# 編碼與演進
資料庫以何種形式儲存資料並適應演進。
[文本於此](https://evan361425.github.io/feedback/designing-data-intensive-applications/foundation-encode/)
----

----
**什麼是演進**
- 向前相容(forward compatible)
- 向後相容(backward compatible)
note:
當你的綱目從 *user\_name* 演進到 *user\_first\_name* 和 *user\_last\_name* 時:
- 如果舊的應用程式(以為資料庫只有 *user\_name*)仍可以運行,我們稱為向前相容(舊綱目可以辨識新綱目所寫的資料)
- 反之,新的應用程式(有 *user\_first\_name* 和 *user\_last\_name*)在讀舊資料(只有 *user\_name* 的資料)時仍可以運行,我們稱為向後相容(新綱目可以讀舊綱目所寫的資料)
在實際應用程式中,我們通常都透過邏輯判斷(`if data.name exist ...`)做這件事情,但是資料庫要怎麼做?
難道他要在每次綱目更新的時候,把所有資料庫裡的資料重新編寫過一遍嗎?這時好的編寫方式就很重要了
----
**什麼是編碼(encode)**
```javascript
function encoder(fileName, data) {
// JSON 就是一種編碼方式
const content = JSON.stringify(data);
return writeFile(fileName, content);
}
```
note:
編碼是為了把記憶體的資料(各種形式,list、object、...)轉進磁碟中(一堆 bytes)。
> 編碼通常還會有另外一個名字:serialization,但是他會和我們後面在談的競賽狀況名詞重疊,所以這裡都稱為 encode
----
好的編碼方式可以提升
- 壓縮(compress)
- 效能(performance)
- 相容性(compatibility)
---
## 編碼
- 編碼方式
- 程式語言預設
- 跨語言
- 二進位
- 使用場景
note:
大綱,先來談談編碼方式,再談使用場景
----
### 程式語言
- 方便簡單
- 低通用性
- 低安全性
- 低相容性
- 低效率
note:
程式語言是被建立於可以讓使用者在程式中快速方便的使用,因此就會有下列的問題。
- 通常不同語言之間是無法互相接通的,例如 PHP 和 JAVA 的編碼方式不同。
- 可能會觸發物件的建置,有安全性疑慮
- 並非以「前後相容」為設計核心,所以很難有相容性的效果
- 效率通常很差
----
### 跨語言
- XML
- JSON
- CSV
note:
這種通常都是人類看得懂的格式(雖然這形容詞很有爭議),相形之下二進位需要讓機器經過轉換和綱目才看得懂,所以這種編碼方式在除錯的時候很方便。
他們有些各自的缺點:
- XML:內容太細,所以很龐大
- CSV:不支援樹狀結構。雖然有規範應該怎麼逸出(escape)逗號等等,但是不同套件的實作不一定都會遵守
除此之外也有些共有的缺點,如下。
----
#### 一些問題
- 字串 v.s. 數字
- 大數字
- 二進位字串
- base64 的體積問題
- 沒有綱目
note:
- 以 CSV 為例,字串和數字是區分不出來的
- JSON 不支援超過 $2^{53}$ 的數字
- 例如 [Twitter 的 ID](https://developer.twitter.com/en/docs/twitter-ids) 因超過這個數字,所以其在輸出 JSON 格式資料時除了有數字的欄位外,還需要有以字串表示其 ID 的欄位。
- 有些資料是以二進位方式儲存的,然而這些編碼方式並沒有相關規範說明如何儲存二進位。
- 有些可能是用 base64,但他會增加 $\frac{1}{4}$ 的體積。
- 沒有綱目會增加維運的負擔,雖然現在有很好用的工具去幫你管理 JSON 的格式,例如 [OpenAPI](https://swagger.io/specification/),但是
- 有學習門檻
- 程式碼和文件的對齊(隨然有工具幫忙,但這些都不是天生的,有時候會有些限制)
- 程式碼要有前後相容的邏輯
----
### 產生程式碼

note:
有綱目就可以透過其產生*強型別*的程式碼。上圖是以 GraphQL 的 GUILD 為例。
在使用需要編譯的語言(Java、C++)時,可以利用綱目去產生相應物件的程式碼(code generation),幫助**編譯**時的型別判定。
例如關於「人」的綱目,就可以根據綱目建立對應的物件,並且配合綱目產生物件的屬性:
```java
var person = new Person(object);
print(person.name);
```
> 相對而言腳本型的語言(JavaScript、Python、Ruby、PHP),雖然不需要產生程式碼來幫助編譯,但自動產生的程式碼還是可以減少自己寫邏輯判斷的時間(和可能的小 bug)。
如果資料是動態調整綱目(例如每個檔案都有自己的綱目在檔案前綴中)時,這樣的機制就不好設計。
----
### 小結
**好用** v.s. **常用**
note:
上述編碼方式都常被使用,他也有一定的好處,但是都不是針對資料庫而去設計的。當資料量大時,額外浪費的編碼體積就會被放大。效能亦如是。
除此之外,實務上也經常發現文件和實際產物沒有對齊。
後面提到的 RPC 也是現在 Google/Facebook 內部服務間溝通時採用的方式,他可以透過工具和其定義的規範、綱目幫助不同服務溝通時自動解析其內容,而不是每次更新都重新編寫相關邏輯判斷。
也許對於一家企業來說,最好的編碼方式就是大家找個最小公約數的編碼方式,並一起使用,減少額外的功去把各種編碼方式轉來轉去。
---
## 二進位編碼
- 壓縮
- 效能
- 相容性
- 不易閱讀
note:
前面談了一些常見的編碼方式和其如何應對演進,現在我們就來談談以二進位做編碼的演算法。
我們也將會看到他怎麼天生去適應綱目的演進,減少開發者要去考慮這些東西的機會進而減少錯誤的發生。
----
### 與二進位的整合
- JSON : MessagePack, BSON, BJSON, UBJSON, BISON, Smile, ...
- XML : WBXML, Fast Infoset, ...
note:
我們先看看有哪些以 JSON 為基礎的二進位編碼,並說明一下他沒辦法滿足我們哪些事情。
----
**範例**
```json=
{
"userName": "Martin",
"favoriteNumber": 1337,
"interests": [
"daydreaming",
"hacking"
]
}
```
note:
資料範例,114 bytes
----

note:
實際效能請實際做負載測試,因為 JSON 的 parsing 已經被極致優化了,所以很多情況下,效能仍會超越這些編碼方式,詳見[之前做的測試](https://evan361425.github.io/feedback/distributed-systems-with-node.js/sla-and-load-testing/#latency)。
但是上述例子確實讓原有的 114 bytes 壓縮到 66 bytes。
> Redis 就是用這種方式去進行 Lua 腳本的編譯。
但是由此也可以看到他受限於在 JSON 之上進行編碼,所以仍然需要鍵的資訊(例如,`userName`)。除此之外,前後相容的機制也和 JSON 一樣。
----
- DER - ASN.1
- [Apache Thrift](https://thrift.apache.org) - 初始於 Facebook
- [Protocol Buffer](https://developers.google.com/protocol-buffers) - Google 的 gRPC
- [Apache Avro](https://avro.apache.org)
note:
二進位編碼並不是新東西,早在 1984 年就有協定 [ASN.1](https://www.oss.com/asn1/resources/books-whitepapers-pubs/larmouth-asn1-book.pdf) 闡述如何進行二進位編碼,他和 [Thrift](#thrift)、[Protocol Buffer](#protocol-buffer) 一樣都使用 tag ID。且其應用(DER)如今仍被大量使用於 X.509。
但是他卻有過於複雜且綱目建置困難的缺點(這就是一個**過度**設計綱目的例子),由此發展出以下幾個較新的方式。
- Thrift 是 Facebook 內部服務在溝通時使用的編碼機制,他是以 RPC(後面會談)的形式去溝通的,特色在於大量語言和溝通協定(TCP、FTP)的實作,讓各種服務都能有相同的方式去溝通(量)。
> Software framework for scalable cross-language services development
- Protocol Buffer 是 Google 內部服務在溝通時使用的編碼方式,透過 gRPC 來互動。其特色是高效能的溝通(質)。
> A high performance, open-source universal RPC framework
- Apache Avro 則是著重在資料庫的儲存、備份、ETL、溝通等等。
----
### Thrift 綱目
```IDL
struct Person {
1: required string userName,
2: optional i64 favoriteNumber,
3: optional list<string> interests
}
```
note:
我們前面提了很多前後相容。要自動化達成這件事,事實上就需要針對每一個版本的資料做一個綱目出來。
> 上面的綱目,使用的語言類型稱為 IDL(interface definition language)
除此之外,因為綱目是必須的,不會出現文件和實際運作有落差(忘記補文件)。
前面的數字代表欄位的 ID,待會看他編碼的時候,就會發現他只需要 ID 就可以代表該欄位,所以後面的欄位名稱(例如,`userName`)就只是單純給人類看和自動化產生程式碼時使用,實際編解碼是不需要的。
----

note:
第一段說明他的型別,再來是 tag ID。透過 tag ID 辨認該值屬於哪個欄位。
從這裡就可以發現,如果任意改動 tag ID,這樣舊的資料(透過舊的綱目編譯出來的資料)可能會解碼錯誤。
----

note:
和上一個比,雖然都是 Thrift 的編碼機制,但特色卻不同。我們前面有提 Thrift 的特色其實是有很多實作的演算法,根據不同場域使用不同方式。
這個 CompactProtocol 相將於上一個的 BinaryProtocol 的優點是較小,但是效率較差。
> 數字相較於上一個編碼方式不太一樣,比起直接編碼成 64 bits 的資料,把他弄的更緊實(compact)。
> 每個 byte 第一個 bit 代表是否後面還有值,第一個 byte 的最後一個值代表他的符號(sign)。所以第一個 byte 可以代表 $\pm2^{6}$,加上第二個 byte 可以代表 $\pm2^{6+7}$。這也是為什麼他會把它倒著放。
----

note:
這是我們剛剛提到的 gRPC 他所實作的編碼方式(之一)。和上面提的差異除了數字的符號 bit 位置有異動外,他的 list 改為相同 tag ID 的欄位。
----
### Protocol Buffers 綱目
```IDL
message Person {
required string user_name = 1;
optional int64 favorite_number = 2;
repeated string interests = 3;
}
```
note:
用 `repeated` 代替 `list` 有什麼好處?
你可以輕易的從 `optional` 調整成 `repeated` 而不會破壞前後相容:
新綱目(`repeated`)讀舊資料(`optional`)時,就變成單一值得陣列;反之,舊綱目(`optional`)讀新資料(`repeated`)時,就只考慮最後一個值。
相反的,使用 `list` 就可以讓資料有多層的陣列(二維陣列)。
我們就順著講一下資料格式的演進吧!
----
### 資料格式的演進
**可能**會破壞前後相容
note:
例如 `int32` 轉成 `int64`,舊綱目在讀新資料的時候可能會被截斷(truncate)
----
### 標籤 ID 的演進
加欄位時
- 新綱目讀舊資料
- 舊綱目讀新資料
note:
我們前面有提,tag ID 很重要,不能輕易改動他,否則就會破壞前後相容。
相反,如果需要增加欄位,就要給他一個全新的 tag ID。
- 新綱目(有新的欄位)在讀舊資料時,只要他是 optional 就沒問題
- 舊綱目(不認識這個欄位)在讀新資料時,不認識的 tag 忽略就可以。
刪除欄位時,就把前後相容對調成後前相容,意思一樣。
> 所以重點是當綱目被定義之後,如果要求要求後相容所有以後的資料都必須是 `optional`。
---
## Avro
為了資料庫的編碼方式
note:
他很適合把資料庫的資料輸出成檔案,並且高度彈性的允許資料庫綱目更新(例如增加欄位)。相較於上述兩個,他們設計目的是 RPC,也就是應用程式和資料庫/應用程式之間的溝通。
為什麼高度彈性的允許資料庫綱目更新,待會談,先了解其機制。
> Protocol buffers (and thrift) encode the field names as id numbers. That means that if you read them into dynamic language like Python that it has to use the field numbers instead of the field names. In Avro, the field names are saved and there are no field ids.
> where one would like to write a script (Pig, Python, Perl, Hive, whatever) to process input data and generate output data, without having to locate the IDL for each input file
> [referer](https://lists.apache.org/thread/z571w0r5jmfsjvnl0fq4fgg0vh28d3bk)
----
### 綱目
```IDL
record Person {
string userName;
union { null, long } favoriteNumber = null;
array<string> interests;
}
```
note:
可以注意到他多了 `union` 型別,但也少了 `required`/`optional` 這類設定。這樣有什麼好處?
- 明確標示哪個是 nullable,可能會更好維運
- 減少額外參數,單純從型別定義
除此之外,最重要的是他少了 tag ID
- 讀取時需要知道編碼時的綱目,透過欄位順序知道其代表的欄位,所以不需要 ID。
----

note:
沒有型別和 ID,所以必須有對應的綱目才能解碼,但是也有相應優點,後面談。
我們先來看看其缺點:需要知道撰寫時是用哪個綱目。
----
### 編碼時的綱目
- 前綴完整綱目
- 前綴綱目版本
- 協商
note:
如何知道編碼時的綱目?
- 若資料庫是在 Hadoop 架構之上,就可以在每份檔案前面添加綱目版本。
- 若資料庫的每筆資料都可能會有不同的版本,就需要在每筆資料前設定版本,如 [Espresso](https://dbdb.io/db/espresso)。
- 若是在網路上進行雙向溝通的應用程式,可以協商出彼此的版本,如 [Avro RPC](https://avro.apache.org/docs/current/spec.html#Protocol+Declaration)
----
### 綱目演進

note:
如果編碼時的綱目和讀取的應用程式的綱目不一樣,怎麼同步?
透過綱目不同版本間的轉換,如上圖。
除此之外透過給予預設值來滿足向前後相容和減少不同版本間的錯誤。
在更改資料的**型別**和**名稱**時:
- **型別**除了和上面提的對應機制很像,在程式實作需要處理資料的截斷(truncate)外,你可以透過 `union` 滿足多型別,並於程式碼中判定。
- 設定 `alias` 來滿足**名稱**的轉換,但只能滿足向後相容(舊綱目看不懂新綱目調整名稱後的資料)
----
### 沒有標籤 ID
好處:不用管他
note:
資料輸出成檔案時(Hadoop 架構下的資料庫常做的事),我可以很方便地從資料庫的綱目轉換成 Avro Schema,然後把檔案撰寫成二位元。同樣的,當資料庫的綱目更新時,已經輸出過的檔案就不再需要轉換,而是透過上述版本轉換機制。
相反的,用 Protocol Buffers 或 Thrift 就需要謹慎使用 tag ID 來避免任何衝突。
例如,綱目本來是 `name` 改成 `last_name` 和 `first_name`。你直接輸出成 tag ID 可能就會是 `name: 1`,然後新版綱目若直接轉一樣會有 1 的 tag,例如 `last_name: 1` 和 `first_name: 2`
> Protocol Buffers、Thrift 並不是為了這類操作而設計的編碼格式
----
### 自描述
資料內含有綱目(或其版本編號)
note:
如果在資料中有放置編碼時的綱目,我們稱為其能夠自描述(self-describing)。若資料能夠自描述,你可以直接透過對應編碼方式的程式庫(例如 Avro library)打開這份檔案,不需要額外再提供綱目。
但是,必須讓資料相對來說不會太大,例如 50 bytes 的資料卻有 300 bytes 的綱目很不合理。相反的,如果是 ETL 的資料,他可能是十幾 GB,綱目的影響就很小。
若是小資料,這時候就可以把所有版本的綱目存起來,只在資料裡面放綱目的版本即可。
這對於高維度的分析工具,如 [Apache Pig](https://github.com/apache/pig),很有幫助。使用者直接透過 SQL 語法在 Hadoop 架構之上的資料庫進行分析,並且產出新的資料,過程中都不需要考慮綱目的問題,因為 Avro 會在資料中的前面撰寫其編碼時的綱目。
---
## 小結
| 綱目 | 除錯 | 演進 | 文件 |
| ---- | -------------- | --------- | ---------- |
| 無 | 方便 | `if-else` | 額外但詳細 |
| 有 | 配合綱目和工具 | 自動化 | 自動化 |
note:
沒有綱目的編碼(如,JSON)有其優點:
- 在解碼時不會受綱目影響,在應用程式面中可輕易允許前後相容(透過邏輯條件)。
- 可以透過文件方式補足綱目,且能詳細限制資料。如:數字只能在 0~1 之間。
然而有綱目的編碼也有其好處:
- 自動產生程式碼
- 透過一些機制仍能保持前後相容
- 因為綱目是必須的,不會出現文件和實際運作有落差(忘記補文件)。
在資料庫中二進位的編碼中又有儲存更緊密,體積小的好處。
---
## 使用情境
- 透過資料庫
- 服務或使用者
- 非同步訊息傳遞
note:
我們已經理解編碼是可以透過其內部機制,去讓使用該編碼方式的人可以不需要考慮怎麼相容不同版本的綱目,接下來透過實際使用場景來感受一下其應用。
----
### 透過資料庫

note:
可以想像資料庫是一個黑盒子,應用程式把資料傳給這個黑盒子後,即使綱目改動了,未來拿到指定的資料時,應自動配合新的綱目改變資料。
- 編碼:傳遞資料時;資料庫寫進磁碟時
- 解碼:接收傳到的資料時;資料庫讀磁碟的資料時
必須向後相容(新綱目讀舊資料),因為是傳給其他人(寫進磁碟)後,未來的自己使用新綱目做讀取。
> 除非你每次更動綱目都要把資料庫所有資料重新編碼一次,否則更動綱目理論上舊資料在編碼上仍是以舊的綱目為準。
> MySQL 就是那個例外。
----
**只做你知道的欄位**

note:
當其他服務傳送資料給資料庫時,其以為的綱目很可能是舊的,這時除了需要向前相容,也要避免資料被舊程式碼覆蓋掉。
----
**ETL**

note:
還有個狀況需要注意:當資料庫要把資料做備份或輸出給資料倉儲時,也會需要一次性把大資料重新編碼(做 ETL)。資料庫內部可能會有多個版本的綱目去做編碼的資料,而這些資料既然都要匯出去,那就重新編碼進最新版本。
----
### 服務或使用者

note:
可能是服務間(不管是不是相同公司)的溝通,也可能是使用者(例如瀏覽器、手機 APP)和服務間的溝通
- 請求者把請求資訊編碼
- 服務者解碼
- 服務者把回應編碼
- 請求者解碼
暴露接口(API)的 REST/GraphQL,還有依照規範,在程式碼中包裝起來的 RPC/SOAP。
----
**比較**
| | RPC | REST |
| -------- | ------------ | ------------ |
| **使用** | 函示 | 文件+呼叫 |
| **綱目** | 無法確保更新 | 前綴、標示 |
| **編碼** | 客製 | 統一(JSON) |
note:
- RPC/SOAP 被函式庫包裝後,就像呼叫函示一樣,可以直接呼叫。反之,REST/GraphQL 就需要參閱提供者的文件。
- RPC/SOAP 無法保證 client 使用最新版本的綱目,所以較難維運。反之,RESTful API 可以利用:
- 前綴詞加上版本
- HTTP 標頭(_Accept_)寫明使用版本
- 請求時需攜帶 Token
- RPC/SOAP 通常會使用較有效率和適合前後相容的編碼方式
總結來說,RPC/SOAP 適合同公司不同服務間的呼叫,快速且前後相容。反之 REST/GraphQL 適合對外,不管是使用者(瀏覽器、APP)和服務間的溝通或者不同公司間的服務溝通。
----
### 非同步訊息傳遞
Asynchronous message passing
note:
第三種方式,介於第一二種中間。
第一種透過資料庫,應用程式完全讓資料庫處理編碼;第二種應用程式和使用者(可能是其他應用程式或瀏覽器等等),則是彼此協商出一起用的編碼方式。
相對來說,非同步訊息傳遞則是大家預設使用某種編碼,但是傳遞是透過第三方。
----
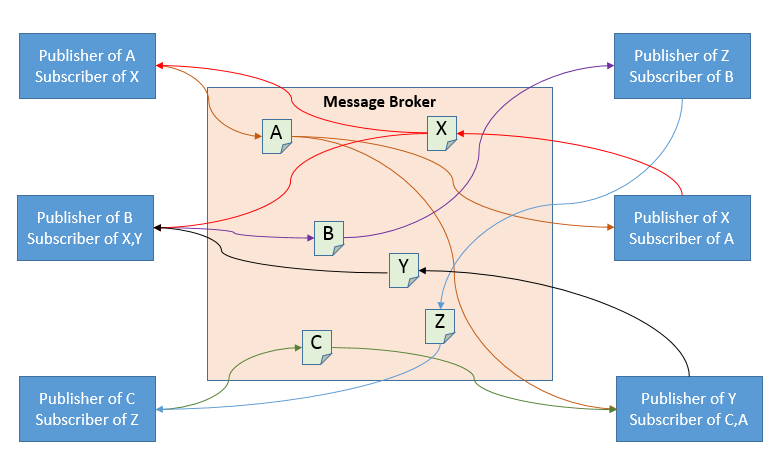
note:
透過一個代理人,幫我把訊息傳遞給其他有興趣的接收者。故而我只要確保資料送給代理人即可,其他接收者是否有收到是代理人要做的事情。
然而編碼方式中,代理人間的溝通其編碼方式和直接兩個服務溝通很像,因為代理人不會在乎你使用什麼編碼方式,他只是進行訊息的傳遞而已。
還記得前面提到會覆蓋資料的問題嗎?有時接收者會把訊息消化並重新傳給代理人(再讓其他有興趣的人接受其輸出),此時就有可能發生覆蓋資料的問題。
> 這段到第十一章,串流處理會更詳細的討論,這邊僅說明其會使用到編碼。
> [文本](https://evan361425.github.io/feedback/designing-data-intensive-applications/foundation-encode/#消息代理)談更細
---
## 總結
- 演進:前後相容
- 編碼
- 綱目
- 體積
- 演進
- (效能)
- 使用情境
note:
我們談了資料庫怎麼配合應用程式的演進,也談了不同種編碼方式彼此間的差異。
我們並不需要決定哪個編碼方式好,而是試著和大家討論哪種情況適合哪種編碼。我們也談了編碼在有無綱目的情況下,有哪些優劣勢,其會影響著體積和處理演進的方式。
這裡的效能之所以用括號表示,就是因為影響效能的東西非常多,包括我們上次提的硬體面,在談效能前我們都需要做好負載測試,提出來的效能比較才有說服力。JSON 也是可以擁有[極致的效能](https://github.com/simdjson/simdjson)的。
最後我們談了使用情境,把編碼丟給第三方(資料庫)或是和其他服務協商。不管是配合公司政策(例如,要求大家都用 JSON),或者透過軟體(例如,Apache Thrift)來彼此動態協商。
----
### Avro
- 適合 ETL
- 體積小
- 自動配合演進
- 自描述
note:
這裡我們再提一下 Avro 的優勢。以資料庫來說,Avro 有體積小、自動配合演進的優勢。
除此之外,在 ETL 上,由於自描述,讓他可以不考慮綱目的情況,做一些宣告式的搜尋語言。
----
### 預告

note:
分享完編碼方式後,資料庫的基礎就告一個段落了。書中把第一到第四章分為第一節:資料庫基礎(Fundations of Data Systems)。
我們談了資料模型、索引、資料倉儲和這次的編碼和演進。
----
**處理競賽狀況**

note:
接下來要談的是現實生活中的那些讓你懷疑人生的問題。理想上,資料庫基礎幫我們解決了基礎的問題:怎麼在合乎商務邏輯下,有效率的存取資料庫。但是常常會有些小惡魔出來搗蛋,這就是下次要討論的「處理競賽狀況」。
{"metaMigratedAt":"2023-06-16T17:08:51.657Z","metaMigratedFrom":"YAML","title":"編碼與演進","breaks":true,"description":"資料庫以何種形式儲存資料並適應演進。","contributors":"[{\"id\":\"c945b58d-6d0e-4680-a2c3-b297ba669e68\",\"add\":18563,\"del\":5655}]"}