---
title: AI BERT
tags: APAC HPC-AI competition
---
# AI BERT pre-knowledge
[TOC]
---
[Benchmark](https://www.hpcadvisorycouncil.com/events/2020/APAC-AI-HPC/pdf/HPC-AI_Competition_BERT-LARGE_Benchmark_guidelines.pdf)
[libnccl-dev_2.5.6-1+cuda10.2_amd64.deb](https://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1804/x86_64/libnccl-dev_2.5.6-1+cuda10.2_amd64.deb)
## GLUE Benchmark (General Language Understanding Evaluation)
### Step1 Download benchmark data
[benchmark data](https://gist.github.com/W4ngatang/60c2bdb54d156a41194446737ce03e2e)
### Step2 Run the downloaded data
run `# python download_glue_data.py --data_dir glue_data --tasks all`
### Step3 Download benchmark codes
run `# git clone https://github.com/NVIDIA/DeepLearningExamples.git`
### Step4 Download BERT-Large model file
run `# https://storage.googleapis.com/bert_models/2019_05_30/wwm_uncased_L-24_H- 1024_A-16.zip
`
---
[Install MOFED](https://community.mellanox.com/s/article/howto-install-mlnx-ofed-driver)

- [x] TensorFlow-GPU installed, with support of NCCL Horovod
- [x] The BERT Large model file
- [ ] The NMLI dataset for fine-tune training tasks
- [ ] MLNX OFED installed
- [ ] A copy of workable OpenMPI-4 at /usr/mpi/gcc/openmpi-4.0.2rc3/bin/mpirun, installed by OFED driver
---
## Three types of model
<table>
<thead>
<tr>
<th>Criteria</th>
<th>Supervised ML</th>
<th>Unsupervised ML</th>
<th>Reinforcement ML</th>
</tr>
</thead>
<tbody>
<tr>
<td>Definition</td>
<td>Learns by using labelled data</td>
<td>Trained using unlabelled data without any guidance.</td>
<td>Works on interacting with the environment</td>
</tr>
<tr>
<td>Type of data</td>
<td>Labelled data</td>
<td>Unlabelled data</td>
<td>No – predefined data</td>
</tr>
<tr>
<td>Type of problems</td>
<td>Regression and classification</td>
<td>Association and Clustering</td>
<td>Exploitation or Exploration</td>
</tr>
<tr>
<td>Supervision</td>
<td>Extra supervision</td>
<td>No supervision</td>
<td>No supervision</td>
</tr>
<tr>
<td>Algorithms</td>
<td>Linear Regression, Logistic Regression, SVM, KNN etc.</td>
<td>K – Means, C – Means, Apriori</td>
<td>Q – Learning, SARSA</td>
</tr>
<tr>
<td>Aim</td>
<td>Calculate outcomes</td>
<td>Discover underlying patterns</td>
<td>Learn a series of action</td>
</tr>
<tr>
<td>Application</td>
<td>Risk Evaluation, Forecast Sales</td>
