# Operating System
###### tags: `UCR`
[TOC]
## Executions
* Von Numerman model
* proceesor , memory, Storage, peripherals(IO connectors)
* Oldest: Batch: Process one in a line
* Provide some sort of data storage
* Run until the program finish
* Drawback: Cannot communicate w/ other machine, head-of-line blocking, hard to debug
* UNIX
* Invention of C: Portable, first OS implemented other than assembly
* Support multople users
* Support IPC
* No GUI
* X windows running on top of it(A program not part of the OS)
* Linux is not a UNIX, a copycat
* DOS(Disk Operating System)
## Modern OS supports
* Virtualization
* Program concurrency
* Data persistency
## Virtualization
* Process
* Most important abstraction, may evolve data, is called running program w/ virtualized hardware
* System calls are APIs the processes talk to the underlying machine
* Program in execution
* The state of a process’s execution on a CPU is referred to as process's context
* Memory
* I/O
* Doing a system call
* Disadvantage
* With virtualization, may distrub executions and add overhead
* Advantage
* Run more programs than numver of process
* Virtual memory
* What happened when creating proess
* Program contains basic areas including data and codes
* Dynamic data: get down from heap
* While stack grows up
* OS responsible for manage virtualized resource usage
* Stack pointer, program counter, Process state
* Because each processes has their own set of the above data
* OS has PCBs(Process control block)
* Containing info neccesary to manage process
* mm_struct: reponsible for memory
* start_blk, blk: dstart end of the heap
* start_stack: Current stack pointer (starts at very end address space, than no end pointer is nedded)
* `thread_struct`: Stores X86 register values and program counter
* Not every instruction should be done via system call
* Restricted operations: User mode and kernel mode
* Privilege operations (System calls)
* Involves HW other than CPU
* Procedure
* Initiate a trap, raise exceptions
* Store the PC
* Jump to kernel privilege mode
* System call handler executed
* CPU support
* Normal: ADD, MUL
* Privilege: Setting timers
* Should be a little as possible, **not a process**
* It's responsible for context switch
* When switching to kernel mode, the process is still the same
* Run only when necessary
* System calls (Liking calling special functions, a special interface to switch to kernel mode)
* Hardware Interrupts
* Exceptions
* It takes a hundred machine cycles to do context switch
## Paper Reading
### THE Operating system
* Impact
* Process abstraction
* Hierarchical system designed
* Virtual memory
* Mutual exclusive
* Abstract (Contributions)
* Short duration
* Improve utilization of periphral devices
* Improve turnaround time
* **No multiaccess**
* Devices
* Drum -> Hard disk
* Core memory -> memory
* Layers Design
* Facilitates(simplify) debugging and verification
* Scheduling takes place on layer 3 for I/O and peripherals
* Why I/O layer on top of interpreter layer
* You need a command to launch a program
* Problem
* What if program of processor allocation/scheduling needs more memory?(No in THE)
* At most support 5 processes
* That's why strict layer design is bad
* Overhead in each layer
::: info
Why Internet has layer?
Layered design is good for debugging and verification
Everyone fullfill a specific layer and can be put toghether
:::
### Hydra
* A microkernel
* Proposed
* Rejection strict hierarchical layering
* Support multiple processors
* **Flexibility**
* Reliability
* Seperation of mechanisms and policies
* Mechenisms are provided by operating systems, but policies are not
* In THE, scheduling cannot be changed
* Why
* HW efficiency/ utilization
* Facilitates construction of an environment for flexible & secure
* Kernel
* Not in THE
* Policy (What to do)
* LRU, FIFO
* Mechanism (How to do)
* Preemptive scheduling, paging, capability
### UNIX: Time-sharing system
* A **Monolithic** kernel, implements everything in the kernel
* Including old BSD
* Kernel Program
* Have to rebuild a kernel
* Modify the kernel code
* Why built UNIX?
* Reduce the cost of building machines with Powerful OSes
* Perhaps the most achievements...
* Easier to modify, reduce the burdun to maintain the OS code
* Bit the size is larger
* Proposed
* Providing a file system
* **Files** as unifying abstraction
* Directories are still "files" (Because in Unix, everything is a file)
* Change to filesystem requires privileges and kernel maintains filesystem, so altering the content of directories needs are privileged operations
* Only 3 kinds of files
* Ordinary Files
* Directories
* Special Files
* **Doesn't care about content**
* Devices are files
* Protection
* Unix implements owners and non-owners
* The same file may have different permissions for different user-id
* The owners may not have permission to access their files
* set-user-id, temporarily amplify the permisssion of the user
* Contains 3 types of user(2 in the paper), associated with each file
* Inside UNIX Kernel
* I/O device drivers
* **File system**
* Virtial memory management
:::info
Shell is a user program
:::
* With set-user-id, others can read the content
### Mach
Strongly affected by Hydra, Object-Oriented
Basic abstraction is a **memory object**
* **Microkernel**, discouraging user to touch the kernel
* Design concerns
* Flexibility / Extensibility
* Easy Debugging
* Kernels contains
* I/O device driver
* Virtual memory Management
* IPC
* Multiprocess scheduling
* Unix traps
* Purpose
* Allows kernel debugging
* (hardware changing) Start to have **multiprocessor** and **network computing**
* Modern UNIX systems do not have a consistent interfaces
* Extent the service of user space, file system is not in the kernel
* Port/Mesage
* Message queues
* Capability (for network communicate)
* Every communication goes through capability, so its secured
* Enables privilege amplification
* Associated with each object, embedded in the memory space of each object
* Can set the permission on functions individually
* What is capability:
* An access control list associated with an object
* A reference to an object and A list of access rights
* Location independence, abstraction for both local and remote communication
### An experimental time-sharing system
* Why multi-level scheduling
* Optimizing the response time for short program, only a set of program(user process needs interaction)
* But the time can be twice as much as perfect round-robin
* Only improve turn-around time when the queue is saturated
* Give priority to short process, thus **not fair**
* System saturation
* The demand of computing is larger than the physical processor resources available
* Service level degrades when
* Lots of prgram swap in-and-out (context switch)
* UI response time is bad
* Long running tasks cannot make good progress
* Decide which queue a new process should go
* Each queue still uses round-robin
* Depending on the program size
* Start in initial assigned queue n
* Run for 2^n quanta (Where n is current depth)
* If not complete, move to a higher queue
* Lower n has higher priority
* **Not optimized for anything**
### Lottery Scheduling
* Goal
* Quality control
* Flexible, Responsive
* The overhead of running algorithms is high
* How
* Overhead: 1000 instructions
* Flexible: allows Monte-Carlo
* Ticket transfer: client-server
* Impact
* Buy "times"
* Bad for following applications
* real-time
* Event driven
* GUI based
#### ticket Abstraction
* Propotional fairness
* Machine-independent
* Generic scheduling policies among different device
* Starvation free
### Kernel threads
* vs user-space thread
* User space thread
* Pthread
* Pthread_lock
* Same process, **no context switch**
* Only 1 scheduling identity regardless of number of threads
* A thread can block all other thread
* The library can be implemented without modifying the kernel
* Kernel threads: process is a macro, scheduling can be controlled directly.
* Synchronization: system call
* OS kernel treat each kernel thread as a scheduling identity
* Linux implementation: tasks
* Scheduler Activations:
* Upcalls, Downcalls
### Virtual memory management in the VAX/VMS Operating system
* Whys
* The system needs to execute various type of applications efficiently
* The system runs on different types of hardware
* System use FIFO page replacement
#### Goals
* Reduce startup time
* copy-on-reference
* Originally, point to the originally location and create a PCB
* If a child has a write, start copying to the new pages and update them later on
* Isolated from that time on
* Demand zero
* Write a memory page to contain just zero
* Don't create a page with real content
* Process performance interference
* Local replacement policy
* vs. Global replacement policies: Can kick out memory of other processes
* A working set for a process: The process can use only limited amount of memory
* Swap onlt the pages associated with the process
* Page local disk read
* Page clustering
* Reading or writing more data together bring more bandwidth
* Combining consecutive writes into single writes
* Page caching (not put back to the disk directly)
* Evicted pages will be put into one of the lists in **DRAM**
* Modified List: Dirtied pages needs to copy data into the disk
* Free List: Clean pages
* With Free List and Modified List, LRU and FIFO has similar performance
* Reduce page lookup overhead
* Segmented memory Layout
* Each segment has own page table And **Entries between stack and heap boundaries do not need to be allocated** — reduce the size of page table
* No hardware support for VAX machine
### UNIX VM Page Replacement
* **Clock Algorithm**, a circular queue
* Requires **a reference bit**, not timestamp
* Page Replacement when
* VMS swaps out all memory page belong to a process when that process is switched out
* Free List
* When we need a page, take one from free list
* A list of pages the system maintains
* Where the requested page be put
* Improves page fault latency, but **does not reduce the latency of swapping out the page**
* Depending on how fast the disk is
* If the threshold is low, swap out pages even without page fault, trigger clock algorithm
* Let's why make it global, not local working set(resident set)
* Don't guarantee response time
### WSClock
* Using working set policy to decide hoe many pages can a process:
* if lower than threshold it will do replcaing
### Work set algo:
* even if no page fault, it wil evit the less used page
### Local , global:
* local:
* VAX/VMS
* Original UNIX
* Global:
* UNIX after Babaoglu
* Mach
### A Fast File System for UNIX
**Optimize reads, not write**
#### Why FFS
* Better performance
* New features
* Problems with old file system
* Lots of seeks when accessing a file
* inode are separated from data locations
* Data blocks belongs to the same file can be spread out
* Low bandwidth utilization
* Limited file size
* Crash recovery
* Device oblivious
#### New features
* Quotas
* Renaming
* Cylinder groups
* Stores
* inode
* data
* Redundant copy of the superblock
* Bitmap of the free blocks in the cylinder group
* Contains one or more consecutive cylinders on a disk
* Stores Redundant copy of superblocks
* Disk Recovery
* Don't have to move the head to other position
* Improve average accessing time
* Improve
* seek time
* Rotational delay
* Larger block size
* Each files can only contains a fixed number of data block
* Cannot fully utilized the I/O interface bandwidth
* Limited the size of the file
* Support **larger** file
* Improve bandwidth
* Fragments
* Addressable unit in the block
* Allocates fragments from a block with free segments
* Replicated superblock
* For **data recovery**
* Pre-allocated blocks
* Improving write performance is **NOT Included**
* Reason: Only 10% benefits, but GPU usage will be higher
* Allocators: Try to allocate inode to the right cylinder group
* Global Allocators
* Allocates inodes to the same file together
* Local Allocators
* Alllocate data blocks upon the request of the global allocator
* Do not use hard link(Symbolic links)
#### Problems
* Data are spread ot the whole disk
* Directories may not be in the same cylinder group
* Write to metadata is synchronous
#### Compared with UFS
* Old UFS
* Reading is not faster than writing
* BSD FFS
* Writing is slower than reading
* But writing in FFS is still better than writing in UFS
* Better CPU utilization (95%)
* Better bandwidth utilization
### The design and implementation of log-structure filesystem
Optimize for write, but also improve read
#### Why LFS
* Optimize to small random write
* Small file access
* As system memory grows, frequently read data can be cached efficiently
* Modern OS aggressively cache: Use "Free" in Linux to check
* For large file, left for hardware designers
* However **increase** the space overhead of metadata in the file system
* inode map
* Garbages: Deleted data are not erased immediately, just invalidated
* Conventional filesystem are not RAID-aware
#### What LFS propose
* Buffer writes to main memory
* Can have multiple logs for disk
* Aggregate small writes together to a Consecutive data chunk
* inode next to the data chunk
* Has a pointer pointing to inode map
#### Segment cleaning / Garbage collection
* Reclaim invalidated segment the
### enVY (improve flash MEM)
* Proposed
* Exactly like LFS
* Garbage collection
* Cache
* Page remapping
* Transparent in-place update
* Good idea for SSD
* Larger block size
* Reading can be parallelized
* Bad ideas
* Logs
* Fragment doesn't help because the bandwidth is large enough (Granularity)
### Don't stack the log on my log
* Duplicated function in different layers
* FTL
* Since flash devices contain a remapping log-like FTL, any log-structured application run atop a flash device creates a stacked log scenario, making such scenarios now more common
* Example: Spotify
* Keep writing new music to the buffer
### Google File System (Flat file sys,Hierarchical namespace implemented with flat structure)
* Every directory is a illusion
* Optimized for
* Large files
* **Don't care** small files
* Sequential and random reads
* Bandwidth, not access latencies (process bulk of data, just a few individual write)
* Build from **inexpensive commodity components**
* Focus on data center (bandwidth)
* Prposed
* Maintaining the same interface
* The same function call and hierarchicals directories/files
* Files are decomposed into large chunks with replica
* Hierarchical namespace implemented with flat structure
* With replicas(duplicate another files)
* Done asynchronously
* Master, Chunkmaster and clients
* Why larger chunk
* Many larger files
* Primary reading stream of data
* Sequential append to the end of the file
* Bandwidth is more important than latency
* No granularity (multi concurrent operation is not good, think about producer and consumer, and each item has its own locks, if we sperate large chunk into small piece ,but sequential read ?!....)
* Flat file system structure
* Support concurrency operation
* If not, have to lock every inode of directory
* Improve both latency and bandwidth
* GFS chunkmaster
* Only one active server, but has other shadow server
* Purpose: Save money
* Chunkserver has 3 replica (can have same data in another chunkserver)
* Chunkserver has multiple purpose(can be the client on the same machine), not dedicated for data storage
* Every price of data has replica
* Only control flow goes through master server
* Clients
* **Cannot** cache the data
* Otherwise, there may be inconsistencies issues
* Redirect request to the master
* Pick one of the chunk to access
* Achieve load balancing
#### Downside
* Single Master, limited scalability
* Relaxed Consistency Model
* Applications have to deal with consistency by themselves
* No geo-redundancy (eletricity of U.S.A)
* Linux problems
* Driver issues: Not report their capabilities honestly (s.m.a.r.t)
* Cost of fsync: Proportional for file size
* Single reader-writer lock for `mmap`
* Evolution
* Now has multiple master servers
* Now has to support small files
### Windows Azure Storage
* Reason: XBOX, video........., must tolerate many different data abstractions
* Why
* Strong consistency
* Global and scalable namespace/ storage
* Disaster recovery
* Multi-tenancy
* Proposes
* Storage stamp at additional layer
* Functions like GFS (3 replicas, 3 extent node)
* Stamp is the basic granularity of storage provisioning, fault domain, geo-replication
* Universal Resource Indicator
* Achieve load balancing by domain name services returning different address at different time
* Stream
* A stream is a list of **extent pointers**. An extent consists of consecutive blocks
* Some is sealed(**Immutable**), some are not
* Each block on the stream contains checksum to ensure the data intergrity
* Read the whole block everytime
* An update to the stream can only be **appended** to the end of the stream
* Copy-on-Write, like LogFS
* 2 streams can share the same set of extents
* That's why streams are implemented with pointers
:::info
Why sealed and append-only?
* Stream consistency
* Disaster recovery
* Lower cost
:::
* Sealing is to keep the data consistency
scalability: add more, improve more, like a straight line
### F4: Facebook BLOB storage system
#### Haystack
* With CDN, is fast enough, otherwise goes to NFS based Haystack
* With volume(a large file) and offset, only one access to retrieve metadata and actual data
* Also has sealed, which is immutable (WAS microsoft)
* Consistency model not mentioned
* Optimized for most frequently used data
* RAID-6
* 3 replica
* Goals
* Reduce the degree of data replication
* Support more types of fault tolerance
#### F4
* Unlink GFS and WAS, treat different files differently
* **Not for long-term cold data**
* Social network has temperature, warm data
* Optimized for
* Read-only data (Because focus on warm data)
* Storage Efficiency
* Reed-Solomon erasure coding
* 100G data + 4GB parity, one volume contains 10 strips
* XOR Geo-replication
* Exclusice OR with other blocks
* 1.4*1.5 = 2.1x space efficiency, instead of 3
* Fault Tolerance
* If the rack fails, recover from other racks, with XOR
* Drive fails
* Reconstruct blocks at another drive
### Google cluster architecture
* Design Philosophy
* Reduce hardware cost with commodity-class and unreliable PCs
* No **RAID**, use replicas for better throughput and availability
* Optimize performance per dollar
* **Cost-effective**
* Replication is the key
* Scalability
* Availability
#### Hardware
* Processor requirements
* **No SIMD**, not so much instruction-level parallism
* Google takes different part of keywords into hashing
* Searching is not a compute intensive task, why Dell PC can work out
* Simultaneous process/thread
* Can predict branch outcome accurately
* Small amount of cache, otherwise it would be expensive
* Memory with good spatial locality
### Xen and the art of paravirtualization
* Ballon driver
* Xen implements a balloon driver to lend resources from one guest OS to another in the case that there is an excess of resources with one OS, and a demand for resources in another OS.
* Adjusts a domain’s memory usage by passing memory pages back and forth between Xen and XenoLinux’s page allocator.
* Circular queue
* A ring is a circular queue of descriptors allocated by a domain but accessi- ble from within Xen.
* Allocated out-of-band by the guest OS and indirectly referenced by I/O descriptors
* based around two pairs of producer-consumer pointer
## Design philosophy of operating system
* Metrics
* CPU Utilization: How busy we keep CPU to be
* Latency
* Throughput
### Threads and Processes
#### Threads
* They all share memory
* Lower latency
* Create virtual registers and program counter for CPU abstraction
* Its possible to hit the limit of address space
* But with X86_64, the space is much larger than before`
* The stack section (local variable) are still not shared by them
#### Processes
* Every process have its own page table
* Duplicate everything
* Safer, more stable than process
* An abstraction of the whole machine
* Virtualized memory, IO, CPU
* **No shared memory**
* Parents and Child processes
* Communication
* IPC
* Pipe
* Files
* Sockets
* Needs kernel switch
* To share memory, need special library, like boost in C++
* Zombie
* The parent doesn't call `wait` when the child process exits
* Can't be kill normally
* Orphan
* Process whose parent has exited before it exits
* Will adopted by `init`, which calls wait periodically
### System calls
* `forks()`
* Return 0 to the child, child pid to the parent thread
* Does not start a new program, just duplicate the current program
* `exit()`
* If parent exits, then child also stops
* `execvp()`
* it dose not "create" new program
* Overwrite process's address space
* Reuse current process
* Why seperate `exec` and `fork` in Unix
* Flexibility
* Allows redirection & pipe:
1. After fork, the shell can setup any appropriate environment variable before exec
* `wait()`
* Suspends process until a child process ended
* Resume when any child ends
:::info
Implement a shell
* Normal
* fork
* exec(cmd)
* Implement redirection
* fork
* The forked code does the following
* opens b.txt
* dup the file descriptor
* assigns b.txt stdin/stdout
* Close b.txt
* exec
:::
### Thread Programming
* Processor/Compiler may reorder active processes/threads that share one or more resources
### Synchronization
* All threads share the same page
* Critical Section
* A policy Implemented to guarantee only one thread is allowed in the critical section
* Enforce mutual exclusion
* Solution
* Mutual exclusion
* Progresss/Fairness
* A threads outside of its critical section cannot block another threads from entering critical section
* A thread cannot be postponed indefinitely from entering its critical section
* Accommodate nondeterminism
* `pthread_lock()`
* Drawback: Frequently lock & unlocks
* Advantage: Guarantee fairness
* spin locks
* Keep tracking a shared variable.
* Problem
* High CPU load (when looping)
* Context Switch may occur between getting lock and setting lock, and other process may check the lock and enter critical section.
* May result in several threads go into critical section
* Disable Interrupts (no context switch anymore) will cause
* A thread cannot be postponed indefinitely from entering its critical section, because the process my die in the critical section
* Solution: Need **automic instructions**, architecture dependent
* One reason we need assembly
* Semaphore
* A synchronization variable
* Tell how many variable are allowed
* Has an integer value
* `sem_wait(S)`: If S > 0, thread proceeds and decrement S. if s == 0, process goes into waiting state and placed in a special queue
* `sem_post(S)`: If no one waiting for entry, increment S.
* If set maximum to 1, it is equivalent to a lock. (The way modern operating system implement locks)
* Bounded Buffer Problems
* Locks will cause only produce and consume
* Busy waiting time is limited
* Example Poll
* Parent is the producer, which put stuffs into the buffer, child is the consumer taling values out of buffer
* Because `empty` tells how much is not consumed
### Types of kernel
* Monolithic
* BSD and Unix
* Microkernel
* Hydra and Mach
* Probably more stable than molithics because of fewer lines of codes
* Worse application performance than monolithic kernel
* Systems calls in microkernel must go through traps, just to call another user space process,
* Too many **Context Switches**, for example, opening a file
* Modular kernel
* Reason
* Still loads certain code into kernel space, so **still same process**
## Scheduling
* Cooperative Multitasking
* Cannot be preempted
* The process is in cooperation with the kernel
* The OS can change the running process if the current process
* Gives up the resource
* Raises an exception or traps into OS kernel
* The processes voluntarily give up, error, trap, otherwise, can not be stopped
* Preemptive Multitasking
* Need HW support
* The OS controls the scheduling
* **interrupts** are used to support preemptive multitasking
* Setup a **timer** event before the process start running
:::info
* Exception: Raisd by the **processor** itself, e.g. devided by 0, unknown memory address
* System calls: Raised by the applications
* Interrupts: Raised by the hardware
:::
* Context Switch Overheads
* Overheads between process in round-robin
* Utilization is low if switch frequently
* No process can make progress
### Policies
* Non-Preemptive
* FIFO
* Shortest Job First(Not realistic)
* Preemptive
* STCF(Not realistic)
* Round Robin
* Time
* Turn-around time: Time between submission/arrival and completion
* Response time: Time between submission and job and scheduling
## Virtual Memory
* Why
* Program may not fit memory
* Run program on computers with different memory space
* An abstraction of memory space
### Segments
* Compiler generate virtual address
* The OS works with hardware
* Needs to occupy consecutive space
* Saving the base address
* Problems
* Malicious program request address belong to another process
* Solution: Meed boundary registers
* Generate segmentation fault beyond boundaries
* OS handles this by killing at most of the time
* External fragmentation
* Leftover Memory space may not be continuous
* Internel fragmentation
* A large amount of allocated but unused memory
### Paging
* Paging
* Page fault
* A requested virtual memory page cannot be found in the physical memory page
* Demand Paging
* Allocate a physical page for virtual memory page when the virtual page is needed (Page fault occur)
* Shadow paging:
* load the whole program/data into the physical memory when you launch it (embedding sys)
* Word: The width of the register
* Depends on architecture
* Calculate size of page table
* 4Bytes * 2^32^ / 2^12^ = 1MB * 4 = 4MB
* 2^64^(64-bit address)/2^12^(4KB page table size)*2^3^(Each page table entry has 8 bytes) = 2^55^ in PB scale
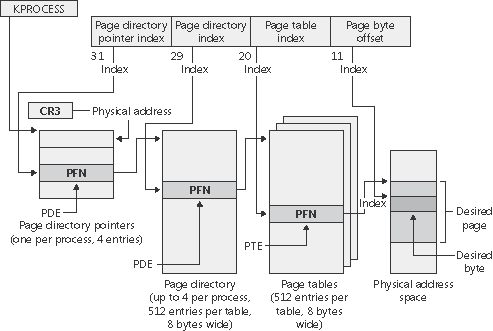
#### Hierarchical page table
* Walk down the tree to translate the virtual page
:::info
* Page table size example
* 50% memory pages are used, PTE size is 4B, 2-level with 4KB page, 32-bit
* 50% set valid
* 2-level doesn't matter
* 2^10^/2(50% usage)*2^12^ = 2^21^
:::
:::info
How many levels do we need for 8B PTE(Because of 64-bit to translate), 64-bit virtual address space and 4KB page size?
* Solution
* Each entry is 8 bytes, a leaf node will be 4KB(**one page long**)
* 2^12^/2^3^ = 2^9^, 9 bits index to locate, 2^9^ entries
* 6 levels, every entries is 8 bits long
:::
* x86_64
* At most 2^48^-1, 48 bit address space, each 9 bits, use 4 levels
* Benefits
* Reduce the size of page tables
* Drawbacks
* **increase** memory acccess
* Add overhead of page fault
### Paging vs Segementation
* Segments cause more external fragmentation
* Paging can still cause internel fragmentation
* Demand paging: May be (`page size`-1)
* Segment: Larger memory size will be allocated
* The overhead of paging is higher
* Consecutive virtual memory address may not be consecutive in physical address if we use demand paging
### Swapping
* Demand paging + Swapping
* Create swap space on secondary storage (Usually on the disk)
:::info
Swapping overhead is 100x when there's no page fault(Given 0.1% page fault probability)
:::
* Processes will share the same memory space
### Page replacement policies
* Local
* Prevent thrashing
* Used by
* VMX
* Old Unix
* Global
* Simplicity, adaptive for process demand
* Used in
* UNIX
* Mach
### Degree of Parallelism
* System spends more time on
* Busy swapping in/out, paging
* CPU will mostly Idle, because cannot meaningful stuffs, called **thrashing**
* When memory are overcommitted
* Beginning at increasing utilization
* Decrease utilization at some point
* CPU has to wait for data
* Saturation
* When processors are overcommitted
* Busy context switching and scheduling
## I/O
* In each devices
* AICS
* Micro-controller
* Memory
* Registers
* Command
* Status
* Data: The location of exchanging data
### Interrupts
* The device signals the processor only when the device requires the processor/OS handle spme tasks/data
* Improve CPU utilization if device need only service occasionally
* via Context Switch
* Cache warm up cost when you switch back
* TLB warm up cost
* If there's no context switch, CPU is idle
* Will drop CPU frequency, **decrease power consumption**
* Increase **latency** of applications and **cache miss rate**
* Worse than polling
* Allow asynchronous I/O (Blocking)
### Polling
* The processor constantly ask if the device is ready to to or requires the processor/OS handles some tasks/data
* The OS executes corresponding handler
* Generally consume more CPU time
* Better to apply polling on **faster** device
:::info
The instructions for both polling and interrupt are the same
Sometimes the device supports both mode, let the developers to choose
:::
## Hard Disk
* Position the head to a proper track (**seek time**)
* Rotate to desired sector (**Rotational delay**)
:::info
latency = seek time + rotational delay + transfer time + controller overhead
:::
* Good at reading **sequential** data
* Only wait one rotational delay
* More bandwidth
* Each sector gets a number
### File System
* Run in kernel mode
* Independent IO interfaces(*e.g.* ioctl) between file system and drivers
* Hierarchical
* Links breaks the tree analogy
* Mount
* Original UNIX
* Create a superblock to store the metadata of the whole file system
* Stores
* The volume size, number of node
* inode
* Store the metadata of a file
:::info
Number of disk accesses for `/home/hungwei/CS202/foo.c` in old UNIX
* Go to superblock, find inode of `/`
* Go to inode, fetch content
* Total access time: `11`
:::
## Abstractions
* Process
* Thread
* Files
## Modern Filesystem
* Conventional Unix inode
### Extented File System
* Extents (Why called Extented)
* the file resides in several group of smaller continuous address
* The flash memory chip has limited number of erase cycles
* Reading
* Still consider device oblivious
* Use block group
* Metadata and actual data together
:::info
Why not cylinder group?
Directories and files may still far away
:::
* FIBMAP
* Implemented like a linked list
* Write-ahead log
* Write to log first
* Write to the actual disk when there's enough bandwidth
### Flashed based SSD
* The writing is 100x slower than reading
* The granularity of writing and erasing is different
* Erase must be performed by block, write and programming can be 4K
* Cannot be written without erasing (the update of MEN is slower than conventional MEN)
* Has limited number of cycles for erasing
* When all cells are programmed, erase a block
* Desity of the cell
* MLC: Multi-level cell, there are 2 bits in cell
* TLC: 3 bits
* QLC: 4 bits
* How to modify the data
* Steps
* Copy the whole block (Read)
* Write to another block
* Erase the block
* Drawbacks
* Bad performance
* Consume erasing cycles
* Solutions: Flash Translations Layer
* Find a free space
* Modify mappings data
* Append to the end
* Invalidate original pages, so **Garbage Collection** is needed
* FTL(Flash Translations Layer)
* Maintains the abstraction for LBA
* So SSD requires a processor
* Improvement
* Write asynchronously
* Need RAM buffer
* Out-of-place update
* Update at different locations
* Prealloc locations for writing data
* Fragment is not help, because SSD write big, but fragment is wrote by units.
* log "may not" suit to solve the problem, because it will let the underline be "indirect" and waste space
:::info
For HDD, write to the same chip is a good idea (**cylinder group**)
But in SSD, it's bad in terms of Parallelism
:::
### UFS, FFS, LFS, UeFS, Log on Log
* old unix, do not have resident set
* not guarantee the respond time of short program
* ExtFS -> Block group
* old unix -> cylinder (HDD)
* FFS+Extent+(write-ahead log),
* 1. write: log area, 2. rearrange
* log structure, small write
## Virtual File System and network file system
* Run on top of device I/O interface
* Must support open, close, read, write
* Request may goes to the underlying NFS
* Go down to hardware, NIC, then communicate with another machine running NFS server
* Go through many layers on NFS server
::: info
Find `/mnt/nfs/home/hungwei/foo.c` from NFS, mounted at `/mnt/nfs` start to count at home
Needs **12** trips
:::
### Original NFS
* Stateless design
* Simplify the system design for recovery after server and client crashes
* Just boot the machine, launch the server, done (No overhead)
* If stateful, no one can recover it
* But bad for file consistency (**No record**)
* Idempotent Operations: the result opertion is not affected by the previous same operation given same input
* Only needs to retry the same operation if it failed
* How does server get information?
* Flush-on-close
* Later open opertations will get the latest content
* Force-getattr
* Open a file requires getattr from server to check timestamp
* NFS to GFS....
## Virtual Machines
### Taxonomy
* Processor virtualization
* Java VM
* System virtualization
* Same ISA (Instruction set architecture)
* VMM: Xen
* Hosted VMM: Virtualbox
* Old ISA
* Binary translator
* Game emulator
### VMM
* Should Provides
* Fidelity: Not aware of running as a virtual machine
* Performance
* Safety & Isolation
### Types
* Hosted VM
* Virtualized network, storage in VMM
* Run on top of hosted operating system
* VMM on bare machines
* Bootloader boot the VMM directly
* VMM launch instance for other guest OS
### Main ideas
* Deprivilege
* x86
* Trap-and-emulate
* Guest OS run on reduced privilege mode
* Use trap handler
* VMM(monitor) running in privileged mode
* More layer of page table and the address translation, by TLB
* With shadow page table, it is the short cut of translation)
* Shadow page table
* Tracing (when it is need to trace the update)
* Make shadow page table consistent with guest OS page table
::: info
Why doesn't work with X86
* The guest knows it has been depriviledged
* Violate fidelity
* A privileged instruction in girst OS may trigger a trap
Note: x86 support write-protected page
:::
### Binary Translation
* VMM examinated every instructions in near future by prefetching and reading instructions from the current program counter
* Modern X86
* Virtual machine control block
* Save required data structure (create the copy of snapshot befor enter)
* Hardware-assisted
* vmrun
* An instruction to enter VMX mode(in the middle of user and kernel)
* Update VMCB
* Create another mode in addition to user and kernel mode
* What VT-x help
* Execute system call to reduce overhead (by picture)
* Help calling a funciton
::: warning
Handling page fault does not need BT
:::
### Paravirtualization
* Avoid binary translation
* Using Xen
## Compyter System Design
* Seperate the worst case and the best case:
* Facebook f4 , (hot data) haystack, (warm data) f4
::: info
Google GFS doesn't care for consistency
Azure Storage only focus on worst case
:::
* Saturation and Thrashing
### Interface
* Keep it simple and stupid
* Don't generalized
* Negative example: emacs, mapping virtual pages to file pages
* Do one thing at a time or do it well
* Get it right
* Fast rather than general or powerful
* RISC is preferred than CISC
* Don't hide power
* Use FTL, which ignore parallelism, on flash memory
* Use procedural arguments to provides flexibility in an interface
* Leave to client
* Keep basic interface stable
* Not changing interface
* Negative example: Nvidia always change CUDA interface
* Keep secret of the implementation
* A black box
### Speed
* Split resource in a fixed way
* Static analysis
* Use batch processing
* Page cluster
### fault-tolerance
## Final Exams
### Programming
* Implement binary trasnaltor in C
### Xen and the Art of Virtualization
* Implement baloon driver
* Adjusts a domain’s memory usage by passing memory pages back and forth between Xen and XenoLinux’s page allocator
* Implement circular queue
* Access to each ring is based around two pairs of producer-consumer pointers: domains place requests on a ring, advancing a request producer pointer, and Xen removes these requests for handling, advancing an associated request consumer pointer. ( Respond placed back, save with **Xen as the producer** and the **guest OS as the consumer**)
*
### Simultaneous multithreading: maximizing on-chip parallelism
* scheduling instructions onto functional units
* using the Multiflow trace scheduling compiler to solve the intruction avability for next cycle.
### Machine-Independent Virtual Memory Management
* explore the relationship between hardware and software memory architecture
* to design a memory management system that would be readily portable to multiprocessor computing enginesas well as traditional uniprocessor
* pros : needs no in-memory hardware-defined data structure to manage virtual memory
* cons : large amount of linear page table space required for uniprocessor makes the system more complex. Don't support consistency for multiprocessors
## Short Q summary
* What is saturation?
* In the paper, An experimental time-sharing system (multilevel scheduling)
* When CPU are overcommitted, and ends up being busy context switching and scheduling
* What is thrashing?
* In the paper, WSCLocak - A Simple and Effective Algorithm for Virtual Memory Management
* When memory are overcommitted, CPU usage is low
* Which paper is about microkernel design?
* Mach
* Which paper talks about capability
* Hydra
* Which paper mentioned TLB (like a cache)
* A Comparison of Software and Hardware Techniques for x86 Virtualization
* hardware-assisted guest execution, the TLB contains entries mapping guest virtual addresses all the way to host physical addresses.
* Sotfware BT
1. Trap elimination: adaptive BT can replace most traps with faster callouts.
2. Emulation speed: a callout can provide the emulation routine with a predecoded guest instruction, whereas a hardware VMM must fetch and decode the trapping guest instruction to emulate it.
3. Callout avoidance: for frequent cases, BT may use in-TC emu- lation routines, avoiding even the callout cost.
* Cons: require careful engineering
* Hardware
1. Code density is preserved since there is no translation
2. Precise exceptions: BT performs extra work to recover guest state for faults and interrupts in non-IDENT code.
3. System calls run without VMM intervention.
* Cons: need a higher cost for the remaining exits
* What is garbage collection? Which paper uses that? (Need to add)
* Not erase immediately, just invalidate, Reclaim invalidated segments in the log once the latest updates are checkpointed
* Paper: The design and implementation of log-structure filesystem , eNvy
* Virtual memory management in the VAX/VMS Operating system (Need to add)
* The list to store the clean page's pointer, usually used for dynamically allocate the MEM
* Which paper is designing FS for write-intensive data access?
* oldFS ?!
* Which paper is designing FS for read-intensive data access?
* FFS ?!
Because of speed?!
* Which paper is designing FS for MapReduce?
* GFS
* What are the three important properties that virtual machines need to hold?
* Fidelity
* Performance
* Safety & Isolation
* Diskless sys
* NFS, maybe Windows Azure storage
* Distributed V kernel
## OS Project Reference
* [Memory mapping and DMA](https://www.oreilly.com/library/view/linux-device-drivers/0596005903/ch15.html)
* [Kernel Driver mmap handler](https://labs.f-secure.com/assets/BlogFiles/mwri-mmap-exploitation-whitepaper-2017-09-18.pdf)
* [Process Address Space](https://medium.com/hungys-blog/linux-kernel-process-address-space-9c6b0a89ac6a)
* [Memory Mapping from Kernel to user](http://www.discoversdk.com/knowledge-base/mapping-memory-from-kernel-to-user)
* [`remap_pfn_range()` techniques for vmalloc non physically continuous allocation](https://www.cnblogs.com/pengdonglin137/p/8150462.html)