Transformer: Attention mechanism & Positional embedding === ## Attention mechanism 注意力機制 最基本sequence to sequence的任務的時候,會用encoder將inout sequence的內容**壓縮/轉換**成一個context vector,通常這個context vector就是inoput sequence的最後一個hidden state,因為最後一個hidden state理論上是繼承了前面所有東西的記憶(整個序列的精華/集大成),然後decoder才會用context vector去生出output sequence  :::info - 問題:記憶長期資訊很困難,而且最早的資訊會被削弱 - 解法:Attention mechanism → 不再只依賴單一 context vector,而是根據每一步的output去**動態地關注**input的不同位置 ::: ### Q, K, V 每一個 input 都有三組權重去算出 Q, K, V,其實計算方法一樣,只是關注的重點不同。 |元素 | 在 attention 裡的角色 | 比喻| | -------- | -------- | -------- | |Query (Q) | 我要找的資訊 | 你要找的主題,例如「貓的睡眠習性」 |Key (K) | 資料庫的標籤 | 每本書的目錄卡:標題、主題 |Value (V) | 實際要讀取的資訊 | 書的內容(正文) 1. Key(K)用來決定「誰重要」 每個詞的 Key 向量會和當前詞的 Query 做比對(內積), 如果相似度(分數)不高 → 表示這個詞「對現在不重要」。 2. Score 不高 → Value 的內容就「貢獻得少」 雖然每個詞都有 Value,但 attention 機制會根據比對分數(attention weight)來加權。 所以如果你的 Key 不吸引人,你的 Value 就不會被「看重」。 :::success Key 決定你能不能「被注意」,Value 決定你「提供了什麼」—— 被注意得不夠,內容再好也沒人聽你說。 ::: ### 加入 Attention 的 Encoder-Decoder 訓練流程 :::info - Q (Query):Decoder 的當前 hidden state - K (Key):Encoder 每個詞的 hidden state - V (Value):Encoder 的 hidden state 經過加權 ::: 1. Encoder 輸入序列:每個詞會產生一個 hidden state:$[h₁, h₂, ..., hₙ]$ → 這些是 Key 2. Decoder 產生第 $t$ 個輸出詞:有一個 decoder hidden state $s_t$ → 這是 Query($t$ 指得是時間步) 3. 計算每個 Encoder hidden state 的 score(相似度加權分數) > $score_i = similarity(s_t, h_i)$ 4. 對所有 score 做 softmax 得到注意力權重 $α$:每個 $α_i$ 表示input sequence 中第 $i$ 個詞對應output的「重要性」 5. 用 $α$ 加權 Encoder 的 hidden states 得到 context vector → 這裡得到 Value > $context = Σ α_i * h_i$ 6. Decoder 用這個 context + $s_t$ 預測下一個詞  <p align="center" style="color: gray; font-size: 0.9em;"> 注意力架構圖 </p> align="center"> 每一次要計算下一步時,會用前一步來跟encoder的hidden state算score,然後得到context vector然後再產出該時間步的結果。  ### Score的常見算法 1. 內積相似度 Dot product similarity 計算 Q 和 K 變換後的向量之間的內積來衡量它們的相似度。內積越大,表示越相似。  2. 餘弦相似度 Cosine similarity 考慮到向量的長度,計算兩個向量之間夾角餘弦值,夾角越小方向越一致,相似度越高。  3. 矩陣乘法調整 Linear transformation 將原始的 Q 和 K 透過機器自學的參數矩陣 𝑊 進行線性調整之後再求內積相似度。  4. 向量拼接 Concatenation 先將 Q 和 K 拼接(concat)起來,然後經過自學的參數矩陣 𝑊 進行線性調整,再透過 activation function 做非線性的轉換,最後乘以一個權重矩陣 𝑉 生成最終的輸出,使得輸出結果回到跟輸入序列相同的長度。  ## Self-attention vs. Multi-head attention 1. Q 和 K 做內積($q ⋅ k$) - 看 Query 和每個 Key 的相似度(關聯性高不高)。 - 相似度越高,表示越「值得注意」。 2. 算出每個詞的注意力權重(softmax) - 把前面算的的相似度轉成 0~1 之間的比重。  3. 權重乘上 Value,加總起來,最後得到最終的注意力輸出。  在上圖就只有處理一個組input $a^1$ 還有其 $q^1, k^1, v^1$。 如果同時處理多組input 就會是multi-head attention,如下圖,不同組input也會去各自捕捉他們之間的關聯。  多個平行的 self-attention 計算出來的注意力輸出,最後會全部 concat 起來,再做線性轉換的處理後成為最終結果。  :::info 小比喻: - Self-attention 就像是「一個人」用「一種視角」去理解一段文字。 - Multi-head attention 就像是有很多人,每個人用自己獨特的觀點,一起來讀同一段文字,最後綜合大家的意見。 ::: ## Positional embedding Transformer 不像 RNN、LSTM 那樣有「時間順序」的概念,它在處理句子時是一次看。所一整句,所以會需要positional embedding 去處理詞的「順序」。 Positional embedding 就是把「詞的位置」編碼成一個向量,然後加到詞的語意向量上。 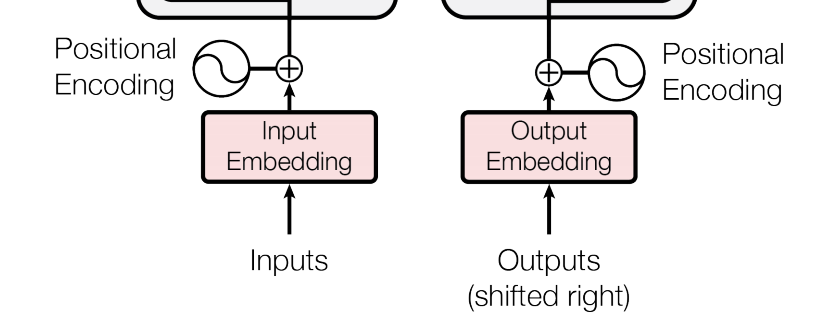 ### Fixed vs. learnable 1. Fixed Positional Encoding(固定位置編碼) 用 sine 和 cosine 函數來產生固定的位置向量: 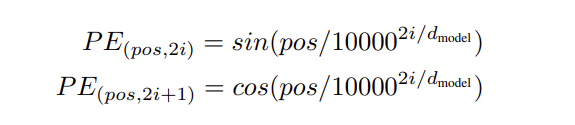 - 優點:因為是用公式算,可以直接處理比訓練時「更長的句子」,不會因為沒看過的位置就失效(泛化能力好) - 缺點:無法針對特定語料調整位置資訊 2. Learnable Positional Encoding(可學習式位置編碼) 用一個「位置查表」的方式,跟詞的 embedding 一樣,讓模型自己學每個位置的向量。 - 優點:可以針對特定語言、文本結構、自定義任務去調整位置夾帶的信息 - 缺點:無法泛化到更長句子(例如:如果訓練時只給模型看過 512 個位置,它就不知道第 513 個詞該用什麼位置向量) ### Absolute vs. relative 1. Absolute Positional Encoding(絕對位置編碼) 每個固定位置(例如:第一個詞、第二個詞…)都對應到一個獨特的向量,這種編碼通常會是前面的固定位置編碼的方式。 - 優點:實作簡單,結構清楚(使用sin, cos 的數學公式計算)能處理任意長度句子 - 缺點:較不擅長捕捉詞與詞間的「相對關係」,對長距離依賴效果有限(例如:當主詞跟動詞離得很遠的時候,就很難抓到這兩個字的語意關聯、結構) 2. Relative Positional Encoding(相對位置編碼) 這種編碼強調序列元素之間相對距離。所以不是關注字詞是「句子的第幾個詞」,而是更在意兩個字詞之間「相隔幾個位置」。 - 優點:更自然地模擬語言中的「關係性」 - 缺點:實作較複雜,需要額外設計查表或邏輯 --- **後記想法** 模型本身並不會知道什麼是「問」或「答」的概念,它只是學到用怎樣的向量運算組合能讓最後的 loss 達到最小。 這些語意功能的角色(Query, Key Value)都是「 emergent behavior」(從訓練中自發出現的行為)是模型在大量語料中學出來的「有用結構」,人類再幫它貼上合理的解釋。 Transformer 的 Attention 機制就像一台數學工廠: - 它並不知道什麼叫語意、問答、重點 - 它只是根據數據學會了:「我這樣計算,效果就比較好」 - 我們人類從外面觀察它的行為,說:「喔~它在做類似問問題、找重要資訊的事欸~」 ## References 1. [28. 注意力機制(Attention mechanism)](https://medium.com/programming-with-data/28-%E6%B3%A8%E6%84%8F%E5%8A%9B%E6%A9%9F%E5%88%B6-attention-mechanism-f3937f289023) 2. [深入理解 Attention 機制(上)- 起源](https://medium.com/@funcry/%E6%B7%B1%E5%85%A5%E7%90%86%E8%A7%A3-attention-%E6%A9%9F%E5%88%B6-b40be0985e84) 3. [Attention Mechanism(注意力機制)](https://marssu.coderbridge.io/2020/11/30/attention-sequence-to-sequence/) 4. [ML : Self-attention](https://medium.com/@x02018991/%E6%A9%9F%E5%99%A8%E5%AD%B8%E7%BF%92%E7%AD%86%E8%A8%98-self-attention-fa6897080a0a) 5. [[AI學習筆記] 李宏毅課程 Multi-head Self-Attention 機制解說](https://andy6804tw.github.io/2021/05/03/ntu-multi-head-self-attention/) 6. [[鐵人12:Day 20] Transformer 3:模型架構 (2)](https://ithelp.ithome.com.tw/m/articles/10248303) 7. [Positional Encoding](https://www.kaggle.com/code/lianghsunhuang/positional-encoding#%E6%8E%A2%E7%B4%A2%E4%BD%8D%E7%BD%AE%E7%B7%A8%E7%A2%BC%EF%BC%9A%E7%B5%95%E5%B0%8D%E8%88%87%E7%9B%B8%E5%B0%8D%E4%BD%8D%E7%BD%AE%E7%B7%A8%E7%A2%BC%E7%9A%84%E7%90%86%E8%A7%A3%E8%88%87%E5%AF%A6%E7%8F%BE)
×
Sign in
Email
Password
Forgot password
or
Sign in via Google
Sign in via Facebook
Sign in via X(Twitter)
Sign in via GitHub
Sign in via Dropbox
Sign in with Wallet
Wallet (
)
Connect another wallet
Continue with a different method
New to HackMD?
Sign up
By signing in, you agree to our
terms of service
.