# 2022: Компьютерные системы и сети. Лекция 9.
[TOC]
# ACID vs BASE, CAP и PACELC теоремы, теорема FLP, алгоритм двухфазного подтверждения изменения состояния, CALM теорема, алгоритм RAFT
# ACID vs BASE


# [Теорема CAP]()
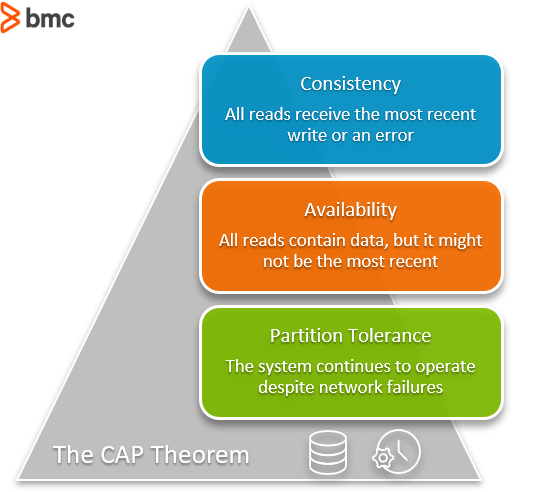
## [Теорема PACELC](https://en.wikipedia.org/wiki/PACELC_theorem)
## [Простой алгоритм консенсуса в распределенной системе](https://neerc.ifmo.ru/wiki/index.php?title=%D0%9A%D0%BE%D0%BD%D1%81%D0%B5%D0%BD%D1%81%D1%83%D1%81_%D0%B2_%D1%80%D0%B0%D1%81%D0%BF%D1%80%D0%B5%D0%B4%D0%B5%D0%BB%D1%91%D0%BD%D0%BD%D0%BE%D0%B9_%D1%81%D0%B8%D1%81%D1%82%D0%B5%D0%BC%D0%B5#.D0.A0.D0.B5.D1.88.D0.B5.D0.BD.D0.B8.D0.B5_.D0.BF.D1.80.D0.B8_.D0.BE.D1.82.D1.81.D1.83.D1.82.D1.81.D1.82.D0.B2.D0.B8.D0.B8_.D0.BE.D1.82.D0.BA.D0.B0.D0.B7.D0.BE.D0.B2)
## [Алгоритм двухфазного подтверждения изменения состояния](https://en.wikipedia.org/wiki/Two-phase_commit_protocol)

Двухфазный коммит. Это способ обработки транзакций, при котором сначала все узлы выполняют транзакцию, а потом фиксируют (коммитят) ее. Для координации этого процесса один из узлов назначается главным — координатором. Затем фиксация коммита выполняется в два этапа:
Координатор отправляет транзакцию на каждый узел, а затем ждет подтверждения, что выполнение транзакции возможно.
Если все узлы выполнили транзакцию, координатор отправляет им команду зафиксировать изменения, то есть сделать их постоянными.
Если на любом этапе один из узлов не может выполнить команду (например, обнаружилась несогласованность данных, или узел вышел из строя), то координатор отменяет всю транзакцию.
С точки зрения распределенных систем, в таком подходе есть две большие проблемы:
* Очень много «общения» между координатором и узлами. Распределенные системы, как правило, находятся в нескольких ЦОД, которые расположены в разных регионах или странах. Поэтому, чем больше узлы «общаются» между собой, тем больше сетевые задержки.
* Блокировка состояний. Перед тем как зафиксировать глобальное изменение состояния, узлы блокируют изменения своих состояний до тех пор, пока координатор не подтвердит или не отменит фиксацию. В это время другие запросы на изменения состояния, ждут в очереди. Это тоже создает дополнительные задержки.
## [Теорема Фишера-Линча-Патерсона (FLP)](https://neerc.ifmo.ru/wiki/index.php?title=%D0%A2%D0%B5%D0%BE%D1%80%D0%B5%D0%BC%D0%B0_%D0%A4%D0%B8%D1%88%D0%B5%D1%80%D0%B0-%D0%9B%D0%B8%D0%BD%D1%87%D0%B0-%D0%9F%D0%B0%D1%82%D0%B5%D1%80%D1%81%D0%BE%D0%BD%D0%B0_(FLP))
**Теорема Фишера, Линча и Патерсона** (FLP, 1985 год):
Невозможно достичь даже необоснованного консенсуса N>2 процессами даже на одном бите при следующих обязательных условиях:
* Алгоритм должен завершиться за конечное время.
* Один из узлов может отказать.
* Система асинхронна.
* Алгоритм должен быть детерминирован.
Если разрешаем незавершаемость в случае отказов, есть [Paxos](https://en.wikipedia.org/wiki/Paxos_(computer_science)) и [Raft](https://web.archive.org/web/20140908092102/https://ramcloud.stanford.edu/wiki/download/attachments/11370504/raft.pdf). Если отказов нет, есть [простой алгоритм](https://neerc.ifmo.ru/wiki/index.php?title=%D0%9A%D0%BE%D0%BD%D1%81%D0%B5%D0%BD%D1%81%D1%83%D1%81_%D0%B2_%D1%80%D0%B0%D1%81%D0%BF%D1%80%D0%B5%D0%B4%D0%B5%D0%BB%D1%91%D0%BD%D0%BD%D0%BE%D0%B9_%D1%81%D0%B8%D1%81%D1%82%D0%B5%D0%BC%D0%B5#.D0.A0.D0.B5.D1.88.D0.B5.D0.BD.D0.B8.D0.B5_.D0.BF.D1.80.D0.B8_.D0.BE.D1.82.D1.81.D1.83.D1.82.D1.81.D1.82.D0.B2.D0.B8.D0.B8_.D0.BE.D1.82.D0.BA.D0.B0.D0.B7.D0.BE.D0.B2). Если система синхронна, то есть [консенсус в синхронных системах](https://neerc.ifmo.ru/wiki/index.php?title=%D0%9A%D0%BE%D0%BD%D1%81%D0%B5%D0%BD%D1%81%D1%83%D1%81_%D0%B2_%D1%81%D0%B8%D0%BD%D1%85%D1%80%D0%BE%D0%BD%D0%BD%D1%8B%D1%85_%D1%81%D0%B8%D1%81%D1%82%D0%B5%D0%BC%D0%B0%D1%85). Если разрешаем недетерминизм, то есть [алгоритм Бен-Ора](https://neerc.ifmo.ru/wiki/index.php?title=%D0%90%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC_%D0%91%D0%B5%D0%BD-%D0%9E%D1%80%D0%B0).
# [О CALM теореме.](https://cacm.acm.org/magazines/2020/9/246941-keeping-calm/fulltext)
## Спокойствие, только спокойствие. Согласование распределенных систем иногда может быть проще.
Согласованная работа и управление распределенными системами - сложная задача. Множество, вообще говоря, ненадежных узлов системы работают параллельно, отправляя друг другу сообщения по сетевым каналам с произвольными задержками.
Как гарантировать согласованную работу таких систем, несмотря на этот управленческий туман?
### Теорема
*Теорема*. Согласованность как логичеческая монотонность (Consistency As Logical Monotonicity -CALM). Программа (функция) может иметь *согласованную некоординирующую распределенную реализацию*, если и только если эта программа **логически монотонная**.
*Определение*. Программа (функция) P **логически монотонна**, если для любых допустимых входных данных S и T, таких, что S ⊆ T , мы имеем P(S) ⊆ P(T ).
### Монотонность
Неформально, блок кода является логически монотонным, если он удовлетворяет простому свойству: добавление входных данных никогда не меняет уже полученных результатов и только может увеличить полученные результаты. Немонотонный код может откатить ранее полученные результаты при получении каких-то критических данных.
### Согласованность без координации
Монотонные программы не изменяют своих старых заключений при поступлении новой информации и могут выполняться распределенно без необходимости координации, за исключением финального объединения результатов. Немонотонные программы могут изменить истинность своих старых заключений при поступлении новой информации. При их распределенной реализации они не могут продолжать дальнейшую работу, пока не произведен обмен информации между узлами и не получено согласованное состояние всей системы.
Кроме того, вследствие того, что они могут на ходу изменять свое "мнение" о мире и своем состоянии, немонотонные программы чувствительны к порядку поступления данных: порядок поступления информации определяет порядок переключения состояния, что в результате и определяет их финальное состояние. А вот монотонные программы просто накапливают свои состояния в виде множества результатов ([например в виде CRDTs](https://www.inkandswitch.com/local-first/#crdts-as-a-foundational-technology)).
# [Алгоритм распределённого консенсуса Raft](https://en.wikipedia.org/wiki/Raft_(algorithm))
Raft — алгоритм для решения задач консенсуса в сети ненадёжных вычислений. Raft разрабатывался с учётом недостатков [семейства алгоритмов Паксос](https://en.wikipedia.org/wiki/Paxos_(computer_science)). При выборе ключевых идей, предпочтение отдавалось более простым и практичным решениям. Тем не менее, несмотря на относительную простоту, Raft обеспечивает безопасную и эффективную реализацию машины состояний поверх кластерной вычислительной системы.
[http://thesecretlivesofdata.com/raft/]
<iframe src="https://raft.github.io/raftscope/index.html" width=1250 height=550> </iframe>
Существует множество реализаций Raft с открытым исходным кодом на разных языках программирования. Например, [Raft.js: Raft Consensus Algorithm in JavaScript](https://github.com/kanaka/raft.js/). Пример [визуализации RAFT](https://www.mattritter.me/?p=107)
## Особенности алгоритма Raft
1) **Чёткое разделение фаз**. Raft предлагает декомпозицию задачи управления кластером на несколько слабо связанных подзадач, основные из которых - выбор лидера (голосование) и репликация протоколов. Каждая из этих задач допускает более детальное разделение. Это упрощает понимание алгоритма и снижает риск ошибок при его реализации.
2) **Явно выделенный лидер**. Raft предполагает, что на кластере всегда существует явно выделенный лидер. Только этот лидер отправляет новые записи на другие узлы кластера. Таким образом, остальные узлы следуют за лидером и не взаимодействуют между собой (за исключением фазы голосования). Если внешний клиент подключается к кластеру через обычный узел, то все его запросы перенаправляются лидеру и только оттуда приходят на узлы.
3) **Протоколы работы не могут содержать пропусков**. То есть записи добавляются строго последовательно без пропусков. Это накладывает некоторые ограничения, по сравнению с Паксос, но позволяет очень сильно упростить алгоритм. Кроме того, специфика прикладных задач чаще всего не позволяет корректно работать с протоколами, содержащими пропуски.
4) **Изменение размера кластера**. Raft позволяет легко менять конфигурацию кластера, не останавливая работы: добавлять или удалять узлы.
> Уважаемые коллеги - ответьте, пожалуйста (с именем и фамилией), на вопросы -
Насколько полезен или вреден этот протокол для реализации многопользовательских игр?
> 1. Пошаговых многопользовательских игр?
> 2. многопользовательских динамических игр ?
## Ссылки для самостоятельного ознакомления:
1. <a href="https://web.archive.org/web/20140908092102/https://ramcloud.stanford.edu/wiki/download/attachments/11370504/raft.pdf"> Оригинальное описание протокола</a>
2. <a href="https://habr.com/ru/company/dododev/blog/469999/">Как сервера договариваются друг с другом: алгоритм распределённого консенсуса Raft</a>
3. <a href="https://en.wikipedia.org/wiki/Raft_(algorithm)">Raft (algorithm)</a>
4. <a href="https://ru.wikipedia.org/wiki/%D0%90%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC_Raft">Алгоритм Raft</a>
5. <a href="https://raft.github.io/">The Raft Consensus Algorithm Visualisation</a>
6. <a href="http://thesecretlivesofdata.com/raft/">The Secret Lives of Data</a>
# Ресурсы
1. [Обеспечение принципов ACID для высоконагруженных распределенных систем](https://habr.com/ru/post/577300/)
2. [The CAP Theorem With Apache Cassandra® and MongoDB](https://www.instaclustr.com/blog/cassandra-vs-mongodb/)
3. [CAP Twelve Years Later: How the "Rules" Have Changed](https://www.infoq.com/articles/cap-twelve-years-later-how-the-rules-have-changed/)
4. [Теорема Фишера-Линча-Патерсона (FLP)](https://neerc.ifmo.ru/wiki/index.php?title=%D0%A2%D0%B5%D0%BE%D1%80%D0%B5%D0%BC%D0%B0_%D0%A4%D0%B8%D1%88%D0%B5%D1%80%D0%B0-%D0%9B%D0%B8%D0%BD%D1%87%D0%B0-%D0%9F%D0%B0%D1%82%D0%B5%D1%80%D1%81%D0%BE%D0%BD%D0%B0_(FLP))
5. [Terminating Reliable Broadcast](https://en.wikipedia.org/wiki/Terminating_Reliable_Broadcast)
6. [Three-phase_commit_protocol](https://en.wikipedia.org/wiki/Three-phase_commit_protocol)
7. [Understanding of consistency in distributed systems](https://medium.com/@mena.meseha/understanding-of-consistency-in-distributed-systems-27da174cc05a)
8. [Two_Generals_Problem](https://en.wikipedia.org/wiki/Two_Generals%27_Problem)
9. [Keeping CALM: When Distributed Consistency Is Easy](https://grapespace.net/bin/download/Architecture%20Design/Distributed%20System%20Architecture/Concepts/CALM/WebHome/Keeping%20CALM%20-%20When%20Distributed%20Consistency%20is%20Easy%201901.01930.pdf)
10. [CRDTs as a foundational technology](https://www.inkandswitch.com/local-first/#crdts-as-a-foundational-technology)
11. [CRDTs and the Quest for Distributed Consistency](https://youtu.be/B5NULPSiOGw)
12. [Building a collaborative text editor with WebRTC and CRDTs](https://youtu.be/hy0ePbpna5Y)
13. [John Mumm - A CRDT Primer: Defanging Order Theory](https://youtu.be/OOlnp2bZVRs)
14. [Beaker Browser. An experimental peer-to-peer Web browser.](https://beakerbrowser.com/)
15. [Agregore Browser. A minimal web browser for the distributed web](https://github.com/AgregoreWeb/agregore-browser)
16. [ipfs](https://ipfs.io/)
17. [hypercore-protocol](https://hypercore-protocol.org/)
18. https://youtu.be/SVk1uIQxOO8
19. https://en.wikipedia.org/wiki/Kademlia
20. https://docs.libp2p.io/concepts/publish-subscribe/
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet