amqp.org)
這時我們會把可用性從 *發布者* 移轉到 *中介者* 本身,追蹤者不再關心發布者的存活狀態。這也可以降低發布者的複雜性,因為發布者通常都是一些商務邏輯的應用程式。
當追蹤者失能時可以透過和追蹤者定期的應答(acknowledgment)得知。當收到應答確保追蹤者已經處理完事件後就刪除該事件,反之則反覆傳遞直到完成。
相關軟體有很多
- RabbitMQ
- ActiveMQ
- ...
:::info
就像我們不會在應用程式中寫資料儲存的邏輯,而是把這部分需要考慮的各種問題丟給資料庫,我們一樣會把發布者需要注意到的各種事情丟給中介者處理。
:::
----
和資料庫有什麼差?
- 資料的刪除
- 搜尋
note:
- 資料的刪除上
- 資料庫只有當要求(`DELETE TABLE ...`)時才刪除
- 中介者確保追蹤者接收到事件後就會把事件刪除掉
- 搜尋特定資料
- 資料庫透過索引和次索引來加速搜尋
- 中介者讓追蹤者追蹤多個主題來達成不同資料的獲取
----
中介者的**異步** v.s. 資料庫的**同步**
note:
發布者和追蹤者在處理事件的時機是 *異步* 的,也就是發布者不會等到追蹤者處理完事情後才結束程序。
有可能節點已經完成事件但是回傳訊息時網路出現問題,此時可以透過 [2PC](https://evan361425.github.io/feedback/designing-data-intensive-applications/distributed-ft/#2pc) 這類機制防範。
----

note:
事件的傳遞分成兩種,要麻為了降低延時而透過 *負載平衡* 的機制傳遞給多個追蹤者,要麻為了讓追蹤者可以高可用而使用扇出(fan-out)機制。
有點像是 *分區* 和 *複製* 的概念。
----

note:
可能造成失序,所以建議使用負載平衡時用來處理順序不重要的主題。
----
**復用性...?**
note:
批次處理有復用性:我可以執行任意次計算都不用擔心資料的損壞(因為不異動輸入)。當我消化完一個事件後,中介者就會把資料刪除,這時想再重新算一次就沒辦法了。
這也造成當有新的追蹤者進來時不能看到以前的東西。
---
### 日誌型中介者
note:
因為無法復用,新型態的中介者就誕生了:日誌型中介者,可能的軟體有:
- Apache Kafka
- Apache DistributedLog
----
`tail -f` v.s. 日誌型中介者
note:
還記得 GNU Coreutils 嗎?其中有個 `tail` 的函式,他允許你查看資料的尾部,當加上 `-f` 時,就可以持續追蹤,這概念和日誌型中介者很像:你可以持續追蹤該主題,但是資料不會被刪除。所以所有新來的追蹤者都可以從新開始處理事件。
事實上日誌型中介者就是這樣處理的,每次事件進來就先丟進日誌中然後再傳給追蹤者。當追蹤者要使用事件時,他可以任意處理而不需擔心事件之後會被銷毀,這樣的容錯機制就好像批次處理一樣。
因為追蹤者和事件的關係解耦了,所以需要注意的東西減少了。傳統的中介者會等到所有追蹤者都收到事件才刪除該事件,如果追蹤者失能(或下線)了就需要謹慎的設定避免中介者為了容錯貯存過多事件進記憶體,這時日誌型中介者就可以起到很好的維運優勢。
----
#### 保存多久?
note:
就像排序字串表一樣,日誌是有最大限制的,當一本日誌達到該值時,則重新開一本日誌並附加事件上去。並依據設定限制最多日誌數,當超過時就刪除最舊的日誌,這就代表如果一個追蹤者落後太多,他有可能遺漏那些過久的資訊。
但是一般實際使用通常都會貯存大約數天至數禮拜的資料(以 6TB 的容量來算),在這段時間,讓維運人員重啟追蹤者是足夠的。你也可以透過一些警報系統幫助你追蹤這些落後的進度。
----
#### 優勢
- 延時穩定
- 批次傳遞
- 追蹤者的解耦
note:
延時是穩定的,因為傳統的中介者會把資料存進記憶體,當一直有事件沒被消化導致記憶體不夠了就會落檔,所以中介者處理事件的延時就很大一部份受到現有事件的量影響;相對而言日誌型的中介者就可以做到較穩定的延時,因為都是把事件附加進日誌中。
不再需要定期接收應答來確認是否接收到事件,而是定期儲存 *偏移量*,當追蹤者失能並復原時就可以從上次儲存的偏移量來重新傳送事件。
因為上述機制(不需要確認是否收到)讓他可以進行批次的傳送而不需要一個一個傳送,再加上連線的管線機制,提升他的通量。如果是傳統中介者,因為需要同時和多個追蹤者確認是否執行過該事件,所以無法像這樣批次處理。
----

note:
分區之後就可以避免中介者的單一節點過度操勞,使用複製讓多個節點擁有資料則可以提高可用性。至於前面提的 _偏移量_,在分區之後一樣可以在各個分區中記錄偏移量。
當為了降低追蹤者的負載使用輪流(前面的 load-balacne)傳送事件時,我們可以透過不同追蹤者追蹤不同分區來達成(如果用傳統中介者的方式就會遇到亂序的問題),但是這會讓追蹤者的數量受限於分區數量。除此之外,當有一個節點執行緩慢時就會讓中介者等待分區中後續的事件被傳送出去(傳統的中介者可以交替傳遞給不同追蹤者,雖然這也是造成亂序的原因),根據應用程式的不同這可能是不被接受的。
總而言之,日誌型中介者適合高通量低運算;反之,傳統中介者適合低通量高運算且順序並不重要的資料模式。
----
#### 原古時代的事件
快照 v.s. 日誌緊壓
note:
當事件越來越多的時候,我們可以透過快照機制來避免每次資料重建都要從原古時代開始,而是從最後一次的快照建立。
除了快照這方法之外,我們可以運用在[排序字串表](https://evan361425.github.io/feedback/designing-data-intensive-applications/foundation-index/#排序字串表)中學到的,定期在背景中把事件壓縮起來(log compaction),例如對同一個值得異動只保留最新的:
```
key=123, value=321
key=123, value=456
# 以上都刪除
key=123, value=789
```
至於要用哪種方式則根據資料的特徵,若資料異動(update)頻繁,如果使用 _日誌緊壓_ 會讓背景執行過多的緊壓導致壓迫執行速度。相對而言,若資料本身大部分都是新增,這樣就很適合使用 _日誌緊壓_。
----
刪除事件
note:
事件有時面臨必須刪除的狀況,例如公司政策、隱私權、安全性等等,這時就會發現刪除事件其實很困難。你有很多追蹤者,不管在硬體或軟體上又有很多備份機制,到後面你會發現刪除資料不代表讓資料不見,而是讓資料更難被找到。
---
## 同步問題

note:
我們說明了串流是什麼,也說明該怎麼傳遞事件,但還沒說串流會造成的一些問題。
現實生活中應用程式會有多種資料系統,主要的資料庫負責 OLTP、用來加速讀取的快取、用來提供使用者搜尋的全文檢索等等。但是如果資料庫更新的時候,我要怎麼讓這些衍生資料也跟著更新?你可能覺得透過應用程式或主要資料庫來更新就可以,但是會有競賽狀況,如上圖。
這種並行處理的問題我們在談[處理競賽狀況](https://evan361425.github.io/feedback/designing-data-intensive-applications/foundation-ft/)時就提過很多,當牽涉到異質的應用程式(資料庫和快取和全文檢索)間的同步時就更困難。
----
- WAL
- 邏輯日誌(Logic log)
note:
串流處理可以怎麼解決這問題?
每次資料庫異動時,都會更新 [WAL](https://evan361425.github.io/feedback/designing-data-intensive-applications/foundation-index/#如何增加穩定度) 或[邏輯日誌](https://evan361425.github.io/feedback/designing-data-intensive-applications/distributed-replication/#複製日誌),問題是這些資訊通常都是僅限於相同的資料庫叢集中,我們沒辦法透過 API 等公開介面得到這些資料,但如果可以呢?
----

note:
CDC(Change data capture)就是這樣的一個概念。
和前面提的一些 ETL 很像,但是差異在於這裡是透過 *WAL/邏輯日誌* 並串流出資料而非批次。這時上面的全文索引或資料倉儲就變成所謂的「衍生資料系統」。除此之外,如果透過 *WAL/邏輯日誌* 串流這些變化,就不用擔心順序的問題,因為他已經在日誌中做好順序的排定了。
----
複製延遲
- 讀你寫的資料
- 單調讀取
- ...
note:
因為 CDC 是異步的,所以資料庫不會等到確認接收方確實收到才繼續做事,所以所有可能發生於[複製延遲](https://evan361425.github.io/feedback/designing-data-intensive-applications/distributed-partition/#複製延遲)的狀況都可能發生。
----
```sql title="VoltDB 用來監聽特定表的異動語法"
CREATE TABLE products EXPORT TO TARGET offsiteprod
ON INSERT, UPDATE, DELETE
[ ... ];
```
note:
資料庫的外掛工具允許 CDC
- PostgreSQL - Bottled Water
- MySQL - Maxwell
- MongoDB - Mongoriver
- Oracle - GoldenGate
- [Kafka Connect](https://kafka.apache.org/documentation.html#connect)
- [Spinal Tap](https://github.com/airbnb/SpinalTap)
- [Debezium](https://github.com/debezium/debezium)
有些甚至支援當特定值被異動時輸出事件:
- RethinkDB, Firebase, CouchDB
- MongoDB - Meteor
- VoltDB
----
| 事件來源 | CDC |
| ------ | ---- |
| 抽象 | 資料 |
| 哲學 | 工具 |
| 快照 | 壓緊 |
note:
事件來源(Event Sourcing,Domain-Driven Design 社群的用詞)和 CDC 很像,都是傳遞事件給需要使用的人,但是不像 CDC 是監聽每次資料庫寫入請求(在日誌層級中)並把該資訊轉成通用的格式給外部追蹤者,事件來源更傾向於把事件以抽象的方式呈現。
例如當學生在網頁上點擊退出選修課程時,事件來源的設計就會紀錄該事件「學生A 退出 課程B」,這時可能會有一個應用程式監聽事件並執行移除 學生A 的個人課程資訊和學分統計,有一個應用程式監聽事件並讓正在排隊選修 課程B 的學生B成功選修該課程。
上述用法可能同樣用於 CDC 只是不那麼抽象,例如:`id=A;class=null`。除此之外,這兩個出發點並不一樣,CDC 目的在於開放資料庫內部的異動資料,且資訊可能很細;反之事件來源是一種哲學,傾向於把資料抽象化並讓任一種目的(Domain-Driver 的由來)的應用程式去執行他該做的事。
由此,CDC 通常可以做到壓緊日誌(限制相同 key 的異動的日誌數量),但是事件來源傾向於建立快照(雖然根據其哲學不應該建立快照,因為所有快照都是基於某種「邏輯」而非原始資料本身)。
---
note:
透過全部的事件,我可以重新建構一個新的視野,就好像批次處理一樣。根據你的商務邏輯和需求,不再需要透過複雜的前後相容的機制來更新你的綱目,而是完全重新建立起新的資料面貌。
例如 [Druid](https://github.com/apache/druid/) 透過 Kafka(日誌型中介者)貯存的事件可以根據需求客制資料面貌。這種根據需求建立面貌的概念稱為 Command Query Responsibility Segregation(CQRS)。
----
是否正規化不再有意義
note:
如果有對資料庫較熟的,可能就知道常常會在要不要正規化(normalization)時做很多爭辯討論,但是如果透過這方法,要不要正規化就顯得沒那麼有意義了,因為所有資料都是去正規化,但又透過追蹤機制(fan-out)維持正規化。
:::info
通常去正規化的用意在加速讀取速度,正規化的用意在減少寫入時的複雜度。網路上有很多資料庫該不該正規化的爭論,不過我個人是傾向於去正規化。
:::
----

note:
前面提到如果一個寫入請求會同時異動很多資料(例如多個關聯式的表)時,這時在做一致性和原子性就會相對複雜,但是如果透過事件來源的方式,多個資料的異動(例如前面提的學生退選課程)在抽象層面上其實只是一個事件,也就是附加一行資料到日誌中。這樣做起來就很單純了,讓不同追蹤者處理不同表的計算就可以輕易達到原子性,然後多個相同並行事件因為是單一事件所以不會有多個異動相互交叉,就很輕易可以達成一致性。
---
## 串流處理
- 應用
- 時間問題、如何聯合
- 容錯
note:
串流處理和批次處理理念一樣:每個程序(job, operator)做自己的事,透過多個程序的協作製作出複雜的應用。前面講的都是單一處理方式,例如快取,我們還沒提到像批次處理那樣可以多個程序傳遞的機制,還有這之中會遇到的一些問題。
適用於批次處理的 _分區_ 和 _平行處理_ 在串流處理中都是一樣的機制,差別在於批次處理是處理一段資料,也就是這個資料大小是受限的,當運算到一半的時候節點失能時就可以重新運算,但是在串流處理時資料是無限的。一個運行了好幾個月的結果,我們不可能說重算就重算,必須要有方式處理。
----
### 哪些應用
- 篩選特定事件
- 整合事件分析
- 建立新觀點
note:
建立新觀點前面有提過,這裡就放在一起回顧一下。前面兩個通常是需要在特定範圍內的資料,但是建立新觀點通常需要從原古時代的資料才能建立正確的觀點。
----
複合事件處理(CEP)
```cep title="example in CEL"
select *
from MeasurementCreated e
where getNumber(e, "c8y_Temperature.T.value") > 100
```
note:
很像 Regular Expression,CEP(Complex Event Processing)就是一種篩選特定事件的工具,自 1990 發展至今,有像 SQL 那樣抽象的語法(如 [CEL](https://cumulocity.com/guides/event-language/event-language-introduction/#using-cel))也有 GUI 工具。
不像其他資料庫把資料存起來,然後讓外部輸入搜尋語法來,這種模式會讓這個處理變成把語法存起來,然後讓外部輸入資料。有時讓每個資料都過這個搜尋會降低整體的速度,所以有時候會先經過 *索引* 再跑篩選,例如 Elasticsearch 的 [percolate](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-percolate-query.html)。
可能的應用有:
- 金融公司監控信用卡狀況
- 自動化工廠檢查
可能的軟體有:
- [Apache Samza](https://samza.apache.org/learn/documentation/1.6.0/api/high-level-api.html)
- [Apache Flink](https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/try-flink/datastream/)
- [Esper](https://www.espertech.com/esper/esper-documentation/)
- [IBM InfoSpher Stream](https://community.ibm.com/community/user/cloudpakfordata/viewdocument/streams-is-joining-the-cloud-pak-fo)
- ...
----

note:
不像 CEP 這種篩選特定事件的,也可能是在特定區間內整合多個事件並輸出成需要的結果。這裡需要注意的是要怎麼訂定特定區間?這個我們會在後面提串流處理的問題時討論。
有時候為了減少運算或儲存資源會透過一些機率運算(例如[基數估計](https://docs.microsoft.com/zh-tw/sql/relational-databases/performance/cardinality-estimation-sql-server?view=sql-server-ver15))導致輸出的結果和真實結果有些微差異,不過這並不是因為串流處理天生的環境,而是犧牲準確性換取效能,這也可能是很多人會認為串流處理的結果通常不準的謬誤來源。
可能的軟體有:
- Apache Flink([Apache Storm](https://stackoverflow.com/a/30719138/12089368))
- Spark Streaming
- Samza
- Kafka
---
### 哪些問題
- 時間
- 該選哪個時間?
- 什麼是五分鐘內的資料?
- 聯合
----
#### 該選哪個時間?

note:
如果使用程序執行當下的時間就會因為傳遞延遲而出現誤差,反過來說有時從使用者送來的事件和準確事件發生的時間差很多,例如手機連到 Wifi 後才會把事件送給伺服器。但是如果使用使用者裝置當下的時間,就很容易受到使用者手動改時間造成的誤差,所以選擇哪個時間是需要根據應用程式去討論的。
不過上述狀況通常會有其他解法:紀錄三個時間,分別是事件發生時裝置當下的時間,事件送出時裝置當下的時間,後端伺服器收到事件當下的時間。透過伺服器的時間和事件送出的時間來計算裝置和伺服器的時間差,得知事件發生時的真正時間。
----
#### 時間窗
- 落後的事件該怎麼處理?
- 時間窗的選擇
note:
在選擇時間窗的實作前我們需要選時距(每五分鐘統計一次還是每分鐘),但無論哪中實作都會有落後事件的情況,例如統計每分鐘的請求數時我該怎麼決定這分鐘(例如 09:30 的這分鐘)的統計已經結束了?有可能請求發生在 09:30.999,但是送過來時已經 09:31.1,這時這個請求就被放在 31 分而失去準度。這時我們可以 **忽略** 或者 **發布修正**(通常需要讓程序紀錄上一個值)。
有幾種時間窗:
- 翻轉時間窗(Tumbling window),例如每 5 分鐘統計一次:`0930-0935`、`0935~0940`、...。
- 跳躍時間窗(Hopping window),例如每 1+5+1 分鐘統計一次:`0930~0937`、`0936~0943`、...。
- 滑動時間窗(Sliding window),例如五分內最大、小的時間:`0930~0935` 中最早的事件是 `09:31:11` 最晚的是 `09:34:44` 這時窗格就是 `09:31:11~09:34:44`。
- 會談時間窗(Session window),例如擁有某編號的事件的區間,通常用於追蹤使用者的操作。
---
#### 聯合
- **兩組主題**的聯合
- **動態表和主題**的聯合
- **動態表和動態表**的聯合
note:
批次處理就有在處理聯合了,但是串流處理的資料是持續不斷的,在面對聯合(join)時就需要更謹慎的方法來處理。
----
廣告點擊時差:$點擊時間 - 推播時間$
note:
想像一下廣告點擊時差的計算:$點擊時間 - 推播時間$,透過一些 session 機制(例如 cookie)我們知道這兩個事件來源於同一個使用者就可以做這樣的計算,這時追蹤者就需要同時追蹤這兩個主題,並記錄其中一個主題(以本例來說就是 _點擊事件_),當 _推播時間_ 有和儲存的 _點擊事件_ 有相同的使用者編號就可以輸出廣告點擊時差這個事件。當然儲存的量是需要限制的,例如僅記錄一小時內。
----
使用者行為:*使用者編號* 聯合 *使用者資訊*
note:
在批次處理中,*使用者資訊* 只需要考慮開始計算時的那一瞬間即可,因為 *使用者行為* 的資料也只有那瞬間的資訊。但是在串流處理中 *使用者行為* 是即時的資料,例如早上 *使用者123* 綽號叫「小明」,到了下午卻改成「大明」,所以這個要聯合的表是 **動態表**,會隨著時間異動,而動態表的由來就是前面提的 CDC。
這有點像是前面的追蹤兩個主題,只是其中一個主題需要整合成「狀態」
----
Twitter:*朋友發文* 聯合 *使用者主頁*
note:
如果每次使用者刷新主頁都透過傳統關聯式資料庫去聯合會大大影響效能,這時就可以考慮使用串流處理。做法就會是當朋友發文時,更新所有追蹤他的人的主頁資訊,然後再讓外部應用程式去取得這個程序輸出的主頁資訊。這個程序就需要透過兩個主題(分別是 _朋友發文_ 和 _使用者主頁_)紀錄兩個「狀態」。
----
聯合時資料已經過期?
note:
有時候在聯合的時候資料已經過期,例如購物商城在結帳時會加上國家的稅率,而這個稅率是結帳瞬間(或者說當天)的稅率,如果過了幾天某國的稅率更新時,在後台統計那一天的營收時就會有錯,所以這種會變動的值(slowly changing dimension, SCD)就不能直接改 key-value 的值,而是要再注入一個新的紀錄並賦予新的編號避免資訊遺失,例如 SQL 的:
```sql title="注入新的值而非異動舊值"
INSERT dim_tax (country, tax, date) VALUES
('Taiwan', 10, '2000-01-01'),
('Taiwan', 15, '2009-01-01');
```
---
### 容錯
- Microbatching/Checkpoint
- 冪等
- 重建狀態
note:
批次處理的容錯是透過每次結果輸出到 HDFS 中,在下次運算時重新拿上一個程序的結果就可以了,而不需要全部重算,但是串流處理呢?
Apache Spark 使用 Microbatching 的方式,也就是把串流處理當成小的批次處理,所以每次小的批次處理做完都可以寫一些備份檔案。但這也代表時間窗天生就只能使用 *翻轉時間窗*。相對而言 Apache Flink 透過定期建立檢查點的機制,雖然和 Microbatching 很像,但是不受限選擇的時間窗。
還有一個重點是要讓運算是冪等的(idempotent),也就是每次運算相同事件的結果都要一樣,這就代表運算中不能夾帶時間或隨機性,這時就要讓事件中夾帶這些值。就算沒辦法避免(例如 `x=x+1`)我們也可以紀錄事件的編號(以日誌型中介者為例就是偏移量)來避免重新運算。
至於重建狀態前面就有提了,需要有機制避免從開天闢地的時候重來,透過[壓緊日誌](https://www.ververica.com/blog/high-throughput-low-latency-and-exactly-once-stream-processing-with-apache-flink)、[建立額外備份主題](https://softwaremill.com/kafka-streams-how-does-it-fit-stream-landscape/)、[快照進 HDFS](http://arxiv.org/abs/1506.08603)、多幾個做一樣事的追蹤者等等。
:::success
有一些[論文](https://dspace.mit.edu/bitstream/handle/1721.1/133983/3407790.3407808.pdf?sequence=2&isAllowed=y)在討論如何讓非冪等計算變成冪等
:::
---
## 結論
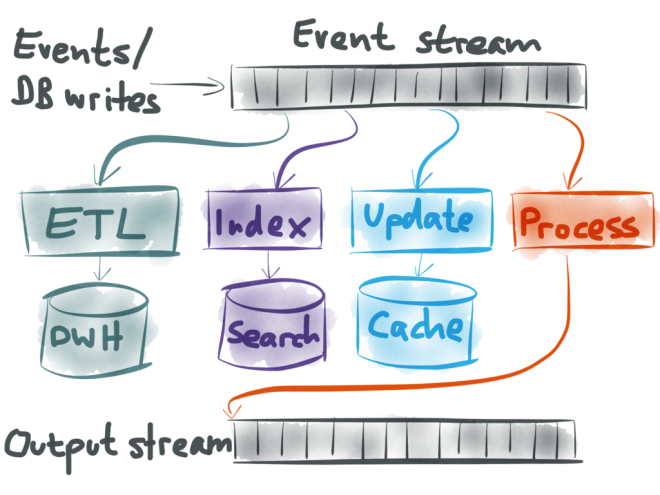
note:
事件來源的概念貫穿本章節,透過和以往「維持狀態」的概念不同事件來源賦予資料成為一種「面向」而非狀態。對於事件等等機制想要深入,可以推薦[此文章](https://www.confluent.io/blog/making-sense-of-stream-processing/)。
{"metaMigratedAt":"2023-06-16T21:41:13.242Z","metaMigratedFrom":"YAML","title":"衍生資料—串流處理","breaks":true,"description":"資料隨時都在產生,透過串流處理算出最即時的結果。","contributors":"[{\"id\":\"c945b58d-6d0e-4680-a2c3-b297ba669e68\",\"add\":22058,\"del\":7574}]"}