# 如何用 SAHI 偵測小物件:推論與微調
# How to Detect Small Objects with SAHI: Inference & Fine-Tuning
> 原文來源:https://visionbrick.com/how-to-detect-small-objects-with-sahi-inference-fine-tuning/
---
像 Ultralytics 這類函式庫對深度學習,特別是物件偵測,有很大影響。即使一個人對電腦視覺一無所知,他們也能透過結合幾個元素來訓練並部署物體偵測模型。首先,從 Kaggle 找到資料集,建立筆記本,啟用 GPU,然後用 Ultralytics 來訓練。只要寫近 **50 行程式碼**,花 **4 到 5 小時**,**任何人都能訓練 YOLO 模型並部署**。是的,這對一般物體偵測是有效的。如果資料集夠乾淨且夠大,就會有一個模型能在大多數情況下使用。你大多時候可以準確偵測常見物體,比如汽車、人。但這是每個任務都一樣嗎?

**Small Object Detection with SAHI [VisDrone19-Detection dataset]**
使用 SAHI 進行小型物體偵測 [VisDrone19-Detection 資料集]
當然不,我們來想想小物件。物體太小,甚至用肉眼無法準確辨識。因此,這種簡單的方法行不通,針對**小型物體的偵測有不同的解決方案**,本文將介紹 **SAHI**。SAHI 的主要理念是將影像切片成較小的區域,並在這些小區域進行推論與訓練,並進一步處理。
---
## 為什麼小物件偵測較難?SAHI 如何成功?
想像影像中的小物體,如飛機、昆蟲和遠方的人。即使在原始圖片中,也很難辨認。現在想想模型訓練部分,因為記憶體限制和訓練時間,大多數情況下**影像會被調整到像 640×640、640×480 這樣的解析度**。
即使在預設情況下,Ultralytics 也會將原始圖片調整為 640×640。影像大小會顯著影響訓練時間,有時在低 GPU VRAM(4GB、6GB、8GB)時,**CUDA 記憶體不足**錯誤很常見。你可以透過減少批次大小或影像解析度來解決這個問題。
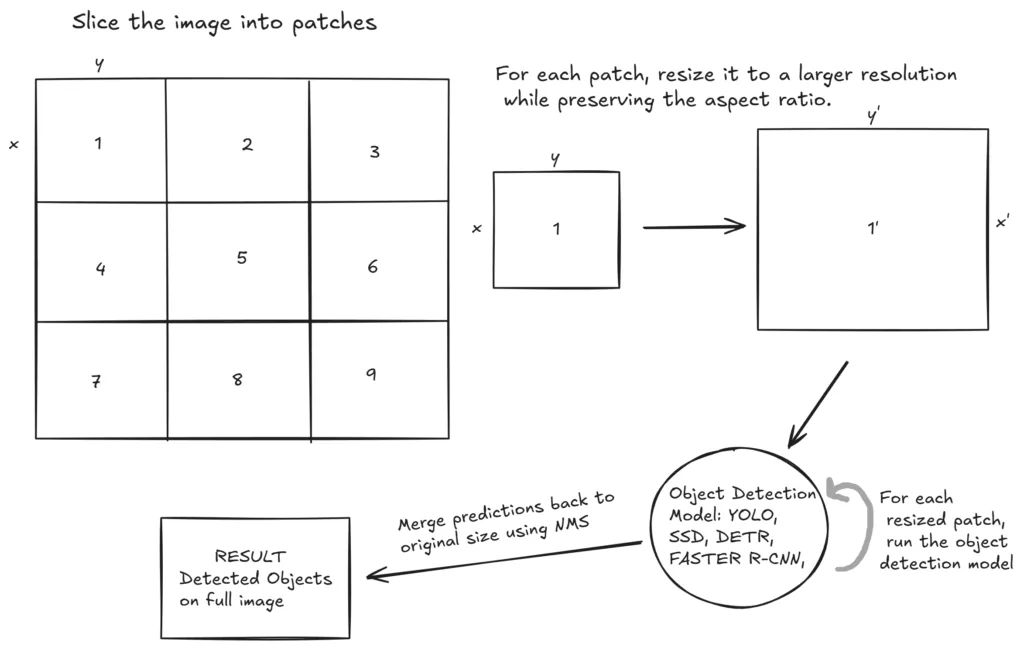
**How SAHI Slicing Aided Inference works?**
SAHI 切片輔助推論是如何運作的?
物件即使在原始解析度下也很小,想想在訓練前調整大小後會發生什麼事?它們變得**非常小**,有時甚至消失。這時 SAHI 登場了。這個想法簡單卻有效:如果我們**將影像切成較小的片段**,逐個處理,就不必將整張影像調整到較低解析度。將影像切片成多個片段後,每個片段的尺寸調整到較高解析度,同時保持比例,使**較小的區域變大**(同時物體變大),此方法對小物件偵測有顯著效果。

**Detecting Small Objects with SAHI [VisDrone19-Detection dataset]**
使用 SAHI 偵測小型物體 [VisDrone19-Detection 資料集]
如果你有時間,我強烈建議你閱讀 SAHI 的論文。內容不長(4 頁),而且他們解釋得很完美。你可以從[這裡](https://arxiv.org/abs/2202.06934)閱讀。
---
## SAHI (Slicing Aided Hyper Inference)
SAHI(切割輔助超推論)
你可以在任何物件偵測模型上使用 SAHI,因為**它不會改變模型架構**。其理念是將影像切片成較小的區域;因此,模型架構保持不變。你可以搭配 **YOLO**、**Faster R-CNN**、**SSD**、**DETR** 等任何你想到的物體偵測模型。
如我之前所說,影像會被切成較小的區域,每個區域都分別處理。但有一個問題:**如果一個物件夾在兩個補丁之間呢?** 解決這個問題,每個補丁與相鄰補丁重疊 **25%**。最後,為了消除從相鄰補丁偵測到的重複物件,會應用 **NMS(非最大抑制)**。順帶一提,25% 是預設參數;你可以改變它。

**Object falls between two patches**
物體落在兩個區域之間 [[img](https://www.pexels.com/photo/person-hiking-in-mountains-13416295/)]
論文中提出了兩種不同的方法:
### 1. Slicing Aided Inference(切割輔助推論)
到目前為止,我已經告訴你第一個方法的主要概念,但還有更多。好,我們有一張圖片,然後把它切成更小的區域。重要的是把這些較小的補丁**調整到更高解析度**。透過這樣做,我們的小塊會變大,裡面的物體也會變大。接著,物件偵測模型會運行在這些新產生的高解析度補丁上。對於小型物體,這種方法特別合理,尤其是**高解析度影像中的小物體**。
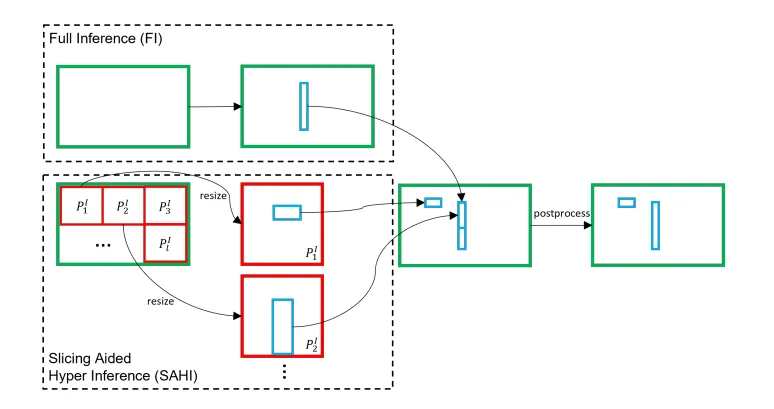
**Slicing Aided Inference**. Source: [[paper link](https://arxiv.org/abs/2202.06934)]
切割輔助推論
### 2. Slicing Aided Fine-tuning(切割輔助微調)
那「切割輔助微調」方法呢?顧名思義,這是關於訓練。訓練前,將影像切片成較小的片段,將這些片段調整至較大解析度,然後**在這些新建立的高解析度片段及整張影像上訓練物件偵測模型**。你可以直覺地處理這件事,因為這很有道理。你有一個超小的物體,存在於高解析度影像中。首先,你將這張圖片分割成較小的區域,然後將這些小區域調整到更高解析度。這樣一來,你的超小物體會變大,接著你用這些補丁訓練物體偵測模型,讓**小物體偵測的準確度提升**。
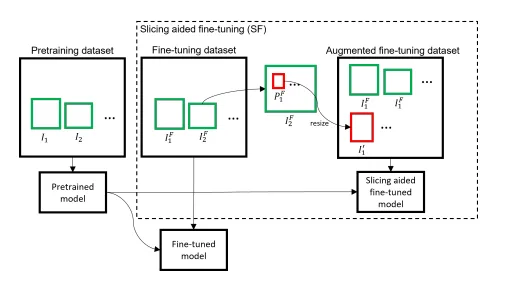
**Slicing Aided Fine-tuning**. Source: [[paper link](https://arxiv.org/abs/2202.06934)]
切割輔助微調
現在,我將展示論文中建議的兩種方法的示範。首先,我會示範如何**將 YOLO 模型與 SAHI 結合**,以提升小物件偵測的推論能力。接下來,我將示範如何在你的資料集上進行**切片輔助微調**,以訓練更穩健的小型物件偵測模型。
---
## 安裝 Installation
安裝並不複雜;你需要幾個函式庫。你應該建立一個支援 GPU 的 PyTorch 環境來訓練並加快推論速度。
```bash
pip install sahi
```

**GitHub repository of SAHI** ([link](https://github.com/obss/sahi))
SAHI 的 GitHub 倉庫
---
## 1. Slicing Aided Inference with YOLO + SAHI
以 YOLO + SAHI 切割輔助推論
好,讓我們從切片輔助推論開始。我談了很多事情,比如調整圖片大小到低解析度或高解析度、重疊區域。**我們不需要處理這些問題,因為 SAHI 和 Ultralytics 一樣使用者友善**。
**Slicing Aided Inference with YOLO + SAHI**
與 YOLO + SAHI 的輔助推斷切割
首先,建立一個 `UltralyticsDetectionModel` 類別實例來**載入你的 YOLO 模型**,然後用 `get_sliced_prediction` 函式來**推論**。我用的是預訓練的 YOLO 模型(`yolov8n.pt`)。如果你想用自訂模型或其他預訓練模型來使用 SAHI,情況不會改變。
`UltralyticsDetectionModel`(models/ultralytics.py)繼承自 `DetectionModel`(models/base.py)類別。我強烈建議你查閱原始碼以更好理解。
**models/ultralytics.py, models/base.py**
你可以在 `predict.py` 檔案中找到 `get_sliced_prediction` 函式所需的所有資訊。
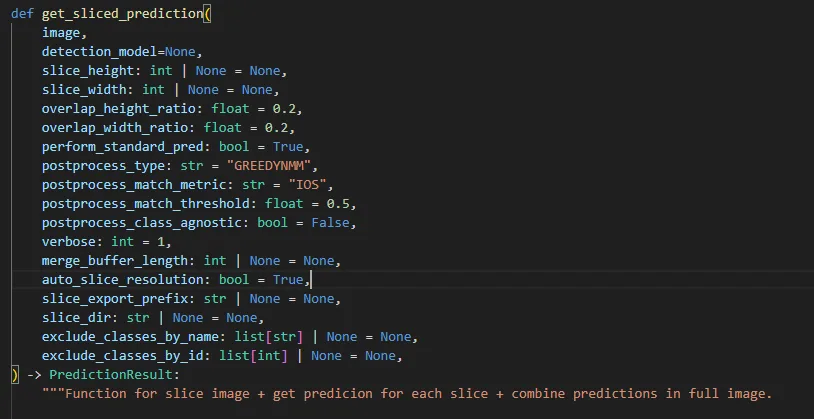
**`get_sliced_prediction` function inside `predict.py` file**
現在讓我們來推論 SAHI。你可以更改 `model_path`、`device`,以及測試影像的路徑。
參數說明:
- **slice_height**:補丁高度
- **slice_width**:補丁的寬度
- **overlap_ratio**:相鄰補丁的重疊百分比
```python
from sahi.models.ultralytics import UltralyticsDetectionModel
from sahi.predict import get_sliced_prediction
detection_model = UltralyticsDetectionModel(
model_path="yolov8n.pt",
confidence_threshold=0.3,
device="cuda"
)
result = get_sliced_prediction(
r"images/cars.jpg",
detection_model,
slice_height=256,
slice_width=256,
overlap_height_ratio=0.2,
overlap_width_ratio=0.2
)
```

**Detection of small objects with SAHI** [[img](https://www.pexels.com/photo/road-between-green-leafed-trees-59512/)]
用 SAHI 偵測小物體
### 視覺化結果
為了視覺化結果,你可以循環 `result` 變數,取得包圍框座標、標籤資訊和置信度值,然後畫出包圍框並在物件上寫入標籤資訊。或者,你也可以直接使用 `export_visuals` 函數;它會將輸出影像儲存到 `export_dir` 路徑。
```python
for pred in result.object_prediction_list:
bbox = pred.bbox.to_xyxy()
x1, y1, x2, y2 = map(int, bbox)
label = pred.category.name
score = pred.score.value
```
```python
result.export_visuals(export_dir="runs/predictions/")
```
### slice_image 函式
還有另一個很酷的函數叫 `slice_image`。你可以利用這個功能**儲存所有切片**,以更好地視覺化和理解 SAHI。讓我給你看一個簡短的示範。
```python
from sahi.slicing import slice_image
slice_image_result = slice_image(
image="test_image.jpg",
output_file_name="slice",
output_dir="runs/sliced_images/",
slice_height=256,
slice_width=256,
overlap_height_ratio=0.2,
overlap_width_ratio=0.2,
)
print(f"Original Image Size: {slice_image_result.original_image_height}x{slice_image_result.original_image_width} (HxW)")
print(f"Slice Size: {slice_width}x{slice_height} pixels")
print(f"Total Slices Created: {len(slice_image_result.images)}")
print(f"Slices Saved To: {slice_image_result.image_dir}")
```
輸出結果:
- Original Image Size: **853×1280 (HxW)**
- Slice Size: **256×256 pixels**
- Total Slices Created: **24 Slices**
- Saved To: **runs/sliced_images/**

**Output: Sliced images in the `output_dir` directory**
輸出:`output_dir` 目錄中的切片影像
---
## 2. Slicing Aided Fine-tuning
切割輔助微調
現在是第二部分的時間。這個想法和第一個很接近;**主要差別在於此步驟是在訓練階段之前完成,而非推論時**。假設我們有一個包含 **1,000** 張高解析度影像的資料集。首先,像第一種方法一樣將影像切成片段,然後再放大。用這些放大後的補丁來訓練物件偵測模型。根據切片參數和影像大小,你會有大約 **10,000** 到 **50,000** 張訓練影像。
**當你擁有高解析度資料集時,這種方法會有效**。假設你的資料集包含低解析度影像,例如 640×640。所以,切割就沒有意義;影像解析度本來就很低。所以,如果你的影像解析度很高,比如 **1920×1080**、**2160×1440** 等,最好進行微調。
### VisDrone19-Detection Dataset
我會用 **VisDrone19-Detection Dataset** 做微調,因為論文中的基準測試都是在這個資料集上進行的。該資料集包含由無人機拍攝的高解析度影像。
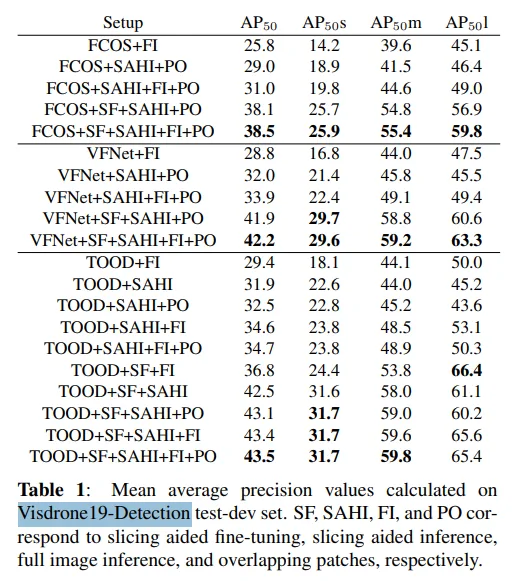
**Benchmark results on VisDrone19-Detection dataset**. Source: [[paper link](https://arxiv.org/abs/2202.06934)]
VisDrone19-Detection 資料集上的基準測試結果
資料集包含不同解析度,如 **1400×1050**、**1920×1080** 及 **2000×1500** 高解析度影像。我決定只用 **2000×1500** 張圖片,因為切片會大幅增加圖片數量,而且我的 GTX 1660 Ti Max-Q GPU 訓練兩天後可能會燒毀 :/

**Visdrone19-Detection dataset**
Visdrone19-Detection 資料集
您可以在下方圖表中看到該 VisDrone19-Detection 資料集的影像解析度分布。
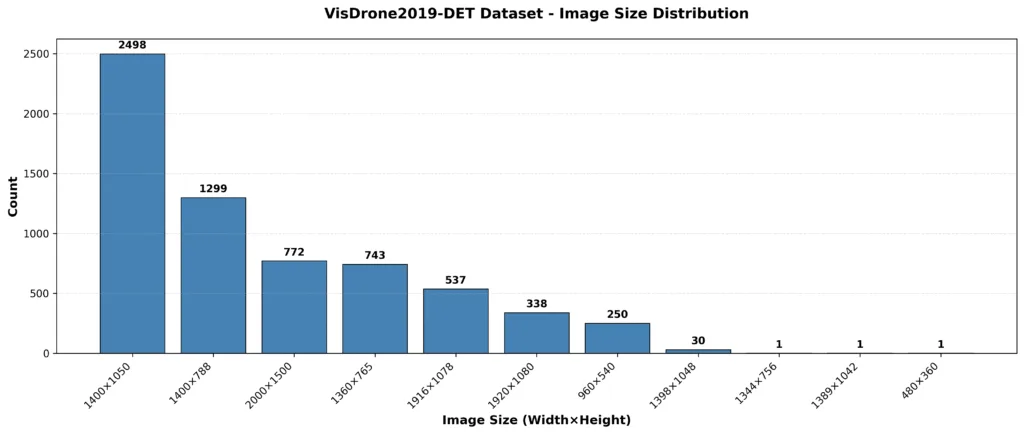
**Image resolution distribution of the VisDrone19-Detection dataset**
VisDrone19-Detection 資料集的影像解析度分布
### 資料集格式轉換
VisDrone19-Detection 資料集格式並非 COCO 格式。如果你不想花時間把資料集轉換成 COCO 格式,我建議你**直接選擇已經是 COCO 格式的資料集**。我處理了 VisDrone19-Detection 資料集並匯出成 COCO 格式。
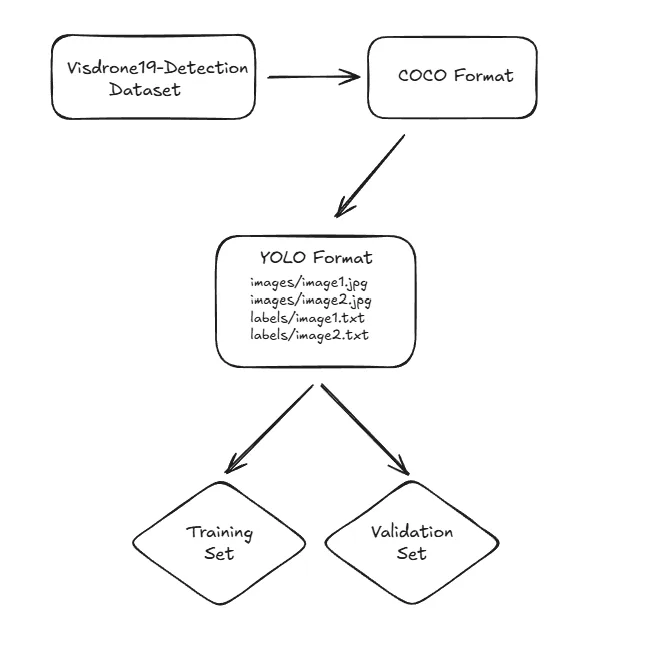
**Converting VisDrone19-Detection dataset to YOLO format**
將 VisDrone19-Detection 資料集轉換為 YOLO 格式
### slice_coco 函式
在 SAHI 中,有一個稱為 `slice_coco` 的函數。這個函式會將 COCO 格式的資料集切片,然後建立 COCO 格式的資料集。
你可以改變 `coco_annotation_path`、`image_dir`、`output_dir` 變數。
```python
from sahi.slicing import slice_coco
coco_dict, coco_path = slice_coco(
coco_annotation_file_path=coco_annotation_path,
image_dir=IMAGE_DIR,
output_coco_annotation_file_name="visdrone_train_sliced.json",
output_dir=SLICED_OUTPUT_DIR,
ignore_negative_samples=False,
slice_height=640,
slice_width=640,
overlap_height_ratio=0.2,
overlap_width_ratio=0.2,
min_area_ratio=0.1,
verbose=True
)
```
輸出是一個包含所有圖片的資料夾,以及一個 JSON 格式的註解檔案。你可以在 `output_coco_annotation_file_name` 目錄裡看到註解檔,以及 `output_dir` 目錄下的切片圖片。
當你擁有 COCO 格式的資料集後,一切都變得相當簡單。COCO 格式就像深度學習中的 `print("hello world")`。你可以用各種工具匯出不同的資料集格式,但我覺得沒必要。你可以直接建立一條簡單的管線,從 COCO 格式匯出到任何其他格式。
我要訓練一個 YOLO 模型;因此,我將資料集轉換成 YOLO 格式。
> VisDrone19-Detection dataset → COCO format → YOLO format
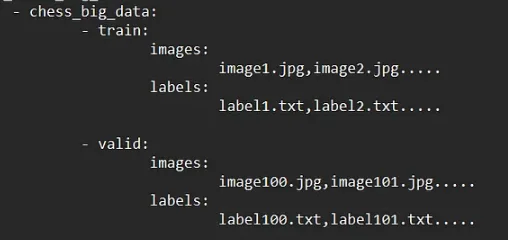
**Example YOLO format**
YOLO 格式範例
你可以將資料集拆分成訓練集和驗證集,比例隨你所想。你可以從 `slice_coco` 函式建立的切片資料集中看到幾個範例。
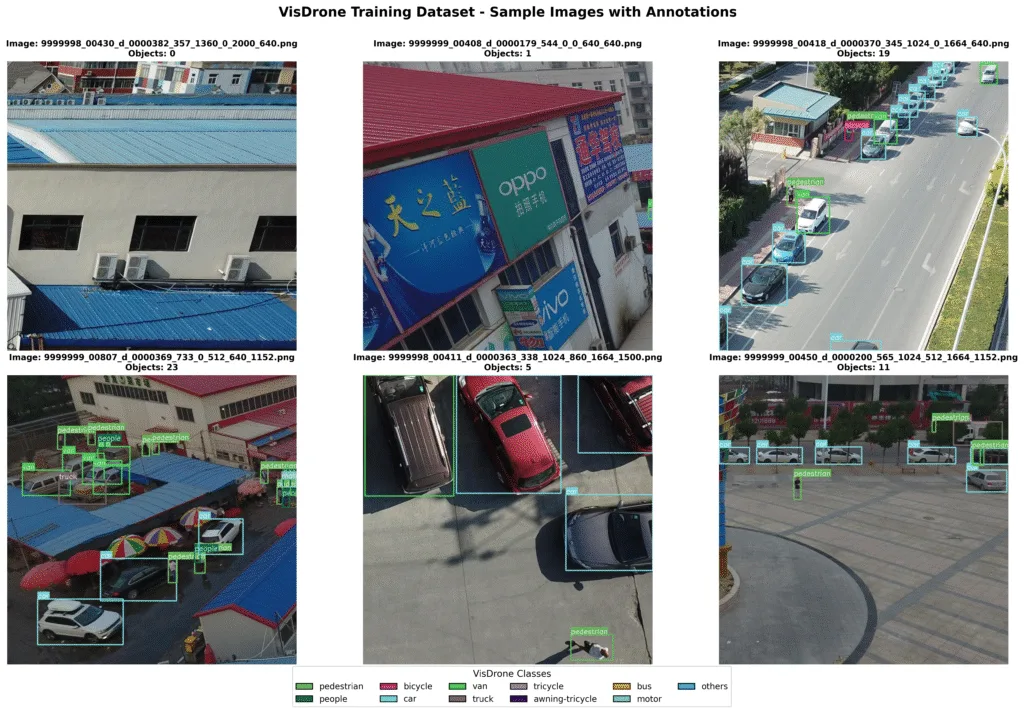
**Visdrone19-Detection dataset with annotations**
帶註解的 Visdrone19-Detection 資料集
### 建立 YAML 檔案
在開始訓練之前,還有幾個額外的步驟。因為我要訓練一個 YOLO 模型,我會建立一個包含資料集資訊的 YAML 檔案。
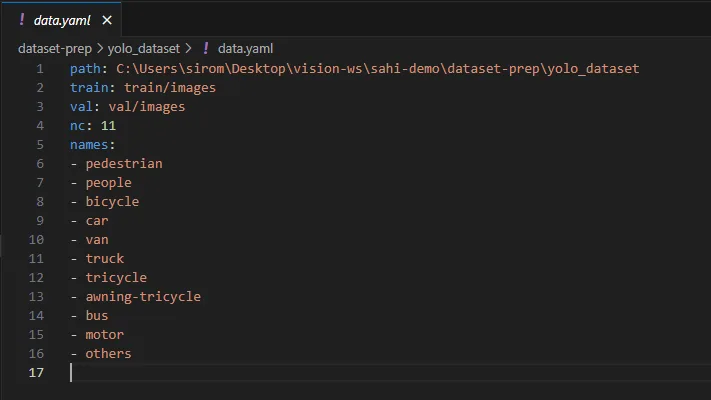
**YAML file for dataset**
資料集的 YAML 檔案
### 開始訓練
好,現在我們可以開始用切片資料集訓練了。我會把 `yolo11n.pt` 當作預訓練模型使用,但你也可以自由使用其他模型。
```python
from ultralytics import YOLO
model = YOLO('yolo11n.pt')
results = model.train(
data="dataset.yaml",
epochs=50,
imgsz=640,
batch=16,
name='yolo11_visdrone_sliced',
project='runs/train',
device='cuda',
patience=10,
save=True,
plots=True,
verbose=True
)
```
訓練開始了。即使我只用了 VisDrone19-Detection 資料集裡 2000×1500 解析度的影像,一個 epoch 大約花了 8 分鐘。2000×1500 解析度下有 772 張影像,切片後則有 9300 張。訓練 8 小時後結束。
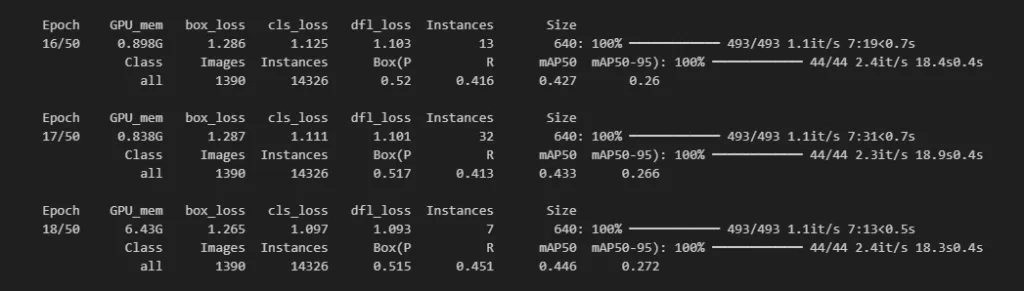
**Model training with sliced images**
使用切片影像進行模型訓練
### 測試新模型
現在,是時候測試新模型了。同樣地,我會用 `get_sliced_prediction` 函式搭配新訓練的模型。
```python
from sahi import AutoDetectionModel
from sahi.predict import get_sliced_prediction
best_model_path = "runs/train/yolo11_visdrone_sliced/weights/best.pt"
test_image = "../test_image.jpg"
detection_model = AutoDetectionModel.from_pretrained(
model_type='ultralytics',
model_path=best_model_path,
confidence_threshold=0.3,
device="cuda",
)
result = get_sliced_prediction(
test_image,
detection_model,
slice_height=640,
slice_width=640,
overlap_height_ratio=0.2,
overlap_width_ratio=0.2
)
result.export_visuals(export_dir="runs/predictions/")
```

**Small Object Detection with SAHI**
使用 SAHI 偵測小型物體
---
## 結語
好了,我就到這裡。希望你喜歡,如果有任何問題,歡迎隨時問我(siromermer@gmail.com)
---
## 參考資料
- SAHI Paper: https://arxiv.org/abs/2202.06934
- SAHI GitHub: https://github.com/obss/sahi
- Ultralytics: https://github.com/ultralytics/ultralytics