# A short introduction to scientific computing
###### tags: `Kickstart`
###### *Work in progress by `enrico.glerean@aalto.fi`, `marijn.vanvliet@aalto.fi`, `richard.darst@aalto.fi`. Looking for contributors/co-authors, add your name if you contributed. All text and images under [CC-BY 4.0](https://creativecommons.org/licenses/by/4.0/). *
## What is scientific computing?
:::success
## *computing*
/kəmˈpjuːtɪŋ/
*noun*
the fact of using computers
>*"to work in computing"*
>*"to study computing"*
>*"computing power"*
:::

[Data science according to xkcd (source)](https://xkcd.com/1838/)
:::success
"**Scientific computing** is the collection of tools, techniques and theories required to solve on a computer the mathematical models of problems in science and engineering."
> *Gene H. Golub and James M. Ortega*
:::
## A common scientific computing flowchart
Often scientific computing is about:
1. getting some data (via data collection or simulation)
2. processing it
3. obtaining results (derivatives outputs like tables, figures, statistics)
4. visualize the results (and publish them!).

*Figure 1 - A common pipeline of scientific computing*
## How does *computing* happen?
### Hardware + Software + Data (*)
(*)...and network connectivity when things are not in the same place

*Figure 2 - Architecture of a computer (also called "computing node" or "server")*
:::info
### Glossary (from Wikipedia)
* **CPU**: Central processing unit (CPU), also just processor, is the electronic circuitry within a computer that executes instructions that make up a computer program. [[link]](https://en.wikipedia.org/wiki/Central_processing_unit)
* **GPU**: A graphics processing unit (GPU) is a specialized electronic circuit designed to rapidly manipulate and alter memory to accelerate the creation of images in a frame buffer intended for output to a display device. Their highly parallel structure makes them more efficient than general-purpose central processing units (CPUs) for algorithms that process large blocks of data in parallel. [[link]](https://en.wikipedia.org/wiki/Graphics_processing_unit)
* **RAM**: Random-access memory (RAM /ræm/) is a form of computer memory that can be read and changed in any order, typically used to store working data and machine code. [[link]](https://en.wikipedia.org/wiki/Random-access_memory)
* **SSD**: A solid-state drive (SSD) is a solid-state storage device that uses integrated circuit assemblies to store data persistently. [[link]](https://en.wikipedia.org/wiki/Solid-state_drive)
:::
## Understanding computing through the kichen metaphor
We have a great [video](https://www.youtube.com/watch?v=9siGLV8pZ5A&list=PLZLVmS9rf3nNDHRo1Baz_JVQWDI0mTYyB&index=3) and [slides](https://docs.google.com/presentation/d/16BTILZlUvEzCt6FfMsB9sSZm0PZHHXLBthE5QfoSrjo/edit) about a simple yet great metaphor that explains computers, HPC infrastructure, and what it means to run code (cook) with HPC rather than the local computer.
## What do I need to make *computing* happen?
In general you need a **system** (hardware) where you can run a **process** (software) and access the **data** to produce your results. A laptop might sometimes be enough, but when the data or the amount of computation increases, you need to access **hardware and software (and data) in remote locations**.
:::warning
### *How to know when I need to scale up to a bigger system?*
Understanding what you need to solve your computing problems is not trivial. Some questions you might ask yourself at some point in your life:
* **Do I need one or more CPUs to process my data?** *Caveat: not every problem can be parallelised.*
* **Do I need 1 computer with N CPUs or N computers with 1 CPU?** *Caveat: not all code is written to use multiple CPUs*
* **Do I need GPUs?** *Caveat: GPUs require special code/libraries*
* **Do I have tools/code that can be run on multiple CPUs and/or GPUs?** *Caveat: code does not automatically use all the resources you might have at hand*
* **Is the speed to access the data a bottleneck?** *Caveat: the faster the access to the data, the more localised your data is*
* **What level of security my data (and code) need to have?** *Caveat: sensitive data should not be taken outside remote storage locations*
Understanding your computational needs is not easy, in the examples of **strategies at Aalto** we show how different solutions can cover different needs.
:::
## How do I do scientific computing?
Get a computer where you can install and run code. You might want to start with something like [Python](https://www.python.org/downloads/) ([Anaconda](https://www.anaconda.com/products/individual), for a distribution of Python with many useful libraries), [R](https://www.r-project.org/) ([Rstudio](https://rstudio.com/products/rstudio/download/)), or [Julia](https://julialang.org/downloads/). [Project Jupyter](https://jupyter.org/) is also a good starting point to interact with code and its output by using **notebooks**, ...but notebooks do not scale well and in the end you will end up interacting with a **Command Line Interface** on a remote system like a **High Performance Computing cluster**.
---
## My computer is not enough for my computing needs, where can I also do scientific computing?
Sometimes your laptop/home computer might not be powerful enough, or you might not have the possibility to install the tools you need. There are many services that allows you to do scientific computing from remote (Note: You still need a computer to connect to these services, but they can also be used from mobile devices).
There are mainly three categories of remote computing
1. **Remote desktop connection** to a powerful dedicated machine (Interactive, GUI, CLI)
2. **Virtual machine running a kernel, interacting via Jupyter notebook** (Interactive, GUI, CLI)
3. **High Performance Cluster**: a login node from where you can *submit computing jobs*, which go in the queue until they are executed by one or more nodes in the cluster. (Non-interactive, CLI... but there are also GUI interfaces)
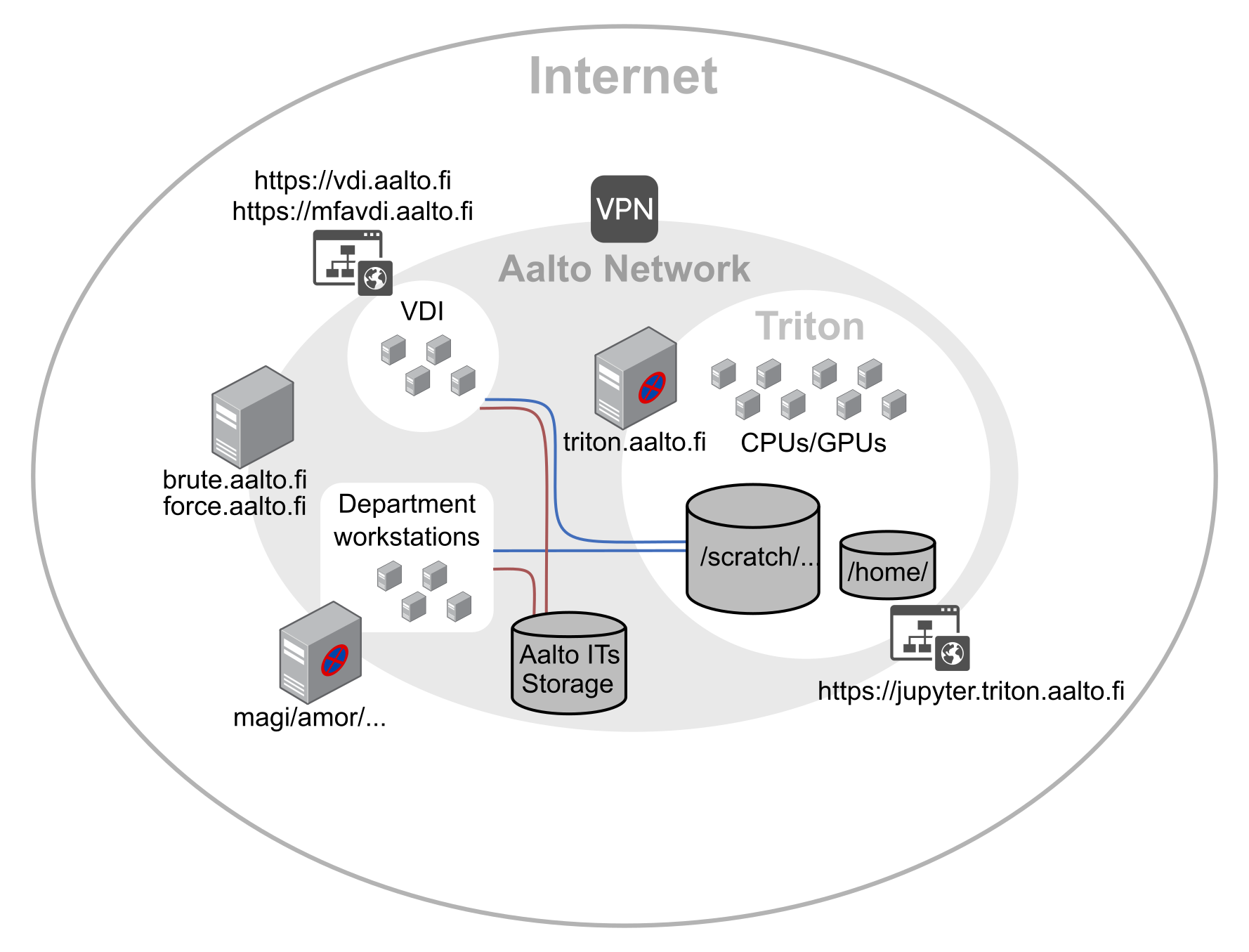
*A more generic non-Aalto alternative:*

*Figure 3 - summary of the three types of remote computing. Large storage systems can be local or remote and they are often slow (especially for GPUs). Local disks (within a computing node) are faster*
## List of services for scientific computing
Most of them are based on notebooks, but Azure and Amazon AWS+EC2 allow you to have dedicated machines or set up your own cluster based on your needs.
* Try Jupyter https://jupyter.org/try
* Binder https://mybinder.org/
* Kaggle Kernels https://www.kaggle.com/kernels
* Google Colaboratory (Colab) https://colab.research.google.com/
* Microsoft Azure https://azure.microsoft.com/en-us/services/machine-learning/
* CoCalc https://cocalc.com/
* Datalore https://datalore.jetbrains.com/
* Amazon AWS+EC2 https://aws.amazon.com/aws/ec2
* Google Cloud Console https://console.cloud.google.com/
* For finnish researchers: CSC.fi
* For norwegian researchers: sigma2.no
## "Free" services are not enough for me OR I have sensitive data that I cannot take outside my institution network, what options do I have at my university?
* [Aalto University scientific computing strategies](https://scicomp.aalto.fi/triton/usage/workflows/)
* [University of Oslo](https://annefou.github.io/resources-UiO/index.html)
* Add here for other institutions in the nordics