**2.Mô hình TEFPA được viết tắt từ các từ:**
- **T**ask ***(T)*** : Nghĩa là nhiệm vụ, việc thuật toán cần làm. có 2 loại cụ thể là reggresion và classification.
- **E**xperience ***(E)*** : CÓ thuật toán cơ bản là $X \rightarrow Z \rightarrow Y$. là các dữ liệu ***input*** và ***output***.
- **F**unction space ***(F)*** : Không gian hàm. Để học máy tìm được hàm tối ưu trong không gian hàm cho trước = $WZ + b$.
- **P**erformance mesure ***( P)***: Kiểm tra thuật toán có tốt hay không.
- **A**lgorith ***(A)***: là các thuật toán cập nhật liên tục $W$ và $b$ sao cho sai số giữa $y$ và $\hat{y}$ giảm nhiều nhất có thể. có các thuật toán là: **GD** (Gradient Descent), **SGD** (Stochastic Gradient Descent), **Adam**,...
**2. Model TEFPA abbreviated from:**
- **T**ask ***(T)*** : Mean a task, algorith that **machine learning** need to do. their are 2 type of task is: reggresion and classification.
- **E**xperience ***(E)*** : basic algorithm is $X \rightarrow Z \rightarrow Y$. They are ***input*** and ***output***.
- **F**unction space ***(F)*** : machine learning need to find the optimize function space in the given function space = $WZ + b$.
- **P**erformance mesure ***( P)***: check if Algorith good or not.
- **A**lgorith ***(A)***: is the Algorith that constantly updated $W$ and $b$ so that the $\hat{y} \approx y$. Some basic Algorith in **ML** is: **GD** (Gradient Descent), **SGD** (Stochastic Gradient Descent), **Adam**,...
- Ta đi vào chi tiết cụ thể từng phần:
- Ở phần **T**ask có 2 phần chính đó là **Reggresion** và **Classification**:
- **Reggresion**: Thực hiện các bài toán yêu cầu trả về là các con số. Ví dụ như bài toán về giá nhà thì **input** là các thông tin của căn nhà và **output** chính là con số là giá trị của từng căn nhà. một số ví dụ khác như:dự đoán cân nặng, dự đoán kích thước,...
- **Classification**: Thực hiện các bài toán phân vùng dữ liệu, khái niệm. Ví dụ: phân loại chó mèo, phân loại căn nhà, phân loại dữ liệu,...
- Ở phần **E**xperience:
- **Input** là các dữ liệu cho trước được đưa vào để học máy xử lí dữ liệu đó để đưa ra **Output**. Tuỳ vào mỗi bài toán thì sẽ có các dạng dữ liệu **Input** khác nhau.
- Ví dụ như bài toán về dữ đoán giá nhà ***(Reggresion)***: các dữ liệu được đưa vào cho học máy xử lý là các thông tin về diện tích, số lượng phòng, diện tích,... và **Output** trả về 1 con số chỉ giá trị của căn nhà đó sau khi đã xử lí các dữ liệu **Input**.
- Ví dụ như bài toán phân loại chó mèo ***(Classification)***: các dữ liệu được đưa vào cho học máy xử lý là các thông tin về kích thước, tai, mũi, lông,.. và **Output** trả về là "Chó" hoặc **Mèo**.
- **Lưu ý**: sẽ có 1 số input là hình ảnh như bài phân loại chó mèo. Thì ta sẽ có thêm 1 bước trung gian (PCA, worde) để trích xuất các đặc trưng về loài như "chó" và "mèo" trong bức ảnh là $Z$, rồi từ các đặc trưng $Z$ đó để phân loại "chó" và "mèo".
- Không gian hàm (**Function space**) chính đó là $\hat{y} = wz+b$ dùng để tìm không gian tối ưu trong không gian hàm để sai số $\hat{y}$ và $y$ thấp nhất để thực hiện các bài toán **Reggresion** hoặc **Classification**.
- Thuật toán (**Algorith**) là sau khi ta tìm được hàm $\hat{y}$ đầu tiên, thuật toán sẽ cập nhật lại $w$ và $b$ để cho ra $\hat{y}$ mới và tính sai số giữa $\hat{y}$ và $y$, rồi lại cập nhật liên tục bộ trọng số $w$ và $b$ để tìm ra $\hat{y}$ tối ưu nhất ($\hat{y} \approx y$).
- Next part is the details of **TEFPA**:
- **T**ask has 2 important task is **Reggresion** and **Classification**:
- **Reggresion**: Can do any algorith that the **output** is a number. For example: calculate the price of the house, so the **input** is the information about the house, **output** is the price of the house we want to predict. Some other example: size of the flower, human weight,...
- **Classification**: Do the algorith that need to classify the data. For example: Differences between dogs and cats, Classify the house,...
- **E**xperience:
- **Input** is the data ML need to process to return **Output**. Depend on each Algorith will have different **Input**.
- Example 1: House price prediction ***(Reggresion)***: acreage, number of rooms,... are the input information for ML data prcessing. **Output** is the number represent the price of the house.
- Example 2 ***(Classification)***: Ear, nose, eyes,... are the input information for ML data prcessing and **Output** return "Dog" or "Cat".
- **Note**: Some time the input is image. In that case, we will have some intermediate step (PCA, CNN) to extract the feature about "Dog" và "Cat" in the image to $Z$. After that, we use feture $Z$ to classify "Dog" and "Cat".
- **Function space** is $\hat{y} = wz+b$ need to find the optimize function space in the given function space. So that $Y-\hat{Y}$ residual is minimize. $\hat{y} \approx y$ to do **Reggresion** or **Classification**.
- **Algorith**: after we find first $\hat{y}$, algorith will update $w$ and $b$ to find new $\hat{y}$ and count the residual $\hat{y}$ and $y$, constantly updated the weight $w$ and $b$ to find the good $\hat{y}$ ($\hat{y} \approx y$).
- **Các giải thuật ML cơ bản được giải thích theo TEFPA**:
- Linear Reggression:
- **T**ask: Reggression.
- **E**xperience: $X \rightarrow Z \rightarrow Y$.
- **F**unction space: $f(x) = WZ + b$.
- **P**erformance mesure: Mean Squared Error: MSE (Tổng bình phương sai số).
- **A**gorith: **GD** (Gradient Descent), **SGD** (Stochastic Gradient Descent), **Adam**,...
- Perceptron:
- **T**ask: Classification.
- **E**xperience: $X \rightarrow Z \rightarrow Y$.
- **F**unction space: $f(x) = sign(WZ + b)$.
- **P**erformance mesure: Tính các điểm bị phân loại sai.
- **A**gorith: chọn $\dot{W}$ rồi tính các $\hat{y}_i$ ứng với từng điểm $x_i$. Sau đó cập nhật lại các bộ trọng số $W$ và $b$ ngay tại các điểm $\hat{y}_i$ bị sai.
- MLP:
- **T**ask: Reggression hoặc Classification.
- **E**xperience: $X \rightarrow Z \rightarrow Y$.
- **F**unction space: $f(x) = \sigma (WZ + b)$.
- **P**erformance mesure: Cross-entroy.
- **A**gorith: **GD** (Gradient Descent), **SGD** (Stochastic Gradient Descent),...
- K-means:
- **T**ask: Phân cụm.
- **E**xperience: $X \rightarrow Z$.
- **F**unction space: Không có.
- **P**erformance mesure: Khoảng các giữa các điểm đến centroi.
- **A**gorith: Cập nhật (các) centroi.
- **ML in TEFPA**:
- Linear Reggression:
- **T**ask: Reggression.
- **E**xperience: $X \rightarrow Z \rightarrow Y$.
- **F**unction space: $f(x) = WZ + b$.
- **P**erformance mesure: Mean Squared Error (MSE).
- **A**gorith: **GD** (Gradient Descent), **SGD** (Stochastic Gradient Descent), **Adam**,...
- Perceptron:
- **T**ask: Classification.
- **E**xperience: $X \rightarrow Z \rightarrow Y$.
- **F**unction space: $f(x) = sign(WZ + b)$.
- **P**erformance mesure: Calculate the wrong classification points.
- **A**gorith: random $\dot{W}$ and caculate $\hat{y}_i$ corresponding to each point $x_i$. constantly updated $W$ and $b$ every point $\hat{y}_i$ is wrong.
- MLP:
- **T**ask: Reggression or Classification.
- **E**xperience: $X \rightarrow Z \rightarrow Y$.
- **F**unction space: $f(x) = \sigma (WZ + b)$.
- **P**erformance mesure: Cross-entroy.
- **A**gorith: **GD** (Gradient Descent), **SGD** (Stochastic Gradient Descent),...
- K-means:
- **T**ask: Clustering.
- **E**xperience: $X \rightarrow Z$.
- **F**unction space: None.
- **P**erformance mesure: Distance between points to centroid.
- **A**gorith: Updated centrois.
**3. Trình bày mô hình $X--(1)-->Z--(2)-->Y$:**
- Bước (1):
- Được gọi là trích xuất đặc trưng. mục đích của nó là trích xuất những đặc trưng của **Input** $x$ ví dụ như:
- Khi ta đưa vào là 1 tấm hình thì Bước (1) sẽ trích xuất xem bức ảnh đó có những đặc trưng gì, nếu là bức hình về 1 con chó thì sẽ trích xuất những đặc trưng như tai, mắt, mũi, màu lông,...
- Khi ta đưa vào là 1 văn bản thì Bước (1) sẽ trích xuất các đặc trưng đó và chuyển thành Onehot-Coding.
- Bươc (2):
- Có tác dụng để dự đoán sau khi đã có $Z$. Dựa vào các đặc trưng sau khi trích xuất ra $Z$ để dự đoán $Y$
**4. Trình bày mạch ý tưởng tiến hoá của chuỗi giải thuật sau. Đính kèm mô hình, công thức toán học và giải thích**

- (1) **Linear Reggression**
- Là mô hình học máy cơ bản nhất, là nền tảng cho những thuật toán về học máy về sau này. Linear Reggession sử dụng công thức $\hat{y} = WX + b$ với ý nghĩa đem $X$ so khớp với dữ liệu $W$ để cho ra $\hat{y}$. Vì kết quả trả về chỉ có 1 con số, cùng với nhu cầu muốn phân loại dữ liệu, nên **Perceptron** đã ra đời để cải tiến vấn đề phân loại.
- (2) **Perceptron**
- Cải tiến hơn **LR** vì có thêm hàm $sign$ để nắn lại dữ liệu của $\hat{y}$. Công thức là $\hat{y} = sign(WX +b)$. Mô hình sau khi đã được hàm $sign$ nắn lại sẽ có giá trị -1, 0, 1 và có thể dùng để phân loại -1, 1. **Perceptron** chỉ có thể phân loại được 1 giá trị, nhưng nếu chúng ta cần phân loại nhiều dữ liệu cùng 1 lúc thì sao? từ đó **Multi-layer Perceptron** ra đời.
- (3) **Multi-layer Perceptron (MLP)**
- Đúng với tên gọi của nó. Ta xếp chồng các layer Perceptron lại với nhau, cho qua 1 lớp hidden layer sử dụng các hàm ***activation*** tuỳ vào từng bài toán. Hàm $\sigma$ (activation) trong $\hat{y} = \sigma(wx+b)$ chính là các hàm ***Softmax, ReLu,...*** ***Softmax*** sẽ chỉnh dữ liệu đầu ra có tổng số bằng 1 và giá trị các dữ liệu có kích thước từ 0 đến 1. Nhưng **MLP** cần có các đặc trưng cụ thể, tốt thì việc dự đoán mới tốt được, vì thế **CNN** đã ra đời để trích xuất các đặc trưng mà ta không thể làm được.
- (4) **Convolutional Neural Networks (CNN)**
- Nếu như đầu vào là 1 bức ảnh. Thực hiện việc trích xuất các đặc trưng trong tấm ảnh ra $X$. Sau đó đưa qua 1 vòng lặp có các nhiệm vụ là:
- So khớp giữa $X$ và **kenel** (chứa các filter-bộ lọc)
- Qua 1 lớp ***pooling*** để giữ lại các đặc trưng cần thiết, quan trọng và giảm kích thước của ma trận.
- Sau khi thực hiện vòng lặp nhiều lần sẽ cho ra các đặc trưng $Z$. ta Flatten thành 1 vector có giá trị. Mỗi giá trị có xác suất đặc trưng đó thuộc về label đó. Ví dụ: nếu ta chọn label là "Mèo" thì râu ria mũi sẽ có giá trị cao hơn. Sau đó qua 1 lớp fully connection để tính trọng số và sẽ qua hàm ***activation*** như **Softmax** để vote, tính đặc trưng nào cao nhất.
- (5) **Recurrent Neural Network (RNN)**

- Nếu như đầu vào là 1 đoạn văn bản hoặc âm thanh. RNN thực hiện việc này sẽ tốt hơn. Ví dụ ta cho 1 đoạn văn bản:"anh đứng đây từ chiều". Mạng nơ-ron sẽ triển khai 5 tầng nơ-ron tương ứng với từng từ, việc tính toán sẽ như sau:
- đầu vào $x$ (one-hot vector) tại vị trí tương ứng là $t$
- $s_t$ là 1 trạng thái ẩn ở vị trí $t$. $s_t$ được tính dựa trên các trạng thái ẩn trước đó $s_t = f(Ux_t+Ws_{t-1})$. Hàm $f$ thường là hàm activation như **ReLU**, **tanh**. Phép toán ẩn đầu tiên $s_{t-1}$ thường có giá trị = 0
- $o_t$ là đầu ra tại bước $t$. Ví dụ, ta muốn dự đoán từ tiếp theo có thể xuất hiện trong câu thì $o_t$ chính là một vec-tơ xác xuất các từ trong danh sách từ vựng của ta: $o_t=softmax(Vs_t)$
- Nhưng dữ liệu của ta không thể nhớ những từ quan trọng sau khi nó chạy qua, nên LSTM đã ra đời để giúp học máy nhớ được những từ quan trọng trong câu để sử dụng.
- (6) **Long-Short Term Memory (LSTM)** là 1 phiên bản cải tiến hơn RNN, giúp việc nhớ những từ quan trọng sau khi nó chạy qua. LSTM train dữ liệu bằng cách sử dụng thuật toán back-propagation. **LSTM** thuận tiện hơn trong việc phân loại, dư đoán từ tiếp theo. LSTM có 3 cổng chính:
- 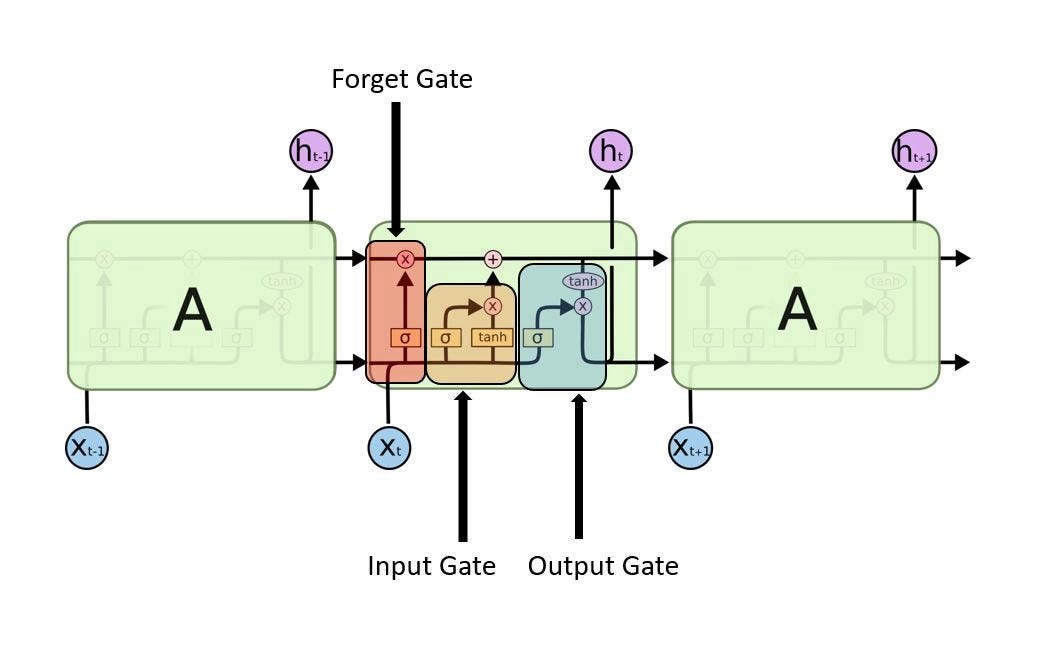
- **Cổng vào**: Sử dụng hàm **Sigmoid** để kiểm tra xem giá trị nào được phép đi qua, trả về giá trị 0,1. Hàm **tanh** để kiểm tra xem từ đó có tầm quan trọng như thế nào, trả về giá trị từ -1 đến 1.
$$i_t = \sigma(W_i \cdot[h_{t-1},x_t]+b_i )$$$$\tilde{C}=tanh(W_C \cdot [h_{t-1}, x_t]+b_C)$$
- **Cổng quên**: Kiểm tra xem từ nào không có giá trị và có thể quên. Tại cổng này thì hàm **sigmoid** quan trọng nhất. nó kiểu tra $h_{t-1}$ và $X_t$ và trả về giá trị là ***1*** (giữ lại) hoặc ***0*** (quên đi)
$$f_t=\sigma (W_f \cdot [h_{t-1},x_t]+b_f)$$
- **Cổng ra**: Dựa vào dữ liệu input và memory để quyết định đầu ra. Hàm **Sigmoid** quyết định dữ liệu có được ra (1) hay không (0). Hàm **tanh** dùng để tạo weight và độ quan trọng của từ đó từ -1 đến 1. Sau đó nhân với output của hàm **Sigmoid**.
**3. $X--(1)-->Z--(2)-->Y$:**
- Step (1):
- Is called extract feature. the purpose is to extract feature **Input** $x$. Example:
- If we put an image in step (1). its will extract the feature in the image, if the image is about dogs, its will extract the feature about: eyes, nose,...
- When we put in a text, Step (1) will extract those features and convert into Onehot-Coding.
- Step (2):
- Effective to predict after $Z$ is available. Based on the characteristics after extracting $Z$ to predict $Y$
**4. Present the evolutionary idea circuit of the following algorithm sequence. Attach models, mathematical formulas, and explanations**

- (1) **Linear Reggression**
- This is the most basic machine learning model, the foundation for later machine learning algorithms. Linear Reggession uses the formula $ \ hat {y} = WX + b $ with the meaning of bringing $ X $ to match the data $ W $ to get $ \ hat {y} $. Because the result returned only one number, want to classify data, ** Perceptron ** was born to improve the classification problem.
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet