# Identification of task dependent accuracy discrepancies between CLIPort and TransporterNET
This research was performed by:
Lennard Dalenberg - 4933451 l.r.dalenberg@student.tudelft.nl
Jesse Dolfin - 5560047 j.r.dolfin@student.tudelft.nl
Bas Rutteman - 5429439 b.rutteman@student.tudelft.nl
## 1. Introduction
This blog post introduces a reproduction of a scientific paper in the field of Deep Learning. The reproduction serves as a learning goal for the course CS4240 - Deep Learning at the Technical University of Delft.
The originally proposed paper to be reproduced is *CLIPORT: What and Where Pathways for Robotic Manipulation* [1], however, due to hardware limitations we were unable to reproduce this paper. To understand the chosen alternative it is important to note that CLIPort consists of two networks, CLIP [2], and TransporterNET [3]. Furthermore, these individual networks are used in the CLIPort paper as baseline references for their results.
While analyzing both papers we noted that the results of the TransporterNet mentioned in the CLIPort and the TransporterNET paper itself did not match the same realm of accuracy for all tasks; accuracy discrepancies around 28% were not uncommon. We decided to investigate what could be the underlying cause of this discrepancy by reproducing the results of the TransporterNet. As guidance we used the original paper on TransporterNET: *Transporter Networks: Rearranging the Visual World for Robotic Manipulation* [3] ourselves.
Opposed to CLIPort, which required over 15 GB of VRAM and multiple days of training, TransporterNet could be trained using an NVIDIA V100 GPU in several hours. The GoogleCloud platform was used to gain access to such GPU for a limited amount of time.
The following two sub-sections are used to give an overview of both the CLIPort and TransporterNet papers. The next sections will discuss the goal of the paper reproduction followed by the methods used for the reproduction. We will finish the blogpost with results and draw a conclusion from them.
### 1.1 CLIPort
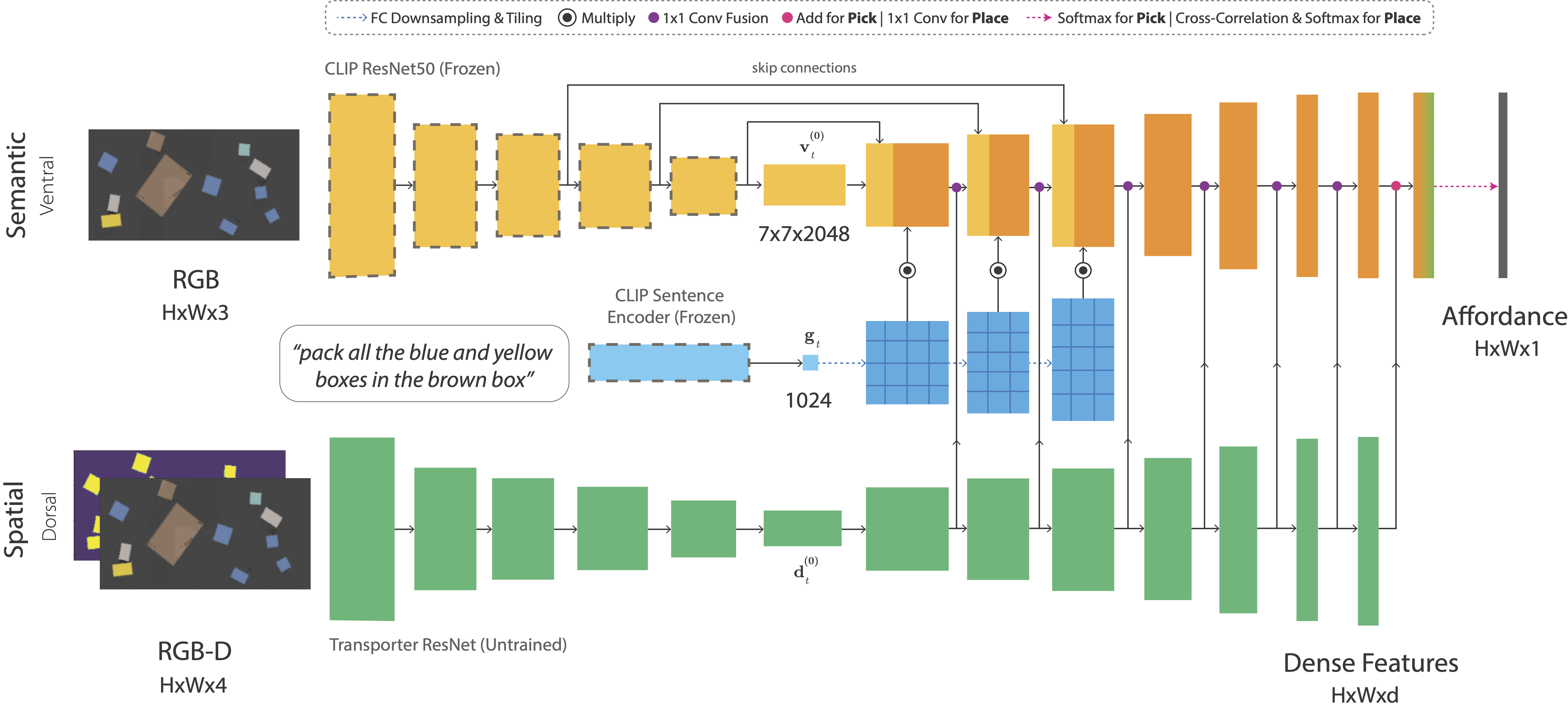
"CLIPort is Broadly inspired by (or vaguely analogous to) the two-stream hypothesis in cognitive psychology, it is a two-stream architecture for vision-based manipulation with semantic and spatial pathways. The semantic stream uses a pre-trained CLIP model to encode RGB and language-goal input. Since CLIP is trained with large amounts of image-caption pairs from the internet, it acts as a powerful semantic prior for grounding visual concepts like colors, shapes, parts, texts, and object categories. The spatial stream is a tabula rasa fully-convolutional network that encodes RGB-D input."[[CLIPort github](https://cliport.github.io/)].
Essentially CLIPort is a language-conditioned imitation learning agent that combines semantic understanding, i.e. the *what* of CLIP, with the spatial reasoning, or the *where*, of TransporterNET. This allows the CLIPort network to use natural language in task execution, for example: *fold the cloth* or *stack the towers of hanoi*. A visual overview of this two-stream network is provided below.
Please note that both the CLIP RESNET50 and CLIP Sentence encoder are frozen during training, only the TransporterNET is unfrozen.
### 1.2 TransporterNET
The TransporterNET revolves around the idea that "robotic manipulation can be formulated as inducing a sequence of spatial displacements: where the space being moved can encompass object(s) or an end effector" [3]. TransporterNET uses a simple architecture to deduct spatial movement from visuals as input. The inferred spatial movement can be discretized to encode robot actions. It is important to note that the network makes no assumptions of objectness but rather exploits spatial symmetries [3].
The transporterNET consist of an observation space, which is an orthographic top-down view of a tabletop workspace, generated in simulation. The top-down image has a resolution of 160x320 pixels, and the image contains both color (RGB) and scalar height-from-bottom (H) information. Here height-from-bottom means 'depth' when viewed from this top-down view.
Additionally, this network also consists of a picking model, which is a feed-forward FCN that takes as input the visual observation and outputs dense pixel-wise values that correlate with picking success. This network is an hourglass-shaped encoder decoder ResNet.
Lastly, the network consist of a placing model, this model consist of a two-stream feed-forward FCN that takes as input the visual observation again and outputs two dense feature maps: query features and key features. This model has the same hourglass ResNet architecture as the picking model, but without non-linear activations in the last layer.
The network is nicely visualized in the video below, first, the picking model finds the location of the object that needs to be picked up, this is labeled 'attention' in the video. Then the placing model finds the placing location by using the key and query values to find the location of both the object that needs to be picked up and its respective placing location, finally by convoluting these two values a new pixel representation is built where the placing location is highlighted.
<div style="text-align: center;">
<iframe width="400" height="400" src="https://www.youtube.com/embed/5pNeUzoz9Xk?&vq=hd1080&autoplay=1&loop=1" frameborder="0" allow="autoplay; encrypted-media" allowfullscreen></iframe>
</div>
## 2. Goal of paper reproduction
As mentioned before the underlying reason as to why we have chosen to reproduce only the TransporterNET part of the CLIPort network is due to the discrepancy between the accuracy this paper reports and the accuracy CLIPort reports for the same task. Additionally, by reproducing only the Transporter part we are not hindered by computational limitations. An overview of the actual discrepancies between various tasks can be found in the table shown below:
*The results reported in the CLIPort paper. Relevant results are highlighted in red.*

*The results reported in the TransporterNET paper. Relevant results are highlighted in red.*

In this reproduction we focus on the *assembling-kits* tasks as it shows the biggest discrepancy and achieves a relatively high accuracy score in TransporterNET paper. Indicating that it is an relatively easy task making it ideal for a hyperparameter study.
We hypothesize that this discrepancy arises from the amount of training steps performed during training. This hypotheis is based on the fact that reproduction guided by the TransporterNET paper does not evidently state how many training steps should be performed prior to evaluation. According to the GitHub of the TransporterNET training may be prematurely interrupted after it has reached 1000 training steps. We suspect that the CLIPort authors used this advise, inherently lowering the accuracy score.
The goal of this reproduction is to identify the source of reduced accuracy score between papers. And therefore suggesting an improved method to increase reproductionability of the TransporterNET paper.
## 3. Method
To elaborate on our hypothesis it is important to first implement a basic reproduction of the TransportNET accuracy scores. More specifically, the accuracy score on the *assembling-kits* task. This enables us to compare vanilla outputs (raw reproduction of the paper) with the reported accuracy scores in the CLIPort paper. Afterwards we can investigate how the improved accuracy scores can be obtained by varying different hyperparameter settings. In order to be able to perform these computations with the network in overseeable time due to limited hardware resources, a Google Cloud GPU VM Instance was created and used during the research. This instance featured a NVIDIA V100 GPU unit and a headless Ubuntu-based operating system.
The TransportNet code was made available on the VM by performing the following steps(taken from the GitHub of the TransporterNet).
* Step 1. Recommended: install Miniconda with Python 3.7.
curl -O https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh -b -u
echo $'\nexport PATH=~/miniconda3/bin:"${PATH}"\n' >> ~/.profile # Add Conda to PATH.
source ~/.profile
conda init
* Step 2. Create and activate Conda environment, then install GCC and Python packages.
cd ~/ravens
conda create --name ravens python=3.7 -y
conda activate ravens
sudo apt-get update
sudo apt-get -y install gcc libgl1-mesa-dev
pip install -r requirements.txt
python setup.py install --user
* Step 3. Recommended: install GPU acceleration with NVIDIA CUDA 10.1 and cuDNN 7.6.5 for Tensorflow.
./oss_scripts/install_cuda.sh # For Ubuntu 16.04 and 18.04.
conda install cudatoolkit==10.1.243 -y
conda install cudnn==7.6.5 -y
* It should be noted here the Github library was cloned into the miniconda directory, between the first and second line using the following command:
git clone https://github.com/google-research/ravens.git
To obtain the vanilla accuracy scores four different training- and test-sets are generated, depending on the amount of expert oracle demonstrations: 1, 10, 100 and 1000 demos respectively. Then the TransporterNET is trained on these training sets using 1k iterations *(n_steps=1000)*. After training, the network is evaluated on all test sets.
To investigate our hypothesis, we extended the vanilla reproduction by adjusting various hyperparameter settings, one at a time, during training of the network. This way we can evaluate the influence of the hyperparameters on the accuracy scores to see if we can improve on the performance of this vanilla network. The hyperparameters that are investigated are: *number of training steps*, *learning rate* and *evaluation metric*.
The influence of the number of training steps is evaluated by using the previously generated training- and test-sets of 100 and 1000 expert oracle demonstrations. For each respective set, the network was trained for 40k iterations *(n_steps=40,000)*. Afterwards the network was evaluated on the test sets of the same sizes.
The effect of learning rate and evaluation metric are evaluated in the same way. The vanilla network is used and either the learning rate or evaluation metric is changed. The default hyperparameter values are 1e-4 for the learning rate and the Mean as performance evaluation metric using the TensorFlow Keras library.
During evaluation of the learning rate and performance metric new training and test sets were generated of 10 expert oracle demo's to lower the computational costs of the network to save Google Credits as these were limited and necessary for Google VM use. To evaluate the effect of these hyperparameters fairly, the network is trained and evaluated with both the default and adjusted hyperparameter value on the smaller data set. The applied hyperparameter values can be found in the table below.
| Learning rates | Evaluation metrics |
| -------------- | -------------------- |
| 1e-4 | MeanSquaredError |
| 3e-4 | MeanAbsoluteError |
| - | RootMeanSquaredError |
## 4. Results
The obtained results can be subdivived into the vanilla reproduction of TransporterNet and the evaluated hyperparameters.
The results of the vanilla reproduction(n_steps = 1000 during training) of the TransporterNet *assembling-kits* task are shown in the table below.
| n_demos (train) | Accuracy score |
| --------------- | -------------- |
| 1 | 0.11 |
| 10 | 0.21 |
| 100 | 0.22 |
| 1000 | 0.18 |
For the hyperparameter study the *n_training_steps* parameter was tested for both 100 and 1000 training demos. The result of this test can be found in the table below. As can be seen the accuracy scores are significantly higher compared to the achieved accuracy with the vanilla reproduction.
| n_demos | Accuracy |
| ------- | ---------- |
| 100 | 0.79 |
| 1000 | 0.94 |
Additionally the accuracy scores for the other evaluated hyperparameters are shown in the sorted tables below. These hyperparameters are tested on the vanilla reproduction of the network with *n_demos=10*.
| Learning Rate value | Accuracy Score | Evaluation metric | Accuracy score |
| ------------------- | -------------- | -------------------- | -------------- |
| 1e-4 (standard) | 0.22 | Mean (standard) | 0.22 |
| 3e-4 | 0.14 | MeanSquaredError | 0.18 |
| - | - | RootMeanSquaredError | 0.16 |
| - | - | MeanAbsoluteError | 0.14 |
## 5. Conclusion & Discussion
After conducting our initial experiments and generating the vanilla reproduction (with *n_steps=10*), we found that our accuracy did not match the reported accuracy of either the CLIPort or TransporterNET papers for n=1, 10, 100, and 1000 expert demos. Moreover, our accuracy did not improve with more demos, and in fact, decreased for n=1000 demos. We speculate that due to the limited number of training steps (only 1000), the network was unable to learn effectively. Additionally, since we matched the number of test demos to the number of train demos, the network had a larger pool of senarios it was evaluated on for n=1000 expert demos. Because of this the network faced more challenging scenarios on average during evaluation, reducing its accuracy.
We conducted a hyperparameter study and evaluated our results using various metrics, ultimately finding that the mean performed the best. It was also found that the standard learning rate of 1e-4 was the most optimal out of the tested values. For the second part of the study, we trained the network for *n_steps=40,000* iterations and found that our accuracy scores matched those reported by TransporterNET. The CLIPort paper mentiones in appendix B under 'validation performances' that it used somewhere between 1k to 200k training steps but does not specifically mention how many training steps it used for their results of Transporter-only. Therefore we suspect that CLIPort likely interrupted their training procedure somewhere between 1k and 40k training steps, which caused them to report a lower accuracy score with respect the the accuracy reported by TransporterNET.
While we were able to evaluate all that we set out to evaluate, we acknowledge that, due to hardware limitations and limited time with google cloud, we were not able to conduct a very large reproduction study and we were not able to fully show the connection between TransporterNET and CLIPort's implementation of the transporter network 'Transporter-only'. Further studies should be conducted to examine if our obtained results can be used 1-to-1 in evaluation of both networks.
## 6. References
[1] Shridhar, M., Manuelli, L., & Fox, D. (2022, January). Cliport: What and where pathways for robotic manipulation. *In Conference on Robot Learning* (pp. 894-906). PMLR.
[2] Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., ... & Sutskever, I. (2021, July). Learning transferable visual models from natural language supervision. In *International conference on machine learning* (pp. 8748-8763). PMLR.
[3] Zeng, A., Florence, P., Tompson, J., Welker, S., Chien, J., Attarian, M., ... & Lee, J. (2021, October). Transporter networks: Rearranging the visual world for robotic manipulation. In *Conference on Robot Learning* (pp. 726-747). PMLR.
## 7. Appendix
### 7.1 Division of Tasks
| Tasks | People Responsible |
| ------------------------------------ | ---------------------------- |
| Writing introduction | Jesse D., Lennard D. |
| Writing "Goal of paper reproduction" | Lennard D. |
| Writing Method | Bas R., Lennard D. |
| Writing Results | Bas R. |
| Writing Conclusion & Discussion | Jesse D. Bas R. |
| Reproduction of CLIPORT-results | Jesse D., Lennard D., Bas R. |
| Hyperparameter check Trainingsteps | Jesse D., Lennard D., Bas R. |
| Hypermarameter check Metrics | Bas R. |
| Hyperparameter check Learning rate | Lennard D., Jesse D. |
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet