# 電算社資訊營
# 第二天
# 網路爬蟲入門
---
## 講師:昱山
---
## 目錄
* [什麼是爬蟲](#3)
* [常用函式庫](#)
* requests
* BeautifulSoup
* Selenium
* [抓衛福部公告 - 實作](#)
---
# 網頁原始碼
----
## HTML
#### 功能:定義網頁的內容與結構
```html
<!DOCTYPE html>
<html>
<head>
<title>網頁</title>
</head>
<body>
<h1>Hello</h1>
<p>介紹</p>
<a href="https://example.com">點我前往其他網站</a>
</body>
</html>
```
----
HTML是標記語言
不是程式語言!
<img
src="https://i.programmerhumor.io/2024/11/programmerhumor-io-frontend-memes-python-memes-0989d4ec8e79f7e.jpg"
alt="The head and torso of a dinosaur skeleton;
it has a large head with long sharp teeth"
width="400"
height="341" />
###### 來源:[ProgrammerHumor](https://programmerhumor.io/webdev-memes/when-youre-not-really-a-programming-language-but-still-vibin-with-the-big-boys-ekuo)
----
## CSS
#### 功能:美化HTML
```css
h1 {
color: blue;
font-size: 36px;
}
p {
color: gray;
}
```
##### 也不是程式語言
----
## JavaScript
#### 功能:讓網頁具有互動性
##### 是程式語言
```javascript
<!DOCTYPE html>
<html>
<head>
<title>點我改文字</title>
<script>
function changeText() {
document.getElementById("text").innerHTML = "你點了按鈕!";
}
</script>
</head>
<body>
<p id="text">原始文字</p>
<button onclick="changeText()">點我</button>
</body>
</html>
```
##### 注意:Java與JavaScript兩者毫無關係
---
# 什麼是爬蟲?🤔
---
## 網路爬蟲是什麼?
- 全名:**Web Crawler**
- 用來**自動抓取網站上的資訊**,就像機器人幫你一頁頁看網頁、抄資料
- 常見用途:資料分析、股價蒐集、票價查詢、自動化報表...
> 維基百科的定義:爬蟲是一種用來自動瀏覽全球資訊網的機器人程式
---
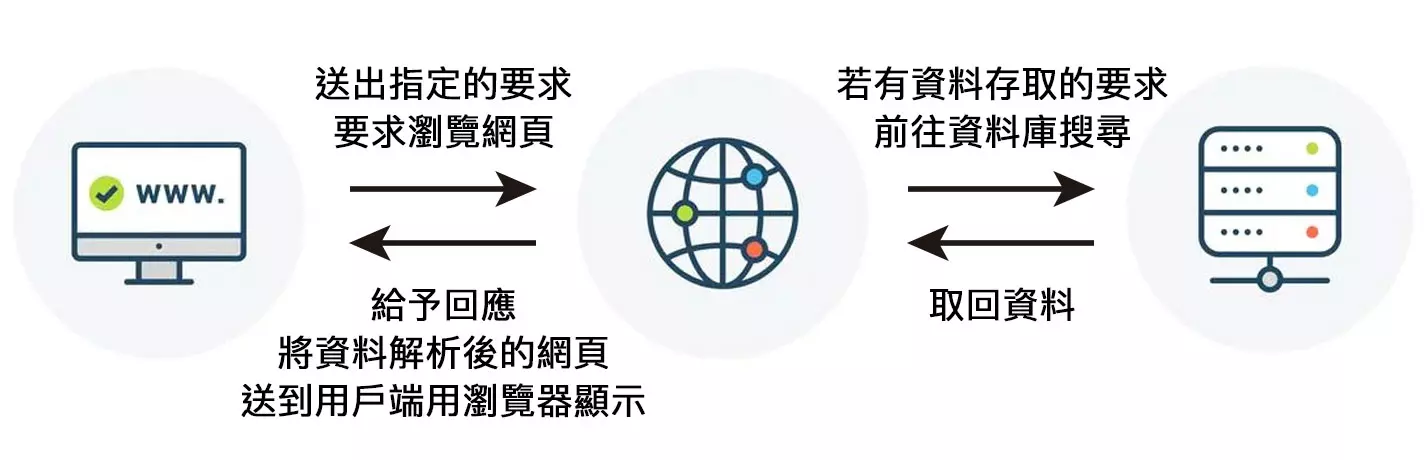
##### 來源:[STEAM教育學習網](https://steam.oxxostudio.tw/category/python/spider/about-spider.html)
---
## robots.txt
```
# version: c6c2d0415f0c1d97565a01952c7b2146e2abe17f
# HTTPS www.bbc.com
User-agent: *
Sitemap: https://www.bbc.com/sitemaps/https-index-com-archive.xml
Sitemap: https://www.bbc.com/sitemaps/https-index-com-news.xml
Sitemap: https://www.bbc.com/sitemaps/https-index-com-archive_video.xml
Sitemap: https://www.bbc.com/sitemaps/https-index-com-video.xml
Sitemap: https://www.bbc.com/sitemaps/sitemap-com-ws-topics.xml
Sitemap: https://www.bbc.com/sport/sitemap.xml
Sitemap: https://www.bbc.com/sitemaps/sitemap-com-ws-topics.xml
Sitemap: https://www.bbc.com/afrique/sitemap.xml
Sitemap: https://www.bbc.com/arabic/sitemap.xml
Sitemap: https://www.bbc.com/bengali/sitemap.xml
Sitemap: https://www.bbc.com/burmese/sitemap.xml
Sitemap: https://www.bbc.com/gahuza/sitemap.xml
Sitemap: https://www.bbc.com/hausa/sitemap.xml
Sitemap: https://www.bbc.com/hindi/sitemap.xml
Sitemap: https://www.bbc.com/indonesia/sitemap.xml
Sitemap: https://www.bbc.com/mundo/sitemap.xml
Sitemap: https://www.bbc.com/pashto/sitemap.xml
Sitemap: https://www.bbc.com/persian/sitemap.xml
Sitemap: https://www.bbc.com/portuguese/sitemap.xml
Sitemap: https://www.bbc.com/russian/sitemap.xml
Sitemap: https://www.bbc.com/swahili/sitemap.xml
Sitemap: https://www.bbc.com/tajik/sitemap.xml
Sitemap: https://www.bbc.com/turkce/sitemap.xml
Sitemap: https://www.bbc.com/ukchina/simp/sitemap.xml
Sitemap: https://www.bbc.com/ukrainian/sitemap.xml
Sitemap: https://www.bbc.com/urdu/sitemap.xml
Sitemap: https://www.bbc.com/uzbek/sitemap.xml
Sitemap: https://www.bbc.com/vietnamese/sitemap.xml
Sitemap: https://www.bbc.com/zhongwen/simp/sitemap.xml
Sitemap: https://www.bbc.com/zhongwen/trad/sitemap.xml
Sitemap: https://www.bbc.com/bbcx/index_sitemap.xml
Sitemap: https://www.bbc.com/bbcx/audio_archive_sitemap.xml
Disallow: /asset/
Disallow: /bitesize/search$
Disallow: /bitesize/search/
Disallow: /bitesize/search?
Disallow: /cbbc/search/
Disallow: /cbbc/search$
Disallow: /cbbc/search?
Disallow: /cbeebies/search/
Disallow: /cbeebies/search$
Disallow: /cbeebies/search?
Disallow: /chwilio/
Disallow: /chwilio$
Disallow: /chwilio?
Disallow: /education/blocks$
Disallow: /education/blocks/
Disallow: /newsround
Disallow: /search/
Disallow: /search$
Disallow: /search?
Disallow: /food/favourites
Disallow: /food/search*?*
Disallow: /food/recipes/search*?*
Disallow: /education/my$
Disallow: /education/my/
Disallow: /bitesize/my$
Disallow: /bitesize/my/
Disallow: /food/recipes/*/shopping-list
Disallow: /food/menus/*/shopping-list
Disallow: /news/0
Disallow: /sport/alpha/
Disallow: /ugc$
Disallow: /ugc/
Disallow: /ugcsupport$
Disallow: /ugcsupport/
Disallow: /userinfo/
Disallow: /userinfo
Disallow: /u5llnop$
Disallow: /u5llnop/
Disallow: /sounds/search$
Disallow: /sounds/search/
Disallow: /sounds/search?
Disallow: /ws/includes
Disallow: /radio/imda
Disallow: /storyworks/preview/*
Disallow: /rd/search$
Disallow: /rd/search/
Disallow: /rd/search?
User-agent: Amazonbot
Disallow: /
User-agent: magpie-crawler
Disallow: /
User-agent: CCBot
Disallow: /
User-Agent: omgili
Disallow: /
User-Agent: omgilibot
Disallow: /
User-agent: Claude-Web
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: cohere-ai
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: PetalBot
Disallow: /
User-agent: Scrapy
Disallow: /
User-agent: Applebot-Extended
Disallow: /
User-agent: GPTBot
Disallow: /
User-agent: ChatGPT-User
Disallow: /
User-agent: Google-Extended
Disallow: /
User-Agent: PerplexityBot
Disallow: /
User-agent: Perplexity-User
Disallow: /
User-agent: Google-CloudVertexBot
Disallow: /
User-agent: meta-externalagent
Disallow: /
User-agent: OAI-SearchBot
Disallow: /
User-agent: YandexAdditional
Disallow: /
User-agent: YandexAdditionalBot
Disallow: /
User-agent: TurnitinBot
Disallow: /
```
---
## 常用的三大工具
| 工具 | 用途 |
|------|------|
| `requests` | 抓取網站原始碼(HTML) |
| `BeautifulSoup` | 分析並提取網頁內容 |
| `Selenium` | 模擬人類點擊、滾動等行為,適合 JavaScript 頁面 |
---
# requests 套件
---
## requests 是什麼?
- 幫我們**發送請求、取得網頁內容**
- 用法簡單,適合靜態網頁(不需要滑動、按鈕)
### 安裝方式(Colab 已內建)
```python
import requests
````
---
## requests 常用屬性
```python
r = requests.get("https://example.com")
```
| 屬性 | 說明 |
| --------------- | --------------------------------- |
| `r.url` | 回傳實際請求的網址 |
| `r.text` | 文字內容(str) |
| `r.content` | 原始位元資料(bytes) |
| `r.status_code` | 狀態碼,200=成功 |
| `r.json()` | 將回傳結果轉成 JSON 字典(前提是該網站真的有提供 JSON) |
---
## 簡單實作
```python
import requests
r = requests.get("https://example.com")
print(r.text)
```
---
# BeautifulSoup 套件
---
## BeautifulSoup 是什麼?
* 幫我們**解析 HTML 結構**
* 找出 `<a>`、`<li>`、`<div>` 中的文字
---
## 用法
```python
from bs4 import BeautifulSoup
html = "<h1>Hello</h1>"
soup = BeautifulSoup(html, "html.parser")
print(soup.h1.text)
```
---
## BBC中文新聞
```python=
import requests
from bs4 import BeautifulSoup
sitemap_url = "https://www.bbc.com/zhongwen/trad/sitemap.xml" # 取得 BBC 的 sitemap.xml
sitemap_response = requests.get(sitemap_url)
sitemap_soup = BeautifulSoup(sitemap_response.content, "xml")
urls = [loc.text for loc in sitemap_soup.find_all("loc")] # 找 loc 標籤
print(f"總共找到 {len(urls)} 筆網址,準備抓取每頁的標題...\n")
for url in urls:
try:
page = requests.get(url)
soup = BeautifulSoup(page.content, "html.parser")
title = soup.find("h1") # 文章標題
if title:
print(title.text.strip())
else:
print("[找不到標題]")
print(f"{url}\n")
except Exception as e:
print(f"錯誤:{e}(網址:{url})\n")
```
---
# Selenium 套件
---
## Selenium 是什麼?
* 模擬**滑鼠點擊、鍵盤輸入、載入 JavaScript** 等行為
* 適合用來抓 **互動式網站**,例如需要按下「載入更多」
---
## 需搭配 ChromeDriver
* 下載對應版本的 ChromeDriver
(與瀏覽器版本一致)
* 在 Colab 中需要使用下列指令安裝:
```bash
!wget -q -O chrome.deb https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb
!dpkg -i chrome.deb
!apt-get -f install -y
!pip install selenium > /dev/null
!wget -q https://storage.googleapis.com/chrome-for-testing-public/xxx.x.xxxx.xx/linux64/chromedriver-linux64.zip #xxx.x.xxxx.xx要改成chrome版本
!unzip -o chromedriver-linux64.zip
!mv -f chromedriver-linux64/chromedriver /usr/bin/chromedriver
!chmod +x /usr/bin/chromedriver
```
---
## Selenium 初始化程式碼
```python
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
import time
options = Options()
options.binary_location = "/usr/bin/google-chrome"
options.add_argument("--headless")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
service = Service("/usr/bin/chromedriver")
driver = webdriver.Chrome(service=service, options=options)
```
---
### 基本語法
```python
element = driver.find_element(By.定位方式, "條件")
```
```python
elements = driver.find_elements(By.定位方式, "條件")
```
※無 `s` →找第一個元素→元素(`WebElement`)
※有 `s` →找尋多個元素→串列( `list` )
---

---
# 抓取衛福部公告
---
## 網址:
[https://www.mohw.gov.tw/lp-7186-1.html](https://www.mohw.gov.tw/lp-7186-1.html)
---
## 實作流程:
```python
driver.get("https://www.mohw.gov.tw/lp-7186-1.html")
time.sleep(3) # 等待頁面載入
rows = driver.find_elements(By.TAG_NAME, 'li')
print("公告訊息:\n")
for row in rows:
try:
link = row.find_element(By.TAG_NAME, 'a')
title = link.text.strip()
href = link.get_attribute('href')
if title:
print(f"{title}\n{href}\n")
except:
continue
driver.quit()
```
---
{"title":"電算社資訊營第二天","description":"什麼是爬蟲","contributors":"[{\"id\":\"b831f9fa-52bb-4a09-bfbb-148e4fdadd0f\",\"add\":10136,\"del\":659,\"latestUpdatedAt\":1754300969044}]"}