---
tags: Paper
---
# ViT & T2T-ViT & HIPT Comparison
<!-- ## Terms
WSI: Whole-Slide Imaging(全載玻片成像,大小可到150,000×150,000 pixels)
HIPT: Hierarchical Image Pyramid Transformer
MIL: Multiple Instance Learning
-->
## ViT

<br>

圖片切塊(d~1~ x d~2~ x d~3~)
$\rightarrow$ 向量化(d~1~d~2~d~3~ x 1 for each)
$\rightarrow$ FC線性轉換 with trainable paras,並加上位置矩陣
$\rightarrow$ 把以上n個向量和CLS向量一起輸入transformer,輸出n+1個向量
$\rightarrow$ 取特徵向量放進softmax,得到最後結果

---
## T2T-ViT


---
## Hierarchical Image Pyramid Transformer(HIPT)
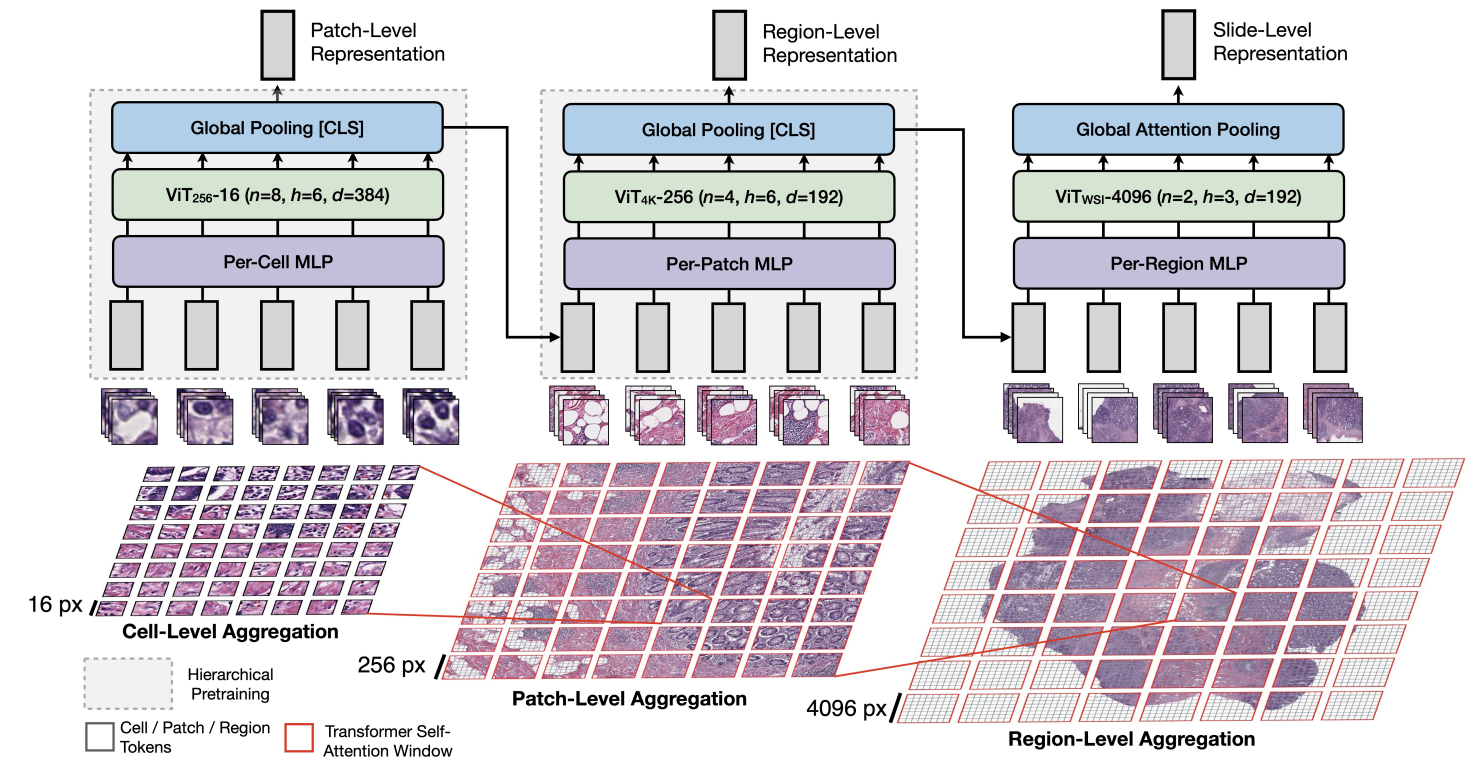
Can be witten as:

:::spoiler
**Notation**
* x~R~: image with resolution R x R
* ViT~A~-l: ViT working on a A x A image resolution with token shape [l x l]
* {x~l~^(i)^}~i=1~^M^ ∈ R^M×dl^: extracted tokens sequence within x
* sequence length = M
* token size = [l x l]
* embedding dimension = d
:::
<br>
* Recursively subdivide the whole slide into non-overlapping tokens
* 3-level aggregation
* Hierarchical pre-training (based on [student teacher knowlege distillation](https://chtseng.wordpress.com/2020/05/12/%E7%9F%A5%E8%AD%98%E8%92%B8%E9%A4%BE-knowledgedistillation/))
1. pre-train patch-level ViT first
2. then pre-train region-level ViT
<!-- <br> -->
Based on 兩個WSI圖片的特性:
1. Have a fixed scale
2. There exists a hierarchical structure of visual tokens at varying image resolutions
<!--
Like hierarchical attention networks in long document modeling, in which **word embeddings** within sentences are aggregated to form **sentence-level embeddings** and subsequently aggregated into **document-level embeddings**. -->
[HIPT source code](https://github.com/mahmoodlab/HIPT)