# 第十四講:多核處理器和 spinlock
> 本筆記僅為個人紀錄,相關教材之 Copyright 為[jserv](http://wiki.csie.ncku.edu.tw/User/jserv)及其他相關作者所有
* 直播:==[Linux 核心設計:多核處理器和 spinlock - 2018/12/27](https://www.youtube.com/watch?v=aYdQ4AtNVro)==
* 詳細共筆:[Linux 核心設計:多核處理器和 spinlock](https://hackmd.io/@sysprog/multicore-locks?type=view)
* 主要參考資料:
* [Concurrent Programming](https://www.cs.cmu.edu/afs/cs/academic/class/15213-f19/www/lectures/24-concprog.pdf)
* [Symmetric Multi-Processing](https://linux-kernel-labs.github.io/refs/heads/master/lectures/smp.html)
* [Synchronization: Basics](https://www.cs.cmu.edu/~213/lectures/24-sync-basic.pdf)
* [Synchronization: Advanced](https://www.cs.cmu.edu/~213/lectures/25-sync-advanced.pdf)
* [Thread-Level Parallelism](http://www.cs.cmu.edu/~213/lectures/26-parallelism.pdf)
* [Linux kernel synchronization](http://www.cs.unc.edu/~porter/courses/cse506/s16/slides/sync.pdf)
* [Synchronization primitives in the Linux kernel. Part 1](https://0xax.gitbooks.io/linux-insides/SyncPrim/linux-sync-1.html)
* [Kernels and Locking](https://retis.santannapisa.it/luca/KernelProgramming/Slides/kernel_locking.pdf)
* [Mutual exclusion, synchronization,communicationin shared memoryOperating systems](https://www.mit.bme.hu/eng/system/files/oktatas/targyak/8699/opre_slides12_mutex_en_1.pdf)
---
## 引言
本課將深入探討 Linux 核心中最基礎也最關鍵的同步機制 Spinlock。從並發程式設計的基本挑戰出發,層層剖析從高階的 Mutex 與 Semaphore 概念,到 Spinlock 在多核處理器 (Multi-core Processor) 架構下的硬體實作細節、效能瓶頸,以及其與中斷處理和核心搶佔 (Kernel Preemption) 的複雜互動。
---
## 自我檢查清單
在開始之前,可以先評估一下自己對以下問題的掌握程度。這些問題涵蓋了本課程的核心議題,在學習完本筆記後,應該能對這些問題有清晰的理解。
- [x] **Atomic Context**:知道 Linux 核心的 atomic context 出現於哪些場合嗎?
- [x] **Busy-Waiting**:教科書常說 Spinlock 是一種 busy-waiting,那它到底在「忙」什麼?對應於現代處理器,它實際做了哪些事?
- [ ] **Disable Interrupt**:Spinlock 的實作可能涉及停用中斷 (disable interrupt),這對作業系統的 latency 和 scalability 有何影響?
- [ ] **Livelock**:除了 Deadlock,Spinlock 還可能導致 Livelock,你知道為什麼嗎?
- [x] **Kernel Preemption**:為了提升 Kernel Preemption,核心開發者致力於避免停用中斷。在這種情況下,該如何確保共享資料的正確性?(提示:`preempt_count`)
- [ ] **Sleeping Spinlocks**:在 `PREEMPT_RT` 環境下,Spinlock 會變成可以「睡眠」(sleeping) 的鎖,那麼 Critical Section 的概念還適用嗎?
- [ ] **Threaded IRQ**:什麼是 Threaded IRQ?它如何對應到現代處理器的中斷處理機制?
- [ ] **IRQ 分類**:hard IRQ 和 soft IRQ (或稱 Bottom Half, BH) 的關聯為何?`ksoftirqd` 核心執行緒的運作機制是什麼?
> 延伸閱讀:
> * [第十講:中斷處理和現代架構考量](https://hackmd.io/@Jaychao2099/Linux-kernel-10)
> * [第十三講:淺談同步機制](https://hackmd.io/@Jaychao2099/Linux-kernel-13)
---
## Symmetric Multi-Processing (SMP) 的衝擊:重新思考 Critical Section 與互斥
並發 (Concurrency) 程式設計的核心挑戰在於管理多個執行單元對共享資源的存取。當多個 thread 或 process 同時執行,其指令序列的交錯 (interleaving) 可能會導致非預期的結果,這種情況稱為 **Race Condition (競爭條件)**。
**SMP (對稱多處理)** 架構的普及,是 Linux 核心同步機制變得複雜的根本原因。在單核時代,同步主要處理的是 **process 與 interrupt 之間** 的 race condition;而在多核時代,還必須處理 **多個 CPU 核心之間** 真正的並行執行,使得舊有的同步方法不再足夠。
### 核心中並行的來源
即便在單核心系統上,並行問題依然存在,主要來自兩種形式的「偽並行」(pseudo-concurrency):
1. **中斷搶佔 (Interrupt Preemption)**:一個硬體中斷可以在任何時刻發生,打斷目前正在執行的核心程式碼,轉而執行中斷服務常式 (ISR)。如果 ISR 和被中斷的程式碼存取了相同的共享資料,就會產生 Race Condition。
2. **行程搶佔 (Process Preemption)**:在啟用核心搶佔 (Kernel Preemption) 的系統中,一個高優先權的 process 可以中斷正在核心態執行的低優先權 process,引發 process 之間的並行問題。
在單核心的世界裡,上述問題有一個相對簡單的解法:**停用本地中斷 (disabling local interrupts)**。透過 `local_irq_disable()` 這類指令,可以確保在 Critical Section 執行期間,不會有任何中斷或排程事件發生,從而達成互斥。
然而,SMP 架構的出現引入了 **真正的並行 (true parallelism)**。多個 CPU 核心可以在 **同一時刻** 獨立執行不同的指令。意味著 **在 CPU 0 上停用中斷,完全無法阻止 CPU 1 存取同一個共享記憶體位址**。舊有的同步方法瞬間失效,核心開發者必須面對一個全新的、更複雜的跨核心同步挑戰。
<center><img src="https://hackmd.io/_uploads/B1AGWEBvll.png" alt="image" width="75%" /></center>
### SMP 如何破壞簡單的同步
一個典型的例子是計數器遞增操作:
```c=
volatile long cnt = 0; // 全域計數器
void *thread(void *vargp) {
long max = *((long *)vargp);
for (long i = 0; i < max; i++) cnt++; // 遞增
return NULL;
}
int main(int argc, char **argv) {
long max;
pthread_t tid1, tid2;
max = atoi(argv[1]);
pthread_create(&tid1, NULL, thread, &max); // thread A
pthread_create(&tid2, NULL, thread, &max); // thread B
pthread_join(tid1, NULL);
pthread_join(tid2, NULL);
if (cnt != (2 * max)) printf("Wrong! cnt=%ld\n", cnt);
else printf("Correct! cnt=%ld\n", cnt);
exit(0);
}
```
遞增操作在組合語言層面,至少包含三個獨立操作:
1. **讀取 (Load)**:從記憶體中讀取 `cnt` 的目前值到處理器的暫存器。
2. **更新 (Update)**:將暫存器中的值 + 1。
3. **寫入 (Store)**:將暫存器中的新值寫回記憶體。
```asm=
thread: # 前置作業 記為 H (head)
mov rcx, QWORD PTR [rdi]
test rcx, rcx
jle .L2
xor edx, edx
.L3:
mov rax, QWORD PTR cnt[rip] # 讀取 cnt 記為 L (load)
add rax, 1 # cnt++ 記為 U (update)
mov QWORD PTR cnt[rip], rax # 寫入 cnt 記為 S (store)
# 後續作業 記為 T (tail)
add rdx, 1 # i++
cmp rcx, rdx
jne .L3
.L2:
...
```
假設兩個執行緒 (Thread A, Thread B) 同時執行 `cnt++`,而 `cnt` 初始值為 0。一種可能的交錯順序如下:
1. Thread A **讀取** `cnt` (值為 0) 到 **自己的暫存器**。
2. 系統排程切換,Thread B 開始執行。
3. Thread B **讀取** `cnt` (值仍為 0),進行 **更新** (暫存器變為 1),並 **寫回** 記憶體。此時 `cnt` 的值為 1。
4. 系統排程再次切換回 Thread A。
5. Thread A 基於它 **先前讀取的舊值 0** 進行 **更新** (暫存器變為 1),並 **寫回** 記憶體。`cnt` 的值最終仍為 1。
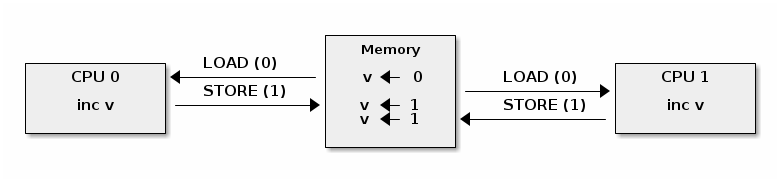
雖然兩個 thread 都執行了遞增操作,但最終結果卻是 1 而非預期的 2,這就是 Data Race 導致的錯誤。
實驗也顯示,結果不一定會正確:
```shell
$ ./badcnt 10000
Correct! cnt=20000
$ ./badcnt 10000
Wrong! cnt=10238
```
### Critical Section 關鍵區段
為了防止 Data Race,需要識別出程式中存取共享資源的程式碼區段,並確保其執行的原子性 (atomicity)。這段程式碼被稱為 **Critical Section (CS, 關鍵區段)**。
#### Progress Graph (進度圖) 與不安全區域 (Unsafe Region)
將此概念視覺化。進度圖是一個 N 維空間 (N 為 thread 數量),每個軸代表一個 thread 的執行進度。圖中的每一個點代表系統的一個狀態,而一條從左下角到右上角的軌跡線 (trajectory) 則代表一種可能的指令交錯順序。
<center><img src="https://hackmd.io/_uploads/S1Jj7XBPll.png" alt="image" width="80%" /></center>
當兩個 thread 的 Critical Section (如 `L`, `U`, `S` 操作) 發生交錯時,軌跡線會進入圖中的「不安全區域」(Unsafe Region)。任何進入此區域的執行路徑都可能導致錯誤的結果。<center><img src="https://i.imgur.com/EU3fibV.png" alt="image" width="80%" /></center>
為了保證程式的正確性,必須採用一種機制,強制所有執行軌跡線都繞開這個不安全區域。這種確保在任何時間點,最多只有一個 thread 能進入 Critical Section 的機制,稱為 **Mutual Exclusion (互斥)**。

> 延伸閱讀:
> * [Symmetric Multi-Processing](https://linux-kernel-labs.github.io/refs/heads/master/lectures/smp.html)
> * [Synchronization: Basics](https://www.cs.cmu.edu/~213/lectures/24-sync-basic.pdf)
> * [Synchronization: Advanced](https://www.cs.cmu.edu/~213/lectures/25-sync-advanced.pdf)
---
## 高階鎖定機制:Semaphore vs. Mutex
在 Linux 核心中,Semaphore 和 Mutex 是兩種常見用來實現互斥的高階同步工具,但它們在概念和用途上存在根本差異。
* **Mutex (Mutual Exclusion lock, 互斥鎖)**:
* **核心概念**:強調 **「擁有權」(ownership)**。一個 thread 取得了 Mutex,就必須由同一個 thread 來釋放。它像一把鑰匙,誰鎖上了門,就必須由誰來開鎖。
* **主要用途**:保護一段程式碼 (Critical Section),確保只有一個 thread 可以執行它,主要用於解決資源的獨佔存取問題。
* **實作考量**:一個設計完善的 Mutex 必須處理 **Priority Inversion (優先權反轉)** 的問題。
* **Semaphore (號誌)**:
* **核心概念**:強調 **「訊號傳遞」 (Signaling)**,是一種更通用的同步機制,本質上是一個計數器,用於控制能同時存取某個資源的 thread 數量。它不強調擁有權,一個 thread 可以發出訊號 (V 操作,增加計數),而另一個 thread 可以等待訊號 (P 操作,減少計數)。
* **主要用途**:常用於解決 **「生產者-消費者」** 問題,或者控制對一組有限資源的存取。例如,一個計數為 N 的 Semaphore 允許最多 N 個 thread 同時存取資源。
> [!Note]**注意**:
> 一個特殊的 Semaphore 稱為 **Binary Semaphore**,其計數值僅為 0 或 1。在某些作業系統的實作中,**Binary Semaphore** 的程式碼可能與 **Mutex** 非常相似,甚至共用。儘管如此,它們在 **概念上** 依然存在「持有者」與「訊號傳遞」的根本區別。
### Mutex 與優先權反轉 (Priority Inversion)
這是即時系統 (Real-time System) 中一個經典且嚴重的問題,尤其與 Mutex 相關。想像以下情境:
1. 系統中有三個任務:高優先權 (H)、中優先權 (M)、低優先權 (L)。
2. 任務 H 和 L 需要存取一個由 Mutex 保護的共享資源。
3. **時間點 T1**:任務 L 執行並取得了 Mutex。
4. **時間點 T2**:任務 H 準備就緒,因其優先權高於 L,它試圖搶佔 L。但由於 L 持有 H 所需的 Mutex,H 必須等待 L 釋放鎖,因此 H 進入阻塞狀態。
5. **時間點 T3**:任務 M (不需該 Mutex) 準備就緒。因為 M 的優先權高於 L,M 搶佔了 L 的執行。
此時,系統出現了**優先權反轉**:高優先權的任務 H 正在等待低優先權的任務 L,而 L 又被中優先權的 M 所搶佔。如果 M 執行很長時間,L 就無法執行並釋放 Mutex,從而導致 H 也一直被阻塞。這使得系統的優先權規則失效,高優先權任務的即時性無法得到保證。
> [!Tip]**經典案例**:
> 1997 年的火星拓荒者號 (Mars Pathfinder) 就因 **Priority Inversion** 問題,導致系統不斷重啟。為了解決此問題,**Mutex** 的實作通常會引入 **Priority Inheritance (優先權繼承)** 或 **Priority Ceiling (優先權天花板)** 等協定。當高優先權任務等待鎖時,暫時將持有鎖的低優先權任務的優先級提升至與等待者相同,使其能盡快完成並釋放資源,從而避免被中優先權任務搶佔。
> 延伸閱讀:[第十三講:淺談同步機制 - Mutex 與 Semaphore 的區別](https://hackmd.io/@Jaychao2099/Linux-kernel-13#Mutex-%E8%88%87-Semaphore-%E7%9A%84%E5%8D%80%E5%88%A5)
---
## Spinlock:核心同步的基石
Semaphore 和 Mutex 屬於高階、可能涉及睡眠和排程器介入的鎖。然而,它們的實作本身依賴於一個更底層、更基礎的鎖定機制,特別是在多核處理器環境下,就是 **Spinlock**。
Spinlock 是一種 **忙碌等待 (busy-waiting)** 的鎖。當一個 CPU 核心嘗試獲取一個已被其他核心持有的 Spinlock 時,它不會進入睡眠狀態,而是會在一個迴圈中不斷地「旋轉」(spin),檢查鎖是否已被釋放。
### Spinlock 的通用原則:
1. **適用場景**:僅用於保護非常短的 Critical Section。因為在等待期間,CPU 持續空轉,浪費處理器週期。
2. **不可睡眠**:持有 Spinlock 的程式碼路徑中,絕對不能發生會導致睡眠或排程的行為 (如呼叫 `kmalloc(GFP_KERNEL)`、等待 I/O 等),否則可能導致 Deadlock。
3. **與中斷的關係**:如果 Spinlock 保護的資料可能被中斷處理程序存取,那麼在獲取鎖時必須同時關閉本地中斷。
### 硬體基礎:Atomic Instructions
Spinlock 的實作仰賴於硬體提供的 **Atomic Instructions (原子指令)**。這些指令由處理器保證在執行過程中不會被其他 CPU 或中斷所打斷,是實現所有同步機制的基礎。常見的原子指令包括:
* **Atomic Increment/Decrement**:原子地對一個整數進行 + 1 或 - 1 操作。
* **Test-and-Set**:測試一個記憶體位置的值,並將其設定為新值,這整個過程是原子的。
* **Compare-and-Swap (CAS)**:比較一個記憶體位置的值與一個期望值,若相符,則將其更新為一個新值。
### 效能瓶頸:Cache Coherence
在多核處理器 (SMP, Symmetric Multi-Processing) 系統中,Spinlock 的效能面臨巨大挑戰,其根源在於 **Cache Coherence (快取一致性)**。
現代 CPU 每個核心都有自己的 L1、L2 快取,並共享 L3 快取或主記憶體。為了確保所有核心看到一致的記憶體視圖,必須有一套協定來同步各個快取中的資料。最常見的協定是 **MESI**:
* **M (Modified)**:Cache Line 內容已被修改,與主記憶體不一致,且僅存在於此核心的快取中。
* **E (Exclusive)**:Cache Line 內容與主記憶體一致,且僅存在於此核心的快取中。
* **S (Shared)**:Cache Line 內容與主記憶體一致,且可能存在於多個核心的快取中。
* **I (Invalid)**:Cache Line 內容無效。
當一個核心對某個記憶體位址進行寫入時,MESI 協定會使其餘所有擁有該資料副本的核心 Cache Line 都變為 `Invalid`。這就是所謂的「寫入-失效」(write-invalidate) 協定。
這個機制對 Spinlock 造成了致命的效能問題,稱為 **Cache Line Bouncing (快取行彈跳)**:
1. 假設 $\text{CPU}_0$ 持有 Spinlock,而 $\text{CPU}_1$、$\text{CPU}_2$ ... $\text{CPU}_n$ 都在 busy-waiting。
2. 一個簡單的 Spinlock 實作會讓等待者不斷嘗試用原子指令 (如 `Test-and-Set`) 去修改鎖變數。
3. 每次 $\text{CPU}_1$ 嘗試寫入,就會觸發快取一致性協定,將 $\text{CPU}_0$、$\text{CPU}_2$ ... $\text{CPU}_n$ 中對應的 Cache Line 設為 `Invalid`。
4. 接著 $\text{CPU}_2$ 嘗試寫入,又會讓其他所有核心的 Cache Line 失效。
5. 導致存放鎖變數的 Cache Line 在不同核心的快取之間瘋狂地「彈跳」,佔用大量的記憶體匯流排頻寬,不僅拖慢了等待者,也嚴重影響了持有鎖的 $\text{CPU}_0$ 存取同一 Cache Line 中其他資料的速度。
> [!Note] **False Sharing 問題**:另一個與 Cache 相關的效能陷阱
> Cache Coherence 的基本單位是 Cache Line (通常是 64 bytes),而不是單個變數。如果兩個不相關的變數,僅僅因為它們在記憶體中地址相近而恰好位於同一個 Cache Line 上,那麼即使 Thread A 只修改變數 `var_a`,Thread B 只修改變數 `var_b`,它們也會像競爭同一個變數一樣,觸發 Cache Line Bouncing。
為了緩解這個問題,Linux 核心採用了更優化的實作,如 **Test-and-Test-and-Set (TTS)** 鎖:
```c
// 概念性 C 程式碼
while (test_and_set(lock) != 0) { // 外層迴圈:嘗試寫入
do {
// CPU 進入低功耗狀態,等待快取事件
pause();
} while (test(lock) <= 0); // 內層迴圈:僅讀取
}
```
等待者首先在一個 **只讀** 的迴圈 (內層) 中旋轉。在這種模式下,多個核心可以共享 (Shared) 存放鎖變數的 Cache Line,不會引發大量的匯流排流量。只有當它們偵測到鎖可能被釋放時,才會去嘗試執行昂貴的原子 **寫入** 操作 (外層)。
> 延伸閱讀:
> * [第十三講:淺談同步機制 - Linux spinlock 的實作與 Cache 效應](https://hackmd.io/@Jaychao2099/Linux-kernel-13#Linux-spinlock-%E7%9A%84%E5%AF%A6%E4%BD%9C%E8%88%87-Cache-%E6%95%88%E6%87%89)
> * [從 CPU cache coherence 談 Linux spinlock 擴展議題](https://hackmd.io/@sysprog/linux-spinlock-scalability) - jserv
---
## Linux Spinlock 的演進與實作
隨著核心數量增加,Linux 的 Spinlock 實作也在不斷演進,以追求更好的 **公平性** 和 **擴展性**。
### Ticket Spinlock
為了解決簡單 Spinlock 可能存在的不公平問題 (即某個核心可能因時序巧合而一直搶不到鎖,導致飢餓),Linux 引入了 **Ticket Spinlock**。其機制類似於銀行排隊叫號:
* 鎖結構包含兩個部分:`owner` (當前服務號碼) 和 `next` (下一個可用號碼)。
* **獲取鎖**:核心原子性地取得一個 `next` 號碼並將 `next` + 1。
* **等待**:該核心在本地旋轉,等待 `owner` 號碼變為自己持有的號碼。
* **釋放鎖**:持有鎖的核心將 `owner` + 1,從而「叫」下一個號碼。
Ticket Spinlock 確保了先到先服務 (FIFO) 的公平性,但它並未解決 Cache Line Bouncing 的問題,因為所有等待者仍在同一個 `owner` 變數上旋轉。
> 延伸閱讀:[第十三講:淺談同步機制 - spinlock 核心實作](https://hackmd.io/@Jaychao2099/Linux-kernel-13#spinlock-%E6%A0%B8%E5%BF%83%E5%AF%A6%E4%BD%9C)
### Queued Spinlock (qspinlock)
為了徹底解決 Cache Line Bouncing 導致的擴展性問題,新一代的 Linux 核心 (特別是在 x86 架構上) 採用了 **Queued Spinlock** (其思想源於 MCS lock)。
* **核心思想**:讓每個等待的 CPU 在 **自己的、核心本地的 (per-CPU) 變數** 上旋轉,而不是在共享的鎖變數上。
* **運作機制**:
1. 當一個核心嘗試獲取鎖失敗時,它會將自己加入一個隱形的 **等待隊列** 中。
2. 然後,它開始在 **自己的本地變數上旋轉**。
3. 當鎖的持有者釋放鎖時,它會 **明確地通知隊列中的下一個等待者**,只修改那個等待者的本地變數,使其停止旋轉並獲得鎖。
<center><img src="https://linux-kernel-labs.github.io/refs/heads/master/_images/ditaa-58545831034f050660727be99cede213bc4a53c7.png" alt="image" width="70%" /></center>
這種方式極大地減少了記憶體匯流排的爭用,因為在等待期間幾乎沒有共享資料的寫入操作,從而顯著提升了 Spinlock 在大規模多核系統上的效能和擴展性。
> 延伸閱讀:[第十三講:淺談同步機制 - Queued/MCS Spinlock](https://hackmd.io/@Jaychao2099/Linux-kernel-13#QueuedMCS-Spinlock)
---
## Spinlock 與中斷處理
在 Linux 核心中,程式碼可能在不同的 context 中執行,最常見的是行程上下文 (process context) 和中斷上下文 (interrupt context)。中斷是異步事件,可能在任何時間點打斷當前的程式碼執行。這為鎖定帶來了新的複雜性。
### 問題
考慮一個場景:
1. 一段在 process context 中執行的程式碼獲取了 Spinlock A。
2. 此時,一個硬體中斷發生在同一個 CPU 核心上。
3. 系統跳轉到該中斷的處理程序 (Interrupt Service Routine, ISR)。
4. 不幸的是,這個 ISR 也需要獲取 Spinlock A。
此時,CPU 陷入了 **Deadlock**。ISR 嘗試獲取一個已經被它自己打斷的程式碼所持有的鎖,但除非 ISR 返回,否則該鎖永遠不會被釋放。而 ISR 不獲取鎖就無法完成並返回。
### 解決辦法
為了處理這種情況,Linux 提供了不同版本的 Spinlock API:
* **`spin_lock(lock)` / `spin_unlock(lock)`**:
* 最基本的版本,不處理中斷。
* **`spin_lock_irqsave(lock, flags)` / `spin_unlock_irqrestore(lock, flags)`**:
* 在獲取鎖之前,**暫時停用本地 CPU 的所有 maskable interrupt 的中斷請求**,並將當前的中斷狀態保存在 `flags` 中。釋放鎖時,再根據 `flags` 恢復中斷狀態。
* 最安全、最常用的版本,用於保護可能在 process 和 interrupt context 中共享的資料。
* 可以處理 **巢狀呼叫** 的狀況,確保程式的強健性:
* `_irqsave()`:先把目前的中斷狀態 (開啟 or 被關閉的) 儲存到 flags 變數中,然後才停用中斷。
* `_irqrestore()`:**「恢復」到 flags 中儲存的原始狀態**。
> [!Note] **巢狀呼叫案例**:
> 1. thread A 用 `_irqsave()` 關閉中斷 + 呼叫 thread B。
> 2. thread B 也用`_irqsave()` 關閉中斷。
> 3. thread B 解鎖時,如果用的是簡單的 `spin_unlock_irq`,它會直接把中斷打開。但這其實是個錯誤,因為外層的 thread A 還期望中斷是關閉的!
> 4. 有了 `_irqrestore()`,thread B 解鎖時只會將中斷恢復到它進入時的狀態 (關閉狀態),就不會破壞外層呼叫者的鎖定邏輯。
* **`spin_lock_irq(lock)` / `spin_unlock_irq(lock)`**:
* 類似 `irqsave()`,但它只是簡單地停用/啟用中斷,不保存先前狀態。
* 適用於已知中斷原本是啟用狀態的場景。
* **`spin_lock_bh(lock)` / `spin_unlock_bh(lock)`**:
* 一個輕量級的版本,只會停用 Bottom Half 的執行,而不會停用硬體中斷。
* 當共享資料只在 process context 和 Bottom Half 之間存取時,使用此鎖可獲得比 `spin_lock_irqsave()` 更低的延遲。
> [!Tip] 複習:Linux 將中斷處理分為兩部分:
> * **Top Half (上半部)**:即硬體中斷處理程序 (hard IRQ),要求執行速度極快。
> * **Bottom Half (下半部)**:可延遲執行的部分 (soft IRQ),由 Top Half 調度,在稍後安全的時間點執行。
> 延伸閱讀:
> * [Synchronization primitives in the Linux kernel. Part 1](https://0xax.gitbooks.io/linux-insides/SyncPrim/linux-sync-1.html)
> * [第十講:中斷處理和現代架構考量 - Linux 的中斷處理分層機制](https://hackmd.io/@Jaychao2099/Linux-kernel-10#Linux-%E7%9A%84%E4%B8%AD%E6%96%B7%E8%99%95%E7%90%86%E5%88%86%E5%B1%A4%E6%A9%9F%E5%88%B6)
---
## Kernel Preemption 的影響
**Kernel Preemption (核心搶佔)** 指的是一個在核心模式下執行的任務,可以被另一個更高優先級的任務所中斷 (搶佔) 的能力,是實現低延遲和即時 (Real-time) 系統的關鍵。
### Kernel Preemption 的演進
傳統的 Linux 核心是不可搶佔的,即一旦進入核心模式,除非主動放棄 CPU 或從系統呼叫返回,否則不會被其他 process 搶佔。然而,為了降低系統延遲,滿足即時性需求,Linux 逐步引入了不同等級的 Kernel Preemption:
* **Voluntary Preemption**:在核心程式碼中插入檢查點,允許主動讓出。
* **Preemptible Kernel**:允許在核心程式碼的大部分地方 (除了持有 Spinlock 等情況) 進行搶佔。
* **Full Preemption (`PREEMPT_RT`)**:目標是讓核心幾乎在任何地方都可以被搶佔,以達到硬即時 (hard real-time) 系統的要求。
### **preempt_count** 的角色
核心搶佔允許在高優先權任務就緒時,打斷正在核心中執行的低優先權任務。這個機制與 Spinlock 產生了深刻的互動。如果一個持有 Spinlock 的低優先權任務被搶佔,而高優先權任務又需要同一個 Spinlock,系統就會發生類似 Priority Inversion 的問題。
因此為了管理搶佔,Linux 核心引入了 **`preempt_count`** 這個 per-CPU 計數器,用來追蹤禁止搶佔的原因。
* 當核心進入一個不可搶佔的區域時 (如獲取 spinlock),`preempt_count` 就會增加。
* 離開該區域時,`preempt_count` 就會減少。
* 只有當 `preempt_count` 為 0 時,核心才允許搶佔。
有趣的是,`preempt_count` 不僅用於搶佔計數,它的不同位元 (bit) 也被用來追蹤是否處於 Hard IRQ 或 Soft IRQ context 中。
### PREEMPT_RT 與 Spinlock
對於硬即時 (hard real-time) 系統,長時間的 busy-waiting 或停用中斷是不可接受的。**`PREEMPT_RT`** 是一個旨在將 Linux 轉變為完全搶佔的即時作業系統的補丁集 (目前已逐漸整合進主線核心)。
在啟用 `PREEMPT_RT` 的核心中,Spinlock 的行為發生了根本性改變:
* `spin_lock` 不再是 busy-waiting 的鎖,而是被轉換為一個支援 **Priority Inheritance** 的 **`RT-Mutex`**。
* 當一個 thread 嘗試獲取一個已被持有的鎖時 (`RT-Mutex`),它會進入 **睡眠 (sleep)**,而不是空轉。
* 同時,它會將自己的優先級 "繼承" 給鎖的持有者,幫助持有者盡快完成任務並釋放鎖。
### Raw Spinlock vs. Spinlock
為了實現上述轉換,`PREEMPT_RT` 區分了兩種 Spinlock:
* **`raw_spinlock_t`**:「原始」的 Spinlock,它的行為始終是 busy-waiting,不受 PREEMPT_RT 配置的影響。
* 被用於核心中極底層、絕對不能睡眠的地方 (如排程器本身)。
`include/linux/spinlock_types_raw.h`
```c=14
typedef struct raw_spinlock {
arch_spinlock_t raw_lock;
... // debug
} raw_spinlock_t;
```
* **`spinlock_t`**:通用的 Spinlock。
* 在非 `PREEMPT_RT` 核心中,它就是一個 `raw_spinlock_t`。
`include/linux/spinlock_types.h`
```c=14
#ifndef CONFIG_PREEMPT_RT
/* Non PREEMPT_RT kernels map spinlock to raw_spinlock */
typedef struct spinlock {
union {
struct raw_spinlock rlock;
... // debug
};
} spinlock_t;
```
* 在 `PREEMPT_RT` 核心中,它會被轉換為 `RT-Mutex`。
```c=45
#else /* !CONFIG_PREEMPT_RT */
/* PREEMPT_RT kernels map spinlock to rt_mutex */
#include <linux/rtmutex.h>
typedef struct spinlock {
struct rt_mutex_base lock;
... // debug
} spinlock_t;
...
#endif /* CONFIG_PREEMPT_RT */
```
這種設計讓大部分核心程式碼無需修改,就能在即時和非即時環境之間切換。
> 延伸閱讀:
> * [第十三講:淺談同步機制 - ARM 架構的 spinlock 的結構體與簡化實作](https://hackmd.io/@Jaychao2099/Linux-kernel-13#ARM-%E6%9E%B6%E6%A7%8B%E7%9A%84-spinlock-%E7%9A%84%E7%B5%90%E6%A7%8B%E9%AB%94%E8%88%87%E7%B0%A1%E5%8C%96%E5%AF%A6%E4%BD%9C%EF%BC%9A)
> * [第十八講:PREEMPT_RT 作為邁向硬即時作業系統的機制](https://hackmd.io/@Jaychao2099/Linux-kernel-18)
---
## 其他並行相關議題:Deadlock vs. Livelock
### Deadlock
* **成因**:一組 process 或 thread 處於互相等待對方持有的資源的狀態,導致所有 thread 都無法繼續前進的狀態,是一個 **靜態的等待** 狀態。最常見的原因是 **鎖序不一致 (Inconsistent Lock Ordering)**:如果 Thread 1 獲取了 A,同時 Thread 2 獲取了 B,那麼它們就會相互等待對方釋放鎖,從而造成死鎖。
* Thread 1: `lock(A); lock(B);`
* Thread 2: `lock(B); lock(A);`
* **避免方法**:確保所有 thread 都以相同的順序獲取鎖。例如,可以規定總是按照鎖變數的記憶體位址從小到大的順序來獲取。
### Livelock
**Livelock** 是一個比 Deadlock 更微妙的問題。在 Livelock 狀態下,相關的 thread 並沒有被阻塞 (blocked):它們的狀態在改變,CPU 也在執行指令,但它們卻無法取得任何實質進展,是一個 **動態的徒勞** 狀態。
> 一個經典的比喻是兩個人在狹窄的走廊相遇,都想給對方讓路,於是同時向左,又同時向右,來回往復,雖然都在動,但誰也過不去。
#### Spinlock 如何導致 Livelock
* **成因**:Spinlock 在某些複雜的場景下可能導致 Livelock。
1. 一個任務在持有 Spinlock 的同時,如果被中斷,而 ISR (中斷處理常式) 也嘗試獲取同一個鎖,這通常會導致 Deadlock。
2. 但如果系統中有更複雜的 **重試或退讓機制**,多個核心可能不斷地嘗試獲取鎖、失敗、退讓、再嘗試,雖然 CPU 一直在忙碌,但沒有任何一個核心能成功獲取鎖並進入 Critical Section,這就是一種 Livelock。
* **避免方法**:關鍵仍然是正確地使用 `spin_lock_irqsave()` 等 API 來協調鎖與中斷的關係。
> 延伸閱讀:
> * [Kernels and Locking](https://retis.santannapisa.it/luca/KernelProgramming/Slides/kernel_locking.pdf)
> * [Mutual exclusion, synchronization,communicationin shared memoryOperating systems](https://www.mit.bme.hu/eng/system/files/oktatas/targyak/8699/opre_slides12_mutex_en_1.pdf)
> * [Linux Locking Mechanisms](https://www.slideshare.net/kerneltlv/linux-locking-mechanisms)
---
## 總結
Spinlock 是 Linux 核心同步機制的基石,它的設計與演進深刻地反映了現代多核處理器架構的挑戰。理解其從硬體原子操作、快取一致性到與中斷和核心搶佔的複雜互動,是掌握 Linux 核心運作的關鍵一步。
---
回[主目錄](https://hackmd.io/@Jaychao2099/Linux-kernel)
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet