2020-01-06 筑波大学 R予習
====
筑波大学の皆様、こんにちは、陳姿因です。
時間を含む実験データ(眼球運動や脳波計測など)をどう処理すればよいかと悩んでいらっしゃいますか?
1/22に筑波大にお邪魔して、最新技術のpermutation analysisについてお話しさせていただきます
**レジュメ**はこちらから:https://hackmd.io/mW1PE170TkCfdScLHYNV2Q?view
その前に、ウォーミングアップとして、以下のコマンドをR上で実行してみてください
# 1.Rのインストール
まずRのホームページから最新版のRをインストールしてください
https://cran.r-project.org/
- Windowsの方: Download R for Windows>base>install R for the first time
- Macの方:Download R for (Mac) OS X>Latest release>R-3.6.2.pkg
(参考)Rのインストールの仕方【Windows版】
https://to-kei.net/r-beginner/r-install-windows/
(参考)Rのインストールの仕方【Mac版】
https://to-kei.net/r-beginner/r-install-mac/
↓こちらの画面が出たらインストールが成功です
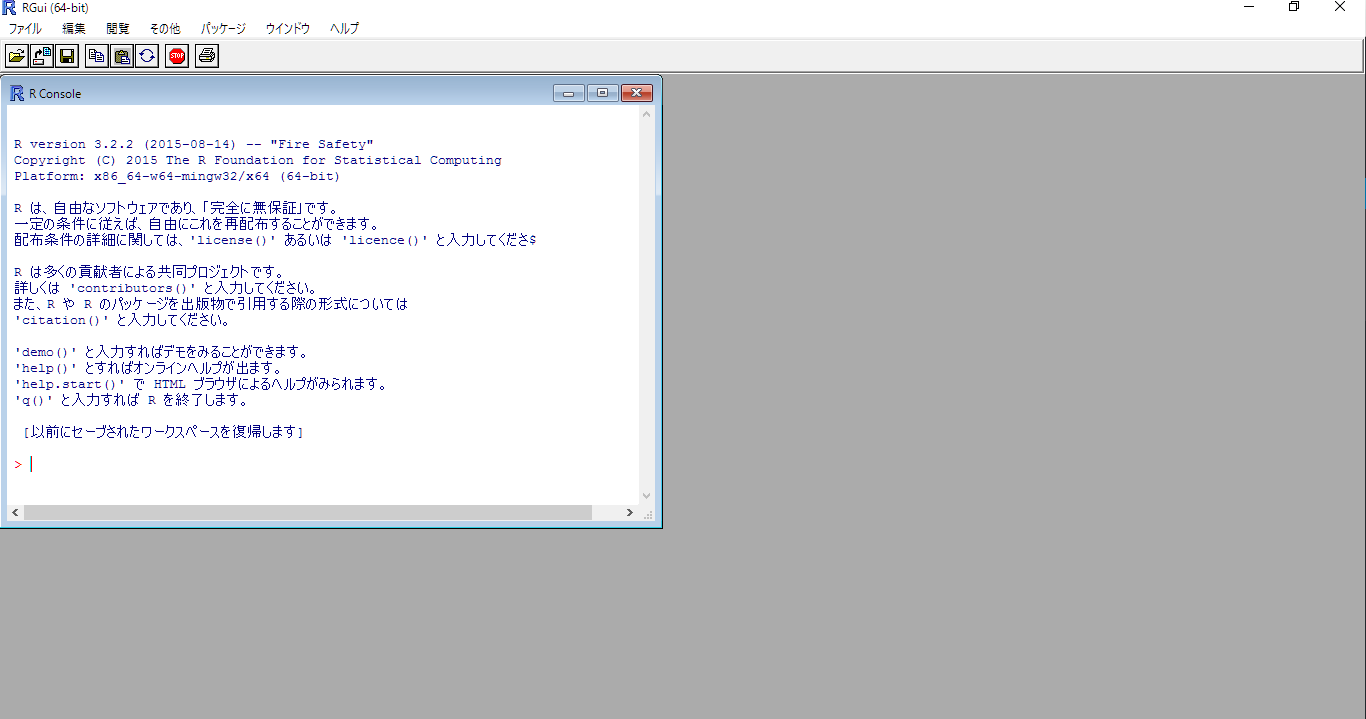
# 2.関数の構成
- 以下のコマンドを直接Rのコンソールに入力してみてください(一行を書き終わったらenterで実行)
- `#`行はメモ書きですので、その内容を入力しなくてもいいです
```R=
data1 <- c("A", "A", "A", "B", "B", "B")
#data1という「お皿」に文字リストA,A,A,B,B,Bを入れる
data2 <- c(32,44,35,65,46,58)
#data2という「お皿」に数値リスト32,...をいれる
data1
#data1の中身を確認
data2
#data2の中身を確認
bigdata <- data.frame(data1, data2)
#data.frameという関数で,data1とdata2を合わせて
#excel表みたいのデータフレームを作成して、bigdataという「お皿」(以降オブジェクトという)に入れる
bigdata
#bigdataの中身を確認
```
- 関数は複雑の処理手順を一つにまとめるプログラミングの武器です
- Rでは`関数名(項1,項2,項3)`という形になっています。
- オブジェクト名は自由に決められます(`data1`と`data2`)。大文字と小文字は区別されます
- 関数名(例:`data.frame()`)、そして実行するのに必要な項目(例:合成したいオブジェクトの名前をいれること)は決まっています
- `<-`とは「~オブジェクトの中身を~と指定する」という意味です
- 関数`c()`は「~を要素としてベクトル(リスト)を作る」という意味です
- 文字列には`" "`が必要ですが、数値は`" "`が要りません
- `#`はコメント表記です。Rは`#`以降の内容を無視します。よくメモ書きとして使われています
# 3.データのインプット
- 一行一行で入力するのが大変?(笑)excelで作成してからのインプットも可能です。
- excelで作成したファイルを「.csvファイル(tabで区切りするテキストファイル)」で保存してください

- あるいはこちらで事前に用意したファイルをダウンロード頂いても構いません [data1data2.csv](http://phiz.c.u-tokyo.ac.jp/~t_chen/download/data1data2.csv) (例としてC:\Users\Tess\Desktop\permutationに保存)
- Rにインプットする前に、「どこからデータを読み込むか」と、データやり取りのディレクトリを指定しておきます。(ファイル>ディレクトリの変更>C:\Users\Tess\Desktop\permutation)

- 以下のコマンドを入力して、データをRに読み込んでください
```R=+
bigdata <-read.csv("data1data2.csv", header=TRUE)
#関数read.csvで"data1data2.csv"を読み込む
bigdata
#bigdataの中身を確認
# data1 data2
# 1 A 32
# 2 A 44
# 3 A 35
# 4 B 65
# 5 B 46
# 6 B 58
```
- `header=TURE`とは、「データの一行目はコラム名と認識してください」という意味です
# 4.パッケージのインストール
- Rの中に元々いろんな基本関数が入っていますが、物足りないと感じる時はよくあります。Rはフリーソフトで、世界中に多くの有志者が、基本関数をもとにしてより複雑な関数を作って(ネギ、塩、ごま油、だしの素から塩ネギソースを作るように)、パッケージという形で発信しています。
- そういうパッケージは各国の研究機関のサーバーにアップロードされています。必要なパッケージを自分のニーズに合わせて無料でダウンロードできます
- 練習で`ggplot2`(グラフ作成専門のパッケージ)をダウンロードしましょう。
```R=+
install.packages("ggplot2")
```
- 実行したら、CRAN(サーバーの場所)が聞かれます。どこでも大丈夫ですが、特にこだわりがなければ日本を選びます
- 初めてパッケージをインストール方には、さらに「libraryを作成するか」と聞かれます。それはパッケージを保存するフォルダを自動生成してくれるという意味で、Yesを選んでください
- では、グラフを作ってみましょう。その前に練習用のデータをダウンロードしてください [passive.csv](http://phiz.c.u-tokyo.ac.jp/~t_chen/download/passive.csv) (Franklin Chang先生のpassive実験のデータと教材を拝借しています)
- passive.csvをRにインプットします。
```R=+
data <-read.csv("passive.csv", header=TRUE)
head(data)
#中身を確認する。
#head()関数は「オブジェクトの最初の数行を確認する」という意味です。
#行数の変更は可能ですが、デフォルトは6行です。
X subj trial time lang cond target win
1 1 1 1 0 English active 0.5046865 0
2 2 1 1 100 English active 0.4539369 0
3 3 1 1 200 English active 0.1571674 0
4 4 1 1 300 English active 0.3502081 0
5 5 1 1 400 English active 0.5736363 0
6 6 1 1 500 English active 0.5974486 0
```
- ggplot2を起動します(自分のパソコンにインストールするのは一回で済みますが、メモリを節約するために、使いたい時に別途起動する必要があります)(普段は冷蔵庫に保存しているが、使うときに調理台に出しておくという感じです)
```R=+
library(ggplot2)
```
- パッケージを起動する時に(`library()`)、文字列を示す`""`は要りません
```R=+
#条件別に各時間点の12人分のデータの平均を算出
means.df <- aggregate(target ~ time + lang + cond, data=data, FUN=mean)
#グラフのデータ元、X軸Y軸のもとを規定する
p <- ggplot(means.df , aes( x = time, y = target, colour=cond))
#線を引く
p <- p + geom_line()
#グラフを表示
p
```
- `aggregate()`はRの基本関数で、カテゴリの水準ごとに各変数列の要約を得るための関数です。
- 47行目は「dataというオブジェクトの中に、target(従属変数である注視率)をtime(各時間点) 、 lang(英語か日本語)、cond(主動文か受身文)という基準に分けて(そうしたら各カテゴリに12点のデータが入っている)、 平均値(mean)を取って、mean.dfという新しいオブジェクトにR内で保存する」という意味です
- `ggplot()`は先ほどダウンロードしたggplot2に入っている特殊関数で、グラフのX軸Y軸及びレイヤーを作成するための関数です(グラフを描くための下描きという感じです)。
- 49行は、「オブジェクトmeans.dfをもとにして、X軸はtimeで、Y軸はtargetで示すようにして、condが違う場合は色で表示する」という意味です
- ただし、49行までではただの下描きで、何も表示されないはずです
- 51行で「先ほど`ggplot()`で作成した下描きのオブジェクトpのもとに、線を足していきます`geom_line()`」(この段階でも何も表示されないはず)
- 53行の`p`を入力することによって、はじめてグラフが表示されるようになります
- 以下のグラフが出てきたら成功です。

# 5.t検定
- 1500msに、active文とpassive文の間に有意差が出るかをt検定で確認しましょう(上のグラフから見ると出そうですよね…)
- まず1500msのデータだけを取り出します。
```R=+
#1500msだけのデータを取り出す
data.1500 <- data[data$time==1500,]
#新しいオブジェクトの要約を確認する
summary(data.1500)
X subj trial time lang
Min. : 16.0 Min. : 1.00 Min. :1.0 Min. :1500 English :36
1st Qu.: 388.8 1st Qu.: 3.75 1st Qu.:2.0 1st Qu.:1500 Japanese:36
Median : 761.5 Median : 6.50 Median :3.5 Median :1500
Mean : 761.5 Mean : 6.50 Mean :3.5 Mean :1500
3rd Qu.:1134.2 3rd Qu.: 9.25 3rd Qu.:5.0 3rd Qu.:1500
Max. :1507.0 Max. :12.00 Max. :6.0 Max. :1500
cond target win
active :36 Min. :-0.1092 Min. :2
passive:36 1st Qu.: 0.4256 1st Qu.:2
Median : 0.5822 Median :2
Mean : 0.6203 Mean :2
3rd Qu.: 0.7826 3rd Qu.:2
Max. : 1.3589 Max. :2
```
- 関数`XXX()`とは違って、角括弧`[]`はデータフレームを意味して、データ整形に使いやすいです。
- 55行では、dataというオブジェクトの中に`data[]`、time欄が1500msという条件`data$time ==1500`に満たす行(`,`の左側は各行に対する条件`,`の右側は各欄に対する条件を示す)を取り出して、新しいオブジェクト`data.1500`にR内で保存する
- `summary()`はデータフレームの要約です。ここでは、data.1500のtime欄は1500msの他にはないということが確認できました
- 次にt検定をかけてみましょう
```R=+
t.test(target~cond, data=data.1500)
Welch Two Sample t-test
data: target by cond
t = -4.2646, df = 65.759, p-value = 6.546e-05
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-0.3755728 -0.1360372
sample estimates:
mean in group active mean in group passive
0.4924043 0.7482093
```
- `t.test()`はRの基本関数です。`~`の前には従属変数、その後は操作要因をいれます。最後にオブジェクトを指定します`data=data.1500`
- グラフと同じ傾向で、1500msには有意差がみられましたね(t = -4.2646,p-value = 6.546e-05)
# 6.回帰検定
- 二条件の検定に対して、t検定と線形回帰は大体同じ結果が出ます。今度は線形回帰モデル`lm()`をかけてみましょう
```R=+
#線形回帰で二条件の差を検定する
result <- lm(target~cond, data=data.1500)
#検定結果の報告
summary(result)
Call:
lm(formula = target ~ cond, data = data.1500)
Residuals:
Min 1Q Median 3Q Max
-0.60156 -0.17511 -0.00141 0.13860 0.61072
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.49240 0.04241 11.609 < 2e-16 ***
condpassive 0.25581 0.05998 4.265 6.15e-05 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.2545 on 70 degrees of freedom
Multiple R-squared: 0.2062, Adjusted R-squared: 0.1949
F-statistic: 18.19 on 1 and 70 DF, p-value: 6.154e-05
```
- 関数の書き方はt検定と似ています。90行は、オブジェクトはdata.1500、従属変数はtarget、操作要因はcondで回帰モデルを作るという意味です。その結果をresultという新しいオブジェクトに保存する。
- `summary(result)`でresultで保存された回帰モデルの結果を要約の形で表示されます
- 104行で示しているのは、「condを条件に、passiveがactiveより大きい」ということがわかりました(t=4.265, p=6.15e-05 ***)
- ここのt値はpermutation analysisでは主役になっていますので、取り出す方法は以下のようです
```R=+
coef(summary(result))[2,3]
[1] 4.264636
```
- 111行では、まずresultの要約を`summary()`で出しておいて、`coef()`関数でその要約の中のCoefficients部分(表)だけを取り出します。さらに表の中、2行目で3欄目の内容を取り出したら、t値の4.264636が表示されます。
# 7.roopの書き方
- permutation analysisの中でroop(繰り返し)の技をたくさん使っています。ここで練習してみましょう。
- ミッション:時間ごとにデータを取り出し、lmをかけた結果の中のt値を新しい表にまとめる
```R=+
#t値を貯めるために空っぽのデータフレームを作っておきます
ttable <-NULL
#オブジェクトdataの中にすべての時間点に対して
for (t in unique(data$time)){
#まず個々の時間を順に、データを取り出してdata.timeというオブジェクトに保存しておきます
data.time <- data[data$time==t,]
#その時間内のデータでlmで計算した結果をresultに保存
result <- lm(target~cond, data=data.time)
#特にt値の部分を取り出してresultというオブジェクトに保存
tvalue <- coef(summary(result))[2,3]
#時間点とt値をペアにして、tempオブジェクトに保存
temp <-data.frame(t,tvalue)
#空っぽだったttableに、順に各時間点で得られたtemp情報を足していきます
ttable <- rbind(ttable, temp)
}
```
- `<-NULL`とは、空っぽのオブジェクトを作成しておくという意味です
- roopの書き方は、`for(変数 in リスト){実行してほしいコード集}`となっています
- 一つの時間点(0, 100, 200,..., 2000)はオブジェクトdataの中に48回現れました。一つの時間点は一回でいいですので、リストの要素の重複を削除する`unique()`を使いました。
- 121, 123行は6.で説明しました。
- 125行は2.で説明しました
- `rbind()`とは行を足していくという意味です。`ttable`は足し先で、`temp`は足すもので、その結果を`ttable`を上書きするという意味です。
- `}`はroopの終わりで、まだ最初に戻って次の処理に入ります
- うまくいけば以下の結果が得られます
```R=+
ttable
t tvalue
1 0 0.3128276
2 100 -0.1178029
3 200 -0.3217607
4 300 0.1812581
5 400 -0.6806972
6 500 -0.1305001
7 600 1.3622857
8 700 -1.8236704
9 800 -2.6045917
10 900 2.0590445
11 1000 -1.7350853
12 1100 -1.5050028
13 1200 -0.6874644
14 1300 0.2909514
15 1400 3.8746079
16 1500 4.2646364
17 1600 2.2070960
18 1700 2.0333425
19 1800 -0.9662678
20 1900 -1.6306320
21 2000 0.7409185
```
# 8.おわりに
ここまでお付き合いいただきまして、どうもありがとうございました!
その予習レジュメの中に、R上級レベルの関数も入ってますので、あんまり挫折と思わないで、繰り返し練習してくださいね~
誤植がありましたら、tess5566779[at]yahoo.co.jpまでご連絡ください
Rの参考書もたくさん出ていますので、なんでもいいですから、ぜひお手に取ってお読みください
お会いするのを楽しみにしております~
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet