###### tags: `Plus` `SQL` `Redis`
# 資料庫基礎(SQL/NoSQL)
## 安裝PostgreSQL:
```bash
# 查看 PostgreSQL 版本資訊
apt-cache show postgresql
# 安裝 postgresql-10
sudo apt install postgresql-10 postgresql-contrib
# 查看 PostgreSQL 服務狀態
systemctl status postgresql.service
```
```bash
# 下載 PostgreSQL 套件庫資訊
wget https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat-repo-latest.noarch.rpm
# 安裝 PostgreSQL 套件庫資訊與 EPEL
sudo yum install pgdg-redhat-repo-latest.noarch.rpm epel-release
# 安裝 10 版 PostgreSQL
sudo yum install postgresql10-server postgresql10-contrib
# 查看 PostgreSQL 服務狀態
systemctl status postgresql.service
```
## 使用PostgreSQL:
```bash
sudo su postgres
##postgres
psql --version
##確認版本
cd /var/lib/postgresql
##進入postgresql根目錄
psql -l
##確認已建立資料庫
##template0~1為板模數據庫
psql dbName
##進入dbName資料庫
createdb dbName
##創建dbName資料庫
dropdb dbName
##刪除dbName資料庫
create table TableName (title varchar(255), content text);
##創建表格
\dt
##查詢資料庫table
\d TableName
##查詢表格內容
alter table posts TableNameOLD to TableNameNEW
\dt;
##對表格更名
\q
##離開
\i Example.sql
## 執行該檔案命令
\x
## 表格呈現橫向顯示
```
```bash
## 創建表格
ceate table TableName(
id serial primary key,
title varchar(255) not null,
content text check(length(content) > 3),
is_del boolean default FALSE,
created_date timestamp default 'now'
);
# not null不能為空
# unique:必須唯一存在
# primary key(not null, unique): 不能為空+必須唯一存在
# check: 屬性設置條件
# default: 屬性默認值
```
## 備份使用mysqldump
### 備份單一資料庫
```bash=
mysqldump -h hostname -u root -p database_name > backup.sql;
# 備份資料庫中單一資料表
mysqldump -u root -p database_name table_name > backup.sql;
# 備份資料庫中多張資料表
mysqldump -u root -p database_name table1 table2 > backup.sql;
#備份多個資料庫
mysqldump -u root -p --databases db1 db2 > backup.sql;
#備份所有資料庫
mysqldump -u root -p --all-databases > backup.sql;
```
### 指令範例-復原
```bash=
# 復原單一資料庫
mysql -u root -p database_name < backup.sql
# 復原多個資料庫
mysql -u root -p < backup.sql
```
## MySQL資料型別:
https://html5-editor.net/
https://www.tablesgenerator.com/markdown_tables
<table cellspacing="5" cellpadding="0">
<tbody>
<tr><td>
<p>數字型態
<div>
<table cellspacing="1" cellpadding="0">
<tbody>
<tr><td>
<p>型態</p>
</td><td>
<p>空間需求</p>
</td><td>
<p>範圍</p>
</td></tr>
<tr><td>
<p>TINYINT[(M)]</p>
</td><td>
<p>1 byte</p>
</td><td>
<p>Signed: -128 to 127 (-2^7 to 2^7 -1) <br> Unsigned: 0 to 255 (0 to 2^8 -1)</p>
</td></tr>
<tr><td>
<p>SMALLINT[(M)]</p>
</td><td>
<p>2 bytes</p>
</td><td>
<p>Signed: -32768 to 32767 (-2^15 to 2^15 -1) <br> Unsigned: 0 to 65535 (0 to 2^16 -1)</p>
</td></tr>
<tr><td>
<p>MEDIUNINT[(M)]</p>
</td><td>
<p>3 bytes</p>
</td><td>
<p>Signed: -8388608 to 8388607 (-2^23 to 2^23 -1) <br> Unsigned: 0 to 16777215 (0 to 2^24 -1)</p>
</td></tr>
<tr><td>
<p>INT[(M)]<br> INTEGER[(M)]</p>
</td><td>
<p>4 bytes</p>
</td><td>
<p>Signed: -2147483648 to 2147483647 (-2^31 to 2^31 -1) <br> Unsigned: 0 to 4294967295 (0 to 2^32 -1)</p>
</td></tr>
<tr><td>
<p>BIGINT[(M)]</p>
</td><td>
<p>8 bytes</p>
</td><td>
<p>Signed: (-2^63 to 2^63 -1) <br> Unsigned: (0 to 2^64 -1)</p>
</td></tr>
<tr><td>
<p>FLOAT(precision)</p>
</td><td>
<p>4 or 8</p>
</td><td>
<p>若 precision <= 24 的話,視為 FLOAT (單精數) <br> 若 25 <= precision <= 53 的話,則視為 DOUBLE (倍精數)</p>
</td></tr>
<tr><td>
<p>FLOAT[(M,D)]</p>
</td><td>
<p>4 bytes</p>
</td><td>
<p>±1.175494351E-38 ±3.402823466E+38</p>
</td></tr>
<tr><td>
<p>DOUBLE[(M,D)]<br> REAL[(M,D)]</p>
</td><td>
<p>8 bytes</p>
</td><td>
<p>±1.7976931348623157E+308 ±-2.2250738585072014E-308</p>
</td></tr>
<tr><td>
<p>DECIMAL[(M[,D])]<br> DEC[(M[,D])] <br> NUMERIC[(M[,D])]</p>
</td><td>
<p>M+2</p>
</td><td>
<p>依 M 與 D 值而定</p>
</td></tr>
</tbody>
</table>
</div>
</td></tr>
<tr><td>
<p>上表中的 M 代表「最大顯示寬度」,其值不得大於 255 上表中的 D 代表「小數位數」,其值不得大於 30 ,也不能大於 M-2 。</p>
</td></tr>
</table>
<table>
<tr><td>
<p>日期與時間型態</p>
</td></tr>
<tr><td>
<div>
<table cellspacing="1" cellpadding="0">
<tbody>
<tr><td>
<p>型態</p>
</td><td>
<p>空間需求</p>
</td><td>
<p>範圍</p>
</td></tr>
<tr><td>
<p>DATE</p>
</td><td>
<p>3 bytes</p>
</td><td>
<p>'1000-01-01' to '9999-12-31'</p>
</td></tr>
<tr><td>
<p>TIME</p>
</td><td>
<p>3 bytes</p>
</td><td>
<p>'-838:59:59' to '838:59:59'</p>
</td></tr>
<tr><td>
<p>DATETIME</p>
</td><td>
<p>8 bytes</p>
</td><td>
<p>'1000-01-01 00:00:00' to '9999-12-31 23:59:59'</p>
</td></tr>
<tr><td>
<p>TIMESTAMP[(M)]</p>
</td><td>
<p>4 bytes</p>
</td><td>
<p>自 1970 年起,至 2037 年的某時</p>
</td></tr>
<tr><td>
<p>YEAR[(2 | 4)]</p>
</td><td>
<p>1 bytes</p>
</td><td>
<p>4-digit format: 1901 to 2155<br> 2-digit format: 1970 to 2069</p>
</td></tr>
</tbody>
</table>
</div>
</td></tr>
<tr><td>
<p>在使用 TIMESTAMP 型態時,您可以指定「最大顯示寬度」,就是 M 。不同的 M 值與儲存所需空間無關,而是與顯示的格式有關。請見下表:</p>
</td></tr>
<tr><td>
<div>
<table cellspacing="0" cellpadding="0">
<tr><td>
<p>型態</p>
</td><td>
<p>顯示格式</p>
</td></tr>
<tr><td>
<p>TIMESTAMP(14)</p>
</td><td>
<p>YYYYMMDDHHMMSS</p>
</td></tr>
<tr><td>
<p>TIMESTAMP(12)</p>
</td><td>
<p>YYMMDDHHMMSS</p>
</td></tr>
<tr><td>
<p>TIMESTAMP(10)</p>
</td><td>
<p>YYMMDDHHMM</p>
</td></tr>
<tr><td>
<p>TIMESTAMP(8)</p>
</td><td>
<p>YYYYMMDD</p>
</td></tr>
<tr><td>
<p>TIMESTAMP(6)</p>
</td><td>
<p>YYMMDD</p>
</td></tr>
<tr><td>
<p>TIMESTAMP(4)</p>
</td><td>
<p>YYMM</p>
</td></tr>
<tr><td>
<p>TIMESTAMP(2)</p>
</td><td>
<p>YY</p>
</td></tr>
<br>
</td></tr>
</tbody>
</table>
<tbody>
<table>
<table cellspacing="5" cellpadding="0">
<tbody>
<tr>
<td>
<p>字串型態</p>
</td>
</tr>
<tr>
<td>
<div>
<table cellspacing="1" cellpadding="0">
<tbody>
<tr>
<td>
<p>型態</p>
</td>
<td>
<p>空間需求</p>
</td>
<td>
<p>最大長度</p>
</td>
</tr>
<tr>
<td>
<p>CHAR(M)</p>
</td>
<td>
<p>M bytes</p>
</td>
<td>
<p>M bytes</p>
</td>
</tr>
<tr>
<td>
<p>VARCHAR(M)</p>
</td>
<td>
<p>L+1 bytes</p>
</td>
<td>
<p>M bytes</p>
</td>
</tr>
<tr>
<td>
<p>TINYBLOB, TINYTEXT</p>
</td>
<td>
<p>L+1 bytes</p>
</td>
<td>
<p>2^8 -1 bytes</p>
</td>
</tr>
<tr>
<td>
<p>BLOB, TEXT</p>
</td>
<td>
<p>L+2 bytes</p>
</td>
<td>
<p>2^16 -1 bytes</p>
</td>
</tr>
<tr>
<td>
<p>MEDIUMBLOB, MEDIUMTEXT</p>
</td>
<td>
<p>L+3 bytes</p>
</td>
<td>
<p>2^24 -1 bytes</p>
</td>
</tr>
<tr>
<td>
<p>LONGBLOB, LONGTEXT</p>
</td>
<td>
<p>L+4 bytes</p>
</td>
<td>
<p>2^32 -1 bytes</p>
</td>
</tr>
<tr>
<td>
<p>ENUM( 'value1','value2',...)</p>
</td>
<td>
<p>1 or 2 bytes</p>
</td>
<td>
<p>65535 個成員</p>
</td>
</tr>
<tr>
<td>
<p>SET( 'value1','value2',...)</p>
</td>
<td>
<p>1, 2, 3, 4, or 8 bytes</p>
</td>
<td>
<p>64 個成員</p>
</td>
</tr>
</tbody>
</table>
</div>
</td>
</tr>
<tr>
<td>
<p>上表中的 L 代表「實際儲存的空間大小」,上述多種型態的空間需求都與實際存入的空間大小有關,意即,它們的空間需求是變動的。</p>
</td>
</tr>
<tr>
<td>
<p>CHAR 與 VARCHAR</p>
<table cellspacing="0" cellpadding="0">
<tbody>
<tr>
<td>
<p>字串內容</p>
</td>
<td>
<p>CHAR(4)</p>
</td>
<td>
<p>空間需求</p>
</td>
<td>
<p>VARCHAR(4)</p>
</td>
<td>
<p>空間需求</p>
</td>
</tr>
<tr>
<td>
<p>''</p>
</td>
<td>
<p>' '</p>
</td>
<td>
<p>4 bytes</p>
</td>
<td>
<p>''</p>
</td>
<td>
<p>1 byte</p>
</td>
</tr>
<tr>
<td>
<p>' ab '</p>
</td>
<td>
<p>' ab '</p>
</td>
<td>
<p>4 bytes</p>
</td>
<td>
<p>' ab '</p>
</td>
<td>
<p>3 bytes</p>
</td>
</tr>
<tr>
<td>
<p>' abcd '</p>
</td>
<td>
<p>' abcd '</p>
</td>
<td>
<p>4 bytes</p>
</td>
<td>
<p>' abcd '</p>
</td>
<td>
<p>5 bytes</p>
</td>
</tr>
<tr>
<td>
<p>' abcdefgh '</p>
</td>
<td>
<p>' abcd '</p>
</td>
<td>
<p>4 bytes</p>
</td>
<td>
<p>' abcd '</p>
</td>
<td>
<p>5 bytes</p>
</td>
</tr>
</tbody>
</table>
</div>
</td>
</tr>
<tr>
<td>
<p>VARCHAR 和各類 TEXT 與 BLOB 都是長度可變的型態,這是它最大的優點;檢索時擁有較佳的效率,則是 CHAR 的長處。</p>
</td>
<tr>
<td>
<p>BLOB 的全名是「 binary large object 」,與 TEXT 一樣,都是用來儲存長度較長的字串或是二元資料。兩者大同小異,唯一的差別在於, TEXT 是有區分大小寫的,而 BLOB 不分。</p>
</td>
<tr>
<td>
<p>ENUM 與 SET 是特別的字串型態,有人稱之為「列舉( enumeration )」型態。這兩種欄位的值只能從固定的項目中挑選,不能隨心所欲的存入資料。舉個例子來看,我們想調查使用者的性別與年齡分布狀況,所以設定了以下兩種欄位:</p>
</td>
</tbody>
</table>
## MySQL常用指令:
```bash
mysql -uroot -p!@$!F
#進入mysql root帳戶
SHOW DATABASES;
#顯示資料庫名稱
USE gamedb_chtqat;
#使用該資料庫
SELECT DATABASE();
#顯示正在使用資料庫名稱
SHOW TABLES;
#顯示該資料庫的所有表
describe playerinfo;
DESC TableName;
#查詢該TABLE欄位屬性
SHOW CREATE TABLE 表名稱;
#查詢該TABLE創建語法
SOURCE xxx.sql
#載入sql檔案
EXIT
#離開MySQL
```
## SQL語法執行順序說明:
| 順序 | 語法 | 註解 |
|- |- |- |
|1| ==FROM== | 來源Table |
|2| ==WHERE== | 過濾Data |
|3| ==GROUP BY== | 分組Data |
|4| ==HAVING== | 過濾Data |
|5| ==SELECT== | 取樣Data |
|6| ==ORDER BY== | 排序Data |
* ==WHERE==在==GROUP BY==之前進行過濾,==HAVING==在 ==GROUP BY==之後進行過濾
**SQL語法分類:**
https://www.1keydata.com/tw/sql/sql-alter-table.html
## SQL DDL 資料定義語言:
**(1) 資料定義語言(Data Definition Language,DDL):**
==CREATE== : 創建表格
```sql
CREATE TABLE "表格名"
("欄位名稱1" "資料型別1" "欄位條件",
"欄位名稱2" "資料型別2" "欄位條件",
... )
CREATE TABLE TableName(
id serial primary key,
title varchar(255) not null,
content text check(length(content) > 3),
is_del boolean default FALSE,
created_date timestamp default 'now'
);
```
```sql
CREAT VIEW CVName SELECT (TN1.C1,TN2.C2) FROM (TableName1 as TN1,TableName2 as TN2) WHERE TN1.C1=TN2.C2;
/* 列出TableName1.C2等於TableName2.C2之中顯示出TableName1.C1兩者TableName2.C2並列表格(其中將TableName1作縮寫TN1) */
/* 將上敘述指令值型結果編制成 CVName */
SELECT * FROM CVName;
/* 可重複使用CVName簡化指令 */
DROP VIEW CVName;
```
==ALTER== : 改變表格
```sql
ALTER TABLE TableName ADD ColumnName char(1);
/* 在表格TableName加入新欄位ColumnName */
ALTER TABLE TableName DROP ColumnName;
/* 在表格TableName中將ColumnName欄位刪除 */
ALTER TABLE TableNameOLD RENAME TO TableNameNEW;
/* 在表格TableNameOLD名稱改成TableNameNEW */
ALTER TABLE TableName RENAME ColumnNameOLD to ColumnNameNEW;
/* 在表格TableName中將ColumnNameOLD欄位名稱改成ColumnNameNEW */
ALTER TABLE TableName ALTER ColumnName type char(30);
/* 將表格TableName中將ColumnName欄位資料型別改成 char(30) */
ALTER DATABASE DBName CHARACTER SET 'utf8' COLLATE 'utf8_general_ci';
/* 將表格DBName中將欄位資料編碼改成'utf8'和 'utf8_general_ci'*/
```
==DROP== : 刪除表格(危險)
```sql
DROP TABLE Customer;
```
## SQL Constraint 限制:
| 語法 | 說明 | 註解 |
|- |- |- |
|==NOT NULL== | 非空值限制 |
|==UNIQUE== | 唯一限制 |
|==PRIMARY KEY== | 主鍵限制 | ==UNIQUE==+==NOT NULL== → PRIMARY KEY (\`欄位1\`, \`欄位2\`)
|==FOREIGN KEY== | 外鍵限制 |
|==CHECK== | 檢查限制 | CHECK (\`欄位\`>0))
|==DEFAULT== | 預設值限制 | INSERT 時的資料預設值|
**==AUTO_INCREMENT==:**
```sql
CREATE TABLE TableName (
ColumnName INT AUTO_INCREMENT,
PRIMARY KEY (ColumnName)
);
/* AUTO_INCREMENT 為自動增加值,故同時也是UNIQUE,常與P rimary Key搭配使用 */
```
**==INDEX==**:
```sql
-- 創建索引
CREATE INDEX IndexName ON TableName (ColumnName1, ColumnName2);
-- 刪除索引
ALTER TABLE TableName DROP INDEX index_name;
/* INDEX和PRIMARY KEY最大不同於,INDEX可用於多個欄位增加檢索速度*/
```
**==FOREIGN KEY==**:
```sql
CREATE TABLE TableName1 (
ColumnName11 INT(10),
PRIMARY KEY (ColumnName12),
FOREIGN KEY (ColumnName12) REFERENCES TableName2 (ColumnName21)
);
--創建外來鍵
CREATE TABLE TableName2 (
ColumnName21 INT(10) ,
PRIMARY KEY (ColumnName21)
);
-- 新增外來鍵
ALTER TABLE TableName3 ADD FOREIGN KEY (ColumnName31) REFERENCES TableName2 (ColumnName21);
-- 新增外來鍵(同步更新)
ALTER TABLE TableName4 ADD FOREIGN KEY (ColumnName41) REFERENCES TableName2 (ColumnName21) ON UPDATE CASCADE;
-- 新增外來鍵(同步更新與刪除成預設值)
ALTER TABLE TableName5 ADD FOREIGN KEY (ColumnName51) REFERENCES TableName2 (ColumnName21) ON UPDATE CASCADE ON DELETE CASCADE;
```
## SQL DML 資料處理語言:
**(2) 資料處理語言(Data Manipulation Language,DML):**
==INSERT== : 插入表格
```sql
INSERT INTO 表格名 (欄位1, 欄位2, ...) VALUES (值1, 值2, ...);
INSERT INTO TableName (ColumnName1,ColumnName2) VALUES ('Los Angeles', 900);
```
==UPDATE== : 更新表格
```sql
UPDATE 表格名 SET 欄位名 = (值表示式) WHERE (條件式);
UPDATE TableName SET ColumnName = (ColumnName+1) WHERE (ColumnName) IS NOT NULL;
/* 將表格TableName之ColumnName欄位內符合不為空值,其值更新為原本值+1 */
```
==DELETE== : 刪除表格
```sql
DELETE FROM 表格名 WHERE (條件式);
```
==SELECT== : 選取表格
```sql
SELECT (欄位1, 欄位2, ...) FROM 表格名;
SELECT * FROM TableName;
/* 將選擇表格TableName所有內容 */
SELECT (欄位1, 欄位2, ...) FROM 表格名 ORDER BY (欄位1,欄位2, ...) ASC;
SELECT (欄位1, 欄位2, ...) FROM 表格名 ORDER BY (欄位1,欄位2, ...) DESC;
/* 將選擇表格TableName的欄位內容,並依欄位名升序排列 */
SELECT * FROM TableName ORDER BY (ColumnName1,ColumnName2) ASC;
/* 將選擇表格TableName所有內容,並依欄位名升序排列 */
SELECT * FROM TableName ORDER BY 2 ASC;
/* 將選擇表格TableName所有內容,並依第二個欄位名升序排列 */
SELECT * FROM TableName ORDER BY (ColumnName1) ASC LIMIT 3;
/* 將選擇表格TableName所有內容,並依欄位名升序排列,限取前三名 */
SELECT * FROM TableName ORDER BY (ColumnName1) ASC LIMIT 3 OFFSET 2;
/* 將選擇表格TableName所有內容,並依欄位名升序排列,限取三名(第3~5名) */
SELECT DISTINCT 欄位名 FROM 表格名;
/* 列舉表格內欄位名的所有項目(不重複) */
SELECT SUM 欄位名 FROM 表格名;
/* 計算表格內欄位名的總和 */
SELECT MAX 欄位名 FROM 表格名;
/* 顯示表格內欄位名的最大值 */
SELECT COUNT (欄位名) FROM 表格名 WHERE 欄位名 IS NOT NULL;
/* 計算表格內欄位名的數量(不包含空值) */
SELECT * FROM TableName WHERE ColumnName1 = (SELECT MAX(ColumnName2) FROM TableName);
/* 顯示TableName中ColumnName1值符合等於ColumnName2欄位中的最大值者 */
SELECT (CTeam,MAX(CScore)) FROM TableName GROUP BY (CTeam) HAVING MAX(CScore)>=25;
/* 顯示CTeam和最大CScore欄位並依CTeam欄位取樣,限定最大CScore值必須大於25 */
SELECT (TableName1.C1,TableName2.C1) FROM (TableName1,TableName2) WHERE TableName1.C2=TableName2.C2;
/* 列出TableName1.C2等於TableName2.C2之中顯示出TableName1.C1兩者TableName2.C2並列表格 */
SELECT (TN1.C1,TN2.C2) FROM (TableName1 as TN1,TableName2 as TN2) WHERE TN1.C1=TN2.C2;
/* 列出TableName1.C2等於TableName2.C2之中顯示出TableName1.C1兩者TableName2.C2並列表格(其中將TableName1作縮寫TN1) */
```
## SQL語法計算符號:
| 符號 | 說明 | 註解 |
|- |- |- |
| `+` |- |- |
| `-` |- |- |
| `*` |- |- |
| `/` | 結果包含小數 |- |
| `%` | 求餘數 |- |
## SQL語法邏輯判斷:
| ----- 符號 -------- | 說明 | 註解 |
|- |- |- |
| `=` | 等於 |- |
| `!=` | 不等於 |- |
| `<>` | 不等於 |- |
| `<` | 大於 |- |
| `<=` | 大於等於 |- |
| `>` | 小於 |- |
| `>=` | 小於等於 |- |
| `AND` | 且 |- |
| `OR` | 或 |- |
| `NOT` | 非 |- |
| `IN` | 包含 |- |
| `NOT IN` | 不包含 |- |
| `BETWEEN` ... `AND` | 介於兩值之間 | 相當於使用`>=`和`<=` |
| `IS NULL` | 為空值 |- |
| `IS NOT NULL` | 非空值 |- |
| `LIKE` | 模糊查詢 |`'%'`(不限長度匹配)和 `'_'`(固定長度匹配)使用 |
## SQL語法 `SELECT` & `SELECT DISTINCT` 函數:
| ----- 函數 -------- | 說明 | 註解 |
|- |- |-
|SUM()|總和|
|MIN()|最小值|
|MAX()|最大值|
|AVG()|平均|
|LEN()|計算字元長度(MS)|
|LENGTH()|計算字元長度|
|COUNT()|計算數量|==COUNT(*)== → 計算所有數量|
|SUBSTR|擷取字元|SUBSTR(欄位名,開始位置,擷取長度)|
|TRIM()|除去最左右空格|
|RAND()|隨機數產生|
|REPLACE()|取代字元|REPLACE(欄位, '欲取代的字串', '取代後的字串'|
|ROUND()|四捨五入|ROUND(欄位, '近位位數'|
|FROM_UNIXTIME()|將日期變數轉換成字串|FROM_UNIXTIME(日期欄位,"%d-%m-%Y %h:%i")|
|DATE_FORMAT()|將日期變數轉換成字串|DATE_FORMAT(日期欄位,"%d-%m-%Y %h:%i")|
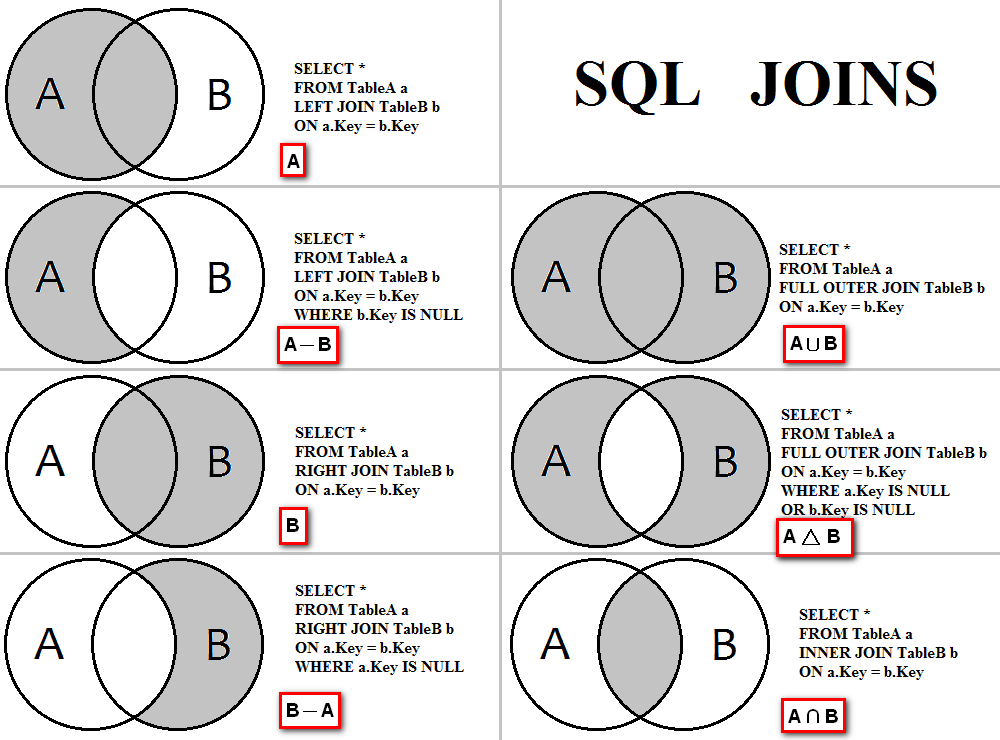
## SQL語法 `Join` 集合:
## SQL DCL 資料控制語言:
**(3) 資料控制語言(Data Control Language,DCL):**
`GRANT` : 開啟權限設置
```sql
GRANT DELETE,INSERT,SELECT,QUERY REWRITE ON TableName TO User01 ;
/* 將 TableName表格中的DELETE,INSERT,SELECT,QUERY REWRITE 權限開放給User01*/
```
`REVOLE` : 取消權限設置
```sql
REVOKE DELETE,INSERT,SELECT ON TableName FROM User01;
/* 將 TableName表格中的DELETE,INSERT,SELECT,QUERY REWRITE 權限取消自User01*/
```
**(4) 交易控制語言(Transaction Control Language,TCL):**
交易功能4個特性 (ACID)
* Atomicity (原子性、不可分割):交易內的 SQL 指令,不管在任何情況,都只能是全部執行完成,或全部不執行。若是發生無法全部執行完成的狀況,則會回滾(rollback)到完全沒執行時的狀態。
* Consistency (一致性):交易完成後,必須維持資料的完整性。所有資料必須符合預設的驗證規則、外鍵限制...等。
* Isolation (隔離性):多個交易可以獨立、同時執行,不會互相干擾。這一點跟後面會提到的「隔離層級」有關。
* Durability (持久性):交易完成後,異動結果須完整的保留。
`START TRANSACTION 或 BEGIN` : 開始交易
```sql
START TRANSACTION;
BEGIN;
```
`COMMIT` : 將開始交易的過程的執行結果提交
`SAVEPOINT` : 在交易過程中設置儲存點
`RELEASE SAVEPOINT` : 刪除在交易過程中設置儲存點
`ROLLBACK` : 回復交易設置儲存點或開始前
```sql
BEGIN;
...
ROLLBACK;
-- 回復交易開始前
```
```sql
BEGIN;
...
SAVEPOINT SV1;
...
ROLLBACK TO SV1;
-- 回復存點SV1以前的狀態
```
關閉/打開自動commit (僅對當下Session有效)
```sql
set autocommit = off;
set autocommit = on;
```
### 不能 ROLLBACK 的指令
* DDL 的指令
### 會造成自動終止交易並 COMMIT 的指令
執行這些指令時,如同先執行了 commit:
* DDL 指令:ALERT TABLE、CREATE INDEX、CREATE TABLE、DROP TABLE、DROP DATABASE、RENAME TABLE、TRUNCATE、LOCK TABLES、UNLOCK TABLES...等
* SET AUTOCOMMIT=1、 BEGIN、START TRANSACTION
### 事務隔離等級
```sql
SET session transaction isolation level Read Uncommitted
SET session transaction isolation level Read Committed
SET session transaction isolation level Repeatable Read
SET session transaction isolation level Serializable
SELECT @@tx_isolation
```
* 髒讀(Dirty Read): 其他使用者可以看到交易未commit的結果。
* 不可重複讀(Non-Repeatable Read): 發起交易過程會可讀取到其他使用者已commit的結果,可能導致更新結果為非本次交易所期望的結果。
* 幻讀(Phantom Read): 其他使用者無法看到交易未commit的結果。因此發起交易過程可能將其他使用者的交易結果覆蓋或是插入新行時回報錯誤。
|事務隔離等級|特性|髒讀|不重複|幻讀|
|-|-|-|-|-|
|Read Uncommitted|最不實用|✓|✓|✓|
|Read Committed|最常使用||✓|✓|
|Repeatable Read|MySQL預設|||✓|
|Serializable|最安全||||
事務隔離等級參考網址:https://kknews.cc/news/l9qlyag.html
## Redis 安裝/操作
```bash
##Ubuntu 安裝步驟
sudo apt-get update
sudo apt-get upgrade
sudo apt-get install redis-server
sudo systemctl enable redis-server.service
## redis安裝檔位於 : /etc/redis/redis.conf
# daemonize no → 設定背景執行(服務)
# maxmemory 256mb → 配置内存限额
# maxmemory-policy volatile-lru → 配置淘汰策略
sudo systemctl restart redis-server.service #重啟伺服器
## redis的一般指令
redis-benchmark #性能測試
redis-check-aof #修復AOF文件
redis-check-dump #修復有問題的dump.rdb
redis-sentinel #redis集群
redis-server#確認起動狀態
redis-cli #客戶端介面登入
redis-cli shutdown #關閉server
/etc/init.d/redis-server stop 停止server背景執行
## redis-cli 客戶端介面
select 8 #切換編號8數據庫,默認有編號0~15的數據庫
keys * #查詢所有key
keys ? #查詢字元數為1的key
keys ?? #查詢字元數為2的key
keys [1-3]* #查詢1*和2*和3*的key
set "測試" "數值" #
exists keyname #判斷keyname是否存在,存在返回1否則返回0
type keyname #查詢該keyname的數據類型
expire key second #為健值設置過期時間(秒),返回設置成功數1
ttl key #查看key還有多少秒過期(-1永不、-2已過期)
dbsize #查看當前數據庫數量
flushdb #清空當前庫
flushall #清空所有
```
```
*key&value單個長度限制512MB
*key數量最高限制為2^32
get key 查詢健值
set
append key value 將原先value增加value 成功後返回字串總長
strlen key 獲得長度
setnx key value key不存在狀況下創建新的KV 回傳創建成功1
incr key 將key儲存值+1(空值視為0),非數值將返回錯誤
decr key key值-1
incrby key add key
decrby key --
```
```
mset key1 value1 key2 value2
mget key1 key2 無健者將回傳nil
msetnx key1 value1 key2 value2 必須在全部不存在狀況下才能更改成功
getrange key 0 3 取的該value中1~4的字元(-2表示最後第二位,-1表示最後一位)
setrange key 3 value 將該value第四位字元後面取代成vaule
setex key 秒 value 重新設定該key過渡時間
getset key value 效果等同set,但設定完成會返回舊values
##list 單鍵多值(次序性的管道)
lpush key value1 value2 ... 將管道由左側存入值
rpush key value1 value2 ... 將管道由右側存入值
lpop key 將管道值由左吐出,管道若為空將會自動刪除
rpop key
rpoplpush key1 key 2將最後邊的值取出後並存入另一管道的左側
lrange key 0 3 取的該value中1~4的字元(list)
lindex key index 通過索引取出元素
LLEN key 獲取list長度
LINSERT key BEFORE value svalue //在value的右邊插入值,由左至右開始
LINSERT key AFTER value svalue //在value的左邊插入值,由左至右開始
Lrem lkey 0 value 刪除符合value值的元素
Lrem lkey 2 value 刪除符合value值的元素2個(由左置右)
Lrem lkey 3 value 刪除符合value值的元素3個(由右置左)
##set 單鍵多值(值不重複)
sadd key v1 v2 將原宿加入set中
smembers key 顯示所有key
smembers key value 顯示是否有該value值,是則返回1否則返回0
sinter key1 key2 返回兩set的交集
sunion key1 key2 返回兩set的並集
sdiff key1 key2 返回兩set的差集(key1-key2)
##Hash 單鍵多(屬性+值) 2³² - 1
hset key field value
hget key field
hgetall key
hmset key field1 value1 field2 value2
hexists key field 檢查是否存在(返回1)
hvals key 列出該hash所有的field
hkeys key 列出該hash所有的value
hincrby key field 增加值 將hash之field的value增加值(值必須為空或數值才行)
hsetnx key field value 將hash加入 field-value(在該屬性-值不存在情況下)
##zset 單鍵多(排序+值)
zadd key score1 value1 score2 value2
zrange key 0 2 返回次序1~3所有值
zrange key 0 -1 withscores 返回所有值語分數
zrangebyscore key -inf +inf WITHSCORES 顯是所有值
zrangebyscore key min max [WITHSCORES] [LIMIT offset count]
返回該值之 min<score<=max之間的值
zrevrangebyscore key min max [WITHSCORES] [LIMIT offset count]
```
## MongoDB 安裝/操作
https://www.runoob.com/mongodb/mongodb-osx-install.html
#### ==db 操作==:
```javascript
db.createCollection(db名稱, db設定參數) //創建
db.dropDatabase() //刪除目前使用的db
use db名稱
db //顯示現在使用db
show dbs //顯示所有db以及所佔用空間
show collection //顯示創建db
```
|db設定參數|值類型|預設值|說明|
|-|-|-|-|
|capped|bool|false|true時則創建固定大小的集合,超過數量時則自動覆蓋最早的文檔。|
|size|bool|無|固定集合指定一個最大字節數|
|max|bool|無|固定集合中包含文檔的最大數量|
#### ==db 操作==:
```javascript
//假設以存在表user
db.test.renameCollection(新名稱) //更名db
db.test.drop() //刪除db
db.test.count() //計算元素量
```
#### ==新增資料 insert==:
```javascript
//db.db名稱.insert(資料文檔)
//db.db名稱.insertOne(資料文檔,insert參數);
//db.db名稱.insertMany(資料文檔,insert參數);
db.ColName.insert({"title": "MongoDB 教程",
"description": "MongoDB 是一个 Nosql 数据库",
"tags": ["mongodb", "database", "NoSQL"],
"likes": 100
});
db.ColName.insertOne(
<document>,
{
writeConcern: <document>
}
);
db.ColName.insertMany(
[ {<document 1> }, <document 2>, ... ],
{
writeConcern: <document>,
ordered: <boolean>
}
);
```
|insert參數|值類型|預設值|說明|
|-|-|-|-|
|writeConcern|int|1|https://docs.mongodb.com/manual/reference/write-concern/|
|ordered|bool|false|是否案順序寫入,依順序寫入時預錯則拋出異常並中斷後續insert|
#### ==查詢資料 find==:
```javascript
//db.db名稱.find(查詢文檔,顯示文檔);
//db.db名稱.find(查詢文檔,顯示文檔).pretty(); //格式化顯示查詢結果
//↓查詢KeyTest值為valueTest,並顯示keyTest全部之值
db.ColName.find({"keyTest":"valueTest"});
//↓查詢keyTest值為valueTest,只顯示keyTest1之值(不顯示_id)
db.ColName.find({"keyTest":"valueTest"},{"keyTest1":true,"_id":false});
//↓查詢keyTest1值為valueTest1 AND keyTest2值為valueTest2
db.ColName.find({"keyTest1":"valueTest1", "keyTest2":"valueTest2"});
//↓查詢keyTest1值為valueTest1 AND keyTest2值為valueTest2
db.ColName.find({$or:[{"keyTest1":"valueTest1", "keyTest2":"valueTest2"}]});
db.ColName.find(
{
"keyTest": "valueTest",
$or: [{"keyTest1": "valueTest1"},{"keyTest2": "valueTest2"}]
}
); // (keyTest==valueTest) AND (keyTest1==valueTest1 OR keyTest2==valueTest2)
```
|*|查詢條件Condition**|格式說明**************************|範例|
|-|-|-|-|
|`=`|<key>等於<value>|{<key>:<value>}|`db.col.find({"Q":"V"})`|
|`!=`|<key>不等<value>|{<key>:{$ne:<value>}}|`db.col.find({"ExQ":{$ne:50}})`|
|`<`|<key>小於<value>|{<key>:{$le:<value>}}|`db.col.find({"ExQ":{$lt:50}})`|
|`<=`|<key>小於等<value>|{<key>:{$lte:<value>}}|`db.col.find({"ExQ":{$lte:50}})`|
|`>`|<key>大於<value>|{<key>:{$gt:<value>}}|`db.col.find({"ExQ":{$gt:50}})`|
|`>=`|<key>大於等<value>|{<key>:{$gte:<value>}}|`db.col.find({"ExQ":{$gte:50}})`|
|`包含`|<key>包含<value>|{<key>:/<value>/}|`db.col.find({"ExQ":/文字/})`|
|`開頭`|<key>開頭<value>|{<key>:/^<value>/}|`db.col.find({"ExQ":/^文字/})`|
|`結尾`|<key>結尾<value>|{<key>:/<value>$/}|`db.col.find({"ExQ":/文字$/})`|
|`存在`|<key>存在<value>|{<key>:{$exists:<value>}}|`db.col.find({"ExQ":{$exists:"文字"}})`|
|`存於`|<key>存在於<value>|{<key>:{$in:[<value>]}}|`db.col.find({"ExQ":{$in:["文字1","文字2"]})`|
```javascript
//db.db名稱.find(查詢文檔,顯示文檔).sort(排序文檔) //將查詢結果作排序
//db.db名稱.find(查詢文檔,顯示文檔).limit(正整數) //將查詢結果依據排序限制顯示數量
//db.db名稱.find(查詢文檔,顯示文檔).skip(正整數) //將查詢結果依據排序跳過前面數量
//↓相當於keyTest1=valueTest1當中,找出排名keyTest1最小的一位
db.ColName.find({"keyTest1":"valueTest1"}).sort({"keyTest1":-1}).limit(1);
//↓相當於keyTest1=valueTest1當中,找出排名keyTest1最大第4名~第10名
db.ColName.find({"keyTest1":"valueTest1"}).sort({"keyTest1":1}).skip(3).limit(7);
```
#### ==更新資料 update==:
```javascript
//db.db名稱.update(查詢文檔,更新文檔,update參數) //更新文檔將會把整個文件資料覆蓋
//db.db名稱.update(查詢文檔,{$set:資料文檔},update參數) //set為更新或插入部分資料於文檔內
//db.db名稱.update(查詢文檔,{$unset:資料文檔},update參數) //unset為部分資料刪除於文檔內
//db.db名稱.update(查詢文檔,{$rename:更名文檔},update參數) //rename為將文檔內的key進行更名
//db.db名稱.update(查詢文檔,{$inc:資料文檔},update參數) //inc為將文檔資料內數值相加
//db.db名稱.update(查詢文檔,{$mul:資料文檔},update參數) //mul為將文檔資料內數值相乘
//db.db名稱.update(查詢文檔,{$push:資料文檔},update參數) //push為將新元素添加到文檔資料
//db.db名稱.update(查詢文檔,{$pull:資料文檔},update參數) //pull為將元素由文檔資料中刪除
db.ColName.update(
<query>, //查詢文檔
<update>, //更新文檔
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>
}
)
```
|update參數|值類型|預設值|說明|
|-|-|-|-|
|upsert|bool|false|不存在時是否進行insert|
|multi|bool|false|是否更新全部<query>資料|
|writeConcern|int|1|https://docs.mongodb.com/manual/reference/write-concern/|
#### ==刪除資料 update==:
```javascript
//db.db名稱.remove(查詢文檔,刪除設定值)
//db.db名稱.deleteOne({"keyTest":"valueTest"}) //刪除一個keyTest=valueTest的資料
//db.db名稱.deleteMany({"keyTest":"valueTest"}) //刪除一個keyTest=valueTest的資料
db.collection.remove(
<query>,
{
justOne: <boolean>,
writeConcern: <document>
}
)
```
#### ==創建索引==:
```javascript
//db.db名稱.createIndex(查詢文檔, 索引設定值) //創建索引
//db.db名稱.getIndexes() // 查詢索引設置
//db.db名稱.dropIndex(查詢文檔) //刪除索引
```
|索引設定參數|值類型|預設值|說明|
|-|-|-|-|
|background|bool|false|建索引過程會阻塞其它數據庫操作,background可指定以後台方式創建索引|
|unique|bool|false|建立的索引是否唯一|
|name|string||索引的名稱。如果未指定,MongoDB的通過連線索引的欄位名和排序順序生成一個索引名稱。|
|sparse|bool|false|對文件中不存在的欄位資料不啟用索引;|
|expireAfterSeconds|integer||指定一個以秒為單位的數值,完成 TTL設定|
|v|index||索引的版本號|
|weights|document||索引權重值,數值在 1 到 99,999 之間,表示該索引相對於其他索引欄位的得分權重。|
|default_language|string||對於文字索引,該引數決定了停用詞及詞幹和詞器的規則的列表。 預設為英語
|language_override|string||對於文字索引,該引數指定了包含在文件中的欄位名,語言覆蓋預設的language,預設值為 language.
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet