---
title: Python Learning Note
tags: python
---
[TOC]
## Fundamental Concept
1. Python為一[強型別程式語言](https://stackoverflow.com/questions/11328920/is-python-strongly-typed)

2. Python的語法中沒有`{}`,因此是用縮排(indent)來判別範圍,縮排並沒有規定為多少空格,只要統一即可
3. Python中所有的東西都是物件,變數實際上是參考到一個物件(可以用id查看)
- Immutable object:此物件的內容不能被更改,所以對此物件的更改實際上是創造一個新的物件,並將新物件的參考assign給變數
- 傳遞參數時**類似C/C++ call by value**
- 常見的有: int、str、tuple
- Mutable object:此物件內容可以被更改,因此每次對其做的更改,都對該物件的參考做更改
- 傳遞參數時**類似C/C++ call by reference**
- 常見的有: list、dict
- 這個觀念非常重要,一開始初學時因為不知道所以很常碰壁
4. 註解符號
- Single Comment: `#後面內容為單行註解`
- Mutiple Comment: `""" 內容為多行註解 """`
5. Keyword
1. `pass`
- 如同字面上的意思,當程式運行到 pass statement 時,會略過
- 非常常見,像是一開始規劃程式時,可以列出需要的function,但function body不能為空,此時就可以用pass略過;或是在處理Exception時,有時遇到一些例外可以略過不處理,也會用到pass
2. `is`
- 用來判斷兩物件是否相等,跟`==`不同的是,`is`比較是兩物件的記憶體位址,`==`比較的是兩物件的值
- 為什麼要有`is`和`==`,事實上跟第三點有關,如果看到這裡還無法明白且暫時不去思考,看完整篇筆記就會知道了
## Control Statement
### If Satement
```python=
if condition:
handle statement
elif condition:
handle statement
else:
handle statement
```
Condition 的部分可以加括號亦可不加
### Ternary Operator
:::danger
Python 沒有 Ternary Operator
:::
```python=
# 第一種方法
True Satement if Condition else False Satement
# 第二種方法
(True Satement, False Satement)[Condition]
# 歡迎提供更多方法
```
### Switch Statement
:::danger
Python 沒有 switch statement
:::
替代方案有蠻多種,這裡提供一個我自己用過還不錯的
```python=
# 使用 dict 模擬 switch
# 使用時機為 內容行為可以直接用function處理
# 為不影響篇幅,假設fun已存在
handler = {
'1' : fun1,
'2' : fun2,
'3' : fun3,
}
# 執行
fun_handle = handler[choice]
fun_handle()
# 簡化
handler[choice]()
# 更好的寫法
handler.get(choice, lambda:print('No option'))()
```
## Loop
### While Loop
```python=
# 注意縮排
while Condition:
statement
```
### For Loop
?? python的for好像是用到iterator、generator的概念,這個我還不是很清楚,先用例子記起來吧
```python=
# Increment
for i in range(5):
print(i, end=' ') # 0 1 2 3 4
for i in range(2, 5):
print(i, end=' ') # 2 3 4
for i in range(1, 5, 2):
print(i, end=' ') # 1 3
# Decrement
for i in range(5, 0, -1):
print(i, end=' ') # 5 4 3 2 1
# List & Tuple
listA = ['A', 'B', 'C']
for idx in range(len(listA)):
print(listA[idx]) # A B C
for elem in ['A', 2, 'C', 4]:
print(elem, end=' ') # A 2 C 4
for key, value in [(1, 'one'), (2, 'two')]:
print(f'{key}={value}', end= ' ') # 1=one 2=two
```
## Function
### Basic Function Prototype
```python=
def FunctionName(Parameter List):
Function Body
```
### Return None Type
這邊需要注意的是,function可以不回傳東西,因此若沒有明確指定要回傳甚麼,都是回傳 `None` 這個特殊型別
```python=
# 以下三種寫法回傳值皆為 None
def fun1():
print('Hello')
def fun2():
print('Hello')
return
def fun3():
print('Hello')
return None
```
### Multiple Return Values
Python 允許同時回傳多個回傳值,以**Tuple**形式回傳
```python=
def fun(a, b, c):
return a, a+b, a+b+c # 等同於 return (a, a+b, a+b+c)
n = fun(1,2,3) # n = (1,3,6)
n1, n2, n3 = fun(1,2,3) # n1=1, n2=3, n3=6
n1, n3 = fun(1,2,3) # Try and Test(T1)
```
### Parameter has Default Value
Python 允許有Default Value,規則是通用的一律從右邊開始省略
```python=
def fun(a, b=5, c=10):
return a+b+c
n1 = fun(1,2,3) # n1=6
n2 = fun(1,2) # n2=13
n3 = fun(1) # n3=16
```
### Position & Keyword Arguments
在Python傳遞參數時,除了用位置對齊以外,還可以用parameter的名字來指定
注意:**position argments 不能在 keyword arguments 的右邊**
```python=
def say(name, msg):
print(name, msg)
say('Tom', 'Hi') == say(msg='Hi', name='Tom') == say('Tom', msg='Hi')
```
### Advanced Function Prototype
> 你可以不會寫,但是遇到必須看得懂
```python=
def FunctionName(arg, *args, **kwargs):
Function Body
```
`*args`:允許傳入可變動position參數,儲存資料型態為 tuple
`**kwargs`:允許傳入可變動keyword參數,儲存資料型態為 dictionary
> 若要同時使用則 `*args` 需要在 `**kwargs` 的左邊
```python=
def fun(arg, *args, **kwargs):
print(f'arg = {arg}')
print(f'args = {args}')
print(f'kwargs = {kwargs}')
# 執行函數
fun(1, 2, 3, k1=4, k2=5)
# 觀察輸出結果
Output:
arg = 1 # Position Argument
args = (2, 3) # Mutable Position Argument, which type is Tuple
kwargs = {'k1': 4, 'k2': 5} # Mutable Keyword Argument, which type is dictionary
```
對於`*args、**kwargs`該如何運用?
你只需要記得他們的型別為何,就可以運用自如
```python=
# *args mutable position arguments
def fun(*args):
sum = 0
for num in args:
sum += num
print(f'sum is {sum}')
# Try & Test(T2)
# 這樣的寫法非常蠢,想想看有沒有更簡短的寫法
fun(1,2,3,4,5,6,7,8,9,10)
# 如果我只想加1~10的奇數就好,該怎麼寫
# (我用到List Comprehension,還沒看到可以跳過)
Output:
sum is 55
```
```python=
# **kwargs mutable keyword arguments
def fun(**kwargs):
for key, value in kwargs.items():
print(f'({key}, {value})')
fun(k1='one', k2='two', k3='six')
Output:
(k1, one)
(k2, two)
(k6, six)
```
傳遞參數時可以使用`*args、**kwargs`
```python=
def fun(a1, a2, a3):
print(f'a1={a1}, a2={a2}, a3={a3}')
# 設定變數
nums = (1,2,3) # Try & Test 將Tuple改成List(T3)
kwnums = {'a3' : 6, 'a1' : 4, 'a2' : 5}
# 傳遞給函式,這樣的寫法有一種將它展開的感覺
fun(*nums)
fun(**kwnums)
Output:
a1=1, a2=2, a3=3 # fun(*nums) result
a1=4, a2=5, a3=6 # fun(**kwnums) result
```
上面的例子唯一要注意的是,`kwnums`中的key必須為**字串**
### Lambda Function
> 這招必學,學會程式碼可以非常簡短!!
#### Lambda Syntax
```python=
lambda [arg1 [, arg2 [,..., argN]...]] : Lambda Body
```
關於Lambda的一些重點:
1. Lambda 為一匿名函數
2. Lambda 的參數可以有或沒有
3. Lambda Body~~只能有一行~~ one expression(?? diff expression statement)
4. Lambda Body不需要寫Return
- 事實上,可以看成`lambda args : return Lambda Body`
- 一樣的概念,如果你的Body像是print(),就是回傳None
5. Lambda Body不能做Assign
- ?? 目前不清楚為什麼,剛好寫程式有碰到
繼續之前,釐清觀念會更好(內含我自己的推測,請不要全盤接受,盡量挑錯):
> 還記得之前說過,變數為一物件的參考(在Fundamental Concept 第三點)。
> 經過我的觀察,函數也可以用相同的概念來看。
>
```python=
# 先進到Python Interpreter
def f():
return 1
# type f
<function f at 0x00000217D65C52F0>
# 網路上沒找相關資訊但我推測後面的數字應該會是記憶體位置
# 我是由 0x + 碼數16位 + python interpreter 64 bits 判斷
# 可以看到函數的行為是被存在一個固定的地方
# f 只是一個變數,它參考到這塊記憶體位址
# 進行以下測試
g = f
f = 0
# type g
<function f at 0x00000217D65C52F0>
# type f
0
# type g()
1
# 其實可以看到我們的function name是甚麼根本沒差
# 重要的是只要參考到我們要的記憶體位址(或是說函式物件),就夠了
# 額外補充()在此用作 function call operator
```
:::info
結論:
funcion name如同變數一樣,它們都是一個名稱,都可以參考到一個物件,
只是funcion name一開始被定義時,稍微特別一點,它參考到的物件可以執行`()`
:::
進入主角
```python=
# 先進入Python Interpreter
# 這個函式行為跟上面是一樣的,希望可以看得出來
# type lambda : 1
<function <lambda> at 0x00000217D65C5488>
# 到這裡,你可能已經看出來了
# 當我們輸入 lambda : 1 時
# 事實上就是定義了一個函式的行為,並且已經被存在某個記憶體空間了
# 剛剛說了名字是甚麼根本不重要,重要的是我們需要掌握這一塊記憶體位址,才能執行函數行為
# 因此底下提供兩種做法
# 1. 這個函式只會在"現在"用到,並且只會使用一次,那就直接呼叫吧
(lambda : 1)()
# 2. 這個函式"未來"會用到,給它一個變數名稱吧
f = lambda : 1
f()
# 發現了嗎,第二點的使用方法跟以前一模一樣阿
# 難道是我在跟你開玩笑?
# 不,能用一行解決的事,為什麼要寫兩行
```
:::info
結論:
就跟你說學會這招可以簡短程式碼了吧。
思考一下如果有參數的lambda,用兩種寫法該怎麼表示。
不要往下滑,有答案!!
:::
Lambda Example
```python=
# 該筆記的Data Structure中List、Dict
# 使用sort時,很常用到Lambda,底下都有範例
# 在此不贅述
seq = [-4, -3, 5, 7, 9]
filter_res = list(filter(lambda x : x < 0, seq))
# filter_res = [-4, -3]
map_res = list(map(lambda x : x**2, seq))
# map_res = [16, 9, 25, 49, 81]
# 未來寫視窗會用到
# 在tkinter中的按鈕,預設command是不能帶參數的
# 如果要帶參數怎麼辦?
def btn_handler(arg):
pass
btn = tkinter.Button(..., command=lambda:btn_handler(x)).pack()
# 公布解答
# 1. 帶參數直接呼叫
(lambda x, y, z : x*y*z)(3,6,9)
# 2. 存起來日後可以用
f = lambda x, y, z : x*y*z
f(3,6,9)
```
### Try & Test
T1: Raise **ValueError**, Message is "too many values to unpack"
> 所以如果不知道會回傳幾個參數,就用一個變數去取,型別為Tuple;不然就必須要用剛好的變數去取
T2: 參考寫法,歡迎貢獻更多不一樣的寫法
```python=
fun(1,2,3,4,5,6,7,8,9,10)
# 改成
fun(*tuple(range(11)))
# 只想加奇數
fun(*[x for x in range(11) if x%2])
```
T3: 答案是沒有問題
> 按照我的理解,list & tuple的差別應該只是
> list is mutable
> tuple is imutable
### Inbulit Function
1. `abs(num)`
- Return the absolute value of `num`
2. `sum(iterable, start=0)`
3. `id(obj)`
- Return a **unique** number(not address) about the `obj`
4. `type(obj [, base, dict])`
- `type(obj)` Return the class name of the obj
- `type(obj, base, dict` Create a new class
5. `int(n) float(n)`
6. `oct(n) hex(n)`
- Return type is string
7. `complex(real=0, imag=0)`
8. `str(x) bytes(x)`
9. `list(iterable) tuple(iterable) dict(iterable)`
- 底下Inbuilt Data Structure有介紹
10. `isinstance(obj, class | tuple)`
- 可以判斷obj是否為該class或是該class的子類別
- Return boolean
## I/O
### Simple I/O
```python=
'''Input'''
# 讀取資料,直到EOF,回傳型別為字串
data = input()
data = input('Input Prompt')
'''Output'''
print(var1, var2, var3, sep='&') # 預設會自動隔一個空格,透過sep指定
print(var1, var2, end='')
# 預設print一次會自動接一個\n,可以透過end指定以空字串結尾(kwargs的用法)
```
### File I/O
1. 開啟檔案: 使用 open 內建函式
- [更詳細的參數用法](https://docs.python.org/3/library/functions.html?highlight=open#open)
- 基本會用到的參數
- file
- 必要
- 為一絕對、相對的檔案路徑
- 型別為字串
- mode
- Default is `'r'`
- 非必要,但一般都會填
- 開啟檔案的模式
- `'r'` : read only
- `'r+'` : read and write, no Truncation
- `'w'` : write only, Truncation
- `'w+'` : read and write, Truncation
- `'a'` : append, always append before EOF
- `'b'` : binary
- `'rb'`、`r+b` : no Truncation
- `'wb'`、`'w+b'` : Truncation
- 型別為字串
- encoding
- 非必要,偶爾會需要用到
- 型別為字串
- 回傳一檔案物件,利用此物件進行File I/O
> Truncation : 開啟檔案時會把原本檔案刪掉
2. 檔案物件(以下簡稱 f_obj)
- 常用屬性
- `f_obj.closed`
- Return Ture if f_obj is closed
- `f_obj.name`
- Return file name
- `f_obj.mode`
- Retrun file open mode
- 常用函式
- `f_obj.close()`
- 關閉檔案物件
- 當檔案物件的參考(變數)參考到其他檔案物件時,python會自動關閉檔案
- `f_obj.read([count])`
- 讀取檔案內容
- count 為要讀取多少 bytes
- 沒有指定參數,則會盡可能地讀全部的資料
- Return string
- Return `''` if reached EOF
- `f_obj.readline()`
- 讀取資料直到`'\n'`
- Return string
- Return `''` if reached EOF
- `f_obj.readlines()`
- 讀取整個檔案
- Return **list**
- 等同於 `f_obj.read().split('\n')`
- 等同於 `list(f_obj)`
- `f_obj.write(string or bytes)`
- 將資料寫入檔案
- 寫入的資料不是string就是bytes(看模式)
- Return bytes which are written successfully
```python=
# 分享一個曾經看過的寫法
f_obj = open('example.txt', 'r')
for line in f_obj:
print(line, end)
f_obj.close()
```
這樣的好處我想應該是可以節省資料的儲存空間
## Class and Object
### Basic Class Prototype
```python=
class ClassName(object):
def __init__(self, args):
# Initialize data members
self.public_data # No underline
self._protected_data # Single underline
self.__private_data # Double underline
def __del__(self):
# Destructor
pass
def func(self):
# Define member function
pass
def __private_func(self):
pass
```
1. Class 一般名稱開頭會大寫
2. Class 的每個member function第一個參數一定要是self
- self 指的就是該類別本身
- 在class內部存取自己的data member都要透過self
3. `__init__` 相當於建構元,用於初始化data member
- 在Python建立物件的流程,事實上是,`__new__ -> __init__`
4. `__del__` 相當於解構元(我還沒用過)
5. 關於`public、protected、private`
- Python 並沒有實作太多這樣的存取機制(protected 不常見到,一般最多就publice、private)
- Default 都是public
- 若要private,前面加雙底線
6. `class ClassName(object):` 可以寫成 `class ClassName:`
- 後面繼承會談到
```python=
def getGender(self):
return self.gender
class Person:
""" This is Person class description """
def __init__(self, name, gender, age=18):
self.name = name
self.gender = gender
self.__age = age
# 提供我知道的一些方法
def showName(self):
print(self.name)
getAge = lambda self : self.__age
getGender = getGender
Mary = Person('Mary', 'woman', 20)
# Class 往下如果是一個多行註解,它會變成該class的說明文字
# 也可以在help(Person)、help(Mary)查看該說明內容
print(Person.__doc__, Mary.__doc__)
# 示範使用member function
Mary.showName()
print(Mary.getGender(), Mary.getAge())
# Raise AttributeError
print(Mary.__age)
```
### Inheritance
```python=
# Single Inheritance
class SuperClass:
pass
class SubClass(SuperClass):
def __init__(self, args)
# 兩種方式呼叫父類別建構元
super().__init__(args)
SuperClass.__init__(self, args)
# Multiple Inheritance
class SubClass(Class1, Class2, ...):
pass
```
### Polymorphism
### Opeartor Overloading
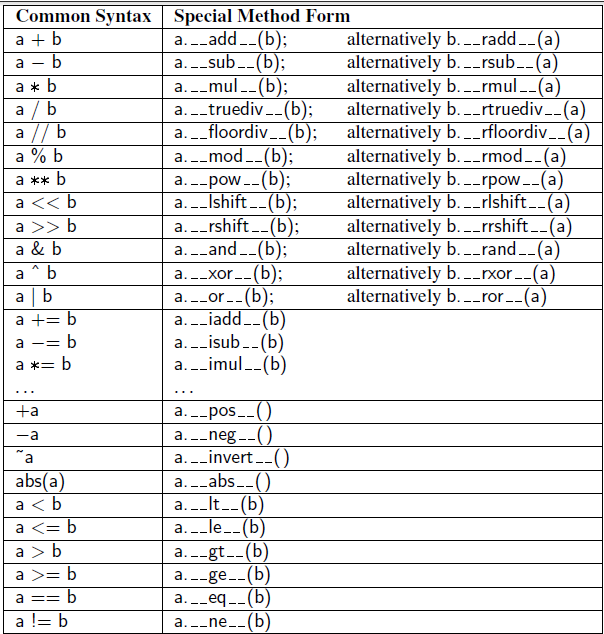
- `int() <=> __int__(self)`
- `float() <=> __float__(self)`
- `str() <=> __str__(self)`
- `[index] <=> __getitem__(self, index)`
- `in <=> __contains__(self, other)`
- `len <=> __len__(self)`
```python=
# 剛好以前有作業有用到
# Inheritance、Operator Overloading、Override
# 暫且拿來當例子ㄅ
# 題目為用現成的PriorityQueue實作Reverse
import queue
# 該Class用來封裝資料,目的是要使用自定義的比大小方式
# 藉此達到Reverse
class Wrapper():
def __init__(self, data):
self.data = data
getValue = lambda self : self.data
# >
def __ge__(self, other):
if isinstance(other, Wrapper):
return not self.data >= other.data
else:
raise TypeError
# >=
def __gt__(self, other):
if isinstance(other, Wrapper):
return not self.data > other.data
else:
raise TypeError
# <
def __le__(self, other):
if isinstance(other, Wrapper):
return not self.data <= other.data
else:
raise TypeError
# <=
def __lt__(self, other):
if isinstance(other, Wrapper):
return not self.data < other.data
else:
raise TypeError
# ==
def __eq__(self, other):
if isinstance(other, Wrapper):
return self.data == other.data
else:
raise TypeError
# 該class繼承了現有PriorityQueue
# 並對put、get兩個function做改寫
# 將送進去儲存的資料用上面的class包裝起來
class MyPriorityQueue(queue.PriorityQueue):
def put(self, data):
super().put(Wrapper(data))
def get(self):
return super().get().getValue()
# 測試函式
if __name__ == '__main__':
pq = MyPriorityQueue()
aList = [5,6,73,1,42,3,9,75]
for e in aList:
pq.put(e)
while True:
if not pq.empty():
print(pq.get(), end=' ')
else:
break
```
## String
### String Function
> Cause string is immutable object, any function changing the string always return a new string object.
#### 1. Test Function
- `isalnum()`
- Return True, if string only contains number or alphabet
- `isalpha()`
- Return True, if string only contains alphabet
- `isdigit()`
- Return True, if string only contains number
- `isspace()`
- Return True, if string only contains whitespace charactor
- `isidentifier()`
- Return True, if string is python identifier
- `islower()`
- Return True, if string is lower case
- `isupper()`
- Return True, if string is upper case
- `startswith(s)`
- Return True, if string starts with `'s'`
- `endswith(s)`
- Return True, if string ends with `'s'`
#### 2. Search Function
- `find(s)`
- Return the first found index of `'s'` in the string which starts from index 0
- Return -1 if `'s'` is not in stirng
- `rfind(s)`
- Return the first found index of `'s'` in the string which starts from last index
- Return -1 if `'s'` is not in stirng
- `count(s)`
- Return how many times `'s'` appers in the string
#### 3. Common Function
- `lower()`
- Return string is lower case
- `upper()`
- Return string is upper case
- `replace(old, new)`
- Return string has replaced old sub_string to new sub_string
- EX:`str.replace('\n', '').replace('\r', '').replace('\t', '')`
- `split(sep=None, maxsplit=-1)`
- Return a list of the words in the string, using sep as the delimiter string.
- EX:`'He ll o'.split(' ') --> ['He', 'll', 'o']`
- `join(iterable)`
- Return a new string that inserted string between the each element in the iterable
- EX:`','.join(['He', 'll', 'o']) --> 'He,ll,o'`
- `string.strip()`
- Return a new string that striped the blank or string you assigned
```python=
string = """ geeks for geeks """
# prints the string by removing leading and trailing whitespaces
print(string.strip())
# prints the string by removing geeks
print(string.strip(' geeks'))
```
#### 4. Format Function
> 不熟,待補充
兩個常用形式:
```python=
name, age = 'Tom', 8
str1 = "I'm {}, {} years old.".format(name, age)
str1 = "I'm {1}, {0} years old.".format(name, age)# output = I'm 8, Tom years
str1 = "I'm {:^8}, {:*>3} years old.".format(name, age)
'''
^ 置中; >, 靠右; <, 靠左
'''
str2 = f'I\'m {name}, {age} years old.'
str3 = "%s is %d years old." % (name, age)
```
## Exception Handling
### Basic Type
```python=
# 觸發例外
raise <ExceptionType>
# 處裡例外
try:
<body>
except <ExceptionType1>:
<handler1>
...
except <ExceptionTypeN>:
<handlerN>
except:
<handlerExcept>
# 當前面的except都無法抓到合適的型態時, 執行此區塊
else
<process_else>
# 當try裡面沒有例外發生時, 執行此區塊
finally:
<process_finally>
# 定義一些收拾行為, 不管有沒有發生例外, 最後都會執行此區塊
```
## Inbuilt Data Structure
### List
> List is a mutable object.
> List is like one dimension array, more like vector in C/C++
#### 1. List Functions
- `list.append(elem)`
- Append elem to the tail of list
- `list.extend(iterable)`
- Extend the iterable and append all elems of it to the list
- EX: `[1,2].extend( (4,5) ) --> [1,2,4,5]`
- `list.insert(idx, elem)`
- Insert the elem to the idx
- EX: `[1,3,4,5].insert(1,2) --> [1,2,3,4,5]`
- `list.remove(elem)`
- Remove the **first** elem in the list
- Raise ValueError if elem is not in the list
- EX: `[1,2,1].remove(1) --> [2,1]`
- `list.pop([idx])`
- Remove the idx-th elem
- Remove the last elem if no idx
- `list.clear()`
- Clear all elems from the list
- Same as `del list[:]`
- `list.index(elem, [start [, end]])`
- Return the idx of the **first** elem
- Raise ValueError if elem is not in the list
- `list.sort(key=None, reverse=False)`
- Sort the list by key
- In-place Sort
- `list.copy()`
- Return the copied list
```python=
# Sort Example
# Initialize var
a = [9, 4, 7, 1]
a.sort()
## a = [1,4,7,9]
# Initialize var
b = [ (1, 'FC'), (-9, 'XY'), (4, 'KC'), (11, 'BZ') ]
# sort by default
# Try & Test & Think, What is default
b.sort()
## b = [(-9, 'XY'), (1, 'FC'), (4, 'KC'), (11, 'BZ')]
# sorted by 'word'
b.sort(key=lambda x : x[1])
## b = [(11, 'BZ'), (1, 'FC'), (4, 'KC'), (-9, 'XY')]
# sorted by the second character of the 'word'
b.sort(key=lambda x : x[1][1])
## b = [(1, 'FC'), (4, 'KC'), (-9, 'XY'), (11, 'BZ')]
```
```python=
# Four ways of copy
# Initilize var
a = [1,2,3]
# Copy
# Bad Way
b = []
for x in a:
b.append(x) or b.insert(len(b), x)
# Better Way
b = a.copy() # Use list copy function
b = [] + a # Use list concatenation
b = [x for x in a] # Use list comprehension
# Try & Test & Think
# Why don't we simply use
b = a
```
#### 2. List Slicing
> List 可以一次取出不只一個元素,用的就是 Slicing
##### Syntax
```python=
list[index1 : index2] #從index1取到index2(不包含index2)
```
##### Example
```python=
x = [1, 2, 3, 4]
x[0:2] # [1, 2]
x[1:-1] # [2, 3], 1和倒數第一個之間的元素
x[2:0] # [] , 若第一個索引的位置在第二個索引的位置之前
x[ :2] # [1, 2], 從開頭開始切
x[2: ] # [3, 4], 從2開始切到尾
x[ : ] # [1,2,3,4], 這邊是不一樣的list只是切出所有元素
```
#### 3. List Comprehension
> 這招必學,學會程式碼可以非常簡短!!
##### Basic Type
```python=
list_var = [ x for x in iterable ]
a = [1, 3, 5]
b = [x for x in a]
## b = [1, 3, 5]
apple = [c for c in 'apple']
## apple = ['a', 'p', 'p', 'l', 'e']
```
##### With Condition
```python=
odd_num = [n**2 for n in range(10) if n % 2]
## odd_num = [1, 9, 25, 49, 81]
# Equal to
odd_num = []
for n in range(10):
if n % 2:
odd_num.append(n**2)
# Nested If
nums = [n for n in range(100) if n % 2 == 0 if n % 5 == 0]
## nums = [0, 10, 20, 30, 40, 50, 60, 70, 80, 90]
# Equal to
nums = []
for n in range(100):
if n % 2 == 0:
if n % 5 == 0:
nums.append(n)
```
##### With Nested Loop
```python=
nums = [ x*y for x in [1,2,3] for y in [10,20,30] ]
## nums = [10, 20, 30, 20, 40, 60, 30, 60, 90]
# Equal to what?
# Try & Test
```
#### 4. List Common Usage
```python=
# 1. Transform input to int
nums = list(map(int, input('Input Numbers: ').split(' ')))
# 2. Access elems dirtectly, not access by index
for elem in aList:
pass
# 3. Get list size
size = len(aList)
# 4. Delete element in list
aList = ['a', 'b', 'c', 3, 4, 5]
del aList[1] # aList == ['a', 'c', 3, 4, 5]
del aList[ :2] # aList == [3, 4, 5]
```
#### 5. List Common Error
```python=
aList = list(1, 2, 3)
## Raise TypeError
# Create a list just simply use
aList = [1, 2, 3]
# list(iterable) correct usage
aList = list( (1, 2, 3) )
aList = list( range(1,4) )
```
### Tuple
> 1. Tuple is a immutable object
> 2. Common usage is to store value
> 3. Can't insert value to the tuple and remove value from the tuple
### Dictionary
> 1. 使用key-value的方式儲存資料
> 2. 如同C++ hash map
> 3. key-value可以為任意型別
#### 1. Dictionary Function
- `dict(mapping)`:
- Return the dict of mapping
- EX:`dict([('one', 1) ,('two', 2)]) --> {'one': 1, 'two': 2}`
- `dict(**kwargs)`:
- EX:`dict(k1='A', k2='B') --> {'k1': 'A', 'k2': 'B'}`
- `[]`:
- Add the value to the key
- EX: `dict_obj[key] = value`
- Get the value of the key
- EX: `var = dict_obj[key]`
- If no key, raise KeyError
- `dict.update(**kwargs or dict_obj)`
- Add the value to the original dict_obj
- `dict.clear()`
- Remove all elems in the dict
- `dict.copy()`
- Return the copy of the dict
- `dict.get(key, default=None)`
- Return the value of the key
- If no key, return default
- EX:`dict.get(fun, lambda:print('no fun'))()`
- `dict.keys()`
- Return a list of the key in dict
- `dict.values()`
- Return a list of the value in dict
- `dict.items()`
- Return a list of the key-value pair in dict
- `dict.pop(key, [default])`
- Return the value of the key, and pop the key from the dict
- If key isn't exist, return default
- If no default , raise KeyError
- `dict.__contain__(key)`
- Return True if key in the dict
- EX:`True if key in dict else False`
#### 2. Dictionary Example
```python=
# dict example with sorted and lambda
dic = {'Mary' : 50, 'Bob': 30, 'Cindy' : 80, 'John' : 100, 'Can' : 10}
# Sort by key
sort_by_key = sorted(dic.items(), key = lambda x:x[0])
## sort_by_key =
## [('Bob', 30), ('Can', 10), ('Cindy', 80), ('John', 100), ('Mary', 50)]
# Sort by value
sort_by_val = sorted(dic.items(), key = lambda x:x[1])
## sort_by_val =
## [('Can', 10), ('Bob', 30), ('Mary', 50), ('Cindy', 80), ('John', 100)]
# Sort with the second word of name and reverse
sort_ch = sorted(dic.items(), key = lambda x:x[0][1], reverse = True)
## sort_ch =
## [('Bob', 30), ('John', 100), ('Cindy', 80), ('Mary', 50), ('Can', 10)]
```
## Module -- JSON
> Library: json
常用函式:
1. `dump(obj, fp)`
- Python物件轉換成JSON格式字串,並寫入檔案
2. `loda(fp)`
- 從檔案讀取JSON,並轉換成Python物件
3. `dumps(obj)`
- 注意s,將Python物件轉換成JSON格式字串
- 選用參數(有很多,僅列出我用過的)
- skipkeys
- default = False
- True,略過非Python基本型態的key值,(Python基本型態:str、int、float、bool、None)
- False 遇到非Python基本型態的key值,產生TypeError
- sort_keys
- default = False
- 按照資料key值排序
- separators
- default = None
- If None 預設字典顯示,為`( ' , ' , ' : ' )`,代表每對pair之間用逗點隔開,key與value之間用冒號隔開
- EX:`json.dumps( { 1 : 'Mary', 2: 'Jack' }, separators=(" | ", " = ") )`
- Output:`'{"1" = "Mary" | "2" = "Jack"}'`
4. `loads(str)`
- 注意s, 將JSON字串轉換成Python物件
型別對照表
| Python | JSON |
|:------:|:------:|
| dict | object |
| str | string |
| int | number(int) |
| float | number(real) |
| True | true |
| Flase | flase |
| None | null |
使用範例
```python=
# 進入Python Interpreter
import json
# 基本型態
a, b, c, d, e, f = 'Hi', 10, 1.0, True, False, None
# dumps function
A = json.dumps(a)
B = json.dumps(b)
C = json.dumps(c)
D = json.dumps(d)
E = json.dumps(e)
F = json.dumps(f)
# type A ~ F,觀察結果
# loads funcion
a1 = json.loads(A)
b1 = json.loads(B)
c1 = json.loads(C)
d1 = json.loads(D)
e1 = json.loads(E)
f1 = json.loads(F) # 用print才看得到
# type a1 ~ f1,觀察結果
# 可以測試一下,a == a1 ~ f == f1,結果都會是True
```
:::info
小結: 基本型態的轉換可以放心使用,沒有問題
:::
```python=
# 進入Python Interpreter
import json
# 資料結構 Tuple List Dictionary
aTuple = ('Tuple', 'will', 'change', 'toList', 99)
aList = ['Int', 10, 'Float', 1.0, 'String', 'hello', 'LofL', [1,2], (3,4)]
aDict = {9 : 99, 1.0 : 5.5, 'str' : 'string', None : None}
# dumps function
TD = json.dumps(aTuple)
LD = json.dumps(aList)
DD = json.dumps(aDict)
# type LD TD DD,觀察結果
# loads function
bTuple = json.loads(TD)
bList = json.loads(LD)
bDict = json.loads(DD)
# type (a、b) pair 比較結果
# 可以測試一下,每對pair的比較,結果都會是Flase
```
:::info
小結: 資料結構的轉換必須要注意一些事情
1. List 在轉換時只要其元素都為基本型態,是沒問題的
2. JSON 沒有Tuple的型態,任何Tuple都會被轉成List
3. Dictionary 的key在JSON裡面必須是字串型態,value不受影響
:::
如果一定要非字串型別當作dict key值的話,可以使用二次dump的技巧
```python=
def transKey(dict_data, encode=True):
tmp_dict = {}
for key, value in dict_data.items():
if encode:
tmp_dict[json.dumps(key)] = value
else:
tmp_dict[json.loads(key)] = value
return tmp_dict
# 使用上
aDict = {9 : 99, 1.0 : 5.5, None : None}
# 先進行key轉換,在做dumps
aDict_transKey = transKey(aDict, encode=True)
jDict_dump = json.dumps(aDict_transKey)
# 先做loads,再將key轉回去
jDict_load = json.loads(jDict_dump)
bDict = transKey(jDict_load, encode=False)
if aDict == bDict:
print('Successed!!')
```
Json 和檔案相關的簡單基本操作
```python=
# Json & File
aDict = {'1' : 'one', '2' : 'two', '6' : 'six'}
# 寫入檔案(法一)
with open('example.json', 'w') as fp:
fp.write(json.dumps(aDict))
# 寫入檔案(法二)
json.dump(aDict, open('example.json', 'w'))
# 讀出檔案(法一)
with open('example.json', 'r') as fp:
data = json.loads(fp.read())
# 讀出檔案(法二)
data = json.load(open('example.json', 'r'))
```
## Third Party Module
```python=
# Download Module
pip install <module name>
# Update Module
pip install -U <module name>
```
```python=
# 下載過的模組
pyperclip # 剪貼簿(複製、貼上)
openpyxl # Excel 相關操作
```
### Module -- Pyperclip
> library pyerclip
- copy(*string*)
- 傳送字串到剪貼簿
- paste()
- 從剪貼簿接收字串
### Module -- Openpyxl
> library openpyxl
> 用來處理Excel檔案
#### Excel
- Excel 試算表文件 == 活頁簿(workbook)
- 儲存在.xlsx檔案中
- 活頁簿可有多個工作表(sheet)
- 正在使用的工作表稱為 active sheet
- 欄從A開始
- 列從1開始
#### Attr & Fun
##### openpyxl
- load_workbook(*file*)
- file 為 Excel 檔名
- Return: Workbook Object
```python=
wb = openpyxl.load_workbook('examply.xlsx')
```
- Workbook()
- 建立空的活頁簿
- Return: Workbook Object
##### openpyxl.utils
- get_column_letter
- 將數字轉成欄位代碼
```python=
openpyxl.utils.get_column_letter(27) #AA
```
- column_index_from_string
- 將欄位代碼轉成數字
```python=
openpyxl.utils.column_index_from_string('AA') # 27
```
##### openpyxl.styles
- Font(*name, size, bold, italic*)
- 可以自訂儲存格字型別樣式
- name : 字型名稱, `string`
- size : 字型大小, `int`
- bold : 粗體, `bool`
- italic : 斜體, `bool`
```python=
from openpyxl.styles import Font
f1 = Font(name='Console', size=12, bold=true, italic=true)
<cell>.font = f1
```
##### workbook
- active
- 取得 active sheet
- Return: Worksheet Object
- worksheets
- 取得所有 sheets
- Return: List
- encoding
- 取得編碼
- Return: String
- get_sheet_by_name(*sheet name*)
- 取得指定 sheet
- Return: Worksheet Object
- get_sheet_names()
- 回傳所有的sheet
- Return: List
- create_sheet(*index=, title=*)
- 建立分頁,預設加在最後,可以指定index
- remove_sheet(*Sheet Objet*)
- 刪除指定的分頁
- save(*excel name*)
- 儲存成Excel檔
##### Worksheet
- title
- 取得 sheet name
- max_row
- 取得工作表列的最大值
- max_column
- 取得工作表行的最大值
- freeze_panes
- 設定凍結窗格(不管捲到哪,都會顯示在最上層)
- 需要注意的是,凍結的範圍是**小於給定的值**
- A1 -> 沒有凍結
- 等同於`None`
- B2 -> 凍結欄A、列1
- C1 -> 凍結欄A、欄B
```python=
ws.freeze_panes = 'A2'
```
- row_dimensions[*row*].[height | width]
- 設定指定列的高度或寬度
```python=
ws.row_dimensions[1].height = 50
```
- column_dimensions[*row*].[height | width]
- 設定指定行的高度或寬度
```python=
ws.column_dimensions['B'].width = 15
```
- cell(*row=i, column=j*)
- 取得i列j行的儲存格
- Return: Cell Object
```python=
# 另外一種取法
sheet['A1'].value
```
- merge_cells(*range*)
- 合併儲存格
```python=
ws.merge_cells('A1:D3') # merge 12 cells
```
- unmerge_cells(*range*)
- 取消合併儲存格
```python=
ws.unmerge_cells('A1:D3') # merge 12 cells
```
##### cell
- value
- 取得值或修改值
- row
- 取得該cell位於哪一列
- column
- 取得該cell位於哪一行
- coordination
- 取得該cell位置(EX: A1、B2)
##### Sheet Slice
```python=
import openpyxl
wb = openpyxl.load_workbook('example.xlsx')
st = wb.get_sheet_by_name('Sheet1')
for row in sheet['A1':'C3']:
for cell in row:
print(cell.coordinate, cell.value)
```
##### Formula
> Excel中公式是由=開頭
```python=
import openpyxl
wb = openpyxl.Workbook()
ws = wb.actice
ws['A1'], ws['A2'] = 100, 200
ws['A3'] = '=SUM(A1:A2)'
wb.save('formula.xslx')
```
##### Example
###### Chart
```python=
import openpyxl
wb = openpyxl.Workbook()
ws = wb.active
# Create simple data in cell
for i in range(1,11):
ws['A'+str(i)] = i
# Create Reference Object
ref = openpyxl.chart.Reference(ws, min_col=1, min_row=1, max_col=1, max_row=10)
# Create Series Object
series = openxl.chart.Series(ref, title='First series')
chart = openpyxl.chart.BarChart() # 直方圖
chart.title = '直方圖'
chart.append(series) # 將序列資料加到圖表中
ws.add_chart(chart, 'C5') # 將圖表加到分頁中指定的位置
wb.save('sammpleChart.xlsx')
```
:::danger
雖然openpyxl可以製作圖表,但在讀取Excel時,無法讀取圖表
:::
- 其他可畫的圖表
- openpyxl.chart.LineChart(), 折線圖
- openpyxl.chart.ScatterChart(), 散佈圖
- openpyxl.chart.PieChart(), 圓餅圖