<td>Recommendation System, Anomaly Detection</td>
<td>Self Driving Cars, Gaming, Healthcare</td>
</tr>
</tbody>
</table>
Goal: 你要辨識出 apple
supervised:
train input: 很多水果照片附上每張是什麼的label
final input: 給我 apple
final output: apple picture
unsupervise:
train input: 一堆水果照片
training 過程中:嘗試output apple, 我們告訴model對不對, model 自己修改權重參數繼續train
最後一樣希望可以辨識apple
啊 reinforcement 我還不甚理解
基本上不會給予訓練的資料,每次讓機器去探索,而探索都會有一個結果,根據結果的好壞機器會自行學習,到最後在==任意==狀態下,機器都有辦法判斷哪一種方法會產生最好的結果
training的過程中,好像不會去告訴model是否正確,這個我覺得應該是機器自己抓取特徵成為它判斷的依據,然而這些特徵是否正確,就要看給定的資料。我看到的資料,會人為介入告訴機器答案的應該是supervised
我猜unsupervised是利用訓練的資料來確定訓練出來就是我們要的結果。
比如說要判斷一個植物是花還是葉
給予的圖片資料裡面讓機器學習出,若特徵是綠色 -> 結果會是葉;若特徵是紅色 -> 結果會是花
如果學習的資料沒有很完整的話,機器可能會判斷錯誤
這兩種最主要的差異在於,資料是否有標記。最主要是當資料太大,要去標記資料會很麻煩
現在好像會採用半監督式(部分資料標記,大部分資料未標記,透過給定現有的標記(pattern),去對未標記的資料進行特徵萃取)
p.s. label tag 應該都差不多,意思到就好
---
## NLP
- Goal: 讓機器學會分析人類語言的語意,可以用來處理大量的文字資料
---
## Transformer Network
### Sequence to Sequence Learning(Seq2Seq)
利用類神經網路,以一段Sequence當作Input(可能是一段句子)透過模型轉換成另一段Sequence作為Output。
Seq2Seq 模型包含Encoder & Decoder
Encoder 負責將Input做轉換,轉換到一個向量空間(n-dimensional vector)
Decoder 再接取那個向量,將其轉換成Output。
Example: 將中文轉換成英文。
Encoder 將中文轉換成一種抽象的虛構語言。
Decoder 接取虛構的語言,再將其轉換成英文。
那Encoder和Decoder怎麼知道要如何轉換成虛構語言/讀取虛構語言,而這就是需要Train的地方。
### Attention
> The attention-mechanism looks at an input sequence and decides at each step which other parts of the sequence are important.
簡單來說,看著一篇文章,你會專注在眼前的詞上,但你的腦中會將這些詞跟先前的詞做比對、組合,藉此了解一段文章的「語意」。
套用在Seq2Seq之中,就會是Encoder在轉換成虛構語言時,不只轉換Sequence至虛構語言,同時會把能夠代表該Sequence之語意的「Keyword」一併轉換過去(可能是透過Weighting Value的方式),Decoder就可根據這些資訊,重建出最符合語意的Sequece。
- Attention Mechanism: Decoder產生輸出時,關注Encoder的輸出,從中獲得上下文資訊
- Self-Attention Mechanism: Encoder & Decoder產生輸出時,會關注自己序列的其他元素,從中獲得文意資訊
- 拿Q對每個K做attention(function有很多不同的做法),產出attention weight vector
- 將attention weight vector帶入sotemax function做normalization
- 將normalization後的weight vector和value vector做內積,產出Output
- Multi-Head Attention:
- Q、K、V再去細分成n個部分,QKV只會對對應的部分作self-attention,目的在於每個細分出的部分所關注的重點不同,可以更詳細的關注自己想關注的重點
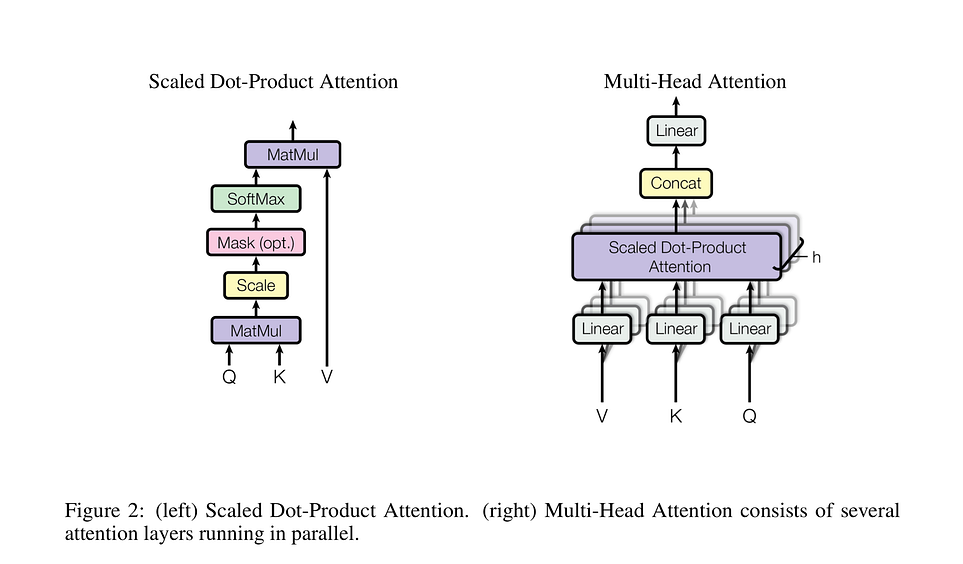
> $Attention(Q,K,V) = sfotmax( \dfrac{QK^T}{\sqrt{d_k}} )V$
- `Q`: Matrix contains the query
- vector representation of one word in the sequence
- `K`: The keys
- vector representations of all the words in the sequence
- `V`: The values
- again the vector representations of all the words in the sequence.
- `d`: dimension of Q and K
### The Transformer
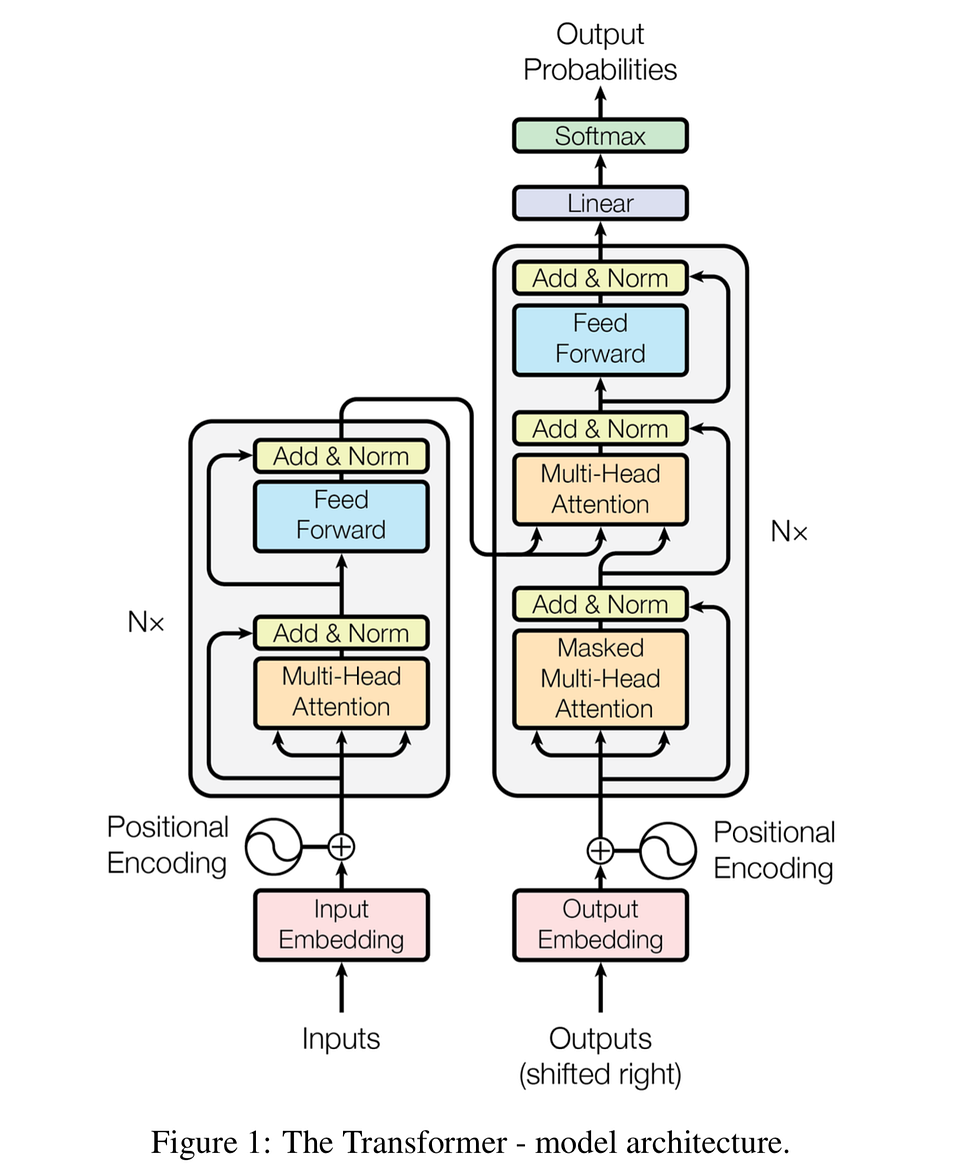
- self-attention的機制讓中間的運算平行化,同時Output也都會看過所有的Input
- 取代RNN,因RNN無法平行運算
- Seq2Seq model + self-attention
- `Nx`: 表示Encoder/Decoder可以相互堆疊N層
- 做N次
- `Pos encoding`: 由於沒有RNN,所以需要利用position對seq的元素進行編號。
- These positions are added to the embedded representation (n-dimensional vector) of each word
- `Add & Norm`:
- `Add`: Attention Input + Attention Output
- `Norm`: 上面加完之後做Layer Normaliztion
- `Masked Multi-Head Attention`: Atten on the generated seq
[尚未整理完](https://medium.com/inside-machine-learning/what-is-a-transformer-d07dd1fbec04)
[Transformer 中文](https://leemeng.tw/neural-machine-translation-with-transformer-and-tensorflow2.html)
[BERT 中文](https://leemeng.tw/attack_on_bert_transfer_learning_in_nlp.html)
[Attention is All You Need](https://papers.nips.cc/paper/7181-attention-is-all-you-need.pdf)
---
## About BERT
**BERT**, or **B**idirectional **E**ncoder **R**epresentations from **T**ransformers, is a new method of pre-training language representations which obtains state-of-the-art results on a wide array of Natural Language Processing (NLP) tasks.
### About BERT Large
- The developer team denote the number of layers (i.e., Transformer blocks) as L, the hidden size as H, and the number of self-attention heads as A. The team primarily report results on two model sizes:
- `BERT-BASE (L=12, H=768, A=12, Total Parameters=110M)` and
- `BERT-LARGE (L=24, H=1024, A=16, Total Parameters=340M)`.
## Terms
- Corpus n. 語言資料庫
- Inference n. 結論
---
## Reference
1. [Supervised vs Unsupervised vs Reinforcement](https://www.aitude.com/supervised-vs-unsupervised-vs-reinforcement/)
2. [What’s the Difference Between Supervised, Unsupervised, Semi-Supervised and Reinforcement Learning?](https://blogs.nvidia.com/blog/2018/08/02/supervised-unsupervised-learning/)
---
### Use `2>&1`
- when you wanna redirect both `stdout` and `stderr` to the same file.
- basically you are saying redirect the `stderr` to the same place we are redirecting `stdout`.
```shell
$ cat foo.txt > output.txt 2>&1
```
> Use `&1` to reference the value of the file descriptor1(`stdout`).
> - this command makes the `stdout` and `stderr` of foo.txt all go to output.txt.
<table>
<thead>
<tr>
<th>file descriptor</th>
<th>std</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<th>stdin</th>
</tr>
<tr>
<th>1</th>
<th>stdout</th>
</tr>
<tr>
<th>2</th>
<th>stderr</th>
</tr>
</tbody>
</table>
[Understanding 2>&1](https://www.brianstorti.com/understanding-shell-script-idiom-redirect/)
## NCCL(NVIDIA Collective Communications Library)
* [NVIDIA](https://developer.nvidia.com/nccl)
* [introduction](https://on-demand.gputechconf.com/gtc/2018/video/S8462/)
### [Horovod](https://horovod.readthedocs.io/en/stable/)
* Horovod is combining NCCL and MPI into an wrapper for Distributed Deep Learning in for example TensorFlow.
* It can detect if GPU Direct via RDMA makes sense in the current hardware topology and uses it transparently.
* [on github](https://github.com/horovod/horovod)
* [Horovod with TensorFlow](https://horovod.readthedocs.io/en/stable/tensorflow.html)
### MPI
* Message Passing Interface
* 訊息傳遞介面是一個平行計算的應用程式介面(API),常在超級電腦、電腦叢集等非共享記憶體環境程式設計。
## BERT Tutorial
[BERT Tutorial](https://drive.google.com/drive/u/0/folders/1aD7GDY2MCq_ZVGk9Rc40QMFpQ_WC06IL)
**BERT** is a Transformer model that:
- Designed to learn powerful methods of encoding representations from text
- Demonstrated state-of-the-art results on many NLP problems in many languages
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet