# 計算機網路 - Network Namespace
[TOC]
## References
### Linux Bridges, IP Tables, and CNI Plug-Ins - A Container Networking Deepdive
這個影片中除了介紹 `veth` 機制之外,最前面也有簡單介紹一些術語如何使用 `ip-link`、`brctl` 等命令列工具。在後面的實驗中,使用如 `brctl` 這類舊工具的命令,都會以 `bridge` 或 `ip` 當中對應的命令取代。
{%youtube z-ITjDQT7DU %}
這個影片中的實驗需要有 `dummy` 這個模組。所以如果在使用 `ip link add` 時出現以下的錯誤訊息:
```
$ sudo ip link add dummy0 type dummy
Error: Unknown device type.
```
那麼可以先試著載入這個模組:
```
$ sudo modprobe dummy
```
如果出現類似下面的錯誤訊息的話:
```
modprobe: FATAL: Module dummy not found in directory /lib/modules/5.13.0-1011-raspi
```
則可以試著安裝以下的套件:
```
$ sudo apt install linux-modules-extra-`uname -r`
```
### Container Networking From Scratch - Kristen Jacobs, Oracle
下面這個影片中的範例 repo 在[這裡](https://github.com/kristenjacobs/container-networking)。
{%youtube 6v_BDHIgOY8 %}
### SREcon19 Asia/Pacific - Software Networking and Interfaces on Linux
這個影片主要是介紹 Linux 中的 interfaces, bridge, tap 這些術語,跟 network namespace 關係較小。不過在不同的 network namespcae 之間
{%youtube HiktxCMF03A %}
### Tutorial: Communication Is Key - Understanding Kubernetes Networking - Jeff Poole, Vivint Smart Home
{%youtube Slce9Nu-NB0 %}
如果比較想知道跟 Kubernetes 有關的介紹,下面有更多:
1. [*Webinar: Kubernetes and Networks: Why is This So Dang Hard?*](https://youtu.be/GgCA2USI5iQ)
2. [*Intro + Deep Dive: Kubernetes (Network) SIG - Tim Hockin, Google*](https://youtu.be/BxDnv7MpJ0I)
3. [*Kubernetes Networking Intro and Deep-Dive - Bowei Du & Tim Hockin, Google*](https://youtu.be/tq9ng_Nz9j8)
## 簡介
關於 Namespace 的一般介紹可以參考[這裡](https://hackmd.io/@0xff07/sp/https%3A%2F%2Fhackmd.io%2F%400xff07%2Fr1wCFz0ut)。簡單地來說,Namespace 是 Linux 中的一種隔離機制。屬於同一個 namespace 的行程,會以為那些被 namespace 隔離出來的資源就是這個作業系統中全部的資源。若一個行程被 mount namesapce 隔離(或說「在那個 namesapce 裡面」),該行程就只能看到特定的 mount point; 而屬於同一個 PID namespace 的行程,在該 namespace 中只看得到那些「跟它屬於同一個 PID namespace」的行程,並且可以有另外一個 PID。這種「限制一個行程只能看到某些資源」也是實作 container 的其中一個基礎設施。
而 network namespace 如其名稱所示,用來隔離作業系統跟網路相關的資源。被 network namespace 隔離的那些行程,會以為自己獨享了一個完整的 network stack。或者更明確地,按照 `man` 中的 [`network_namespaces(7)`](https://www.man7.org/linux/man-pages/man7/network_namespaces.7.html) 中的說法:
> *Network namespaces provide isolation of the system resources associated with networking: network devices, IPv4 and IPv6 protocol stacks, IP routing tables, firewall rules...*
也就是說:不同的 network namespce 中的行程會看見不同的 interface、routing table、netfilter 規則等等。
雖然可以用 `unshare -n` 建立一個 network namespace,但更常見的可能是使用 [`ip netns`](https://man7.org/linux/man-pages/man8/ip-netns.8.html)。不同的 network namespace 可以各自有自己的 interface、IP、routing table、port mapping 等等。這些隔離出來的 namespace 之間可以使用虛擬的 bridge 連接起來。關於這個命令更詳細的行為可以在 [`ip-netns(8)`](https://www.man7.org/linux/man-pages/man8/ip-netns.8.html) 找到。
## 例子一:兩個 Network Namespace 用 veth 連接
本來的配置是參考自 [*Create Your Own Network Namespace*](https://itnext.io/create-your-own-network-namespace-90aaebc745d)。這之類的配置很常被拿來展示各種網路基礎設施的例子,比如 [xdp-project/bpf-examples](https://github.com/xdp-project/bpf-examples) 中的 [tc-basic-classifier](https://github.com/xdp-project/bpf-examples/tree/master/tc-basic-classifier) 中有使用類似的配置來展示 eBPF Qdisc classifier 怎麼使用; 而 [xdp-project/xdp-tutorial](https://github.com/xdp-project/xdp-tutorial) 中也有在 `veth` 上使用 XDP 的例子。裡面使用的架構是這樣:
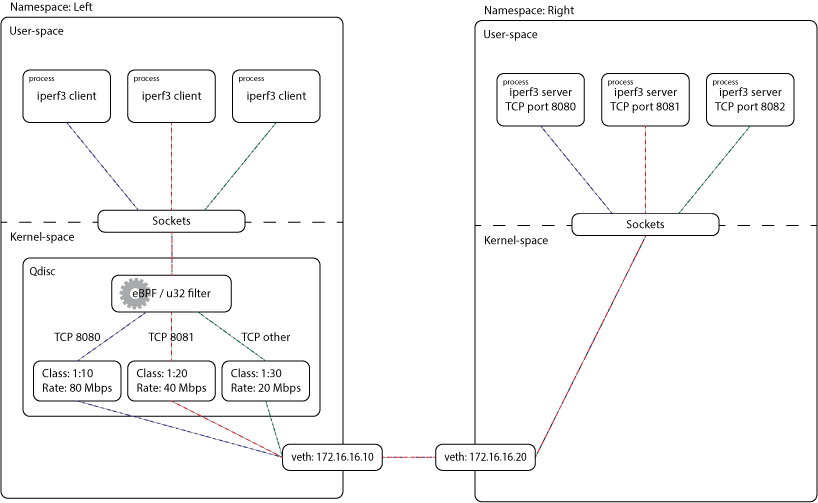
而現在會重製的是 Namespace 的部分,也就是像下面這樣:

### 前置準備
為了方便
```shell
$ L_IP=172.16.16.10
$ R_IP=172.16.16.20
$ L_CIDR="${L_IP}/24"
$ R_CIDR="${R_IP}/24"
$ L_NS="left"
$ R_NS="right"
$ L_DEV="$L_NS-veth"
$ R_DEV="$R_NS-veth"
```
### 建立兩個 Network Namespace
首先,建立兩個 network namespace:
```shell
$ sudo ip netns add "$L_NS"
$ sudo ip netns add "$R_NS"
```
這時候如果使用 `ip-netns` 命令中的 `list` 選項,可以發現多出了剛剛新增的 namespace:
```shell
$ ip netns list
right
left
```
### 建立 `veth` Pair
接著建立一對 `veth`,假定兩端叫做 `veth0` 與 `veth1`
```shell
$ sudo ip link add "$L_DEV" type veth peer "$R_DEV"
```
這時候如果使用:
```shell
$ ip link
```
應該會出現 `left-veth` 與 `right-veth`:
```clike
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc mq state DOWN mode DEFAULT group default qlen 1000
link/ether dc:a6:32:dc:90:8f brd ff:ff:ff:ff:ff:ff
3: wlan0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DORMANT group default qlen 1000
link/ether dc:a6:32:dc:90:90 brd ff:ff:ff:ff:ff:ff
4: right-veth@left-veth: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 32:1f:54:00:55:2d brd ff:ff:ff:ff:ff:ff
5: left-veth@right-veth: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 52:08:25:fb:ae:f0 brd ff:ff:ff:ff:ff:ff
```
> TODO: 上面輸出的不同欄位的意思
### 將 `veth`-pair 兩端各自移至 Namespace 中
接著把 `left-veth` 與 `right-veth` 這兩個 interface 分別移到 `left` 與 `right` 兩個 network namespace 中:
```shell
$ sudo ip link set "$L_DEV" netns "$L_NS"
$ sudo ip link set "$R_DEV" netns "$R_NS"
```
這時候如果在預設的 namespace 中檢視:
```shell
$ ip link
```
就會發現剛剛的 `veth0` 與 `veth1` 又不見了:
```clike
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc mq state DOWN mode DEFAULT group default qlen 1000
link/ether dc:a6:32:dc:90:8f brd ff:ff:ff:ff:ff:ff
3: wlan0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DORMANT group default qlen 1000
link/ether dc:a6:32:dc:90:90 brd ff:ff:ff:ff:ff:ff
```
但是另外一方面,在 `$L_NS` 這個 network namespace 中去檢視:
```shell
$ sudo ip -n "$L_NS" link
```
就會發現 `left-veth` 其實在這裡面:
```clike
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
5: left-veth@if4: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 52:08:25:fb:ae:f0 brd ff:ff:ff:ff:ff:ff link-netns right
```
類似地,如果在 `$R_NS` 這個 netowrk namespace 中做一樣的事情:
```shell
$ sudo ip -n "$R_NS" link
```
也會找到 `right-veth` 在這當中:
```clike
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
4: right-veth@if5: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 32:1f:54:00:55:2d brd ff:ff:ff:ff:ff:ff link-netns left
```
### 分配 IP 位址
接著幫 `left-veth` 與 `right-veth` 分配 IP 位址,分別是 `$L_CIDR` 與 `R_CIDR`:
```shell
$ sudo ip -n "$L_NS" addr add "$L_CIDR" dev "$L_DEV"
$ sudo ip -n "$R_NS" addr add "$R_CIDR" dev "$R_DEV"
```
> 這個網段是 *private IP*,可以參考 [*Public IP vs. Private IP and Port Forwarding (Explained by Example)*](https://youtu.be/92b-jjBURkw) 這個簡介。
這時,如果在 `left-vnet` 中檢查這個 namespace 中的 interface 對應的位址:
```shell
$ sudo ip -n "$L_NS" addr
```
就會找對剛剛指定的 IP 位址:
```clike
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
5: left-veth@if4: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 52:08:25:fb:ae:f0 brd ff:ff:ff:ff:ff:ff link-netns right
inet 172.16.16.10/24 scope global left-veth
valid_lft forever preferred_lft forever
```
類似地,在 `right-vnet` 中:
```shell
$ sudo ip -n "$R_NS" addr
```
則會出現:
```clike
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
4: right-veth@if5: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 32:1f:54:00:55:2d brd ff:ff:ff:ff:ff:ff link-netns left
inet 172.16.16.20/24 scope global right-veth
valid_lft forever preferred_lft forever
```
### 啟動 `veth` 與 `lo`
```shell
$ sudo ip -n "$L_NS" link set "$L_DEV" up
$ sudo ip -n "$L_NS" link set lo up
```
這時,如果再檢視 `vnet0` 中 namespace 中的狀況:
```shell
$ sudo ip -n vnet0 link show
```
就會發現狀態變成 `UP`:
```clike
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
5: left-veth@if4: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state LOWERLAYERDOWN mode DEFAULT group default qlen 1000
link/ether 52:08:25:fb:ae:f0 brd ff:ff:ff:ff:ff:ff link-netns right
```
類似地:
```shell
$ sudo ip -n "$R_NS" link set "$R_DEV" up
$ sudo ip -n "$R_NS" link set lo up
```
若檢視其中的 interface:
```shell
$ sudo ip -n "$R_NS" link show
```
之後也會發現類似的結果:
```clike
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
4: right-veth@if5: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether 32:1f:54:00:55:2d brd ff:ff:ff:ff:ff:ff link-netns left
```
### ping
這時候再從 `left` 中執行 `ping`:
```shell
$ sudo ip netns exec "$R_NS" ping "$L_IP"
```
就會發現可以順利的 `ping`:
```
PING 172.16.16.10 (172.16.16.10) 56(84) bytes of data.
64 bytes from 172.16.16.10: icmp_seq=1 ttl=64 time=0.098 ms
64 bytes from 172.16.16.10: icmp_seq=2 ttl=64 time=0.118 ms
64 bytes from 172.16.16.10: icmp_seq=3 ttl=64 time=0.119 ms
64 bytes from 172.16.16.10: icmp_seq=4 ttl=64 time=0.084 ms
64 bytes from 172.16.16.10: icmp_seq=5 ttl=64 time=0.115 ms
...
```
類似地,在 `right` 中也可以 `ping` 到 `left`:
```shell
$ sudo ip netns exec "$L_NS" ping "$R_IP"
```
就會發現可以成功 `ping` 了:
```
PING 172.16.16.20 (172.16.16.20) 56(84) bytes of data.
64 bytes from 172.16.16.20: icmp_seq=1 ttl=64 time=0.097 ms
64 bytes from 172.16.16.20: icmp_seq=2 ttl=64 time=0.121 ms
64 bytes from 172.16.16.20: icmp_seq=3 ttl=64 time=0.087 ms
64 bytes from 172.16.16.20: icmp_seq=4 ttl=64 time=0.085 ms
64 bytes from 172.16.16.20: icmp_seq=5 ttl=64 time=0.080 ms
...
```
### 清理
如果想要回覆原狀,只要把兩個 namespace 移除即可:
```shell
$ sudo ip netns delete "$L_NS"
$ sudo ip netns delete "$R_NS"
```
## 例子二:兩個 Namespace + 兩組 `veth` + 一個 bridge

參考自 [*Using network namespaces and a virtual switch to isolate servers*](https://ops.tips/amp/blog/using-network-namespaces-and-bridge-to-isolate-servers/)
### Namespace 的 veth 參數 (一樣)
首先跟前面是差不多的,只是這時要建立兩對 `veth`,而且還要建立 bridge。
```bash
L_IP=172.16.16.10
R_IP=172.16.16.20
L_CIDR="${L_IP}/24"
R_CIDR="${R_IP}/24"
L_NS="left"
R_NS="right"
L_DEV="$L_NS-veth"
R_DEV="$R_NS-veth"
```
### Bridge 的參數
接著是跟 bridge 有關的參數:
```bash
BR_IP=172.16.16.1
BR_CIDR="${BR_IP}/24"
BR="br0"
L_BR_DEV="$L_NS-$BR-veth"
R_BR_DEV="$R_NS-$BR-veth"
```
### 建立 Namespace (一樣)
```bash
sudo ip netns add "$L_NS"
sudo ip netns add "$R_NS"
```
### 建立兩對 `veth`-pair
```bash
sudo ip link add "$L_DEV" type veth peer "$L_BR_DEV"
sudo ip link add "$R_DEV" type veth peer "$R_BR_DEV"
```
### 移動 `veth`-pair 的其中一端到 Namespace 中 (一樣)
```bash
sudo ip link set "$L_DEV" netns "$L_NS"
sudo ip link set "$R_DEV" netns "$R_NS"
```
### 指定 `veth` 的 IP (一樣)
```bash
sudo ip -n "$L_NS" addr add "$L_CIDR" dev "$L_DEV"
sudo ip -n "$R_NS" addr add "$R_CIDR" dev "$R_DEV"
```
### 啟動 Namespace 中的 `veth` (一樣)
```bash
sudo ip -n "$L_NS" link set "$L_DEV" up
sudo ip -n "$L_NS" link set lo up
sudo ip -n "$R_NS" link set "$R_DEV" up
sudo ip -n "$R_NS" link set lo up
```
### 建立一個 Bridge
```bash
sudo ip link add name "$BR" type bridge
```
### 將 `veth`-pair 的另外一端與 Bridge 連接
```bash
sudo ip link set "$L_BR_DEV" master "$BR"
sudo ip link set "$R_BR_DEV" master "$BR"
```
### 設定 Bridge 的 IP
```bash
sudo ip addr add "$BR_CIDR" brd + dev "$BR"
```
### 啟動連接 Bridge 上的 `veth`
```bash
sudo ip link set "$L_BR_DEV" up
sudo ip link set "$R_BR_DEV" up
```
### 啟動 Bridge
```bash
sudo ip link set "$BR" up
```
## 例子三:使 Namespace 可以連到外面
在目前的狀況下去 `ping` 外面,比如說:
```
$ sudo ip netns exec left ping 8.8.8.8
```
會發現:
```
ping: connect: Network is unreachable
```
首先,把所有(也就是剛剛兩個)namespace 的 default gateway 設定成 `br0` 的 IP:
```shell
$ sudo ip -all netns exec ip route add default via "$BR_IP"
```
接著使用 `nftables` 設定 NAT 的規則:
```shell
$ sudo nft add table ip nat
$ sudo nft add chain ip nat "POSTROUTING {type nat hook postrouting priority srcnat;}"
$ sudo nft add rule ip nat POSTROUTING ip saddr "$BR_CIDR" counter masquerade
```
這時候檢視 nftables 的規則:
```shell
$ sudo nft list ruleset
```
就會出現類似以下的內容:
```clike
table ip nat {
chain POSTROUTING {
type nat hook postrouting priority srcnat; policy accept;
ip saddr 172.16.16.0/24 counter packets 1 bytes 84 masquerade
}
}
```
這邊的 NAT 指的是 Nework Address Translation。可以參考 [*Network Address Translation - NAT Explained*](https://youtu.be/RG97rvw1eUo) 與 [*Public IP vs. Private IP and Port Forwarding (Explained by Example)*](https://youtu.be/92b-jjBURkw)。而其中 masquerade 是一個 NAT 的特例。可以參考 nftables wiki 中的 [*Performing Network Address Translation (NAT)*](https://wiki.nftables.org/wiki-nftables/index.php/Performing_Network_Address_Translation_(NAT)#Masquerading) 的說明。
> 文章裡面本來是使用 `iptables`,這裡使用比較新的 nftables。可以使用 [`iptables-translate`](https://manpages.debian.org/bullseye/iptables/iptables-translate.8.en.html) 這個命令把 `iptables` 命令轉換為對應的 nftables 的命令。另外一個轉換方式是使用完 `iptables` 之後,直接用 `nft list ruleset` 來對照產生了什麼新規則(這兩個命令列工具有一樣的後端)。
最後啟動 IP forwarding:
```shell
$ sudo sysctl -w net.ipv4.ip_forward=1
```
然後就可以在 namespace 裡面 `ping` 到外面的網路了,比如:
```shell
$ sudo ip netns exec "$L_NS" ping 8.8.8.8
```