# Pytorch 基本教學
* **教學影片**:
* ==[ML2021 Pytorch tutorial part 1](https://www.youtube.com/watch?v=8DaeP2vSu90)==
* ==[ML2021 Pytorch Tutorial part 2](https://www.youtube.com/watch?v=CyV3zbcuufs)==
* **程式碼範例**:
* colab:[Pytorch Tutorial](https://colab.research.google.com/github/ga642381/ML2021-Spring/blob/main/Pytorch/Pytorch_Tutorial.ipynb)
---
## 先備知識
需具備以下基礎:
* **Python 3**:
* 熟悉 `if-else` 條件判斷、迴圈 (`loop`)、函式 (`function`) 定義、檔案輸入輸出 (file IO)、類別 (`class`) 等基本語法與概念。
* 參考資料:[Python 官方教學](https://docs.python.org/3/tutorial/), [Google's Python Class](https://developers.google.com/edu/python/), [Learn Python the Hard Way](https://learnpythonthehardway.org/python3/)
* **NumPy**:
* 了解 NumPy 的陣列 (`array`) 操作。
* 參考資料:[NumPy 官方教學](https://numpy.org/doc/stable/user/quickstart.html)
---
## 什麼是 PyTorch?
PyTorch 是一個開源的機器學習 (machine learning) 框架。它主要提供以下兩個高級功能:
* **Tensor (張量) 計算**:類似 NumPy 的陣列運算,但具有強大的 GPU 加速能力。Tensor 可以在圖形處理單元 (Graphics Processing Unit, GPU) 上運行以加速計算。
* **基於 TAPE 的自動微分 (Autograd) 系統**:用於建構與訓練深度神經網路,能夠自動計算梯度 (gradient),這是訓練 DNN 最重要的部分之一。

---
## PyTorch v.s. TensorFlow
PyTorch 和 TensorFlow 是目前最主流的兩個深度學習框架。它們的主要差異如下:
| 特性 | PyTorch | TensorFlow |
| :---------- | :---------------------------------------- | :----------------------------------------------- |
| **開發者** | Facebook AI | Google Brain |
| **介面** | Python & C++ | Python, C++, JavaScript, Swift |
| **除錯** | 相對容易 (動態圖) | 舊版較難,2.0 版後改善 (預設 Eager Execution) |
| **應用** | **研究領域**較受歡迎 (快速開發、易於除錯) | 工業界**產品部署**較多 |
TensorFlow 可以在更多平台上運行,例如 JavaScript 或 Swift。PyTorch 因為其易用性和除錯的便利性,在學術研究中更受青睞。本課程將主要使用 PyTorch。
---
## DNN 訓練流程概覽
訓練一個深度神經網路通常包含以下步驟,PyTorch 提供了相應的模組來支持這些步驟:
1. **載入資料 (Load Data)**:
* 這是訓練模型的第一步,你需要先有資料才能進行後續操作。
* PyTorch 提供 `torch.utils.data.Dataset` 和 `torch.utils.data.DataLoader` 來處理資料載入。
2. **定義神經網路 (Define Neural Network)**:
* 建構你的模型架構。
* 使用 `torch.nn` 模組。
3. **定義損失函數 (Loss Function)**:
* 衡量模型預測結果與真實答案之間的差距。
* 同樣在 `torch.nn` 中定義。
4. **定義優化器 (Optimizer)**:
* 根據損失函數計算出來的梯度來更新模型的權重,執行梯度下降 (gradient descent) 等優化算法。
* 使用 `torch.optim` 模組。
5. **訓練 (Training)**:
* 將資料輸入模型,計算損失,反向傳播計算梯度,並使用優化器更新模型參數。
6. **驗證 (Validation)**:
* 在訓練過程中,使用驗證集評估模型性能,檢查模型是否有進步,並用於調整超參數或判斷是否發生過擬合。
7. **測試 (Testing)**:
* 訓練完成後,使用獨立的測試集評估模型的最終性能。
訓練和驗證步驟通常會重複多次 (多個 epochs)。

---
## Tensor (張量)
Tensor 是 PyTorch 中的核心資料結構,可以理解為一個高維度的矩陣 (matrix) 或陣列 (array)。
* 一維 Tensor:向量 (vector)
* 二維 Tensor:矩陣 (matrix)
* 三維 Tensor:可以想像成一個立方體

### Tensor 資料型態 (Data Type)
Tensor 中最常儲存的是浮點數 (floating point) 和整數 (integer)。
| 資料型態描述 | `dtype` | Tensor 建立函式 |
| :------------------- | :------------ | :-------------------- |
| 32-位元 floating point| `torch.float` | `torch.FloatTensor` |
| 64-位元 integer (signed) | `torch.long` | `torch.LongTensor` |
> 更多資料型態可參考:[PyTorch Tensors 文件](https://pytorch.org/docs/stable/tensors.html)
### Tensor 的形狀 (Shape)
Tensor 的形狀描述了其在各個維度上的大小。
* **一維 Tensor**:例如 `[1, 2, 3, 4, 5]`,其 shape 為 `(5,)`。
* **二維 Tensor (矩陣)**:例如一個 3 個 row、5 個 column 的矩陣,其 shape 為 `(3, 5)`。
* **三維 Tensor**:例如一個 4x5x3 的立方體,其 shape 為 `(4, 5, 3)`。
維度 (Dimension) 的索引從 0 開始。PyTorch 中的 `dim` 與 NumPy 中的 `axis` 是相同的概念。

### Tensor 建構器 (Constructor)
有幾種常見的方式可以創建 Tensor:
1. **從 Python list 或 NumPy array 轉換**:
```python=
# From list
x = torch.tensor([[1, -1], [-1, 1]])
# From NumPy array
import numpy as np
arr = np.array([[1, -1], [-1, 1]])
x = torch.from_numpy(arr)
```
轉換後的 `x` 會是:
```
tensor([[ 1., -1.],
[-1., 1.]])
```
2. **創建全零 Tensor**:使用 `torch.zeros()`,需要指定 shape。
```python=
x = torch.zeros([2, 2])
```
結果:
```
tensor([[0., 0.],
[0., 0.]])
```
3. **創建全一 Tensor**:使用 `torch.ones()`,需要指定 shape。
```python=
x = torch.ones([1, 2, 5])
```
結果:
```
tensor([[[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.]]])
```
### Tensor 常用運算 (Operators)
PyTorch 提供了豐富的 Tensor 運算。
* **`squeeze(dim=None)`**:移除 Tensor 中所有大小為 1 的維度。如果指定 `dim`,則只移除指定維度 (若其大小為 1)。
* 例如:一個 Tensor 的 shape 為 `(1, 2, 3)`,`x.squeeze(0)` 後,shape 變為 `(2, 3)`。

* **`unsqueeze(dim)`**:在指定的維度 `dim` 上增加一個大小為 1 的新維度。
* 例如:一個 Tensor 的 shape 為 `(2, 3)`,`x.unsqueeze(1)` 後,shape 變為 `(2, 1, 3)`。

* **`transpose(dim0, dim1)`**:交換指定的兩個維度 `dim0` 和 `dim1`。
* 例如:一個 Tensor 的 shape 為 `(2, 3)`,`x.transpose(0, 1)` 後,shape 變為 `(3, 2)`。

* **`cat(tensors, dim=0)`**:將多個 Tensor 沿著指定的維度 `dim` 串接 (concatenate) 在一起。除了串接的維度外,其他維度的 shape 必須相同。
* 例如:有三個 Tensor x, y, z,shape 分別為 `(2, 1, 3)`, `(2, 3, 3)`, `(2, 2, 3)`。
`w = torch.cat([x, y, z], dim=1)`
`w` 的 shape 會是 `(2, 1+3+2, 3)` 即 `(2, 6, 3)`。

* **算術運算**:
* 加法:`z = x + y`
* 減法:`z = x - y`
* 次方:`y = x.pow(2)` 或 `y = x ** 2`
* **聚合運算**:
* 加總:`y = x.sum()`
* 平均:`y = x.mean()`
> 更多運算子請參考:[PyTorch Tensor Operators](https://pytorch.org/docs/stable/tensors.html)
### Tensor - PyTorch v.s. NumPy
PyTorch 的 Tensor 操作在很多方面與 NumPy 相似。
* **屬性 (Attributes)**:
| PyTorch | NumPy |
| :------- | :------- |
| `x.shape`| `x.shape`|
| `x.dtype`| `x.dtype`|
* **形狀操作 (Shape manipulation)**:
| PyTorch | NumPy |
| :---------------------- | :------------------------ |
| `x.reshape()` / `x.view()` | `x.reshape()` |
| `x.squeeze()` | `x.squeeze()` |
| `x.unsqueeze(dim)` | `np.expand_dims(x, axis)` |
> 參考:[PyTorch for NumPy users](https://github.com/wkentaro/pytorch-for-numpy-users)
### Tensor - 運算裝置 (Device)
預設情況下,Tensor 和模組會在 CPU 上進行運算。PyTorch 允許將運算轉移到 GPU 上以獲得加速。
* **CPU**:`x = x.to('cpu')`
* **GPU**:`x = x.to('cuda')` (如果 CUDA 可用)
要使用 GPU,你需要有一張支援 CUDA 的 NVIDIA 顯示卡。
* **檢查 GPU 是否可用**:
```python
torch.cuda.is_available()
```
* **指定 GPU**:如果有多張 GPU,可以指定使用哪一張,例如 `cuda:0` (第一張), `cuda:1` (第二張) 等。
```python
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
x = x.to(device)
```
* **為什麼使用 GPU?**
GPU 擁有大量的核心,非常適合進行平行運算。矩陣運算通常可以分解為許多獨立的小運算,這些小運算可以在 GPU 的多個核心上同時執行,從而大幅提升運算速度。
> 參考:[What is a GPU and do you need one in Deep Learning?](https://www.quora.com/What-is-a-GPU-and-do-you-need-one-in-deep-learning-3)
---
## 如何計算梯度 (Gradient)?
PyTorch 的 `autograd` 套件提供了自動微分功能,用於計算 Tensor 的梯度。
假設我們有一個輸入 Tensor $X$,我們要計算一個輸出 $Z$,其計算方式為 $X$ 中每個元素的平方和:$$Z = \sum_i \sum_j X_{i,j}^2$$
$Z$ 對 $X$ 中任一元素 $X_{k,l}$ 的偏微分 (partial derivative) 為:$$\frac{\partial Z}{\partial X_{k,l}} = 2X_{k,l}$$
梯度 $\nabla_X Z$ 就是所有這些偏微分組成的矩陣。
在 PyTorch 中計算梯度的步驟如下:
1. **創建 Tensor 並設定 `requires_grad=True`**:告知 PyTorch 需要追蹤此 Tensor 的所有運算,以便計算梯度。
```python
x = torch.tensor([[1., 0.], [-1., 1.]], requires_grad=True)
```
2. **進行運算得到輸出 Tensor**:
```python
z = x.pow(2).sum() # 2次方後加總
```
3. **呼叫 `backward()` 方法**:從輸出 Tensor `z` 開始**反向傳播**計算梯度。
```python
z.backward()
```
4. **獲取梯度**:梯度會儲存在原始 Tensor 的 `.grad` 屬性中。
```python
print(x.grad)
```
結果會是:
```
tensor([[ 2., 0.],
[-2., 2.]])
```
這與我們手動計算的 $2X$ 是一致的。

---
## Dataset 與 DataLoader
為了有效地載入和處理資料,PyTorch 提供了 `Dataset` 和 `DataLoader` 兩個類別。
```python
from torch.utils.data import Dataset, DataLoader
```
### Dataset
`Dataset` 是一個抽象類別,用於表示資料集。你需要繼承 `Dataset` 並覆寫以下兩個方法來創建自訂的資料集:
* **`__init__(self, ...)`**:初始化函式。通常在這裡讀取資料、進行預處理 (例如 feature extraction 特徵提取)。
* **`__getitem__(self, index)`**:根據索引 `index` 返回一個樣本 (一筆資料)。`DataLoader` 會使用這個方法來獲取資料。
* **`__len__(self)`**:返回資料集的總大小 (樣本數量)。
```python=
class MyDataset(Dataset):
def __init__(self, file_path):
# 例如:讀取 CSV 檔案或圖片路徑列表
self.data = ... # 讀取資料並進行預處理
def __getitem__(self, index):
# 返回第 index 筆資料及其對應的標籤 (label)
sample = self.data[index]
# label = self.labels[index]
return sample #, label
def __len__(self):
return len(self.data)
```
### DataLoader
`DataLoader` 是一個迭代器,它將 `Dataset` 包裝起來,並提供批次 (batch) 讀取、資料打亂 (shuffle) 等功能。
* **創建 `DataLoader` 時的主要參數**:
* `dataset`:你創建的 `Dataset` 物件。
* `batch_size`:每次迭代返回的樣本數量 (一個 mini-batch 的大小)。
* `shuffle`:是否在每個 epoch 開始時打亂資料順序。通常在訓練時設為 `True`,在驗證和測試時設為 `False` (確保每次評估順序一致,避免結果變異)。
* `num_workers`:使用多少個子行程來載入資料。可以加速資料讀取。
```python=
my_dataset = MyDataset(file_path='path/to/your/data')
my_dataloader = DataLoader(dataset=my_dataset, batch_size=32, shuffle=True)
# 使用 DataLoader 範例
for epoch in range(num_epochs):
for data_batch in my_dataloader:
inputs, labels = data_batch
# ... 進行訓練 ...
```
* **`DataLoader()` 內部**:從 `Dataset` 中透過 `__getitem__` 獲取多筆資料 (數量等於 `batch_size`),然後將它們組合成一個 mini-batch 返回。

---
## torch.nn - 神經網路模組
`torch.nn` 模組包含了建構神經網路所需的各種工具,如網路層 (layers)、激活函數 (activation functions)、損失函數 (loss functions) 等。
### 神經網路層 (Neural Network Layers)
* **`nn.Linear(in_features, out_features)`**:全連接層 (fully-connected layer)。
* `in_features`:輸入特徵的維度。
* `out_features`:輸出特徵的維度。
* 輸入 Tensor 的 shape 可以是 `(*, in_features)`,其中 `*` 表示任意數量的其他維度 (通常是 batch size)。最後一個維度必須是 `in_features`。
* 輸出 Tensor 的 shape 會是 `(*, out_features)`。
* 例如:`layer = nn.Linear(32, 64)`。如果輸入 shape 為 `(N, 32)`,輸出 shape 為 `(N, 64)`。

* 一個線性層的運算可以表示為:$y = Wx + b$
* $x$:輸入向量 (shape:`in_features`)
* $W$:權重矩陣 (shape:`out_features * in_features`)
* $b$:偏差向量 (bias) (shape:`out_features`)
* $y$:輸出向量 (shape:`out_features`)

可以通過 `layer.weight` 和 `layer.bias` 來存取線性層的 weight 和 bias。
* `layer.weight.shape` 會是 `(out_features, in_features)`。(上圖為 `([64, 32])`)
* `layer.bias.shape` 會是 `(out_features,)`。(上圖為 `([64])`)
### 激活函數 (Activation Functions)
`torch.nn` 提供了多種激活函數,例如:
* **`nn.Sigmoid()`**:[Sigmoid 激活函數](https://hackmd.io/@Jaychao2099/imrobot1#%E7%A1%ACS%E5%9E%8B%E5%87%BD%E5%BC%8F-Hard-Sigmoid%EF%BC%9A)$$f(x) = \frac{1}{1 + e^{-x}}$$
* **`nn.ReLU()`**:[ReLU (Rectified Linear Unit) 激活函數](https://hackmd.io/@Jaychao2099/imrobot1#%E5%8F%A6%E4%B8%80%E6%BF%80%E6%B4%BB%E5%87%BD%E5%BC%8F%EF%BC%9AReLU-Rectified-Linear-Unit)$$f(x) = \max(0, x)$$

* 其他還有 `nn.Tanh()`, [`nn.Softmax()`](https://hackmd.io/@Jaychao2099/imrobot3#%E7%B6%B2%E8%B7%AF%E8%BC%B8%E5%87%BA%E8%88%87-Softmax-%E5%87%BD%E6%95%B8) 等工具。
### 損失函數 (Loss Functions)
`torch.nn` 中也定義了多種常用的損失函數:
* **`nn.MSELoss()`**:[均方誤差損失 (Mean Squared Error)](https://hackmd.io/@Jaychao2099/imrobot3#%E5%9D%87%E6%96%B9%E8%AA%A4%E5%B7%AE-Mean-Squared-Error-MSE),常用於**迴歸 (regression) 問題**。$$L(y, \hat{y}) = \frac{1}{N} \sum (y_i - \hat{y}_i)^2$$
* **`nn.CrossEntropyLoss()`**:[交叉熵損失 (Cross-Entropy Loss)](https://hackmd.io/@Jaychao2099/imrobot3#%E4%BA%A4%E5%8F%89%E7%86%B5-Cross-entropy),常用於**分類 (classification) 問題**。這個函數內部通常會結合 `LogSoftmax` 和 `NLLLoss`。$$L(y, \hat{y}) = - \frac{1}{N}\sum_{i} \hat{y}_i \ln(y'_i)$$
* 其他還有 `nn.L1Loss()`, `nn.BCELoss()` (二元交叉熵) 等。
### 建構自訂神經網路
要建構自己的神經網路,你需要創建一個繼承自 `nn.Module` 的類別。
* 在 `__init__(self)` 方法中:
* 呼叫 `super().__init__()`。
* 定義網路中需要用到的層 (layers)。這些層本身也是 `nn.Module` 的子類。
* 可以使用 `nn.Sequential` 來快速串聯多個層。`nn.Sequential` 是一個容器,它會按照層被加入的順序依次執行這些層。
* 在 `forward(self, x)` 方法中:
* 定義資料 `x` 如何在網路中前向傳播 (forward pass) 並得到輸出。
```python=
import torch.nn as nn
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
# 定義網路層
self.net = nn.Sequential(
nn.Linear(10, 32), # 輸入 10 維,輸出 32 維
nn.Sigmoid(), # Sigmoid 激活
nn.Linear(32, 1) # 輸入 32 維,輸出 1 維
)
def forward(self, x):
# 定義前向傳播路徑
return self.net(x)
# 使用模型
model = MyModel()
input_tensor = torch.randn(5, 10) # 假設 batch_size=5, input_features=10
output_tensor = model(input_tensor)
```
上述模型的結構:Input (10維) -> Linear(10, 32) -> Sigmoid -> Linear(32, 1) -> Output (1維)。

---
## torch.optim - 優化器模組
`torch.optim` 模組實現了多種優化算法,用於更新神經網路的參數 (weight 和 bias)。
* **`optim.SGD(params, lr, momentum=0, ...)`**:**隨機**梯度下降 (Stochastic Gradient Descent, SGD)。
* `params`:模型中需要被優化的參數。通常是 `model.parameters()`。
* `lr`:[學習率 (learning rate)](https://hackmd.io/@Jaychao2099/imrobot3#%E4%B8%89-%E6%B7%B1%E5%BA%A6%E5%AD%B8%E7%BF%92%E8%A8%93%E7%B7%B4%E6%8A%80%E5%B7%A7%EF%BC%9A%E8%87%AA%E5%8B%95%E8%AA%BF%E6%95%B4%E5%AD%B8%E7%BF%92%E9%80%9F%E7%8E%87-Adaptive-Learning-Rate),控制每次參數更新的步長。
* `momentum`:[動量 (momentum)](https://hackmd.io/@Jaychao2099/imrobot3#%E5%8B%95%E9%87%8F-Momentum),SGD 的一種改進,有助於加速收斂並減少震盪。
```python=
# 假設 model 和 criterion (損失函數) 已定義
# model = MyModel()
# criterion = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
```
* 其他[常用優化器](https://hackmd.io/@Jaychao2099/imrobot3#%E5%B8%B8%E8%A6%8B%E7%9A%84-sigma_it-%E8%A8%88%E7%AE%97%E6%96%B9%E6%B3%95):`optim.Adam()`, `optim.RMSprop()`, `optim.Adagrad()` 等。
---
## 神經網路訓練與評估
### 訓練準備 (Setup)
在開始訓練迴圈之前,需要完成以下設置:
1. **準備 dataset 和 data loader**:
```python=
dataset = MyDataset(file_path_train)
train_loader = DataLoader(dataset, batch_size=64, shuffle=True)
val_dataset = MyDataset(file_path_val)
val_loader = DataLoader(val_dataset, batch_size=64, shuffle=False)
```
2. **實例化模型並移至特定裝置**:
```python=6
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = MyModel().to(device)
```
3. **定義損失函數**:
```python=8
criterion = nn.MSELoss()
```
4. **定義優化器**:
```python=9
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
```
### 訓練迴圈 (Training Loop)
訓練通常在一個迴圈中進行,每個迴圈迭代稱為一個 epoch (完整遍歷一次訓練資料集)。
```python=10
num_epochs = 10
for epoch in range(num_epochs):
model.train() # 將模型設置為訓練模式
running_loss = 0.0
for inputs, labels in train_loader: # 假設 train_loader 已定義
# 1. 將資料移至指定裝置
inputs, labels = inputs.to(device), labels.to(device)
# 2. 清除舊的梯度 (非常重要!)
optimizer.zero_grad()
# 3. 前向傳播: 計算模型預測
outputs = model(inputs)
# 4. 計算損失
loss = criterion(outputs, labels)
# 5. 反向傳播: 計算梯度
loss.backward()
# 6. 更新參數
optimizer.step()
running_loss += loss.item()
print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {running_loss/len(train_loader):.4f}")
# (可選) 每個 epoch 後進行驗證
# ... validation code ...
```
**關鍵步驟解釋**:
* `model.train()`:告訴模型現在是訓練模式。這對某些層 (如 `Dropout`, `BatchNorm`) 很重要,它們**在訓練和評估時的行為不同**。
* `optimizer.zero_grad()`:在計算新的梯度之前,必須**清除上一步殘留的梯度**。否則梯度會累加。
* `loss.backward()`:計算損失相對於模型參數的梯度。
* `optimizer.step()`:根據 `loss.backward()` 計算得到的梯度來更新模型的參數。
### 驗證 (Validation)
在每個 epoch 結束後,通常會在驗證集上評估模型性能。
```python=40
model.eval() # 將模型設置為評估模式
total_val_loss = 0
with torch.no_grad(): # 在評估時不需要計算梯度,可以節省記憶體和計算
for inputs, labels in val_loader: # 假設 val_loader 已定義
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
total_val_loss += loss.item()
avg_val_loss = total_val_loss / len(val_loader)
print(f"Validation Loss: {avg_val_loss:.4f}")
# 根據 avg_val_loss 決定是否保存模型
```
**關鍵步驟解釋**:
* `model.eval()`:告訴模型現在是評估模式。
* `with torch.no_grad()`:在這個區塊內的運算**不會被追蹤梯度**,這在驗證和測試時是必要的,可以節省計算資源並防止意外的梯度計算。
### 測試 (Testing)
訓練完成後,在測試集上評估模型的最終性能。測試集上的資料模型之前從未見過。
```python=
model.eval() # 設置為評估模式
predictions = []
with torch.no_grad():
for test_inputs in test_loader: # 測試集通常只有輸入,沒有標籤
test_inputs = test_inputs.to(device)
outputs = model(test_inputs)
# 將預測結果移回 CPU 並轉換為 NumPy array (如果需要)
predictions.extend(outputs.cpu().numpy())
# 將 predictions 整理成提交格式,例如 CSV 檔案
```
* `.cpu()` 方法是將 Tensor 從 GPU 移回 CPU。
---
## 儲存與載入神經網路
訓練好的模型參數需要儲存起來,以便後續使用或繼續訓練。
* **儲存模型 (Save)**:通常儲存模型的 `state_dict` (狀態字典),它包含了模型的所有參數 (wieght 和 bias)。
```python=
torch.save(model.state_dict(), 'model_weights.pth')
```
* **載入模型 (Load)**:
1. 先創建一個和儲存時相同結構的模型實例。
2. 然後載入 `state_dict`。
```python=
model_loaded = MyModel() # 創建模型實例
model_loaded.load_state_dict(torch.load('model_weights.pth'))
model_loaded.to(device) # 不要忘記將模型移到適當的裝置
model_loaded.eval() # 如果是載入來做預測,設為評估模式
```
---
## 更多關於 PyTorch
* PyTorch 生態系中有許多其他實用的套件:
* **`torchaudio`**:用於處理**語音**和**音訊**資料。
* **`torchtext`**:用於處理**自然語言處理 (NLP) 任務**的資料。
* **`torchvision`**:包含了流行的**電腦視覺**資料集、模型架構和圖像轉換工具。
* **`skorch`**:一個將 PyTorch 與 scikit-learn 結合的套件,使得 PyTorch 模型可以像 scikit-learn 模型一樣使用。
* 一些有用的 GitHub repositories (使用 PyTorch):
* [Hugging Face Transformers](https://github.com/huggingface/transformers):提供了大量預訓練的 Transformer 模型 (如 BERT, GPT)。
* [Fairseq](https://github.com/facebookresearch/fairseq):用於 sequence-to-sequence 建模,適用於 NLP 和語音。
* [ESPnet](https://github.com/espnet/espnet):用於 end-to-end 語音處理,包括語音辨識、翻譯、合成等。
---
## PyTorch 文件查詢
[PyTorch 官方文件](https://pytorch.org/docs/stable/)是學習和解決問題的重要資源。
* 神經網路相關函式:`torch.nn`
* 優化演算法相關:`torch.optim`
* Dataset 和 DataLoader:`torch.utils.data`
### 文件查詢範例:`torch.max`
當查詢一個函式 (例如 `torch.max`) 時,注意以下幾點:
1. **函式簽名 (Function Signature)**:
* 第一行通常會顯示函式的輸入參數和輸出。
* 例如 `torch.max(input) → Tensor` 表示輸入 `input`,輸出一個 `Tensor`。

2. **參數說明 (Parameters & Keyword Arguments)**:
* 會詳細列出每個參數的名稱、型態和意義。
* **位置參數 (Positional Arguments)**:不需要指定參數名稱,按順序傳入即可。
* **關鍵字參數 (Keyword Arguments)**:必須指定參數名稱才能傳入值。通常在函式簽名中**以 `*` 分隔**位置參數和關鍵字參數。
* **預設值 (Default Value)**:某些參數有預設值,如果沒有傳入這些參數,函式會使用預設值。

3. **不同用法**:
一個函式可能有多種用法,根據輸入參數的不同,行為也會不同。以下為 **`torch.max` 的三種主要用法**:
1. **`torch.max(input) → Tensor`**:
* 返回整個 `input` Tensor 中的最大值。
* 例如 `x = torch.tensor([[1, 2, 3], [5, 6, 4]])`,`torch.max(x)` 返回 `tensor(6)`。
2. **`torch.max(input, dim, keepdim=False, *, out=None) → (Tensor, LongTensor)`**:
* 沿著指定的 `dim` 維度尋找最大值。
* 返回一個 tuple,包含兩個 Tensor:
* `values`:每個子陣列在 `dim` 維度上的**最大值**。
* `indices`:這些最大值在 `dim` 維度上的**索引**。
* `keepdim=True` 會保持原始維度數量,最大值所在的維度大小變為 1。
* 例如 `x = torch.tensor([[1, 2, 7], [5, 6, 4]])`
`values, indices = torch.max(x, dim=1)`
`values` 為 `tensor([7, 6])`,`indices` 為 `tensor([2, 1])`。
3. **`torch.max(input, other, *, out=None) → Tensor`**:
* 比較兩個 Tensor `input` 和 `other` (shape 需相同或可廣播),**逐元素取最大值**。
* 返回一個與 `input` (或廣播後) shape 相同的 Tensor。
* 例如 `x = torch.tensor([[1, 2, 3], [5, 6, 4]])`, `y = torch.tensor([[2, 4, 0], [1, 3, 5]])`
`torch.max(x, y)` 返回 `tensor([[2, 4, 3], [5, 6, 5]])`。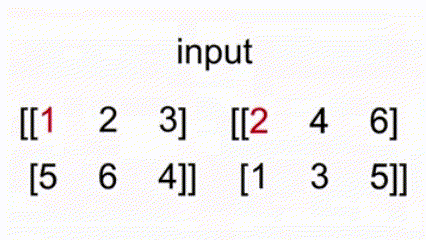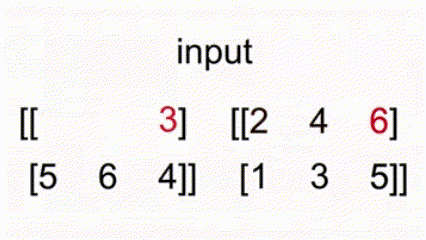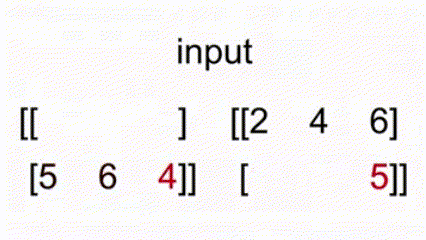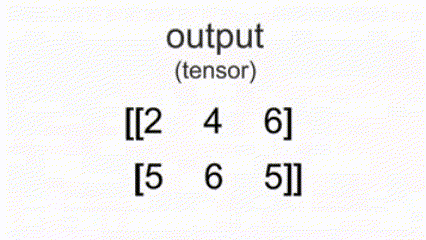
#### 程式碼範例:
```python=
import torch
x = torch.randn(4,5)
y = torch.randn(4,5)
# 1. max of entire tensor
m = torch.max(x)
print(m)
# 2. max along a dimension
m_val, idx = torch.max(x, dim=0) # 沿著第0維 (column-wise)
print(m_val)
print(idx)
# 錯誤範例:
m, idx = torch.max(x,0,False,p) # 'out' 是關鍵字參數,不能當作位置參數 p 傳入
m, idx = torch.max(x,True) # 未指定 dim,True 會被誤認為 dim
# (且 True 不能被視為 1)
# 3. max of two tensors
t = torch.max(x,y)
print(t)
```
---
## 常見錯誤 (Common Errors)
1. **Tensor 與 Model 在不同裝置 (Device Mismatch)**:
* **錯誤訊息類似**:
* `RuntimeError:Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu!`
* `Tensor for * is on CPU, but expected them to be on GPU`。
* **原因**:模型在 GPU 上,但輸入 Tensor 在 CPU 上 (或反之)。
* **解決**:確保模型和所有輸入 Tensor 都在同一個裝置上。
```python=
model = torch.nn.Linear(5,1).to("cuda:0")
x_cpu = torch.Tensor([1,2,3,4,5]).to("cpu")
y = model(x_cpu) # << 會報錯
# 修正
x_gpu = x_cpu.to("cuda:0")
y = model(x_gpu)
```
2. **維度不匹配 (Mismatched Dimensions)**:
* **錯誤訊息類似**:`RuntimeError:The size of tensor a (X) must match the size of tensor b (Y) at non-singleton dimension Z`。
* **原因**:進行運算的兩個 Tensor 在某個維度上的大小不一致,且無法進行廣播 (broadcasting)。
* **解決**:使用 `transpose()`, `squeeze()`, `unsqueeze()`, `view()`, `reshape()` 等操作來調整 Tensor 的 shape。
```python=
x = torch.randn(4,5)
y = torch.randn(5,4)
z = x + y # << 會報錯
# 修正
y_transposed = y.transpose(0,1) # y_transposed shape is (4,5)
z = x + y_transposed
```
這種錯誤可能發生在使用預訓練模型時,輸入資料的 batch size 或特徵維度與模型期望的不符。
3. **CUDA 記憶體不足 (CUDA Out-of-Memory)**:
* **錯誤訊息**:`RuntimeError:CUDA out of memory. Tried to allocate X MiB ...`。
* **原因**:一次性載入過多資料到 GPU,導致 GPU 記憶體耗盡。
* **解決**:
* 減小 `batch_size`。
* 如果不是使用 `DataLoader`,而是手動將整個資料集放入 GPU,請改用迭代方式或使用 `DataLoader`。
```python=
resnet18 = models.resnet18().to("cuda:0")
data = torch.randn(2048,3,244,244) # 假設是 2048 張 244x244 的 RGB 圖片
out = resnet18(data.to("cuda:0")) # << 可能 OOM
# 修正 (迭代處理)
for d_single_image in data:
# d_single_image shape:(3, 244, 244)
# resnet18 預期輸入 (N, C, H, W), 所以要 unsqueeze
out = resnet18(d_single_image.to("cuda:0").unsqueeze(0))
```
4. **Tensor 型態不匹配 (Mismatched Tensor Type)**:
* **錯誤訊息類似**:`RuntimeError:Expected scalar type Long but found Float`。
* **原因**:函式期望特定資料型態的 Tensor,但傳入的是其他型態。
* 常見於使用 `nn.CrossEntropyLoss` 時,其 `target` (標籤) 參數期望是 `torch.long` 型態的 Tensor,但可能不小心傳入了 `torch.float`。
* **解決**:將 Tensor 轉換為正確的型態,例如使用 `.long()` 或 `.float()`。
```python=
L = nn.CrossEntropyLoss()
outs = torch.randn(5,5) # 模型的輸出 (logits)
labels_float = torch.Tensor([1,2,3,4,0]) # 錯誤的型態
lossval = L(outs, labels_float) # << 會報錯
# 修正
labels_long = labels_float.long()
lossval = L(outs, labels_long)
```
注意 `torch.Tensor()` 預設創建的是 `torch.FloatTensor`。
---
## 補充:Dataset 和 DataLoader 的更多細節
`torch.utils.data.Dataset` 和 `torch.utils.data.DataLoader` 是 PyTorch 中處理資料的標準方式。
* **`Dataset` 的核心**:
* `__len__(self)`:告訴 `DataLoader` 資料集有多大。
* `__getitem__(self, idx)`:根據 `DataLoader` 提供的索引 `idx` (可能經過 shuffle),返回對應的資料點。
* **`DataLoader` 的作用**:
* 根據 `Dataset` 的 `__len__` 和 `batch_size` 產生索引。
* 如果 `shuffle=True`,會打亂索引順序。
* 將一批索引傳給 `Dataset` 的 `__getitem__` 來獲取一批資料。
* 將這批資料組合成一個 mini-batch。
### 範例:資料增強 (Data Augmentation) 的簡單實現
可以在 `Dataset` 的 `__getitem__` 中實現簡單的資料增強。例如,如果我們想讓資料集長度加倍,一半是原始小寫字母,另一半是大寫字母:
```python=
import torch.utils.data
class ExampleDataset(torch.utils.data.Dataset):
def __init__(self):
self.data = "abcdefghijklmnopqrstuvwxyz"
self.original_len = len(self.data)
def __getitem__(self, idx):
if idx >= self.original_len: # 索引超出原始長度,返回大寫
actual_idx = idx % self.original_len
return self.data[actual_idx].upper()
else: # 索引在原始長度內,返回小寫
return self.data[idx]
def __len__(self):
return 2 * self.original_len # 資料集長度變為兩倍
dataset1 = ExampleDataset()
dataloader = torch.utils.data.DataLoader(dataset=dataset1, shuffle=True, batch_size=1)
for datapoint in dataloader:
print(datapoint)
```
這個範例展示了如何在 `Dataset` 內部控制資料的返回方式和資料集的有效大小。
---
回[主目錄](https://hackmd.io/@Jaychao2099/aitothemoon)
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet