# 2024q1 Homework1 (lab0)
contributed by < [P96114175](https://github.com/p96114175/lab0-c) >
## 開發環境
```shell
$ gcc --version
gcc (Ubuntu 9.4.0-1ubuntu1~20.04.2) 9.4.0
Copyright (C) 2019 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
$ lscpu
架構: x86_64
CPU 作業模式: 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 39 bits physical, 48 bits virtual
CPU(s): 24
On-line CPU(s) list: 0-23
每核心執行緒數: 1
每通訊端核心數: 16
Socket(s): 1
NUMA 節點: 1
供應商識別號: GenuineIntel
CPU 家族: 6
型號: 151
Model name: 12th Gen Intel(R) Core(TM) i9-12900F
製程: 2
CPU MHz: 2400.000
CPU max MHz: 5100.0000
CPU min MHz: 800.0000
BogoMIPS: 4838.40
虛擬: VT-x
L1d 快取: 384 KiB
L1i 快取: 256 KiB
L2 快取: 10 MiB
```
:::warning
在終端機先執行 `export LC_ALL=C` 再執行上述命令,可得到英文訊息的輸出。
:::
透過執行以下命令,可得知編譯細節
```make
make VERBOSE=1
```
在編譯完成後,可得到名為 qtest 的執行檔
```bash
$ make VERBOSE=1
gcc -o qtest.o -O1 -g -Wall -Werror -Idudect -I. -Wvla -c -MMD -MF .qtest.o.d qtest.c
gcc -o report.o -O1 -g -Wall -Werror -Idudect -I. -Wvla -c -MMD -MF .report.o.d report.c
gcc -o console.o -O1 -g -Wall -Werror -Idudect -I. -Wvla -c -MMD -MF .console.o.d console.c
gcc -o harness.o -O1 -g -Wall -Werror -Idudect -I. -Wvla -c -MMD -MF .harness.o.d harness.c
gcc -o queue.o -O1 -g -Wall -Werror -Idudect -I. -Wvla -c -MMD -MF .queue.o.d queue.c
gcc -o random.o -O1 -g -Wall -Werror -Idudect -I. -Wvla -c -MMD -MF .random.o.d random.c
gcc -o dudect/constant.o -O1 -g -Wall -Werror -Idudect -I. -Wvla -c -MMD -MF .dudect/constant.o.d dudect/constant.c
gcc -o dudect/fixture.o -O1 -g -Wall -Werror -Idudect -I. -Wvla -c -MMD -MF .dudect/fixture.o.d dudect/fixture.c
gcc -o dudect/ttest.o -O1 -g -Wall -Werror -Idudect -I. -Wvla -c -MMD -MF .dudect/ttest.o.d dudect/ttest.c
gcc -o shannon_entropy.o -O1 -g -Wall -Werror -Idudect -I. -Wvla -c -MMD -MF .shannon_entropy.o.d shannon_entropy.c
gcc -o linenoise.o -O1 -g -Wall -Werror -Idudect -I. -Wvla -c -MMD -MF .linenoise.o.d linenoise.c
gcc -o web.o -O1 -g -Wall -Werror -Idudect -I. -Wvla -c -MMD -MF .web.o.d web.c
gcc -o qtest qtest.o report.o console.o harness.o queue.o random.o dudect/constant.o dudect/fixture.o dudect/ttest.o shannon_entropy.o linenoise.o web.o -lm
```
---
### Pointer to pointer
最近看 pointer to pointer 程式時,我認為我理解的不夠<s>透徹</s> [透澈](https://dict.revised.moe.edu.tw/dictView.jsp?ID=50922),希望真的能夠好好理解其意義。於是我參考了 [你所不知道的 C 語言: linked list 和非連續記憶體
](https://hackmd.io/@sysprog/c-linked-list#%E6%A1%88%E4%BE%8B%E6%8E%A2%E8%A8%8E-LeetCode-86-Partition-List) 和 [The mind behind Linux 筆記](https://hackmd.io/@Mes/The_mind_behind_Linux)。這裡我以教材中的例子進行描述,若有誤還請多指教
我們搭配下面圖片及程式,可以明白這是一個函式在刪除 target。圖片中,考慮了兩個情況。
* 第一個情況是, target 在第一個節點(A節點),需要將 list head 指向 target 的下一個節點,也就是 B 節點。
* 第二個情況考慮了 target 在 list 中間情況,於是你可以在下方第 19 行程式觀察到將上一個節點指向 target 的下一個節點

```c=
remove_list_entry(entry)
{
prev = NULL;
walk = head;
// Walk the list
while (walk != entry) {
prev = walk;
walk = walk->next;
}
// Remove the entry by updating the
// head pr the previous entry
if (!prev)
head = entry->next;
else
prev->next = entry->next;
}
```
再來是 Linus Torvalds 的指標的指標來操作,但是我頭一個疑問是,為何需要改用指標的指標,這有什麼好處呢? 於是我發現藉由指標的指標來操作,就可以不用做 branch 了,就是不用做下方這個程式(這是上面程式擷取下來的)
```c
if (!prev)
head = entry->next;
else
prev->next = entry->next;
```
而是改用下面第 16 行程式`*indirect = entry->next;`代替,為什麼可以這樣呢? 首先我們先來理解 `indirect` 和 `*indirect` 分別代表的意義,釐清他們對於妳的程式思考有很大的幫助。
* indirect 是個指標的指標,他用來指向 list_head 指標的位址,也就是透過 `indirect = &head;` 達成
* 接下來重頭戲了,`*indirect` 的意思就是對指標的指標做 deference ,也就是取得 `list_head 指標` 所指向的節點,這一點我們從 `while ((*indirect) != entry)` 就可以觀察到,在每一次 while loop 藉由 `*indirect` 得知目前的節點,接著用來判斷是否等於 entry。
而在 `indirect = &(*indirect)->next;` 我其實也想了很久,為什麼要讓指標的指標來指向目前節點的 next 指標的位址,這其中有什麼原因嗎!? 然後我就假設 `while ((*indirect) != entry)` 不成立了,也就代表目前 `*indirect` 等於 entry,接著要將目前節點移除,但是要如何取得上一個節點呢? 其實藉由 `*indirect` 就可以辦到,因為 *indirect 是上一個節點的 next 指標,它指向著要被刪除的節點資訊,只要將其更改成指向 target 的下一個節點就可以了。這樣就明白為什麼是 indirect 指向 `&(*indirect)->next;` 了,這讓你可以同時獲得當前節點以及更改上一個節點的 next 指標的指向的權利,可喜可賀。
後來搭配練習 leetcode ,來加深使用指標的指標印象。

```c=
remove_list_entry(entry)
{
// The "indirect" pointer points to the
// *address* of the thing we'll update
indirect = &head;
// Walk the list, looking for the thing that
// points to the entry we want to remove
while ((*indirect) != entry)
indirect = &(*indirect)->next;
// .. and just remove it
*indirect = entry->next;
}
```
## q_remove_tail
```diff
element_t *q_remove_tail(struct list_head *head, char *sp, size_t bufsize)
{
if (!head && list_empty(head))
return NULL;
element_t *entry = list_last_entry(head, element_t, list);
list_del(&entry->list);
if (sp){
- memcpy(sp, entry->value, bufsize - 1);
+ strncpy(sp, entry->value, bufsize - 1);
}
return entry;
}
```
執行 `make valgrind` 後,在以下訊息可觀察到問題發生在 `memcpy` ,也就是 `queue.c:93`
```shell
==3514808== Invalid read of size 8
==3514808== at 0x4842A87: memmove (in /usr/lib/x86_64-linux-gnu/valgrind/vgpreload_memcheck-amd64-linux.so)
==3514808== by 0x10FA0F: memcpy (string_fortified.h:34)
==3514808== by 0x10FA0F: q_remove_tail (queue.c:93)
==3514808== by 0x10C565: queue_remove (qtest.c:352)
==3514808== by 0x10C864: do_rt (qtest.c:415)
==3514808== by 0x10E035: interpret_cmda (console.c:181)
==3514808== by 0x10E605: interpret_cmd (console.c:201)
==3514808== by 0x10EA42: cmd_select (console.c:610)
==3514808== by 0x10F34D: run_console (console.c:705)
==3514808== by 0x10D3C2: main (qtest.c:1258)
==3514808== Address 0x4bac418 is 24 bytes after a block of size 48 in arena "client"
==3514808==
```
於是我參考 [C 規格書 ISO/IEC 9899:TC3](https://www.open-std.org/jtc1/sc22/wg14/www/docs/n1256.pdf),裡頭提到
```c
#include <string.h>
void *memcpy(void * restrict s1,
const void * restrict s2,
size_t n);
```
> The memcpy function copies n characters from the object pointed to by s2 into the object pointed to by s1.
```c
#include <string.h>
char *strncpy(char * restrict s1,
const char * restrict s2,
size_t n);
```
>1. The strncpy function copies not more than n characters (characters that followanull character are not copied) from the array pointed to by s2 to the array pointed to by s1.
>2. If the array pointed to by s2 is a string that is shorter than n characters, ==null characters== are appended to the copy in the array pointed to by s1, until n characters in all have been written.
於是我們得知 strncpy 和 memcpy 之間的差異就是,strncpy 會用 null characters 做結尾,使得字串結束時有正確定義。
### q_aescend / q_descend
參考 [2487. Remove Nodes From Linked List](https://leetcode.com/problems/remove-nodes-from-linked-list/description/) ,它提到
> Remove every node which has a node with a greater value anywhere to the right side of it.
> Return the head of the modified linked list.
下方我便採用 recursive 去實作
```c
ListNode* removeNodes(ListNode* head) {
if(!head) return NULL;
head->next = removeNodes(head->next);
return head->next && head->val < head->next->val ? head->next : head;
}
```
:::danger
避免過多的中英文混用,已有明確翻譯詞彙者,例如「鏈結串列」(linked list) 和「佇列」(queue),就使用該中文詞彙,英文則留給變數名稱、人名,或者缺乏通用翻譯詞彙的場景。
> 我會多注意的
:::
但我觀察到我們的佇列都是迴圈鏈結串列,不同於 [2487. Remove Nodes From Linked List](https://leetcode.com/problems/remove-nodes-from-linked-list/description/) 採取單一方向走訪,我們只需要將我們佇列走訪方向從 `next` 改為 `prev` 實作即可。
```c
/* Remove every node which has a node with a strictly less value anywhere to
* the right side of it */
int q_ascend(struct list_head *head)
{
// https://leetcode.com/problems/remove-nodes-from-linked-list/
if (!head || list_empty(head))
return 0;
element_t *r = list_entry(head->prev, element_t, list);
element_t *l = list_entry(head->prev->prev, element_t, list);
while (&l->list != head) {
if (strcmp(l->value, r->value) > 0) {
list_del(&l->list);
} else {
l = list_entry(l->list.prev, element_t, list);
r = list_entry(r->list.prev, element_t, list);
}
}
return q_size(head);
}
/* Remove every node which has a node with a strictly greater value anywhere to
* the right side of it */
int q_descend(struct list_head *head)
{
// https://leetcode.com/problems/remove-nodes-from-linked-list/
if (!head || list_empty(head))
return 0;
element_t *r = list_entry(head->prev, element_t, list);
element_t *l = list_entry(head->prev->prev, element_t, list);
while (&l->list != head) {
if (strcmp(l->value, r->value) < 0) {
list_del(&l->list);
} else {
l = list_entry(l->list.prev, element_t, list);
r = list_entry(r->list.prev, element_t, list);
}
}
return q_size(head);
}
```
### q_sort
參考 [Linked List Sort](https://npes87184.github.io/2015-09-12-linkedListSort/),接下來實作 merge sort
在 `q_sort` 中,當結束完 `q_divide` 後,還需要將 list_head 的 `prev` 鏈接起來。在 [lab0-c/list.h](https://github.com/sysprog21/lab0-c/blob/master/list.h) 有定義出 list_head 該結構體的詳細資訊,如下
```c
* struct list_head - Head and node of a doubly-linked list
* @prev: pointer to the previous node in the list
* @next: pointer to the next node in the list
struct list_head {
struct list_head *prev;
struct list_head *next;
};
```
```c
/* Sort elements of queue in ascending order */
void q_sort(struct list_head *head, bool descend)
{
if (!head || list_empty(head))
return;
head->prev->next = NULL;
head->next = q_divide(head->next, descend);
struct list_head *cur=head, *safe = head->next;
while(safe){
safe->prev = cur;
cur = safe;
safe = safe->next;
}
cur->next = head;
head->prev = cur;
}
// Devide elements of queue into two parts.
struct list_head *q_divide(struct list_head *head, bool descend) {
if(!head->next) return head;
struct list_head* fast = head->next;
struct list_head* slow = head;
struct list_head *l1, *l2;
// split list
while(fast && fast->next) {
slow = slow->next;
fast = fast->next->next;
}
fast = slow->next;
slow->next = NULL;
// sort each list
l1 = q_divide(head, descend);
l2 = q_divide(fast, descend);
return merge(l1, l2);
}
// Merge the elements
struct list_head *merge(struct list_head *l1, struct list_head *l2){
// merge sorted l1 and sorted l2
struct list_head temp;
struct list_head* cur = &temp;
if (!l1 && !l2)
return NULL;
while(l1 && l2) {
if(strcmp(list_entry(l1, element_t, list)->value, list_entry(l2, element_t, list)->value)<0)
{
cur->next = l1;
l1 = l1->next;
}else
{
cur->next = l2;
l2 = l2->next;
}
cur = cur->next;
}
if(l1) cur->next = l1;
if(l2) cur->next = l2;
return temp.next;
}
```
:::danger
使用作業規範的程式碼縮排風格。
> 已執行 `clang-format -i *.[ch]` 確保一致的程式風格
:::
---
## 研讀 Linux 核心原始程式碼的 [lib/list_sort.c](https://github.com/torvalds/linux/blob/master/lib/list_sort.c) 並嘗試引入
參考[改進 lib/list_sort.c](https://hackmd.io/@sysprog/Hy5hmaKBh) 和 [vax-r](https://hackmd.io/@vax-r/linux2024-homework1) 和 [M01: lab0](https://hackmd.io/@sysprog/linux2024-lab0/%2F%40sysprog%2Flinux2024-lab0-e)
在[ 129 行](https://github.com/torvalds/linux/blob/master/lib/list_sort.c)中指出, mergesort 會盡可能總是執行 2:1 平衡合併。打個比方,給定兩個大小為 $2^k$ pending sublists,一旦接下來來了 $2^k$ 個元素,剛剛那兩個 pending sublists 便會合併成 $2^{k+1}$ 的 list。
在[ 133 行](https://github.com/torvalds/linux/blob/master/lib/list_sort.c)中提到只要這 $3 * 2^k$ 元素能放進 cache,就能夠去避免 [trashing](https://en.wikipedia.org/wiki/Thrashing_(computer_science)),為什麼要去避免呢! 因為 trashing 會對大多數應用程式級處理降速。接著 [ 133 行](https://github.com/torvalds/linux/blob/master/lib/list_sort.c) 也提到雖然不像 fully-eager bottom-up mergesort 那樣好,但也做到了減少 $0.2 \times n$ 次比較,在一切都適合 L1 的常見情況下速度更快
在 [第 139 行](https://github.com/torvalds/linux/blob/master/lib/list_sort.c)中,pending lists 中元素的數量由 count 所控制著。
每一次我們增加 count 時,我們便設定 1 個 bit(假設是 bit k) 並且清除 bit k-1 ... 0 為 0。
在較小的 list 中,當 count 達到 $2^k$ 的奇數倍時,便會合併掉 2 個大小為 $2^k$ 的 list。這樣的操作做兩次以後,我們便產生了 2 個大小為 $2^{k+1}$ 的 list。接著在產生第三個大小為 $2^{k+1}$ 的 list 前,將 2 個大小為 $2^{k+1}$ 的 list 合併至大小為 $2^{k+2}$ 的 list ,這樣一來就絕對不會超過 2 個 pending。
pending lists 的數量由 count 的第 k 個 bit 和另外兩個資訊所決定。
1. The state of bit k-1 (when k == 0, consider bit -1 always set)
2. Whether the higher-order bits are zero or non-zero (i.e. is count >= 2^(k+1)).
對於第 k 個 bit,這裡我們有 6 個狀態要去區分, x 表示為一些隨機的 bits,y 表示為一些隨機的 non-zero bits。我們可以根據我們所在的狀態,得知目前大小為 $2^k$ 的 pending 數量。
* 0: 00x: 0 pending of size $2^k$; x pending of sizes < $2^k$
表示目前有 x 個 pending 在大小小於 $2^k$ 的 Sublists 中。
* 1: 01x: 0 pending of size $2^k$; $2^{(k-1)}$ + x pending of sizes < $2^k$
表示目前有 $2^{(k-1)}$ + x 個 pending 在大小小於 $2^k$ 的 Sublists 中。
* 2: x10x: 0 pending of size $2^k$; $2^k$ + x pending of sizes < $2^k$
表示目前有 $2^k$ + x 個 pending 在大小小於 $2^k$ 的 Sublists 中。但是沒有將這 $2^k$ 個合併起來
* 3: x11x: 1 pending of size $2^k$; $2^{(k-1)}$ + x pending of sizes < $2^k$
經 2 到 3 的轉換後,大小為 $2^k$ 的 pending 進行合併。這是因為 sublist 中有了大小為 $2^{(k-1)}$ 的 pending,以確保前面 torvalds 所說的執行 2:1 平衡合併。
* 4: y00x: 1 pending of size $2^k$; $2^k$ + x pending of sizes < $2^k$
和狀態二一樣,雖然有 $2^k$ 個 pending,但是沒有將這 $2^k$ 個合併起來
* 5: y01x: 2 pending of size $2^k$; $2^{(k-1)}$ + x pending of sizes < $2^k$
經 4 到 5 的轉換後,將大小為 $2^k$ 的 pending 進行合併,因為 sublist 中有了大小為 $2^{(k-1)}$ 的 pending,遵守著 2:1 平衡合併。在狀態 5中可以觀察到,需要將 2 個大小為 $2^k$ 的 pending 進行合併為 $2^{k+1}$,才能回到狀態 2。
在 2 到 3 和 4 到 5 的轉換中,我們得到了大小為 $2^k$ 的 list(因為在這些轉換中,"bit k-1" 被設置,而更 significant bits 不為 0),並在 5 到 2 的轉換中將它們合併掉。特別注意,在 5 到 2 的轉換之前,所有 lower-order bits 都是 11(狀態 3),因此有一個每個較小大小的 list。
當我們到達輸入的結尾時,我們將所有未完成的 list 從最小到最大進行合併。如果您仔細分析上述的 2 到 5 的情況,您會發現我們與大小為 $2^k$ 的 list 進行合併的元素數量因情況而異,從 $2^{(k-1)}$(在 x == 0 時的情況 3 和 5)變化到 $2^{k+1} - 1$(在 x == $2^{k-1}- 1$ 時的情況 5 的第二次合併)
以下為 list_sort 的 Data structure invariants 相關資訊:
- All lists are singly linked and null-terminated; prev pointers are not maintained.
- pending is a prev-linked "list of lists" of sorted sublists awaiting further merging.
- Each of the sorted sublists is power-of-two in size.
- Sublists are sorted by size and age, smallest & newest at front.
- There are zero to two sublists of each size.
- A pair of pending sublists are merged as soon as the number of following pending elements equals their size (i.e. each time count reaches an odd multiple of that size). That ensures each later final merge will be at worst 2:1.
- Each round consists of:
- Merging the two sublists selected by the highest bit
which flips when count is incremented, and
- Adding an element from the input as a size-1 sublist.
參考 [list_sort](https://hackmd.io/@sysprog/linux2024-lab0-e#list_sort) 紀錄我的所見所聞
`__attribute__((nonnull(2,3)))` 意思是指該函式的第 2 個及第 3 個參數不為 null。
```c
__attribute__((nonnull(2,3)))
void list_sort(void *priv, struct list_head *head, list_cmp_func_t cmp)
{
struct list_head *list = head->next, *pending = NULL;
size_t count = 0; /* Count of pending */
if (list == head->prev) /* Zero or one elements */
return;
/* Convert to a null-terminated singly-linked list. */
head->prev->next = NULL;
```
* priv: 作為 merge function 和 list_sort function 的輸入。
```c
static struct list_head *merge(void *priv, list_cmp_func_t cmp,
struct list_head *a, struct list_head *b)
```
* head: 傳入一個指標指向需要排序的 list 的第一個節點。
* cmp: 它是 comparison function,輸入型別為 function pointer,有考慮通用性,導致 function call 成本增加。
透過 `list == head->prev` 來判斷目前是不是 0 或是 1 個元素,當 2 個元素以上,這個判斷式便不會成立。並將 head 的前一個節點的 next 指標指向 NULL,把雙向 linked list 變成單向。
:::info
我在看老師對 [list_sort](https://hackmd.io/@sysprog/linux2024-lab0-e#list_sort) 敘述時,發現老師這樣寫 `list 指向 head 的第一個節點,` 感到有點疑惑。我認為應該是 head 指標指向 list 的第一個節點XD,我有認知錯誤的話,還請多指教。
:::
參考[排序測試和效能評估機制](https://hackmd.io/@sysprog/Hy5hmaKBh#%E6%8E%92%E5%BA%8F%E6%B8%AC%E8%A9%A6%E5%92%8C%E6%95%88%E8%83%BD%E8%A9%95%E4%BC%B0%E6%A9%9F%E5%88%B6),提到評估和比較各個排序演算法,會關注以下三種指標
* Execution time
* The number of comparisons
* Cache miss ratio
在實驗 list_sort 部分,我參考了 [比較並改進 list_sort](https://hackmd.io/@vax-r/linux2024-homework1#%E5%BC%95%E5%85%A5-list_sort-%E5%88%B0-lab0-c-%E7%95%B6%E4%B8%AD) 的想法,發現老師給了以下評論
:::info
未能充分考慮資料的分佈。
:::
之後上課時詢問 jserv 老師,建議我應該去看 c 規格書,看 sort 那部分是針對哪些情況去做測試
### 將 Linux 核心原始程式碼的 lib/list_sort.c 並引入 lab0
我建立 `test_list_sort.h` 檔案存放 torvalds linux 的 list_sort 所需要的函式
```h
/**
* Define the function needed by list_sort.
**/
typedef int (*list_cmp_func_t)(const struct list_head *,
const struct list_head *);
#define unlikely
#define IS_ERR_VALUE(x) \
unlikely((unsigned long) (void *) (x) >= (unsigned long) -MAX_ERRNO)
#define likely(x) __builtin_expect(!!(x), 1)
```
並將 [lib/list_sort.c](https://github.com/torvalds/linux/blob/master/lib/list_sort.c) 放在 `queue.c` 中的 q_sort,然後成功執行 make。
程式碼詳見於 [commit a119fd8](https://github.com/sysprog21/lab0-c/commit/a119fd80504582c8d68c32f789b3cb151a9163e2)。
```diff
void q_sort(struct list_head *head, bool descend)
{
- if (!head || list_empty(head))
return;
- head->prev->next = NULL;
- head->next = q_divide(head->next, descend);
- struct list_head *cur = head, *safe = head->next;
- while (safe) {
- safe->prev = cur;
- cur = safe;
- safe = safe->next;
- }
- cur->next = head;
- head->prev = cur;
+ list_sort(head, list_cmp);
+ if (descend)
+ q_reverse(head);
}
```
在引入過程中,我做了幾項更動,如下
* 我觀察到 `priv` 在 [lib/list_sort.c](https://github.com/torvalds/linux/blob/master/lib/list_sort.c) 僅做為參數傳遞,並無任何作用,因此我將其刪除
```diff
- void list_sort(void *priv, struct list_head *head, list_cmp_func_t cmp)
+ void list_sort(struct list_head *head, list_cmp_func_t cmp)
...
- static void merge_final(void *priv, list_cmp_func_t cmp, struct list_head *head,
- struct list_head *a, struct list_head *b)
+ static void merge_final(list_cmp_func_t cmp, struct list_head *head,
+ struct list_head *a, struct list_head *b)
...
```
* 在 list_sort 中對 [u8](https://github.com/torvalds/linux/blob/3aaa8ce7a3350d95b241046ae2401103a4384ba2/crypto/jitterentropy.c#L60) 的定義如下,所以在宣告 count 變數時,其型別宣告為 `unsigned char`,詳見於[commit 2603833](https://github.com/sysprog21/lab0-c/commit/2603833d8c4c0cd5049c177f8b0eacf9f3463b2e)。
```c
typedef unsigned char u8;
```
* 我參考在 [linux/lib/test_list_sort.c](https://github.com/torvalds/linux/blob/3aaa8ce7a3350d95b241046ae2401103a4384ba2/lib/test_list_sort.c#L47) 對 cmp 的實作邏輯,將 cmp 改寫成以下程式,透過 strcmp 對兩個字串進行比較。
```c
// 在 linux/lib/test_list_sort.c 的 cmp
/* `priv` is the test pointer so check() can fail the test if the list is invalid. */
static int cmp(void *priv, const struct list_head *a, const struct list_head *b)
{
struct debug_el *ela, *elb;
ela = container_of(a, struct debug_el, list);
elb = container_of(b, struct debug_el, list);
check(priv, ela, elb);
return ela->value - elb->value;
}
```
```c
// 我的 cmp
static int list_cmp(const struct list_head *a, const struct list_head *b)
{
element_t *a_ele = list_entry(a, element_t, list);
element_t *b_ele = list_entry(b, element_t, list);
return strcmp(a_ele->value, b_ele->value);
}
```
在 [C 規格書 ISO/IEC 9899:TC3](https://www.open-std.org/jtc1/sc22/wg14/www/docs/n1256.pdf) 便有提到對 strcmp 的描述,如下
> Synopsis
#include <string.h>
int strcmp(const char *s1, const char *s2);
> Description
The strcmp function compares the string pointed to by s1 to the string pointed to by s2.
> Returns
The strcmp function returns an integer greater than, equal to, or less than zero, accordingly as the string pointed to by s1 is greater than, equal to, or less than the string pointed to by s2.
### 基於 [M03: review](https://hackmd.io/@sysprog/linux2024-review) 來確認分析 Linux 核心的 lib/list_sort.c 實作並評估其效益
基於 [lab0-a](https://hackmd.io/@sysprog/linux2024-lab0/%2F%40sysprog%2Flinux2024-lab0-a) 中的 qtest `ih RAND` 指令,我們測試 `traces\trace-15-perf.cmd` 在不同元素數量下的 clock cycles,分別有 `10000`,`50000`,`100000`,每一種皆測試 5 次,並將 `scripts/driver.py` 只保留 15 用於協助測試,以下為 ih RAND 指令的 解釋。
```
ih str [n] | Insert string str at head of queue n times. Generate random string(s) if str equals RAND. (default: n == 1)
```
以下為 `scripts/driver.py` 的修改處。
```c
...
# 12: "trace-12-malloc",
# 13: "trace-13-malloc",
# 14: "trace-14-perf",
15: "trace-15-perf",
# 16: "trace-16-perf",
# 17: "trace-17-complexity"
}
...
```
以下為 `list_sort` 和 `merge_sort` 在各項指標上的表現,其中採用 perf 進行,在 clock cycle 上,可以觀察到 `merge_sort` 優於 `list_sort`。在 cache misses 上,`list_sort` 在 `50000`, `100000` 的元素數量上,優於 `merge_sort`。
**list_sort**
| num of elements | clock cycles | cache misses | cache references|
| -------- | -------- | -------- | -------- |
| 10000 | 121,776,127 | 328,576 |1,860,456|
| 50000 | 244,537,216 | 458,940 |5,178,060|
| 100000 | 421,052,906 | 779,689 |9,795,823|
**Merge_sort**
| num of elements | clock cycles | cache misses |cache references|
| -------- | -------- | -------- | -------- |
| 10000 | 118,761,083 | 235,442 |1,847,270|
| 50000 | 241,944,230 | 466,484 |466,484|
| 100000 | 418,216,820 | 889,077 |9,979,715|
## 在 qtest 提供新的命令 shuffle
> [commit 7759053](https://github.com/sysprog21/lab0-c/commit/7759053a323ef273471fb9089f7448d2e45bf054)。
為了執行 shuffle 操作,我們需要在 qtest.c 的 console_init() 中新增命令
```c
ADD_COMMAND(shuffle, "Fisher-Yates shuffle Algorithm", "");
```
接著會發生以下錯誤訊息,告訴你需要定義出一個 do_shuffle 的函式。
```shell
In file included from qtest.c:47:
qtest.c: In function ‘console_init’:
console.h:48:52: error: ‘do_shuffle’ undeclared (first use in this function); did you mean ‘q_shuffle’?
48 | #define ADD_COMMAND(cmd, msg, param) add_cmd(#cmd, do_##cmd, msg, param)
| ^~~
```
觀察以下程式碼,它將 cmd 命令藉由巨集展開成 `do_##cmd`,`do_##cmd` 表示為 handler,舉例來說,new 命令會去呼叫 do_new 函式,而我們定義出 shuffle 命令,便會去呼叫 `do_shuffle` 函式。
```c
#define ADD_COMMAND(cmd, msg, param) add_cmd(#cmd, do_##cmd, msg, param)
```
如下我們定義出 do_shuffle 該函式,它前面 if 判斷式,主要是在確保 queue 的數量達至我們要求。接著後面再對 queue 做 shuffle 操作。
```c
static bool do_shuffle(int argc, char *argv[])
{
if (!current || !current->q) {
report(3, "Warning: Calling shuffle on null queue");
return false;
}
if (q_size(current->q) < 2)
report(3, "Warning: Calling shuffle on null queue");
error_check();
set_noallocate_mode(true);
if (current && exception_setup(true))
q_shuffle(current->q);
exception_cancel();
set_noallocate_mode(false);
return q_show(0);
}
```
我參考 [Fisher–Yates shuffle](https://en.wikipedia.org/wiki/Fisher%E2%80%93Yates_shuffle#The_modern_algorithm) 和 [lab0 亂數+論文閱讀](https://hackmd.io/@sysprog/linux2024-lab0-d#%E5%9C%A8-qtest-%E6%8F%90%E4%BE%9B%E6%96%B0%E7%9A%84%E5%91%BD%E4%BB%A4-shuffle) 來實作 q_shuffle()。
1. 首先取得 queue 的大小 `size`。
2. 再從 queue 的 0 ~ size-1 隨機抽出一個節點,將 old 指標指向該節點,而 new 指標指向最後一個未被抽到的節點,將兩個節點做 swap 操作,再將 size 減一。
3. 當 size 歸零便意味著 shuffle 結束。
接下來使用 [Pearson's chi-squared test](https://en.wikipedia.org/wiki/Pearson%27s_chi-squared_test) 來驗證 shuffle,其中參考 [lab0-D](https://hackmd.io/@sysprog/linux2024-lab0-d#%E5%9C%A8-qtest-%E6%8F%90%E4%BE%9B%E6%96%B0%E7%9A%84%E5%91%BD%E4%BB%A4-shuffle) 對於該測試方法的解釋。參考 [測試程式](https://hackmd.io/@sysprog/linux2024-lab0-d#%E6%B8%AC%E8%A9%A6%E7%A8%8B%E5%BC%8F) 去實作 Pearson's chi-squared test,詳情參見 [commit 8fbfdc8](https://github.com/sysprog21/lab0-c/commit/8fbfdc8e739b4d25dc6aa1767d968c3dd3d61224)
最後我們可以得到 Expectation 和 Observation 和 chi square sum。
* Observation
```shell
$ python shuffle.py
Expectation: 4166
Observation: {'1234': 4159, '1243': 4230, '1324': 4197, '1342': 4154, '1423': 4188, '1432': 4177, '2134': 4120, '2143': 4148, '2314': 4042, '2341': 4117, '2413': 4216, '2431': 4173, '3124': 4143, '3142': 4194, '3214': 4061, '3241': 4159, '3412': 4139, '3421': 4183, '4123': 4177, '4132': 4242, '4213': 4216, '4231': 4136, '4312': 4185, '4321': 4244}
chi square sum: 13.866538646183391
```
下方圖表結果記錄了 1234 所有可能的排序的出現次數,因為有 4 個元素要 shuffle,所以共有 4! 種可能的排序,從圖表來看 shuffle 的頻率是大致符合 Uniform distribution 的。

我們可以嘗試將 [Fisher–Yates shuffle](https://en.wikipedia.org/wiki/Fisher%E2%80%93Yates_shuffle#The_modern_algorithm) 加入 q_sort 中,來實驗在該情況下,linux kernel 的 list_sort 和 merge_sort 在 clock cycles 和 cache miss 上的表現,我們將取執行五次後平均的結果。
```diff
/* list sort */
void q_sort(struct list_head *head, bool descend)
{
+ shuffle(head);
list_sort(head, list_cmp);
if (descend)
q_reverse(head);
}
```
```diff
/* merge sort */
void q_sort(struct list_head *head, bool descend)
{
if (!head || list_empty(head))
return;
+ shuffle(head);
head->prev->next = NULL;
head->next = q_divide(head->next, descend);
struct list_head *cur = head, *safe = head->next;
while (safe) {
safe->prev = cur;
cur = safe;
safe = safe->next;
}
cur->next = head;
head->prev = cur;
}
```
**採用 q_shuffle 的 list_sort**
| num of elements | clock cycles | cache misses | cache references|
| -------- | -------- | -------- | -------- |
| 10000 | 118,919,357 | 283,525 |1,908,910|
| 50000 | 244,175,455 | 576,363 |5,068,997|
| 100000 | 420,213,155 | 815,923 |9,662,633|
**未採用 q_shuffle 的 list_sort**
| num of elements | clock cycles | cache misses | cache references|
| -------- | -------- | -------- | -------- |
| 10000 | 121,776,127 | 328,576 |1,860,456|
| 50000 | 244,537,216 | 458,940 |5,178,060|
| 100000 | 421,052,906 | 779,689 |9,795,823|
從 list_sort 的 `10000` 可以觀察到,list_sort 在 shuffle 過的測資上,clock cycles 表現更好。但是在 list_sort 的 `50000`, `100000` 可以觀察到在 shuffle 過的測資上,cache misses 是上升的。
**採用 q_shuffle 的 merge_sort**
| num of elements | clock cycles | cache misses | cache references|
| -------- | -------- | -------- | -------- |
| 10000 | 117,870,073 | 253,193 |1,874,273|
| 50000 | 243,566,574 | 611,209 |5,052,431|
| 100000 | 414,814,195 | 725,122 |9,671,023|
**未採用 q_shuffle 的 merge_sort**
| num of elements | clock cycles | cache misses |cache references|
| -------- | -------- | -------- | -------- |
| 10000 | 118,761,083 | 235,442 |1,847,270|
| 50000 | 241,944,230 | 466,484 |466,484|
| 100000 | 418,216,820 | 889,077 |9,979,715|
從 merge_sort 的 `10000`, `100000` 可以觀察到,merge_sort 在 shuffle 過的測資上,clock cycles 表現更好。但是在 merge_sort 的 `10000`, `50000` 可以觀察到在 shuffle 過的測資上,cache misses 是顯明提高。
## [tic-tac-toe](https://github.com/jserv/ttt)
我們將 Linux 核心的 linux/list.h 標頭檔與 hlist 相關的程式碼抽出,建立 hlist.h,並透過 make 確保可以正常編譯
> [commit bcc6459](https://github.com/sysprog21/lab0-c/commit/bcc64592a10f903066ff9f80a7c1d19578f0de27)
接著將 [jserv/ttt](https://github.com/jserv/ttt) 中的 `game.h`, `game.c` 引進 lab0 中,同時在 qtest.c 中新增對應的<s>指令</s> ??
> [commit 91a9b86](https://github.com/sysprog21/lab0-c/commit/91a9b866a40820efeb9a86e15238aea022688654)。
```c
ADD_COMMAND(ttt, "Start my tic-tac-toe", "");
```
`do_ttt` 函式則是參考 [113行](https://github.com/jserv/ttt/blob/d327beb2787565849497aec9084c106f9b0156a0/main.c#L103), [122行](https://github.com/jserv/ttt/blob/d327beb2787565849497aec9084c106f9b0156a0/main.c#L122) 進行實作
考慮到 tic-tac-toe 的更新棋盤位置需求,於是我們引進了 **[Zobrist hashing](https://en.wikipedia.org/wiki/Zobrist_hashing)** ,原因如下
* Zobrist hashing 不會更新全部的棋盤,只對已更改位置的 bitstring 進行 XOR operation ,以此來更新棋盤特定位置,以防止浪費計算資源,參見 [commit a3022c8](https://github.com/sysprog21/lab0-c/commit/a3022c8c2418445fb71c9bba93afcf4097abc119)
在 tic-tac-toe 裡,我們引進 64 位元版本的 Mersenne Twister pseudo-random number generator,pseudo-random number generator(PRNG) 對於 Monte-Carlo tree search(MCTS) 相當重要,原因如下。
* 潛在的移動會在 MCTS 的 search tree 被建構出來,並且許多的 random simulation 方法會被使用來評估每一個移動的長期潛力。
* random simulation 其中一個方法便是 PRNG,PRNG 可以產生一個數字序列,該序列的屬性近似於隨機數字序列,而 PRNG-generated 序列並非真正意義上的 [random](https://en.wikipedia.org/wiki/Randomness),其實完全是由名為 PRNG's seed 所決定的。在真實世界應用上,PRNG 更重視於數字序列產生的速度以及重現性 (reproducibility),前述內容參考自 [Pseudorandom number generator](https://en.wikipedia.org/wiki/Pseudorandom_number_generator)。
* 在 [Improving performance and efficiency of PRNG](https://github.com/jserv/ttt/issues/32) 中指出我們在整合 Mersenne Twister pseudorandom number generator 至 tic-tac-toe 時,也應當和其他演算法(SplitMix64、Xoroshiro128+、PCG64 和 ChaCha20) 執行效能和效率上的評估,而我對 PRNG 的實現可在[commit 4f68024](https://github.com/sysprog21/lab0-c/commit/4f680245772a4308fbd9cee2d35ba14816cce280) 觀察到。
為了在 do_ttt 函式中使用 negamax AI,我從 tic-tac-toe 中引進相關指令,並在 Makefile 中新增對 ttt_agents/negamax.o 的編譯規則,參見 [commit 9a707c1](https://github.com/sysprog21/lab0-c/commit/9a707c1d9d4ad46576dfdb2a035d37c8400bbcdb),完成前述程式便可以執行 tic-tac-toe 。只要輸入以下指令,就可以看到下方 tic-tac-toe 示意圖
```terminal
$ make
$ ./qtest
cmd> ttt
```

要實作使用者和電腦一起玩井字遊戲,可使用以下的演算法
* [negamax](https://en.wikipedia.org/wiki/Negamax)
* [reinforcement learning (RL)](https://en.wikipedia.org/wiki/Reinforcement_learning)
* [Monte Carlo tree search (MCTS)](https://en.wikipedia.org/wiki/Monte_Carlo_tree_search)
:::info
我好奇這麼多演算法,誰是最適合的。
:::
#### 蒙特卡羅樹搜尋(MCTS)
[Monte Carlo tree search(MCTS)](https://zh.wikipedia.org/zh-tw/%E8%92%99%E7%89%B9%E5%8D%A1%E6%B4%9B%E6%A0%91%E6%90%9C%E7%B4%A2)是一種用於玩遊戲的人工智慧的啟發式搜尋演算法,最著名的應用是 AlphaGo。相較於需要完整遊戲樹的極小化搜索,MCTS 能夠在一定時間內停止,並在部分構建的 search tree 中選擇足夠優秀的解決方案。MCTS 每一次移動都需要經過這[四個步驟](https://en.wikipedia.org/wiki/Monte_Carlo_tree_search)。
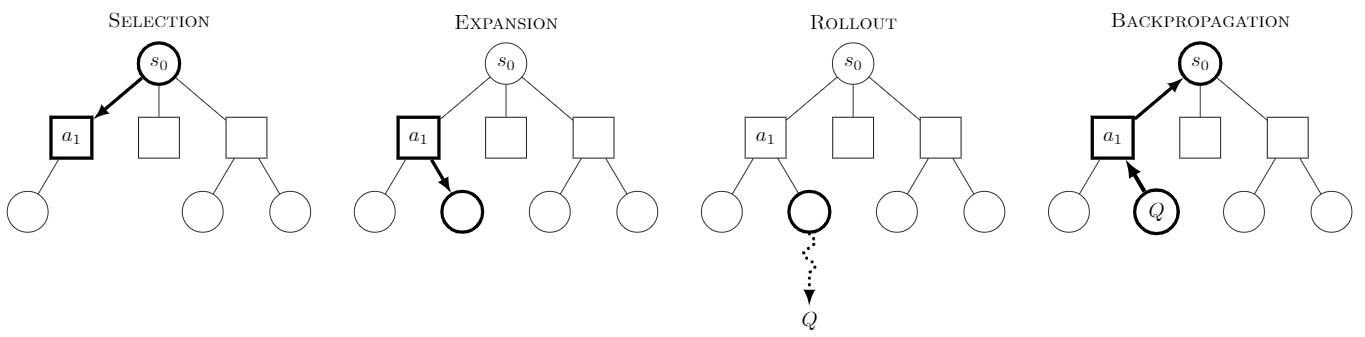
* Selection: 從 root R 開始,直到 leaf node 抵達前選擇連續的子節點。Root 表示為目前的遊戲狀態。
* Expansion: 除非 leaf node 結束該遊戲,否則便會建立一至多個子節點並且從這些子節點中,選擇子節點 C。
* Simulation: 該步驟又稱為 playout 或是 rollout。完成節點 C 的 random playout
* Backpropagation: 使用節點 C 的 playout 結果,去更新節點 C 至 R 這段路徑上的節點。
MCTS 透過保留每個節點的統計數據,並應用 Upper Confidence Bound (UCB) 演算法來選擇下一步操作。UCB 決定每個節點勝率的置信區間,並傳回信賴區間中的最高值。透過不斷測試節點,我們對其勝率越來越有信心,並縮小其置信區間。
UCB(Upper Confidence Bound)演算法是一種用於平衡探索和利用的方法,確保沒有潛在節點會被完全忽略,同時保證有希望的分支會被更頻繁地探索。
\begin{gather*}
\cfrac{w_i}{n_i} + c\mathop{}\sqrt{\cfrac{\ln(t)}{n_i}}
\end{gather*}
* $w_i$ 表示第 i 次移動之後,該節點贏的次數
* $n_i$ 表示第 i 次移動之後,該節點總模擬的次數
* $t$ 表示總模擬的次數
* $c$ 表示 exploration parameter,通常設為 $\sqrt{2}$
公式的前後項分別對應到 exploitation 和 exploration。當該節點贏得越多時,前項的數字越高,若是該節點的模擬少,則後項的數字更高。
關於 Monte Carlo tree search 在 lab0 的實作,參見 [commit commit 3e9476b](https://)
#### Linux 核心的浮點數運算
在 Linux kernel mode 中仍可使用浮點運算,但這會降低執行速度,還需要手動儲存/取回相關的 FPU 暫存器,因此 kernel files 不建議你在 kernel 中使用浮點數運算。
在 [afcidk](https://github.com/afcidk) 的[實驗](https://gist.github.com/afcidk/7178ef368d98ee4b49c7a1acc3704303)中指出 kernel mode 的浮點數運算,時間成本比整數高。

:::info
下方我先記錄一下定點數的知識,因為我不懂
:::
目前 [jserv/ttt](https://github.com/jserv/ttt) 大量運用到浮點數運算,我們可採用[定點數計算 (Fixed-point arithmetic)](https://en.wikipedia.org/wiki/Fixed-point_arithmetic) 來解決效能問題,定點數就是小數表示的一種方法,藉由儲存小數部分的固定位數達成。常見的有十進位(基數 10)和二進位(基數 2)。小數的定點數表示本質上就是一個整數,它將乘以一個固定的 scaling factor。舉個例子來說
1. 值 1.23 可以以整數值 1230 的形式存儲在變數中,隱式縮放因子為 $\frac{1}{1000}$
2. 值 1 230 000 可以以整數值 1230 的形式存儲在變數中,隱式縮放因子為 $1000$
這樣的表示方式,可以讓標準整數運算單元去執行有理數計算。而負值通常以二進位格式來去表示,帶有隱式 scaling factor 的有號整數,其表示方式為二進位補數。例如 8 位元有號二進位整數 $(11110101)_2 = -11$ 採用 -3, +5, +12 隱式的 fraction bits,那依序可以表示成
* $\frac{-11}{2^{-3}} = -88$,$\frac{-11}{2^{5}} = −0.34375$,$\frac{-11}{2^{12}} = −0.002685546875$
程式通常會假設,儲存至變數的所有定點數值,將具有相同的 scaling factor。這項參數通常由開發者所選定,他會依據所需要的精度以及要存儲值的範圍。為了更高效率,scaling factor 通常被選擇為用於表示整數的基數 b 的冪。像是十進位表示的整數,它的基數 b 為 10,那麼 scaling factor 便為 10 的冪。
由於定點數運算沒有像 IEEE 754 浮點數標準有一致的格式,一般對二進位和十進位的處理方式如下:
* 二進位的準確度為小數點後 4 位,$number_{2} \times 2^4 = 定點數_{2}$
* 十進位的準確度為小數點後 3 位,$number_{10} \times 10^3 = 定點數_{10}$
參考 [Fixed Point Arithmetic in C Programming](https://stackoverflow.com/questions/10067510/fixed-point-arithmetic-in-c-programming) 來進行定點數的實作,並定義出以下定點數表示方式,並將相關檔案中有 `double` 型別更改為 `fixed_point_t`,下方可以觀察到 log() 內部仍存在浮點數運算,所以需要設計相對應的定點數運算。
**game.h**
```c
#define FRACTION_BITS 16
#define MAX_FIXED_POINT (~0U)
#define MIN_FIXED_POINT (0U)
typedef unsigned fixed_point_t;
```
```diff=
...
- double calculate_win_value(char win, char player)
+ fixed_point_t calculate_win_value(char win, char player)
...
```
**mcts.c**
```diff
static inline fixed_point_t uct_score(int n_total, int n_visits, fixed_point_t score)
{
if (n_visits == 0)
- return DBL_MAX;
+ return MAX_FIXED_POINT;
return score / n_visits +
EXPLORATION_FACTOR * sqrt(log(n_total) / n_visits);
}
```
#### 「電腦 vs. 電腦」的對弈
這裡包含兩種對弈模式,一個是「人 vs.電腦」,也就是原先的對弈模式,另一個則是「電腦 vs. 電腦」的對弈。可採用以下指令進行
```bash
$ ./qtest
cmd> option aivsai 1
cmd> ttt
```
`option aivsai 1` 表示對弈模式為「電腦 vs. 電腦」。若要改回「人 vs.電腦」便輸入 option aivsai 0 即可,參見 [commit 0dd0d29](https://github.com/sysprog21/lab0-c/commit/0dd0d29993d17025c8971816e8727c828ea3e795) , [commit 1d12ae8](https://github.com/sysprog21/lab0-c/commit/1d12ae8252e163eb48cb0a34ddffa802c53811aa)。
---
## 研讀論文[〈Dude, is my code constant time?〉](https://eprint.iacr.org/2016/1123.pdf)
解釋本程式的 "simulation" 模式是如何透過以實驗而非理論分析,達到驗證時間複雜度,需要解釋 Student's t-distribution 及程式實作的原理。
該論文提出 dudect 工具,它用於評估一段程式碼在平台(不限於特定平台)上,是否以常數時間 O(1) 完成。它和先前研究的差異是不需要對硬體行為進行建模。
在論文中有提到以下內容,將通過執行時序測量的統計分析,也就是實驗,而非靜態分析(理論分析)。
> Our tool does not rely on static analysis but on statistical analysis of execution timing measurements on the target platform
在實際執行中,程式會執行多次,每次使用不同的輸入數據,並記錄每次執行所花費的時間。這樣做的目的是模擬實際運行環境中的執行時間變異,以確定程式是否符合期望的時間複雜度。
在這個過程中,程式會收集大量的執行時間數據,然後使用統計方法來分析這些數據。其中,使用了 Student's t-distribution,這是一種統計分佈,用於估計樣本平均值的信心區間。這種分佈通常應用於小樣本的情況,當樣本數量較大時,就會越接近標準常態分佈。
Student's t-distribution 可以用來確定兩個不同輸入類別的執行時間分佈是否在統計上有顯著差異。如果差異顯著,則認為存在 timing leakage 的可能性,反之則認為程式的執行時間與輸入數據無關,符合期望的時間複雜度。
Timing leakage 指的是在加密系統或其他安全應用中,由於執行時間的不同而洩露出敏感資訊。導致攻擊者可以通過監視這些時間變化來推斷出密鑰、密碼或其他重要資訊。例如,字串比對(密碼比對),若逐一比對時找到不相符的字元便立即回傳 false,而不是比對到最後一個,這樣便會造成執行時間不同,產生 leakage。
在圖 1 中,可看見兩個類別的時間分佈的 cumulative distribution function (cdf)。我們看到兩個類別的分佈明顯不同,即輸入資料存在 timing leakage

**解釋 simulation**
在 `./qtest.c` 中的 `queue_insert`,`queue_remove` 函式可以觀察到皆設有 simulation,用於檢查是否符合 constant time。
在 `queue_insert` 函式中藉由 pos 來決定要檢查哪裡的 constant time。
```c
bool ok = pos == POS_TAIL ? is_insert_tail_const() : is_insert_head_const();
```
關於 `is_insert_tail_const()`,`is_insert_head_const()` 的定義在 dudect/fixture.h 當中,如下。
```c
/* Interface to test if function is constant */
#define _(x) bool is_##x##_const(void);
```
參考 [ISO/IEC 9899:201x](https://www.open-std.org/jtc1/sc22/wg14/www/docs/n1548.pdf),其 `6.10.3.3 The ## operator` 裡頭提到以下:
> If, in the replacement list of a function-like macro, a parameter is immediately preceded or followed by a ## preprocessing token, the parameter is replaced by the corresponding argument’s preprocessing token sequence; however, if an argument consists of no preprocessing tokens, the parameter is replaced by a placemarker preprocessing token instead.
在 [concatenation](https://gcc.gnu.org/onlinedocs/cpp/Concatenation.html)^該詞彙意思是連結,接續^ 也提到以下例子,<s>我覺得</s> 對我理解很有幫助。藉由以下改寫,就不需要 commands table,只需要定義 `#define COMMAND(NAME) { #NAME, NAME ## _command }`,便可使程式碼更加乾淨。
:::danger
工程人員說話要精準,避免說「我覺得」
:::
**改善前**
```c
struct command
{
char *name;
void (*function) (void);
};
// commands table
struct command commands[] =
{
{ "quit", quit_command },
{ "help", help_command },
…
};
```
**改善後**
```c
#define COMMAND(NAME) { #NAME, NAME ## _command }
struct command commands[] =
{
COMMAND (quit),
COMMAND (help),
…
};
```
接著我閱讀〈[你所不知道的 C 語言:前置處理器應用篇](https://hackmd.io/@sysprog/c-preprocessor#%E9%96%8B%E7%99%BC%E7%89%A9%E4%BB%B6%E5%B0%8E%E5%90%91%E7%A8%8B%E5%BC%8F%E6%99%82%EF%BC%8C%E5%96%84%E7%94%A8%E5%89%8D%E7%BD%AE%E8%99%95%E7%90%86%E5%99%A8%E5%8F%AF%E5%A4%A7%E5%B9%85%E7%B0%A1%E5%8C%96%E9%96%8B%E7%99%BC)〉裡頭提示使用 `gcc -E -P` 來觀察巨集所產生的程式碼。我關注的程式碼如下。
```c
#define DUT_FUNCS \
_(insert_head) \
_(insert_tail) \
_(remove_head) \
_(remove_tail)
#define DUT(x) DUT_##x
enum {
#define _(x) DUT(x),
DUT_FUNCS
#undef _
};
```
執行以下命令,觀察 `DUT_FUNCS` 展開的程式碼
```shell
$ gcc -E -P dudect/constant.h
```
```c
#define DUT_FUNCS \
_(insert_head) \
_(insert_tail) \
_(remove_head) \
_(remove_tail)
DUT_FUNCS
```
```c
// Output
_(insert_head) _(insert_tail) _(remove_head) _(remove_tail)
```
執行以下命令,觀察經過 `#define _(x) DUT(x)` 處理後的程式
```c
#define DUT_FUNCS \
_(insert_head) \
_(insert_tail) \
_(remove_head) \
_(remove_tail)
enum {
#define _(x) DUT(x),
DUT_FUNCS
#undef _
};
```
```c
// Output
DUT(insert_head), DUT(insert_tail), DUT(remove_head), DUT(remove_tail),
```
在經過 `#define DUT(x) DUT_##x` 後,程式碼轉換成這樣
```c
DUT_insert_head, DUT_insert_tail, DUT_remove_head, DUT_remove_tail,
```
最終 `enum` 所包含的成員如下所示
```c
enum {
DUT_insert_head, DUT_insert_tail, DUT_remove_head, DUT_remove_tail,
};
```
而我也觀察到 `dudect/fixture.h` 定義以下函式,介面
:::danger
interface 的翻譯是「介面」,而非「接口」,你是多想要支付?
:::
:::info
對不起XD
:::
```c
/* Interface to test if function is constant */
#define _(x) bool is_##x##_const(void);
DUT_FUNCS
#undef _
```
經 `gcc -E -P` 你就能得到以下函式原型
```c
_Bool is_insert_head_const(void);
_Bool is_insert_tail_const(void);
_Bool is_remove_head_const(void);
_Bool is_remove_tail_const(void);
```
針對上方函式原型的詳細實作,在 `dudect/fixture.c` 可以觀察到
```c
_Bool is_insert_head_const(void) { return test_const("insert_head", DUT_insert_head); }
_Bool is_insert_tail_const(void) { return test_const("insert_tail", DUT_insert_tail); }
_Bool is_remove_head_const(void) { return test_const("remove_head", DUT_remove_head); }
_Bool is_remove_tail_const(void) { return test_const("remove_tail", DUT_remove_tail); }
```